Exploring AI Memory Architectures (Part 1): A Deep Dive into Memory³
 Qin Liu
Qin Liu
Paper: Memory³: Language Modeling with Explicit Memory
Link: https://arxiv.org/abs/2407.01178v1
1. The Third Path for Knowledge
Large language models learn in two ways. The first is parametric memory. Knowledge gets encoded into the model’s billions of weights during pre-training. This memory is fast to access but incredibly expensive to update. The second is working memory, what we know as the context window. We stuff it with external documents at inference time using techniques like RAG. This is flexible, but it's a shallow integration, limited by context length and retrieval latency.
Neither way is perfect. The core problem remains: can we design a new form of knowledge that is deeply integrated like parametric memory, but as flexible as working memory? The Memory³ paper is a serious attempt to answer this, introducing a third type: explicit memory.
2. The Theory: Memory Circuits
To understand Memory³, you first have to understand its theoretical foundation: memory circuit theory. This theory defines "knowledge" by how it's computed inside the model. A specific fact, like "the capital of China is Beijing," can be seen as a circuit formed by specific attention heads and MLP neurons.
This theory divides knowledge into two types:
Abstract Knowledge: General capabilities like grammar or logical reasoning. Their circuits are complex, generalized, and hard to isolate from the model.
Concrete Knowledge: Facts tied to specific entities, like "the Eiffel Tower is in Paris." Their circuits are relatively simple and fixed.
The core idea of Memory³ is to externalize the circuits for "concrete knowledge" from the model's parameters and store them as explicit memory. The model's parameters can then focus on the more essential "abstract knowledge." This allows the model to be smaller and more efficient.
3. What is "Explicit Memory"?
The central concept in Memory³ is explicit memory. It's not an external database but an architectural optimization deep inside the model.
How it differs from model parameters: Parameters are implicit, highly compressed, and costly to update. Explicit memory is external, structured, and can be added, deleted, or modified without retraining the entire model.
How it differs from RAG: RAG feeds raw text into the context window, forcing the model to spend compute cycles reading and understanding it. Explicit memory stores pre-computed states—sparse attention key-value pairs—that the model can use directly. It skips the comprehension step, making it far more efficient.
In essence, explicit memory is a highly efficient data structure, tailor-made for the model's attention mechanism.
4. How It Works: Generation, Storage, and Retrieval
Creating and Storing Memory: Sparsity is Key
Explicit memory is fundamentally a set of sparse attention key-value pairs. It's written like this:
Encode: A "memory generator" (a trained Transformer model) reads a source document.
Filter & Sparsify: This is the crucial step. By analyzing attention scores, the system identifies the few most informative tokens in the document. Only these key tokens are kept.
Store: The system saves only the key and value vectors for these critical tokens. This sparse set of K-V pairs is the "compiled" essence of the document. This sparsity dramatically reduces storage costs, making large-scale memory banks feasible.
Retrieving and Using Memory
When a user asks a question, the system uses vector search (the paper mentions Faiss) to find relevant memory units.
The vector index stores the key vectors of all memory units.
The search query is the user's question, encoded into a query vector.
The retrieved key-value pairs are then directly concatenated into the key and value matrices of the model's current attention layer. The external knowledge becomes a direct part of the computation, without the overhead of being "read." It's the most efficient fusion possible.
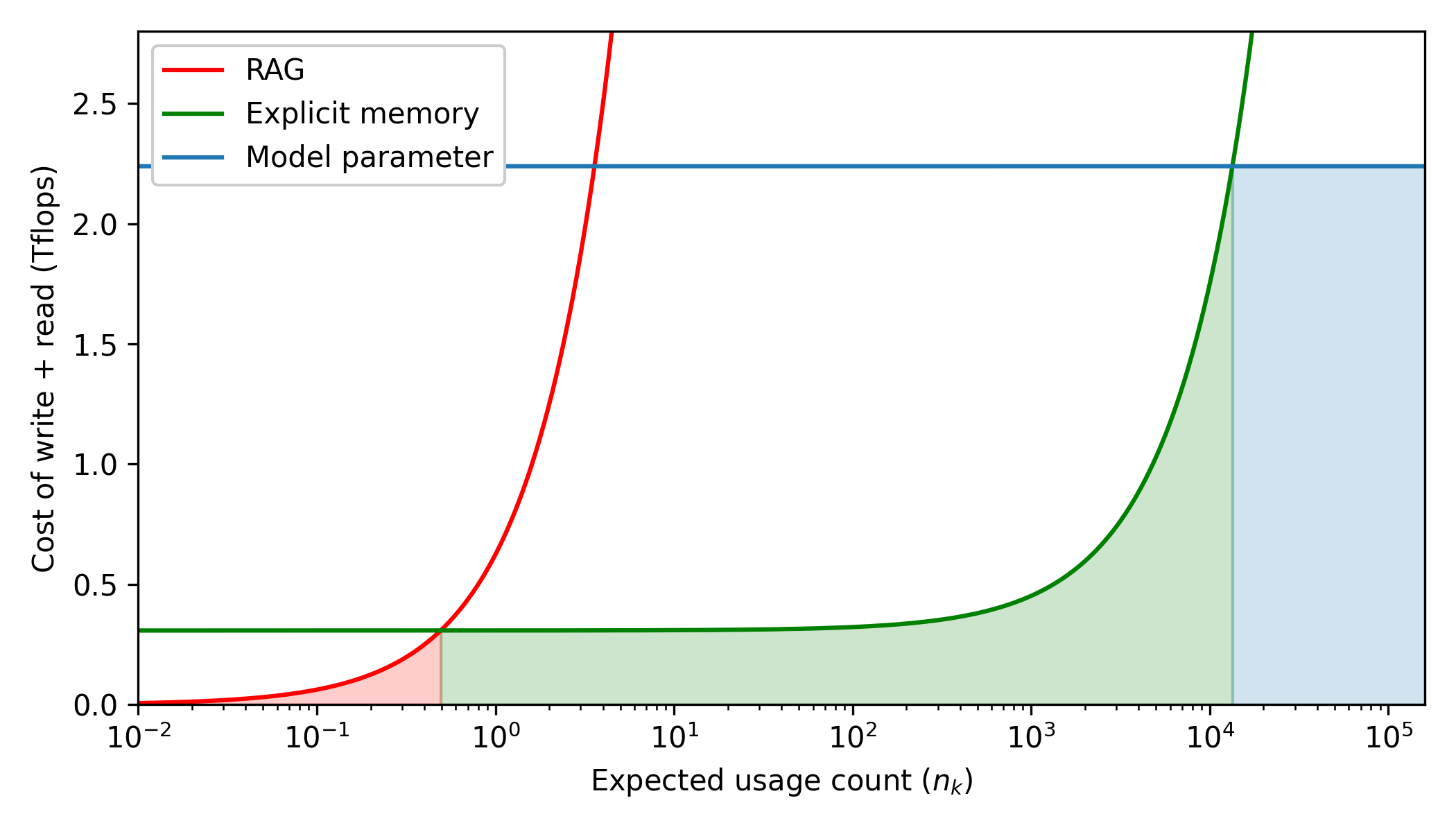
5. The Economics of Memory
The value of Memory³ isn't just theoretical; it's economical. The paper provides a clear cost analysis comparing the total cost (write cost + read cost) of the three memory types at different usage frequencies.
Model Parameters: Extremely high write cost (training), but very low read cost. Best for high-frequency abstract knowledge.
RAG: Almost zero write cost (storing plain text), but high read cost every time (real-time encoding). Best for very low-frequency knowledge.
Explicit Memory: Moderate write and read costs.
The conclusion is clear: Explicit memory has an unbeatable cost advantage for knowledge with medium-frequency usage. This is its sweet spot.
6. Answering Key Questions
How is the model trained?
This is a critical detail. The Memory³ model is not a fine-tune of an existing open-source model. The researchers pre-trained a 2.4B parameter model from scratch, architected to natively support explicit memory. The training has two phases:
Warm-up Phase: The model learns to encode knowledge into its parameters, like a traditional pre-training run.
Continual Training Phase: The model learns how to read from and use explicit memory. It's exposed to a growing memory bank compiled from documents processed in the first phase.
How does it handle long texts for "infinite context"?
Memory³ uses a "encode first, then chunk" strategy. It first encodes the entire document to capture global context. Then, preserving this global information, it splits the long sequence of K-V pairs into manageable memory fragments. Each fragment's vectors thus contain context from the whole document. Since the memory is stored externally and retrieved only when needed, this theoretically breaks the length limits of traditional context windows.
What are the other benefits?
Besides efficiency, explicit memory offers two major advantages:
Improved Factual Accuracy: Because knowledge is stored and retrieved in a form closer to its source, there's less information loss and "hallucination" than can occur during parametric compression.
Enhanced Interpretability: When the model gives an answer, you can trace back to the specific memory units it relied on, which in turn point to the original source text.
7. Potential and Limitations
The results are promising: the Memory³ 2.4B model outperforms Llama2-7B on several knowledge-intensive tasks, and it's faster. This proves the architecture's effectiveness.
But as a frontier exploration, it faces serious open questions:
Scalability: Can storage costs and retrieval speeds remain acceptable when the memory bank grows to trillions of tokens?
Knowledge Updates: For real-time information, what are the latency and cost of recompiling memory?
Generality: Will its success on Q&A tasks transfer to more complex reasoning or creative tasks?
Memory³ proposes an inspiring optimization at the architectural level. It shows us a third path beyond RAG and fine-tuning. But it also forces us to ask a deeper question: when the amount and complexity of memory grow beyond what a clever data structure can handle, do we need a whole new system to manage it? That's what we'll explore next with MemOS.
Subscribe to my newsletter
Read articles from Qin Liu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Qin Liu
Qin Liu
I am Qin Liu, a software engineer with a deep passion for computer systems and artificial intelligence. Currently, I work at MyScale, a fully-managed vector database company, focusing on vector databases and retrieval-augmented generation (RAG).