Tạo Open WebUI Cá Nhân sử dụng Olama
 Justin
JustinKhi AI ngày càng được tích hợp vào cuộc sống hàng ngày của chúng ta, các vấn đề về quyền riêng tư khi chia sẻ dữ liệu trở thành mối quan tâm nghiêm trọng đối với nhiều người. Trong nhiều trường hợp, chúng ta không có quyền kiểm soát hoàn toàn đối với lượng thông tin được chia sẻ và có thể phải đối mặt với các chính sách lưu giữ dữ liệu không chắc chắn hoặc tệ hơn, các thực hành đáng ngờ của các nhà cung cấp dịch vụ.
Lấy ví dụ, một phát triển gần đây với OpenAI trong đó họ nhận được lệnh của tòa án để lưu trữ các cuộc trò chuyện của người dùng vô thời hạn. Điều này rõ ràng có tác động lớn đến tất cả người dùng ChatGPT trên các gói Free, Plus và Pro. Điều này thậm chí còn mở rộng đến bất kỳ ai sử dụng API của họ.
Vậy, làm thế nào để bạn bảo vệ các cuộc trò chuyện của mình? Cách an toàn nhất là ngừng sử dụng các dịch vụ AI, đúng không? Chà, điều đó rõ ràng sẽ không phải là trường hợp của nhiều người! May mắn thay, có một cách tiếp cận đơn giản hơn bảo vệ quyền riêng tư của bạn và giữ thông tin của bạn 100% trên máy của bạn.
Ollama + Open WebUI
Để thiết lập một giải pháp thay thế ChatGPT trên máy của chúng ta, chúng ta sẽ sử dụng hai dự án mã nguồn mở phổ biến:
Ollama: Cho phép bạn chạy các mô hình AI trên máy tính của mình mà không cần truy cập mạng (100% ngoại tuyến).
Open WebUI: Một giao diện web đơn giản cho phép bạn trò chuyện với các mô hình AI chạy trên máy tính của bạn. (Cung cấp cho bạn giao diện người dùng kiểu ChatGPT).
Để giữ cho thiết lập của chúng ta gọn gàng, chúng ta sẽ sử dụng Docker cho hướng dẫn này. Mặc dù không bắt buộc, việc đóng gói các dự án của bạn luôn là một ý tưởng tốt vì nó tự động cung cấp một môi trường sạch, cô lập và có khả năng tái tạo cao.
Tạo Docker Compose
Chúng ta sẽ bắt đầu bằng cách tạo một tệp docker-compose.yml mới, sau đó dán nội dung sau vào:
services:
ollama:
image: ollama/ollama
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
environment:
- OLLAMA_LLM_MAX_MEMORY=6000MB
- OLLAMA_NUM_THREADS=6
- OLLAMA_MAX_LOADED_MODELS=1
- OLLAMA_KEEP_ALIVE=5m
- OLLAMA_NUM_PARALLEL=1
deploy:
resources:
limits:
cpus: '6.0'
reservations:
cpus: '2.0'
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
ports:
- "8080:8080"
volumes:
- open_webui_data:/app/backend/data
environment:
- OLLAMA_BASE_URL=http://ollama:11434
- WEBUI_SECRET_KEY=enter-key-here
depends_on:
- ollama
volumes:
ollama_data:
open_webui_data:
Tệp docker-compose.yml của chúng ta thiết lập hai container:
ollama: Chạy các mô hình cục bộ trên cổng11434, giới hạn sử dụng 6 lõi CPU và 6GB RAM, với các mô hình được giữ trong bộ nhớ trong 5 phút sau khi sử dụng. (Hãy điều chỉnh theo nhu cầu của bạn).open-webui: Cung cấp một giao diện web trên cổng8080kết nối với Ollama để tạo ra một giao diện giống ChatGPT.
Cả hai dịch vụ lưu trữ dữ liệu trong các volume persistent để không mất dữ liệu khi container khởi động lại, và WebUI chờ Ollama khởi động trước vì nó phụ thuộc vào nó để hoạt động.
Tạo Container
Đảm bảo bạn đang ở cùng thư mục nơi tệp docker-compose.yml nằm, sau đó chỉ cần chạy docker-compose up.
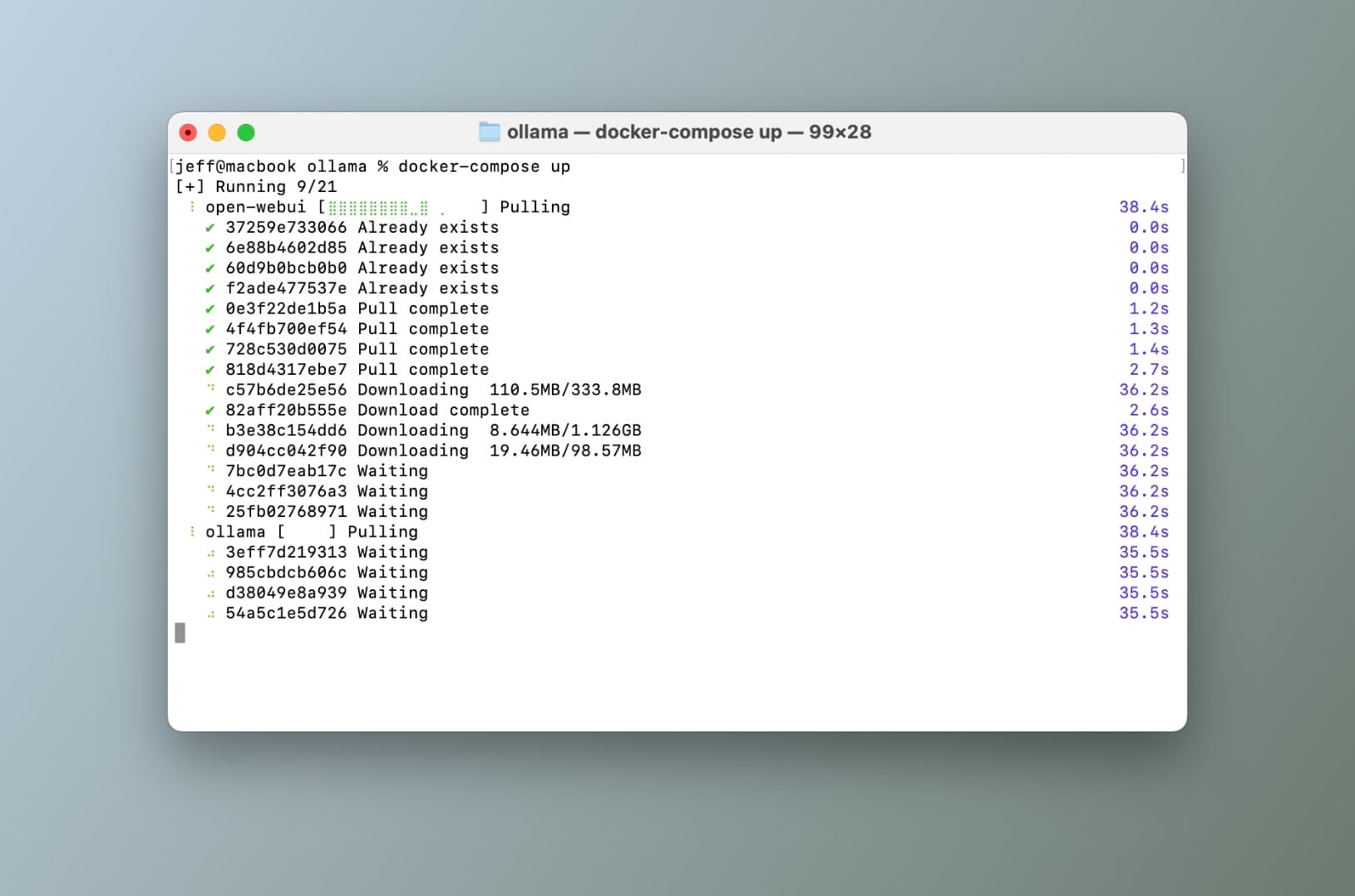
Chạy docker-compose up từ terminal
Bây giờ điều này sẽ mất vài phút tùy thuộc vào tốc độ kết nối internet của bạn, nhưng cuối cùng bạn sẽ có hai container.
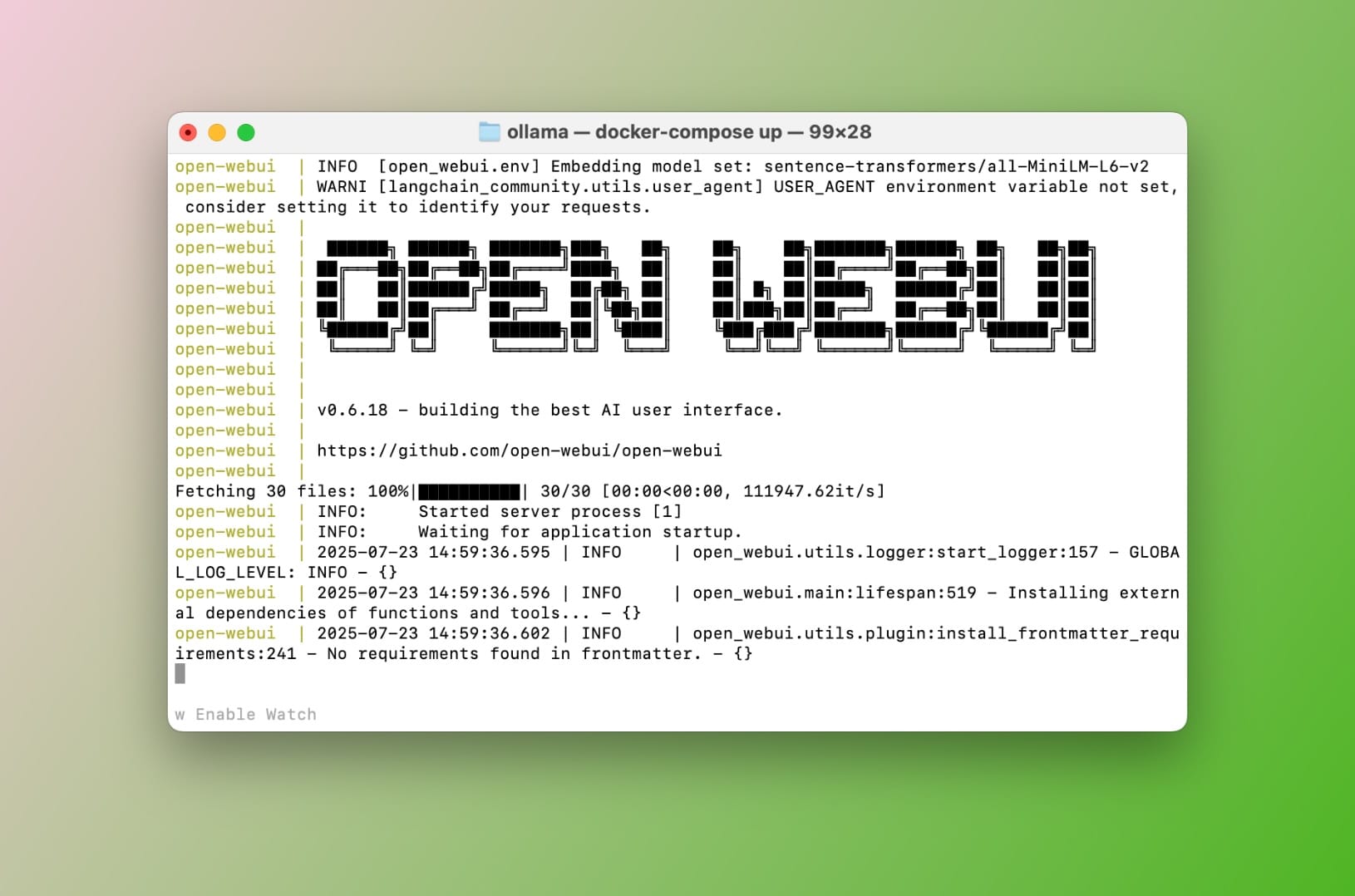
Kết quả của docker-compose up
Để xác nhận mọi thứ đều ổn, hãy chạy lệnh sau trong terminal của bạn: docker ps
Bạn sẽ thấy một cái gì đó như thế này:
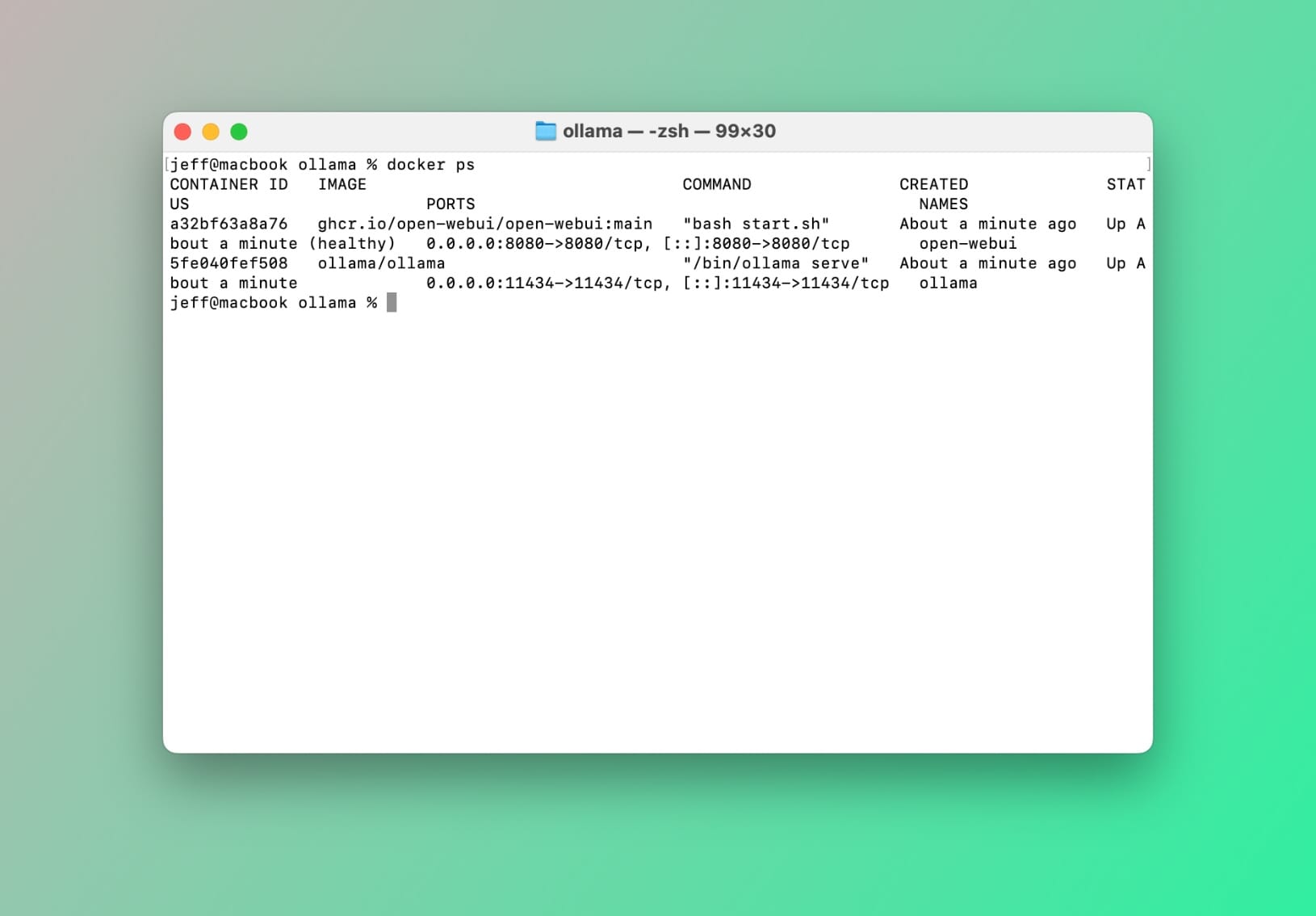
Container đang chạy sau: docker ps
Chọn và Cài Đặt Mô Hình
Tiếp theo, chúng ta sẽ muốn tải xuống và cài đặt một mô hình để Ollama hoạt động. Điều quan trọng là biết rằng các mô hình đa năng như GPT-4o, Claude Sonnet, Google Gemini và các mô hình khác được thiết kế để xử lý một loạt các nhiệm vụ một cách hợp lý. Tuy nhiên, chúng không được tối ưu hóa cụ thể cho một lĩnh vực cụ thể, chẳng hạn như lập trình hoặc viết lách.
⚠️
Điều đó không có nghĩa là các mô hình chuyên biệt luôn tốt hơn, nhưng điều quan trọng là hiểu sự khác biệt. Khi bạn cài đặt một mô hình cục bộ, nó sử dụng các tài nguyên hạn chế của máy tính của bạn như CPU và RAM. Vì vậy, tốt nhất là chọn một mô hình phù hợp với nhu cầu của bạn mà không làm quá tải hệ thống của bạn.
Được rồi, giả sử bạn đang tìm kiếm một trợ lý mã để giúp với các nhiệm vụ lập trình, bạn sẽ muốn một mô hình được điều chỉnh cho mã. Để xem những gì có sẵn, hãy truy cập thư viện mô hình của Ollama. Một số tùy chọn phổ biến bao gồm codellama, qwen2.5-coder và phi3.5. Các mô hình này khác nhau về kích thước và hiệu suất, nhưng làm thế nào để bạn chọn phiên bản nào hoạt động tốt nhất cho bạn?
Tải Xuống Mô Hình cho Ollama
Trong bản demo này, chúng ta sẽ sử dụng llama3.2:1b-instruct-q4_0. Mô hình này là một lựa chọn tuyệt vời cho trợ giúp mã cơ bản và rất nhẹ trên tài nguyên hệ thống. Tùy thuộc vào phần cứng của bạn, bạn có thể chọn một mô hình lớn hơn hoặc chuyên biệt hơn.
Vì chúng ta đang chạy Ollama trong một container, chúng ta cần thực hiện lệnh tải xuống (pull) trong container. Để làm điều này, hãy gõ lệnh sau trong terminal của bạn:
docker exec -it ollama bash
Lấy một shell bên trong container ollama
💡
Nếu bạn không chạy dự án trong một container docker, bạn có thể bỏ qua lệnh pull dưới đây.
Bây giờ chúng ta đã ở bên trong container, hãy kéo llama3.2:1b-instruct-q4_0 bằng cách sử dụng CLI ollama:
Kéo llama3.2:1b-instruct-q4_0 bên trong container ollama
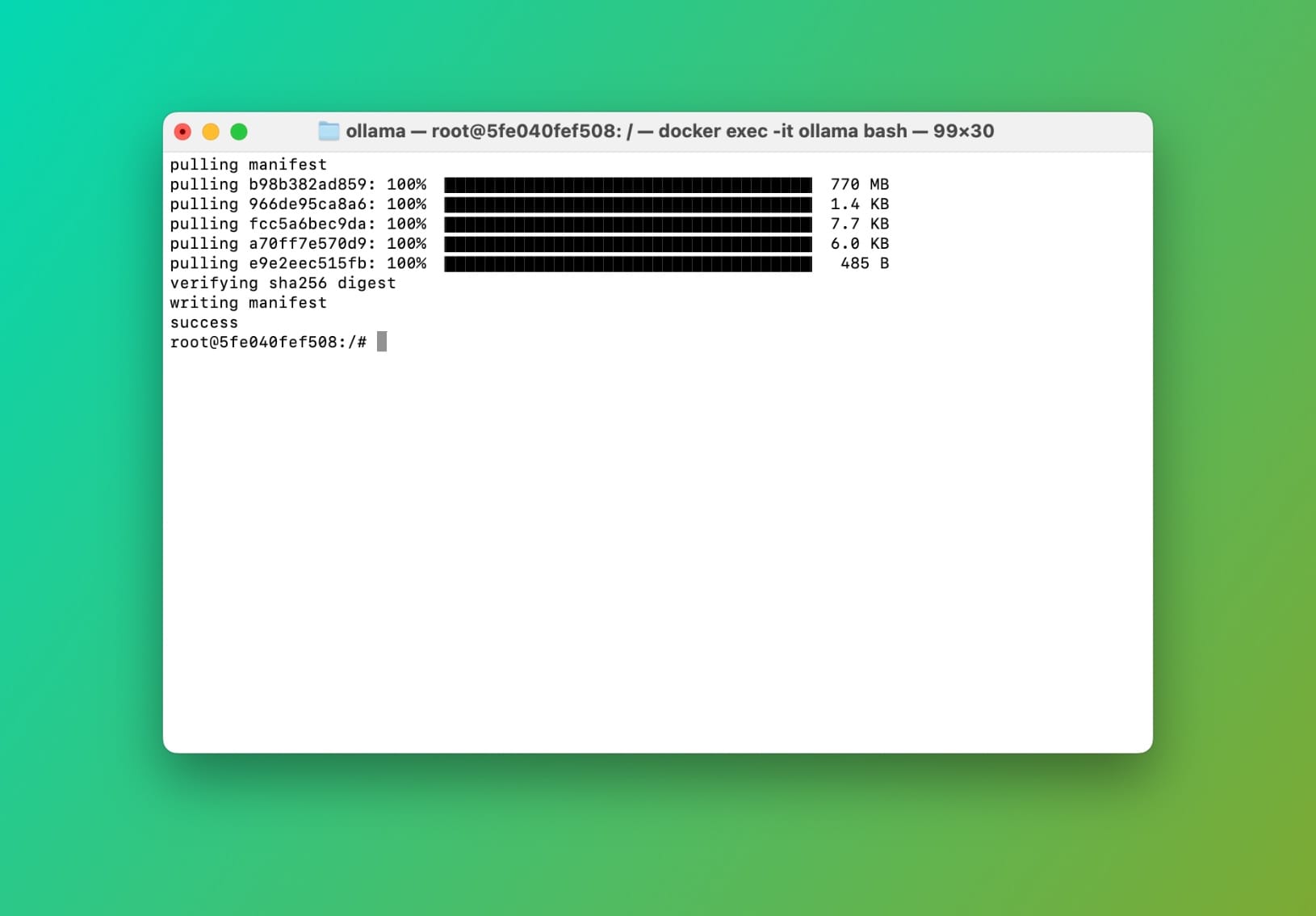
Hoàn thành kéo mô hình Ollama
Bây giờ hãy nhanh chóng thử nghiệm nó. Trong khi ở bên trong container, chạy lệnh sau: ollama run llama3.2:1b-instruct-q4_0 sau đó nhấn return. Bạn bây giờ có thể nhắc mô hình:
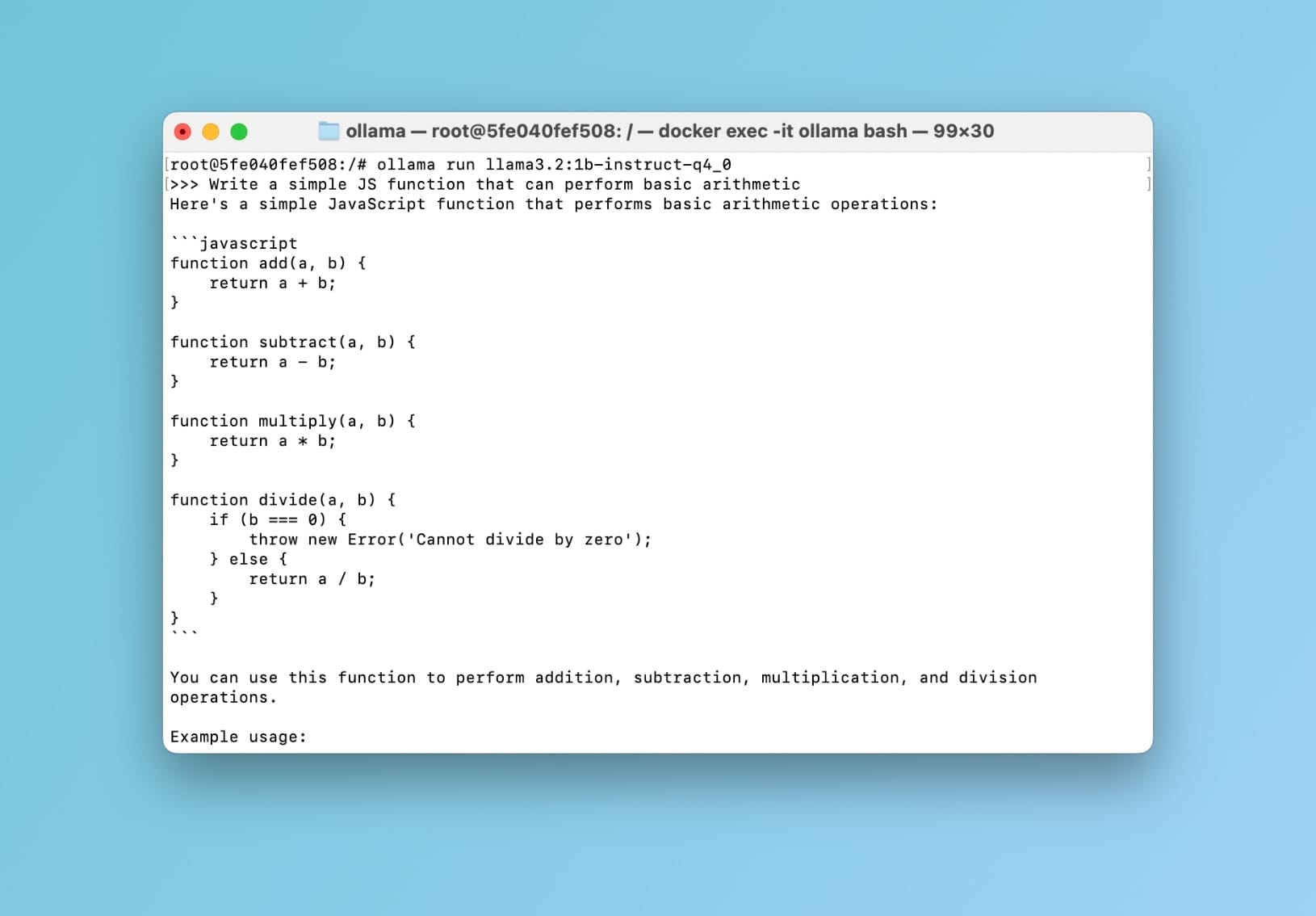
llama3.2:1b-instruct-q4_0 demo trong container ollama
ollama pull llama3.2:1b-instruct-q4_0
Tuyệt vời 🥳 Điều này xác nhận rằng mọi thứ đều ổn. Bây giờ hãy đưa nó lên cấp độ tiếp theo và tương tác với mô hình của chúng ta bằng giao diện kiểu ChatGPT thay vì terminal.
Sử Dụng Mô Hình với Open WebUI
Nếu bạn đã làm theo các bước trong hướng dẫn này, bạn bây giờ sẽ có một container thứ hai đang chạy với Open WebUI đã được cài đặt và sẵn sàng hoạt động. Để xác nhận điều này, trong terminal của bạn gõ docker ps.
Bạn sẽ thấy một container có tên open-webui.
💡
Nếu bạn không sử dụng docker, hãy làm theo các bước cài đặt trên repo chính thức của Open WebUI.
Bây giờ hãy mở cửa sổ trình duyệt của bạn và điều hướng đến: http://localhost:8080 (hoặc cổng nào bạn đã đặt trong tệp docker-compose.yml của bạn.)
Bạn sẽ thấy màn hình đăng nhập Open WebUI. Hãy tạo một tài khoản (đừng lo, tài khoản này chỉ lưu trên máy của bạn). Sau khi bạn đăng nhập, bạn sẽ thấy một giao diện tương tự như thế này:
Open WebUI + Ollama chạy cục bộ
Hãy sử dụng cùng một lời nhắc (Viết một hàm JS đơn giản có thể thực hiện các phép toán cơ bản):
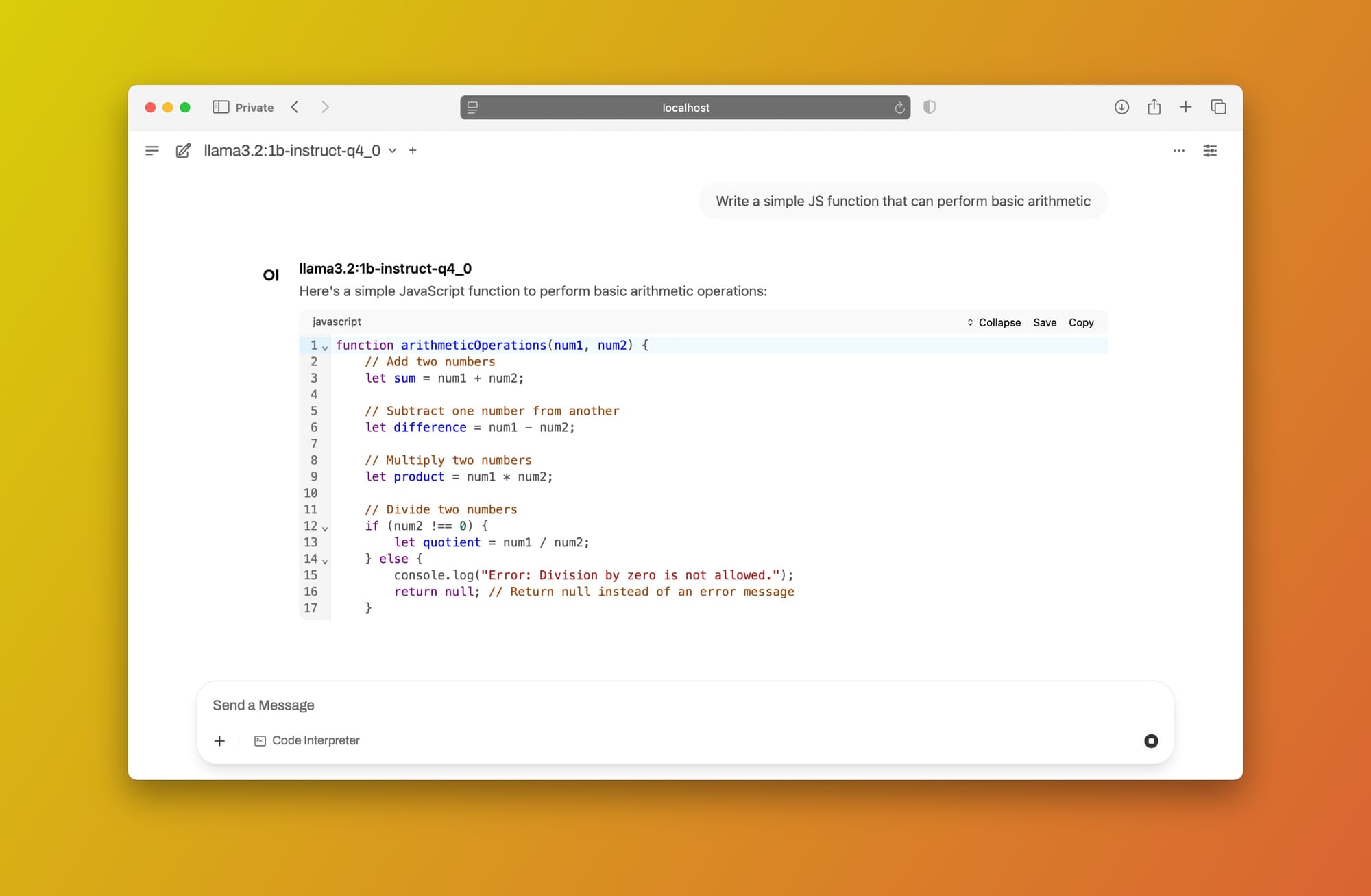
Nhắc nhở llama3.2 sử dụng Open WebUI + Ollama cục bộ
Tuyệt vời! Bạn bây giờ có một giao diện kiểu ChatGPT với tất cả các tính năng bạn cần, được cung cấp bởi một LLM được lưu trữ cục bộ. Bạn có thể sử dụng mô hình này với sự yên tâm, biết rằng thông tin bí mật hoặc riêng tư của bạn không bao giờ rời khỏi máy tính của bạn.
Nếu bạn muốn tìm hiểu cách sử dụng mô hình này trong VS Code như một sự thay thế cho GitHub Copilot, hãy để lại bình luận và cho tôi biết!
Subscribe to my newsletter
Read articles from Justin directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by