Exploring AI Memory Architectures (Part 2): MemOS Framework
 Qin Liu
Qin LiuPaper: MemOS: A Memory OS for AI System
Link: https://arxiv.org/abs/2507.03724v2
GitHub: https://github.com/MemTensor/MemOS
1. From Data Structure to Operating System
In the last post, we saw how Memory³ designed an efficient "memory data structure." But a single data structure, no matter how clever, can't solve systemic complexity. When vast amounts of memory need to be used concurrently by different agents, persisted, updated, and permissioned, you need a management system.
This is the context for MemOS. It asks a bigger question: do we need an operating system for AI to manage its memory and behavior? It's not trying to make a single memory access more efficient, but to build a governance framework that can support complex, multi-agent systems over the long term.
2. The Core Idea: Unifying Three Memory Tiers
MemOS explicitly builds on the ideas from Memory³. Its central thesis is to classify all AI-related knowledge and state into three interoperable forms of memory:
Plaintext Memory: The base layer. Stable, human-readable memory. This is the equivalent of a computer's hard drive. MemOS supports various backends, from plain text files and tree structures to graph databases like Neo4j for storing structured entity-relationship knowledge.
Activation Memory: "Hot" memory that exists to accelerate access. This is the KV cache, fully adopting the "explicit memory" concept from Memory³. It's the equivalent of a computer's RAM.
Parametric Memory: Knowledge deeply internalized into the model's weights, for example, through a LoRA fine-tune. This is the most tightly coupled memory, like a CPU cache.
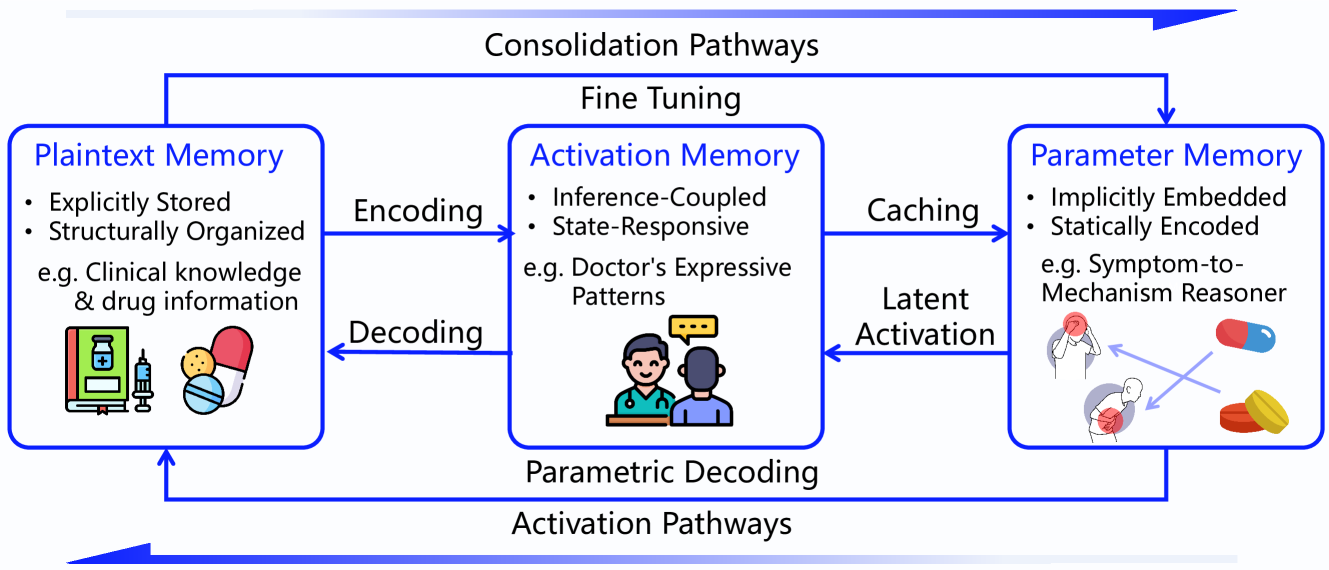
The goal of MemOS is to design a system for the unified, full-lifecycle management of these three memory tiers.
3. The Core Abstraction: MemCube
To manage these different forms of memory uniformly, MemOS introduces its most important abstraction: the MemCube. Think of it as a standardized "memory container."
Each MemCube has two parts:
Payload: The actual memory content. This could be a chunk of plaintext, a set of KV-cache activation pairs, or a LoRA weight file.
Metadata: This is the foundation of governance. It's a set of tags describing the payload, defining system-level information like
user_id,source,timestamp,importance_score,access_control_list, andversion.
By wrapping all memory in these standardized, metadata-rich containers, MemOS can track, schedule, permission, and evolve it at a system level. The MemCube transforms memory from mere data into a manageable system asset.
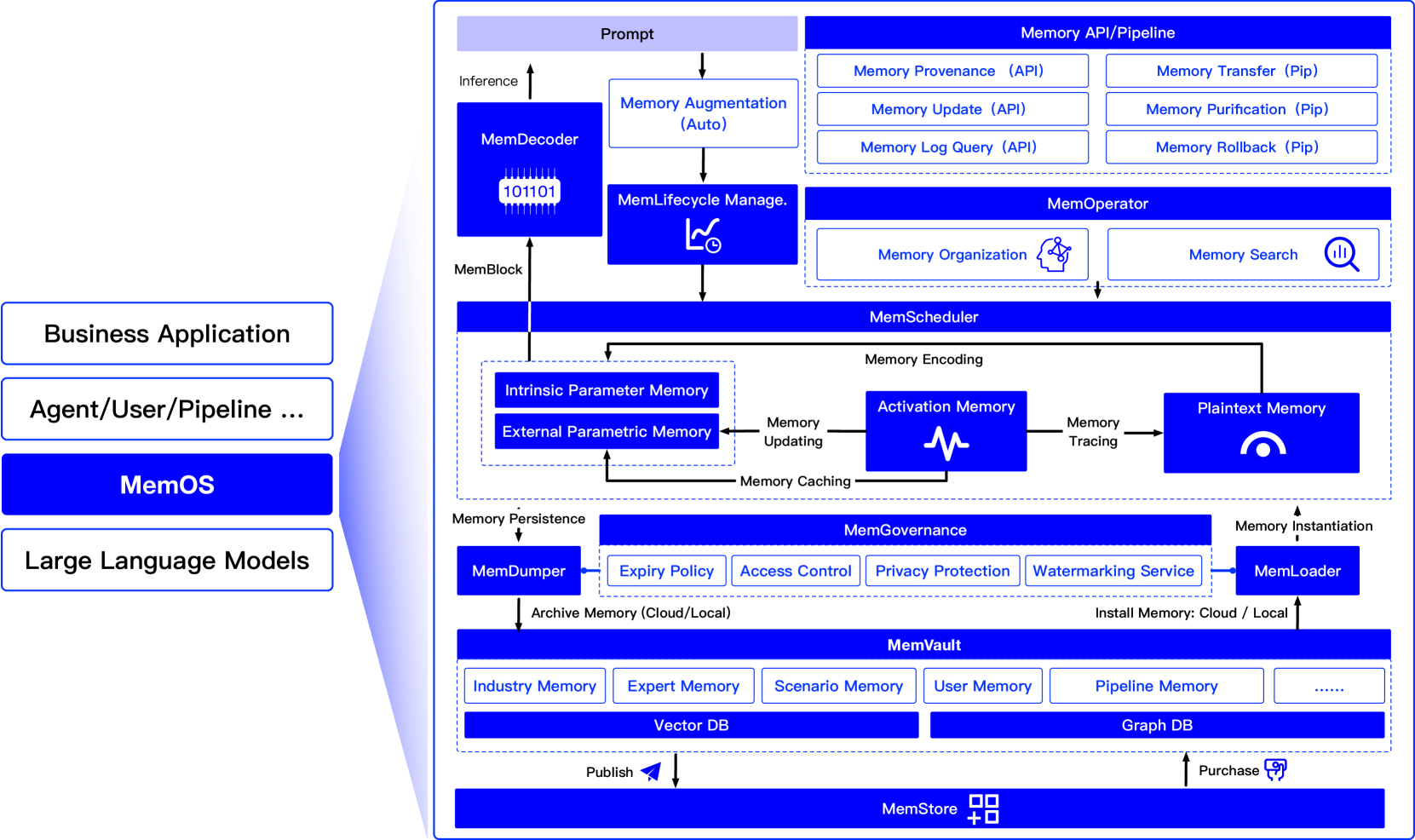
4. The MemOS Architecture
MemOS uses a layered architecture, consisting of storage, service, and application layers.
Storage Layer: Handles persistence, connecting to backends like local filesystems, S3, or Neo4j.
Service Layer: The system's core, providing APIs for memory management, user management, etc. It comes in two flavors:
MemOS NEO: A full, standalone memory OS service.
MemOS MCP: A lightweight, embeddable plugin for platforms like Coze.
Application Layer: Where developers build their AI apps on top of the MemOS APIs.
This flexible architecture allows MemOS to act as either a powerful central memory hub or a convenient embedded component.
5. Dynamic Memory Flow: Caching and Hardening
The elegance of the MemOS framework lies in its vision of a self-optimizing system where memory flows dynamically between the three tiers:
"Caching": When the system notices a piece of plaintext memory (on the "hard drive") is accessed frequently, it can automatically "compile" it into activation memory (the KV cache in "RAM") to speed up future calls.
"Hardening": When a skill or piece of knowledge needs to be deeply learned, the system can take plaintext or activation memory and "harden" it into parametric memory (in the "CPU cache") via training methods like LoRA. This is like turning a practiced skill into muscle memory.
"Archiving": Conversely, parametric or activation memory that goes unused can be "demoted" back to plaintext to free up valuable compute resources.
This dynamic capability would allow a system to intelligently balance cost, speed, and performance based on real-world usage.
6. The Workaround: Supporting Closed Models with Prefix Caching
This is a critical, real-world problem. You can't access the internals of a model like GPT-4o, so you can't directly inject a KV cache into its attention layers. MemOS's solution is a clever simulation that leverages a common optimization in modern LLM inference: Prefix Caching.
Prefix Caching is simple. When you send a prompt to an LLM, the inference engine first computes the Key-Value pairs for every token in your prompt. This is called the prefill stage. The resulting KV cache is stored in VRAM. For every new token the model generates, it can reuse this cache instead of recomputing the whole prompt, which is much faster. Prefix caching just means sharing this KV cache between different requests. If two prompts start with the same text, the engine can reuse the cached KVs for that prefix.
MemOS's strategy becomes obvious:
Retrieve Plaintext: It finds the original plaintext memory corresponding to the desired "activation memory."
Prepend to Prompt: It then prepends this plaintext to the user's current query, forming a combined prompt.
When this combined prompt is sent to the closed model, the inference engine's native prefix caching mechanism kicks in. If that memory text has been used recently, its KV cache is likely still available. The engine reuses the cache, functionally "simulating" the injection of activation memory while getting the performance benefit.
7. The Trade-off: Compatibility vs. Performance
We can now clearly see the trade-off between the MemOS approach and Memory³'s native architecture:
Memory³ (Native Injection):
Pro: Peak performance. It skips reading and encoding text, injecting pre-computed, sparse KVs directly into the model's core. It is maximally efficient.
Con: Inflexible and incompatible. It requires modifying the model's architecture, so it can't work with closed models or standard open-source models.
MemOS (Prefix Cache Simulation):
Pro: Highly flexible and compatible. It works with any black-box model that supports prefix caching. This gives its governance ideas much broader applicability.
Con: Performance compromise. It's less efficient than native injection. It relies on the inference engine's caching strategy and uses a dense KV cache of the full text, not the optimized sparse KV cache from Memory³.
MemOS makes a smart trade-off, sacrificing some performance for the ability to work in a heterogeneous world. Memory³ focuses on pushing a single, unified architecture to its theoretical limits.
8. The Grand Vision: "LLM as Kernel"
MemOS's most ambitious idea is "LLM as Kernel." It suggests that the core scheduler of a future operating system could be an LLM. The LLM would no longer be just a program to be called, but the brain of the system itself, responsible for interpreting user intent, scheduling memory, selecting tools, and generating a response.
This is a disruptive vision, but it faces huge hurdles today in performance, cost, and the fundamental reliability required of an OS kernel. Still, it paints an exciting picture of what might come.
MemOS provides a comprehensive and profound theoretical framework. It highlights a systemic weakness in today's agent architectures. By introducing ideas from operating systems and databases, it gives us the vocabulary and the blueprint—however controversial—to think about building more robust and evolvable AI systems.
Subscribe to my newsletter
Read articles from Qin Liu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Qin Liu
Qin Liu
I am Qin Liu, a software engineer with a deep passion for computer systems and artificial intelligence. Currently, I work at MyScale, a fully-managed vector database company, focusing on vector databases and retrieval-augmented generation (RAG).