Best ETL Tools in 2025
 Community Contribution
Community ContributionTable of contents
- Key Takeaways
- Best ETL Tools Overview
- ETL and Data Integration Basics
- ETL Tool Types
- Choosing an ETL Tool
- Best ETL Tools Detailed Review
- ETL Tools Comparison Table
- Data Integration Trends 2025
- FAQ
- What is the main purpose of an ETL tool?
- How does ETL differ from ELT?
- Are open-source ETL tools safe for business use?
- How do real-time ETL tools benefit organizations?
- What factors should teams consider when choosing an ETL tool?
- Can non-technical users work with ETL tools?
- Do ETL tools support both cloud and on-premises data sources?
- How often should organizations update their ETL pipelines?

Businesses in 2025 rely on the best ETL tools such as AWS Glue, Fivetran, Talend, and Apache NiFi to manage complex data integration needs. ETL adoption continues to rise, with the global market projected to reach $8 billion by 2032. Organizations select ETL tools based on pre-built connectors, ease of use, scalability, pricing, real-time processing, support, and security. Strong data integration ensures better analytics and decision-making across sectors like healthcare, retail, and finance.
Key Takeaways
ETL tools help businesses collect, clean, and move data to support better decisions and analytics.
Top ETL tools in 2025 include cloud-based, open-source, and enterprise solutions, each with unique strengths.
Cloud ETL tools offer easy scaling, real-time processing, and reduce infrastructure costs.
Open-source ETL tools provide flexibility and community support but may need technical skills to manage.
Enterprise ETL tools handle large data volumes with strong security and automation features.
Choosing an ETL tool requires considering usability, scalability, integration options, pricing, and security.
No-code and low-code ETL platforms empower non-technical users to build data pipelines quickly.
Real-time and hybrid ETL solutions enable faster insights by combining instant and batch data processing.
Best ETL Tools Overview
Top ETL Tools List
Many organizations in 2025 rely on a range of ETL solutions to manage their data integration needs. Industry analysts and user surveys highlight several platforms as the most widely recognized ETL tools:
Airbyte offers both open-source and cloud options, making it flexible for different teams.
Fivetran provides automated data pipelines and supports a wide range of connectors.
Stitch stands out for its open-source roots and enterprise-ready features.
Matillion delivers cloud-native ETL with a focus on scalability and ease of use.
These platforms help businesses streamline data integration and support analytics across industries.
The following table summarizes additional leading ETL and data integration tools, their main features, and pricing details:
| ETL Tool | Description | Pricing Details |
| Integrate.io | Popular cloud-based ETL with many connectors (Amazon Redshift, MySQL, Google Cloud). Easy to use. | Starts at $15,000/year with free trial |
| Talend | Offers cloud and on-premises solutions; includes open-source version Talend Open Studio. Drag-and-drop interface. | Starts at $1,170 per user |
| Pentaho Data Integration | Open-source platform, good for AI and IoT integration, strong ease of use. | Community version free; Enterprise pricing on request |
| Saras Analytics | Focused on e-commerce with 200+ connectors, no-code, low-maintenance, great for data consistency. | Starts at $95/month for 5 million rows |
| IBM DataStage | Enterprise-level, graphical interface, suitable for large data volumes. | Pricing not publicly disclosed |
| Stitch | Open-source, automatic updates, enterprise-ready after Talend acquisition. | Free trial; paid plans start at $100 |
| Azure Data Factory | Microsoft’s ETL tool with scheduling and monitoring, fewer connectors but powerful. | Pricing varies by usage |
| AWS Glue | Serverless, ideal for AWS users, powerful but less flexible. | Pricing varies by usage |
| Informatica Powercenter | Reliable, high-performance, complex with steep learning curve. | Pricing not publicly disclosed |
| Oracle Data Integrator | Enterprise ELT tool, large number of connectors, more difficult to learn. | Pricing via estimator |
| dbt | SQL-based transformation workflow, modern, git-based version control. | Free trial; paid plans start at $100/month |
| Fivetran | Automated data platform, charges by data usage, 300+ connectors, 99.9% uptime. | Free plan; paid plans start at $36/month |
| Panoply | Data warehouse with ETL features, 205+ data sources, no-code, includes data visualization. | Pricing not specified |
Why These Tools Lead
The best etl tools in 2025 stand out because they address the most pressing challenges in data integration. Leading platforms like Informatica PowerCenter, IBM DataStage, Talend, AWS Glue, and Azure Data Factory offer advanced features that set them apart.
Many top ETL solutions provide real-time data processing, automated data governance, and strong security. These features help organizations maintain data quality and meet compliance requirements.
Some tools, such as Talend and Matillion, support hybrid environments and integrate with cloud services like AWS, Azure, and Google Cloud. This cloud-native approach allows businesses to scale their data integration efforts quickly. Automated scaling, self-service data preparation, and integration with AI or machine learning tools also make these platforms attractive.
Fivetran and Integrate.io focus on automation and ease of use. They offer pre-built connectors and automated pipeline management, which reduce manual work. Airbyte and Stitch appeal to teams that want open-source flexibility and community support.
Data integration tools that lead the market often combine robust security, user-friendly interfaces, and support for both legacy and modern systems. These strengths help organizations handle growing data volumes and complex analytics needs. As a result, the best etl tools enable companies to unlock the full value of their data.
ETL and Data Integration Basics
What is ETL?
ETL stands for Extract, Transform, Load. This process forms the backbone of modern data workflows. Organizations use ETL to move data through three main stages. First, they extract data from sources such as databases, APIs, or files. Next, they perform data transformation by cleaning, standardizing, validating, and enriching the information. This step ensures consistency and usability. Finally, they load the transformed data into target systems like data warehouses or data lakes.
The ETL process helps unify fragmented data and improves data quality. Companies automate workflows using ETL, making data ready for business intelligence, machine learning, and reporting. By consolidating data from multiple sources, ETL creates a single source of truth. This supports data-driven decision-making across industries. Modern ETL tools often use cloud technologies for scalability and integrate with various storage solutions. These tools enable efficient, reliable, and scalable data management.
ETL plays a vital role in breaking down data silos and automating repetitive tasks. Many organizations rely on ETL to ensure data quality and support advanced analytics.
Data transformation remains a key part of the ETL process. It allows teams to adapt raw data to meet quality, consistency, and structural requirements. As a result, ETL supports a wide range of business needs, from daily reporting to complex machine learning projects. Data engineering tools often include ETL as a core feature, helping teams manage growing data volumes.
Why Data Integration Matters
Data integration brings together information from different sources into a unified view. ETL tools perform critical functions in this process. They extract, transform, and load data, ensuring quality and consistency by applying validation and cleaning rules. This automation allows organizations to handle large volumes of data quickly.
Effective data integration offers several business benefits:
It creates a unified view of data from multiple sources, enabling better business decisions.
ETL filters out noise and redundancy by cleansing and transforming data from diverse systems.
It supports business intelligence by turning raw data into usable information for analytics and visualization.
ETL enables performance management by standardizing data models and tracking business process metrics.
It facilitates integration of existing systems, improving operational efficiency and supporting data-driven decision-making.
Strong data integration also enhances data governance. Organizations establish clear data ownership and access controls, which strengthens security and reduces the risk of unauthorized access. This approach helps companies comply with regulations and improves overall operational efficiency.
ETL Tool Types
Cloud ETL Tools
Cloud-based ETL tools have become essential for organizations that want flexibility and scalability. These tools run on cloud platforms and help users move, transform, and load data without managing physical servers. Cloud-based ETL tools support both technical and non-technical users. They offer pre-built connectors, making it easy to link different data sources. Many cloud-based ETL tools provide strong security features, such as encryption and role-based access control, to meet standards like GDPR and HIPAA.
Cloud-based ETL tools reduce manual work and infrastructure costs. They handle automatic updates and maintenance, which saves time for IT teams.
Some advantages of cloud-based ETL tools include:
Simplified management with all processes in one platform.
Real-time data processing for faster insights.
Compliance with privacy regulations.
However, cloud-based ETL tools may have some drawbacks. Users might notice data latency or delays in data refresh. Some tools offer limited logging or error handling. On-premises solutions, in contrast, give more control over security and may offer lower latency for local data.
| Category | Description | Typical Users / Use Cases |
| Cloud-native ETL | SaaS-based solutions designed for scalable cloud environments. | eCommerce brands, SaaS companies, fast-growing startups. |
Cloud-based ETL tools often lead to cost savings, sometimes reducing expenses by up to 80% compared to on-premises solutions. They also make it easier to connect to many data sources and support remote access.
Open-Source ETL Tools
Open-source ETL tools give organizations control and flexibility. These tools are community-driven and allow users to build custom data pipelines. Technical teams often choose open-source ETL tools when they want to tailor workflows or avoid vendor lock-in. Many open-source ETL tools support both batch and real-time processing.
| ETL Tool | Typical Use Cases and Features |
| Singer | Customizable pipelines, extraction and loading. |
| Airbyte | Data integration, real-time processing, strong community support. |
| dbt | Data transformation, analytics engineering, data modeling. |
| PipelineWise | Data replication, pipeline automation. |
| Meltano | End-to-end integration, orchestration, transformation workflows. |
| Talend Open Studio | Scalable integration, data governance, cloud-native capabilities. |
| Pentaho Data Integration | Batch and real-time processing, low-code interface, data observability. |
Open-source ETL tools offer several benefits:
Data observability for better monitoring.
Cloud-native architecture for efficient scaling.
Low-code interfaces for easier use.
Strong data governance features.
These tools help organizations integrate data from many sources and support data transformation, making them suitable for analytics and reporting.
Enterprise ETL Tools
Enterprise ETL tools serve large organizations with complex data needs. These tools handle high data volumes and connect to many types of systems, including legacy and cloud platforms. Enterprise ETL tools provide advanced data transformation functions, helping teams clean, format, and enrich data.
Key features of enterprise ETL tools include:
Integration with diverse data sources.
Automation and orchestration to reduce manual tasks.
Strong security and compliance for regulatory needs.
Support for schema changes and change data capture.
Flexible deployment options, such as cloud-native or hybrid models.
Observability features like logging and monitoring.
Enterprise ETL tools help organizations maintain data quality and reliability. They support automation, which reduces errors and improves efficiency.
These tools are ideal for businesses that need robust, reliable, and secure data integration at scale.
Hybrid and Real-Time ETL
Hybrid and real-time ETL solutions have become essential for organizations that need both speed and flexibility in their data workflows. These tools combine the strengths of traditional ETL with the capabilities of real-time data integration. Companies often face situations where some data must be processed instantly, while other information can wait for scheduled batch updates. Hybrid ETL tools address this challenge by supporting both approaches in a single platform.
Hybrid ETL tools enable continuous data flow. They allow real-time ingestion for immediate needs and batch processing for deeper analytics. This dual approach helps organizations balance cost, latency, and resource usage. For example, a business might stream critical sales data in real time for instant dashboards, while processing historical sales records in batches during off-peak hours.
Hybrid ETL architectures unify data lakes and warehouses, making it possible to handle both structured and unstructured data efficiently.
Many modern ETL pipelines use frameworks like Apache Spark's Structured Streaming. These frameworks support both batch and streaming workloads, giving teams the flexibility to choose the best method for each use case. Real-time data integration plays a key role in applications such as fraud detection, IoT monitoring, and live customer analytics. Batch ETL remains valuable for large-scale reporting and compliance tasks.
Organizations benefit from hybrid and real-time ETL in several ways:
They unlock faster insights by combining real-time data integration with traditional batch analytics.
They support machine learning pipelines that require real-time inference and batch retraining.
They enable hybrid analytics, offering instant operational insights alongside historical trend analysis.
They optimize costs by streaming only the most urgent data and batching less critical information.
Real-time ETL tools provide low latency and event-driven processing. These features are ideal for time-sensitive applications. Batch ETL tools, on the other hand, handle large volumes of structured data with scheduled processing. Many companies now use both methods together, creating a unified approach to batch and streaming data.
However, hybrid systems can introduce complexity. Teams must ensure data consistency across both batch and streaming pipelines. Careful design and monitoring help maintain data quality and reliability.
Hybrid and real-time ETL solutions empower organizations to make agile, data-driven decisions. By integrating the benefits of both real-time data integration and batch processing, businesses can respond quickly to changing conditions and gain a competitive edge.
Choosing an ETL Tool
Usability
Usability stands as a top priority when selecting an ETL tool. Teams often look for solutions that offer a user-friendly interface and straightforward deployment. Many organizations prefer ETL tools with low-code or no-code options, such as drag-and-drop components. These features help users with limited programming experience build data pipelines quickly. Visual workflow orchestration and clear representations of data flows make it easier to monitor and manage the ETL process.
Comprehensive documentation and intuitive design reduce onboarding time. Tools that support quick deployment with minimal configuration are ideal for time-sensitive projects. For technical users, code-driven ETL tools provide full control over logic and integration with CI/CD pipelines. Cloud-based ETL platforms further improve usability by removing the need for infrastructure management. They often include automatic scaling and serverless architecture, which simplify operations.
A balance between technical flexibility and visual design tools ensures that both technical and non-technical users can work efficiently with ETL solutions.
Scalability
Scalability determines how well an ETL tool can handle growing data volumes and increased user demands. Leading ETL platforms use dynamic resource allocation to optimize computing power. They employ data partitioning and task parallelism to process large datasets efficiently. Distributed computing frameworks allow these tools to manage data across multiple nodes, supporting both vertical and horizontal scaling.
Asynchronous processing improves throughput and responsiveness. Many ETL tools now integrate machine learning and AI to automate resource allocation and maintain data integrity. These features help organizations adapt to changing workloads and business growth. Advanced monitoring and data lineage tracking ensure that performance remains consistent as the data integration environment expands.
Scalable ETL solutions support both batch and real-time processing, making them a strategic choice for modern enterprises.
Integrations
Integration capabilities play a crucial role in the effectiveness of any ETL tool. Top ETL solutions connect with a wide range of data sources and destinations, including REST APIs, relational and NoSQL databases, cloud storage, SaaS applications, data warehouses, and data lakes. Many tools, such as Airbyte, offer dozens of destination connectors, covering cloud data warehouses, databases, and cloud storage.
Connector extensibility allows users to customize or build new connectors as business needs evolve. Integration types include both batch ETL and ELT, supporting structured and unstructured data. Features like change data capture, schema migration, and automation are common. Many ETL tools also integrate with orchestration and transformation platforms, such as dbt and Airflow. Both on-premise and cloud environments are supported, ensuring flexibility for diverse data integration needs.
| ETL Tool | Supported Integrations | Key Features |
| Integrate.io | 200+ connectors for databases, cloud storage, SaaS apps, data warehouses | Low-code interface, scheduling, monitoring, security |
| Apache NiFi | Real-time ingestion from many sources via extensible processors | Visual flow design, scalability, encryption |
| Talend | Pre-built connectors for databases, cloud services, applications | Unified platform, reusable pipelines, governance |
| Matillion | Cloud data warehouses (Redshift, BigQuery, Snowflake) | Cloud-native, scalable, live collaboration |
Strong integration capabilities ensure that an automated data pipeline can connect to all necessary systems, supporting seamless data integration across the organization.
Pricing
Pricing plays a major role when selecting an ETL tool. Organizations often compare costs across cloud-based, open-source, and enterprise solutions. Each type offers a different pricing model and cost structure.
Cloud-based ETL tools usually follow a subscription or pay-as-you-go model. Costs depend on factors such as data volume, number of users, connectors, update frequency, and support level. These tools provide predictable expenses with subscriptions, but usage-based plans can lead to variable monthly bills. Examples include Skyvia, Stitch, and Fivetran.
Open-source ETL tools are generally free to use. They allow teams to access and modify the source code. However, these tools require internal resources for setup, maintenance, and security. Some open-source platforms offer paid support or premium features. Airbyte is a popular example, offering a free core product with optional paid support.
Enterprise ETL solutions come with higher costs. Vendors often use custom pricing based on advanced features, security, and premium support. These tools provide extensive capabilities, better user interfaces, and dedicated services. Hevo and enterprise plans of Skyvia and Stitch fall into this category.
The table below summarizes the main differences in pricing models:
| Pricing Model Type | Cloud-Based ETL Tools | Open-Source ETL Tools | Enterprise ETL Solutions |
| Common Pricing Models | Subscription, Usage-based (pay-as-you-go) | Free, self-hosted; paid support plans | Custom pricing, tiered subscription, premium add-ons |
| Cost Drivers | Data volume, users, connectors, support | Internal resource costs for maintenance | Advanced features, security, premium support |
| Support | Basic included, premium as add-on | Community, paid professional support | 24/7 premium, onboarding, dedicated services |
| Pricing Predictability | Predictable with subscription; variable with usage | Free but indirect costs in maintenance | Often higher and complex, tailored to needs |
Tip: Teams should estimate their expected data volume and support needs before choosing an ETL tool. This helps avoid unexpected costs and ensures the solution fits the organization’s budget.
Security
Security remains a top concern for any ETL process. Organizations must protect sensitive data during extraction, transformation, and loading. Modern ETL tools include several security features to address these needs.
Encryption protects data both at rest and in transit. Strong protocols like AES-256 and TLS keep information safe during storage and transfer.
Role-Based Access Control (RBAC) assigns permissions based on user roles. This limits access and simplifies audits.
Multi-Factor Authentication (MFA) adds extra verification steps, reducing the risk of unauthorized access.
Audit logging and data lineage tracking monitor user actions and data flow. These features support accountability and compliance.
Data masking and tokenization anonymize sensitive information during processing and sharing.
Compliance automation helps organizations meet regulations such as GDPR, HIPAA, and CCPA.
Automated retention and deletion policies enforce data lifecycle management.
Integration with cloud Key Management Services (KMS) ensures secure encryption key handling.
Endpoint filtering and validation secure entry points and prevent attacks.
Granular access control and regular permission reviews maintain a strong security posture.
Many ETL tools also use authentication protocols like Kerberos and centralized key management. These layered measures ensure confidentiality, integrity, and regulatory compliance throughout the ETL pipeline.
Note: Security features should match the sensitivity of the data and the organization’s compliance requirements. Regular reviews and updates help maintain a secure ETL environment.
Best ETL Tools Detailed Review
AWS Glue
Overview
AWS Glue is a fully managed ETL service designed for cloud-native data integration. It operates within the Amazon Web Services ecosystem and supports serverless operations. Many organizations choose AWS Glue for its seamless integration with other AWS services. The platform helps users extract, transform, and load data from various sources into data lakes or warehouses. AWS Glue simplifies metadata management and automates much of the ETL workflow, making it a strong choice for businesses already invested in AWS.
Features
Centralized metadata management through AWS Glue Data Catalog
Serverless architecture for automatic scaling
70+ pre-built data sources and connectors
Native integration with Amazon S3, Redshift, RDS, and other AWS services
Support for both ETL and ELT workflows
Built-in job scheduling and workflow orchestration
Python and Scala support for custom data transformation scripts
Automated schema discovery and data profiling
Pros and Cons
| Pros | Cons |
| Seamless integration with AWS ecosystem | May require technical expertise for integration outside AWS |
| Serverless and scalable | Limited flexibility for non-AWS environments |
| Centralized metadata and automated schema discovery | Learning curve for advanced features |
| 70+ pre-built connectors | Usage-based pricing can be unpredictable |
Many users praise AWS Glue for its tight integration with AWS services and its ability to automate complex ETL tasks. However, some report that working outside the AWS ecosystem can require additional technical resources.
Pricing
AWS Glue uses a usage-based billing model. Users pay for the compute resources consumed during ETL jobs and for metadata storage. The first million objects stored in the Data Catalog are free each month. Additional charges apply for data processing and development endpoints. This model allows organizations to scale costs with usage, but monthly bills can vary depending on workload.
Fivetran
Overview
Fivetran is a cloud-based ETL platform known for its automated data pipelines and extensive connector library. The platform focuses on simplifying data integration by offering over 300 pre-built connectors. Fivetran supports real-time change data capture (CDC), enabling continuous data movement from source systems to destinations like data warehouses. Many businesses select Fivetran for its reliability and minimal maintenance requirements.
Features
300+ pre-built connectors for databases, SaaS applications, and cloud storage
Real-time CDC for near-instant data updates
Automated schema migration and pipeline maintenance
Consumption-based pricing with a free plan for small workloads
Secure data transfer with encryption in transit and at rest
Centralized monitoring and alerting dashboard
No-code setup for most connectors
Integration with major cloud data warehouses
Pros and Cons
| Pros | Cons |
| Extensive connector library | No data transformation before loading |
| Real-time CDC for fast data updates | May be complex for non-technical users |
| Automated pipeline management reduces manual work | Consumption-based pricing can be unpredictable |
| Strong technical support and documentation | Limited transformation capabilities within platform |
Fivetran receives strong reviews for its technical focus and ability to handle multi-system workflows. Users appreciate the platform's reliability and connector breadth, but some note that it lacks built-in data transformation before loading.
Pricing
Fivetran offers a consumption-based pricing model. Users can start with a free plan that includes limited data volume and connectors. Paid plans scale with data usage and offer a free trial. This approach provides flexibility for organizations of different sizes, but costs can increase with higher data volumes.
Talend Open Studio
Overview
Talend Open Studio is an open-source ETL tool that supports both ETL and ELT workflows. It provides a graphical interface for designing data pipelines and offers over 1,000 connectors for various data sources. Talend Open Studio appeals to technical users who want flexibility and control over their data integration processes. The platform works well for both structured and unstructured data, making it suitable for hybrid environments.
Features
Open-source and free to use
1,000+ connectors for databases, cloud services, and applications
Drag-and-drop graphical interface for pipeline design
Support for both ETL and ELT workflows
Data quality and data governance tools
Integration with big data platforms and cloud environments
Custom scripting with Java and other languages
Community support and extensive documentation
Pros and Cons
| Pros | Cons |
| Free and open-source | Complexity may challenge non-technical users |
| Robust and reliable for technical teams | Paid versions can be costly |
| Supports unstructured data and hybrid environments | Steeper learning curve for beginners |
| Large connector library | Community support may not meet enterprise needs |
Users describe Talend Open Studio as reliable and robust, especially for technical teams. The platform's flexibility and open-source nature attract organizations seeking customizable ETL solutions. However, non-technical users may find the interface and setup process challenging.
Pricing
Talend Open Studio is free as an open-source product. Organizations can access paid versions with additional features, enterprise support, and advanced data governance. Pricing for these versions is private and may be costly for larger deployments.
User Ratings and Comparison
The following table summarizes recent user satisfaction ratings and key features for AWS Glue, Fivetran, and Talend Open Studio:
| Product | User Rating (G2) | Key Features | Pricing Model | User Review Summary |
| AWS Glue | 4.2/5 | Centralized metadata, AWS-native, serverless | Usage-based billing | Praised for AWS integration; 70+ data sources; may need technical resources for non-AWS integration |
| Fivetran | 4.2/5 | ETL, real-time CDC, 300+ connectors | Consumption-based; free plan | Strong technical focus; extensive connectors; no transformation before loading; complex for some users |
| Talend Open Studio | 4.0/5 | Open-source, ELT/ETL, 1000+ connectors | Free (open-source); paid versions | Reliable and robust; suitable for technical users; complexity for non-technical users |
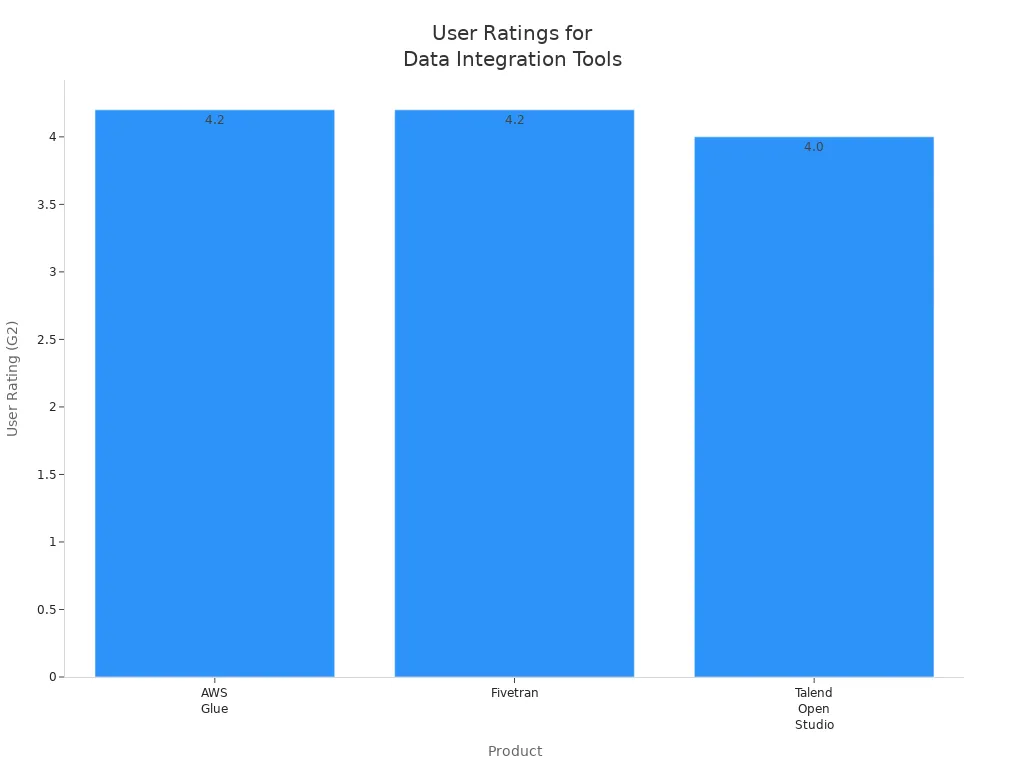
These three platforms rank among the best etl tools for organizations seeking scalable, flexible, and reliable data integration. Each tool offers unique strengths in ETL, connector support, and data transformation capabilities.
Informatica
Overview
Informatica stands as a leader in enterprise data integration. Many large organizations trust Informatica for its robust ETL capabilities. The platform supports both on-premises and cloud deployments. Informatica PowerCenter, its flagship product, handles complex data workflows and large-scale data movement. Informatica offers a suite of tools for data quality, data governance, and master data management. Companies in finance, healthcare, and retail often choose Informatica for its reliability and advanced features.
Features
Comprehensive Data Integration: Informatica connects to a wide range of data sources, including databases, cloud storage, and SaaS applications.
Advanced Data Transformation: The platform provides a rich set of transformation functions for data cleansing, enrichment, and validation.
Scalability: Informatica processes large volumes of data efficiently. It supports both batch and real-time data integration.
Data Governance and Quality: Built-in tools help organizations maintain high data quality and comply with regulations.
Workflow Orchestration: Users can design, schedule, and monitor complex ETL workflows with visual tools.
Cloud and Hybrid Support: Informatica integrates with major cloud providers such as AWS, Azure, and Google Cloud.
Security: The platform includes encryption, role-based access control, and audit logging.
Informatica’s automation features reduce manual work and help teams focus on strategic data initiatives.
Pros and Cons
| Pros | Cons |
| Enterprise-grade scalability | High cost for enterprise licenses |
| Extensive connector library | Steep learning curve for new users |
| Strong data governance and compliance | Complex setup and configuration |
| Reliable performance for large data volumes | Resource-intensive for smaller organizations |
| Flexible deployment options | Some features only available in premium tiers |
Pricing
Informatica uses a custom pricing model. Organizations must contact the sales team for a quote. Pricing depends on deployment type, data volume, and required features. Informatica offers both subscription and perpetual licensing. Cloud-based solutions use a pay-as-you-go model. Enterprise licenses can be expensive, but they include premium support and advanced features.
Airbyte
Overview
Airbyte has gained popularity as an open-source data integration platform. Many data teams choose Airbyte for its flexibility and active community. The platform supports both cloud and self-hosted deployments. Airbyte focuses on making data integration accessible and customizable. Users can build and maintain connectors with ease. The platform appeals to organizations that want control over their ETL pipelines.
Features
Open-Source Core: Airbyte’s codebase is open to everyone. Users can modify and extend the platform as needed.
Connector Library: The platform offers hundreds of pre-built connectors for databases, APIs, and cloud services.
Custom Connector Development: Teams can create new connectors using Airbyte’s developer framework.
Real-Time and Batch Processing: Airbyte supports both streaming and scheduled data syncs.
Data Observability: Built-in monitoring tools help users track pipeline health and data quality.
Cloud and Self-Hosted Options: Organizations can deploy Airbyte in the cloud or on their own infrastructure.
Community Support: An active community contributes new connectors and features regularly.
Airbyte’s modular design allows organizations to scale their data integration efforts as their needs grow.
Pros and Cons
| Pros | Cons |
| Free and open-source | Requires technical expertise for setup |
| Rapidly growing connector ecosystem | Limited enterprise support in free version |
| Flexible deployment options | Some connectors may lack advanced features |
| Strong community involvement | Documentation can be inconsistent |
| Easy to build custom connectors | New features may be less stable |
Pricing
Airbyte’s core platform is free and open-source. Organizations can use the self-hosted version at no cost. Airbyte Cloud offers managed services with additional features and support. Pricing for Airbyte Cloud starts with a free tier and scales based on data volume and connector usage. Paid plans include premium support, advanced monitoring, and SLAs.
Matillion
Overview
Matillion provides a cloud-native ETL solution designed for modern data teams. The platform integrates closely with popular cloud data warehouses. Matillion focuses on usability and scalability. Many organizations use Matillion to build, schedule, and manage data pipelines in the cloud. The platform supports both technical and non-technical users with its intuitive interface.
Features
Cloud-Native Architecture: Matillion runs directly within cloud environments such as AWS, Azure, and Google Cloud.
Visual Workflow Designer: Users can create ETL pipelines using a drag-and-drop interface.
Pre-Built Connectors: The platform connects to a wide range of data sources, including SaaS apps and databases.
Scalable Processing: Matillion handles large data volumes and supports parallel processing.
Job Scheduling and Orchestration: Users can automate data workflows and monitor job status in real time.
Integration with Data Warehouses: Matillion works seamlessly with Snowflake, Redshift, BigQuery, and Databricks.
Collaboration Tools: Teams can share projects and manage permissions easily.
Matillion’s user-friendly design helps organizations accelerate their cloud data integration projects.
Pros and Cons
| Pros | Cons |
| Easy-to-use visual interface | Pricing can increase with usage |
| Deep integration with cloud data warehouses | Limited on-premises support |
| Fast deployment and setup | Some advanced features require technical skills |
| Scalable for large data workloads | Fewer connectors than some competitors |
| Good documentation and support | Custom connector development is limited |
Pricing
Matillion uses a consumption-based pricing model. Organizations pay based on the number of virtual credits used for data processing. Pricing varies by cloud provider and data volume. Matillion offers a free trial for new users. Paid plans include premium support and advanced features. Users can estimate costs using the Matillion pricing calculator on the company’s website.
Hevo
Overview
Hevo stands as a cloud-based ETL platform that focuses on simplicity and automation. Many organizations use Hevo to move data from multiple sources into data warehouses without writing code. Hevo supports real-time data integration and offers a user-friendly interface. Companies in e-commerce, SaaS, and finance often choose Hevo for its quick setup and managed infrastructure. Hevo helps teams build reliable data pipelines with minimal maintenance.
Features
No-Code Data Pipelines: Hevo allows users to create data pipelines without programming knowledge.
Real-Time Data Replication: The platform supports continuous data sync, ensuring up-to-date analytics.
Pre-Built Connectors: Hevo provides over 150 connectors for databases, SaaS applications, and cloud storage.
Automated Schema Mapping: The system detects schema changes and adjusts pipelines automatically.
Data Transformation: Hevo offers transformation features using Python, SQL, and drag-and-drop tools.
Monitoring and Alerts: Users receive notifications for pipeline failures or delays.
Data Quality Checks: Built-in validation ensures accurate and consistent data.
Security: Hevo uses encryption, role-based access, and compliance with GDPR and SOC 2.
Hevo’s automation features help teams focus on analysis instead of pipeline management.
Pros and Cons
| Pros | Cons |
| Easy setup and no-code interface | Limited advanced transformation options |
| Real-time data sync | Pricing increases with data volume |
| Wide range of connectors | Some connectors may lack customization |
| Automated schema handling | Fewer features for on-premises deployment |
| Strong monitoring and alerting | Limited open-source flexibility |
Pricing
Hevo uses a tiered subscription model. Pricing depends on the number of events processed each month. The platform offers a free trial with limited data volume. Paid plans start at around $239 per month for basic features and increase with higher data volumes or premium support. Hevo provides custom pricing for enterprise customers. Users can estimate costs using the pricing calculator on the Hevo website.
Apache NiFi
Overview
Apache NiFi is an open-source data integration tool developed by the Apache Software Foundation. Many organizations use NiFi for its powerful data flow automation and visual interface. NiFi supports both batch and real-time data movement. The platform excels in scenarios that require complex routing, transformation, and system integration. Government agencies, healthcare providers, and large enterprises often rely on NiFi for secure and scalable data workflows.
Features
Visual Flow-Based Programming: NiFi uses a drag-and-drop interface for designing data flows.
Extensive Processor Library: The platform includes hundreds of processors for data ingestion, transformation, and routing.
Real-Time and Batch Processing: NiFi handles streaming and scheduled data transfers.
Data Provenance: The system tracks data lineage for auditing and troubleshooting.
Scalability: NiFi supports clustering for high availability and large-scale deployments.
Security: Features include SSL encryption, user authentication, and access control.
Back Pressure and Prioritization: NiFi manages data flow rates to prevent overload.
Integration: The platform connects to databases, cloud services, IoT devices, and messaging systems.
Apache NiFi’s visual approach makes complex data flows easier to manage and monitor.
Pros and Cons
| Pros | Cons |
| Open-source and free to use | Steep learning curve for beginners |
| Powerful visual interface | Resource-intensive for large deployments |
| Flexible data routing and transformation | Limited built-in data quality tools |
| Strong security and data provenance | Requires manual scaling and tuning |
| Active community and regular updates | Documentation can be complex |
Pricing
Apache NiFi is free and open-source. Organizations can download and deploy NiFi without licensing fees. Some companies choose commercial support or managed services from third-party vendors. These services offer additional features, support, and cloud hosting. Costs for managed NiFi solutions vary by provider and deployment size.
RisingWave
Overview
RisingWave is a modern streaming database designed for real-time data processing and analytics. The platform enables organizations to build real-time ETL pipelines with SQL. RisingWave focuses on simplicity, scalability, and low-latency analytics. Many companies use RisingWave to power dashboards, alerts, and machine learning applications that require instant insights.
Features
Streaming SQL Engine: RisingWave allows users to write SQL queries for real-time data transformation.
Low-Latency Processing: The platform delivers sub-second response times for streaming analytics.
Horizontal Scalability: RisingWave scales out across multiple nodes to handle large data streams.
Integration: The system connects to popular message queues, databases, and cloud storage.
Fault Tolerance: RisingWave recovers from failures automatically to ensure data reliability.
Materialized Views: Users can create persistent views for fast query results.
Cloud-Native Deployment: The platform runs on Kubernetes and integrates with cloud infrastructure.
Monitoring and Metrics: RisingWave provides dashboards for tracking performance and health.
RisingWave’s streaming-first architecture helps organizations react to data changes in real time.
Pros and Cons
| Pros | Cons |
| Real-time analytics with SQL | Newer platform with smaller community |
| High scalability and fault tolerance | Limited support for batch ETL |
| Easy integration with modern data stacks | Fewer connectors than established tools |
| Cloud-native and Kubernetes support | Documentation still evolving |
| Fast materialized views | Enterprise features still under development |
Pricing
RisingWave offers an open-source community edition that is free to use. The company provides a managed cloud service with usage-based pricing. Costs depend on data volume, compute resources, and required support. RisingWave’s website includes a pricing calculator for managed deployments. Enterprise customers can request custom quotes for advanced features and dedicated support.
Microsoft Azure Data Factory
Overview
Microsoft Azure Data Factory (ADF) stands as a cloud-based data integration service. Many organizations use ADF to create, schedule, and orchestrate data pipelines. The platform supports both ETL and ELT processes. ADF works well for moving data between on-premises systems and cloud environments. Microsoft designed ADF to integrate with other Azure services, making it a strong choice for businesses invested in the Azure ecosystem.
Features
Visual Pipeline Designer: Users can build data workflows using a drag-and-drop interface. This feature helps both technical and non-technical users.
Wide Connector Support: ADF connects to over 90 data sources, including SQL databases, Azure Blob Storage, and SaaS applications.
Data Flow and Transformation: The platform provides built-in data transformation tools. Users can clean, aggregate, and join data without writing code.
Hybrid Data Integration: ADF supports data movement between on-premises and cloud systems. This flexibility helps organizations with mixed environments.
Scalability: The service scales automatically to handle large data volumes.
Monitoring and Management: ADF includes real-time monitoring dashboards. Users can track pipeline performance and set up alerts.
Security: The platform uses Azure Active Directory for authentication. Data encryption protects information at rest and in transit.
Azure Data Factory helps organizations modernize their data integration with cloud-native tools and automation.
Pros and Cons
| Pros | Cons |
| Deep integration with Azure services | Learning curve for new users |
| Visual interface simplifies pipeline design | Limited connectors compared to some rivals |
| Supports both ETL and ELT workflows | Advanced features may require coding |
| Scales for enterprise workloads | Pricing can be complex to estimate |
| Strong security and compliance | Best suited for Azure-centric environments |
Pricing
Azure Data Factory uses a pay-as-you-go pricing model. Costs depend on pipeline activities, data movement, and data flow execution. Microsoft charges separately for data integration runtime and data pipeline orchestration. Users can estimate costs with the Azure Pricing Calculator. Small projects may see low costs, but large-scale deployments can become expensive. ADF offers a free tier with limited activity runs each month.
dbt
Overview
dbt (data build tool) has become a popular choice for data transformation in analytics engineering. The platform focuses on transforming data inside cloud data warehouses. dbt uses SQL and a command-line interface, making it accessible to data analysts and engineers. Many teams use dbt to manage, test, and document their data models. dbt works well with modern ELT workflows.
Features
SQL-Based Transformations: Users write SQL queries to define data models and transformations.
Version Control Integration: dbt integrates with Git, allowing teams to track changes and collaborate.
Automated Testing: The platform includes built-in tests for data quality and integrity.
Documentation Generation: dbt creates documentation from code and metadata. Teams can share this documentation with stakeholders.
Modular Project Structure: dbt organizes projects into reusable models and macros.
Cloud and Open-Source Options: dbt offers both a free open-source version and a managed cloud service.
Integration with Major Warehouses: dbt works with Snowflake, BigQuery, Redshift, Databricks, and more.
dbt empowers data teams to build reliable, maintainable, and transparent analytics pipelines.
Pros and Cons
| Pros | Cons |
| Strong support for analytics engineering | No data extraction or loading capabilities |
| Encourages best practices in data modeling | Requires knowledge of SQL |
| Automated testing improves data quality | Command-line interface may challenge some |
| Excellent documentation tools | Limited to supported data warehouses |
| Active community and open-source foundation | Transformation only, not full ETL |
Pricing
dbt offers a free open-source version for self-hosted projects. dbt Cloud provides managed services with additional features, such as a web-based IDE, job scheduling, and team collaboration tools. dbt Cloud pricing starts with a free tier for individuals. Paid plans begin at around $100 per month per developer seat. Enterprise plans include advanced security, support, and SLAs. Users can choose the option that fits their team size and needs.
Rivery
Overview
Rivery is a cloud-native ETL platform designed for fast and flexible data integration. The platform targets businesses that want to automate data workflows without heavy coding. Rivery supports both ETL and ELT processes. Many organizations use Rivery to connect cloud data sources, automate data ingestion, and manage transformations. The platform appeals to companies seeking a managed, scalable solution.
Features
No-Code and Low-Code Interface: Users can build data pipelines with a visual editor. This feature reduces the need for programming skills.
Pre-Built Data Connectors: Rivery offers over 200 connectors for databases, SaaS apps, and cloud storage.
Automated Data Workflows: The platform schedules and orchestrates data pipelines. Users can set triggers and dependencies.
Data Transformation: Rivery supports SQL-based transformations and Python scripts.
Multi-Cloud Support: The platform integrates with AWS, Azure, and Google Cloud.
Monitoring and Alerts: Real-time dashboards help users track pipeline health and performance.
Security and Compliance: Rivery uses encryption, role-based access, and complies with GDPR and SOC 2.
Rivery helps organizations accelerate analytics by automating data integration and reducing manual work.
Pros and Cons
| Pros | Cons |
| Easy-to-use interface for all skill levels | Pricing may be high for large data volumes |
| Wide range of connectors | Some advanced features require coding |
| Strong automation and scheduling | Limited on-premises deployment options |
| Multi-cloud flexibility | Smaller community than open-source tools |
| Good monitoring and alerting | Custom connector development is limited |
Pricing
Rivery uses a consumption-based pricing model. Costs depend on the number of data processing units (DPUs) used each month. The platform offers a free trial for new users. Paid plans start at around $1,200 per month, with custom pricing for enterprise needs. Rivery provides volume discounts for high-usage customers. Users can estimate costs with the Rivery pricing calculator on the company’s website.
Skyvia
Overview
Skyvia stands as a cloud-based data integration platform. Many businesses use Skyvia for ETL, ELT, and data backup tasks. The platform supports both technical and non-technical users. Skyvia offers a no-code interface that helps users build data pipelines quickly. Companies often choose Skyvia for its flexibility and ease of use. The platform connects to a wide range of cloud services and databases.
Features
No-Code Data Integration: Skyvia provides a drag-and-drop interface. Users can create data pipelines without writing code.
Wide Connector Support: The platform connects to over 100 cloud apps and databases, including Salesforce, MySQL, and Google BigQuery.
Data Synchronization: Skyvia supports both one-way and bi-directional data sync.
Data Backup and Restore: Users can schedule automatic backups for cloud data and restore it when needed.
Data Import and Export: The platform allows users to import and export data in various formats, such as CSV and Excel.
Cloud-to-Cloud and Cloud-to-Database Integration: Skyvia enables data movement between different cloud services and on-premises databases.
Scheduling and Automation: Users can automate data workflows with flexible scheduling options.
Data Security: The platform uses encryption and secure connections to protect data.
Skyvia’s no-code approach makes data integration accessible to users with limited technical skills.
Pros and Cons
| Pros | Cons |
| User-friendly interface | Limited advanced transformation features |
| Supports many connectors | Performance may drop with large datasets |
| Flexible scheduling and automation | Some features require higher-tier plans |
| Reliable data backup and restore | Custom connector development is limited |
| Affordable entry-level pricing | Less suitable for complex enterprise needs |
Pricing
Skyvia uses a tiered subscription model. The platform offers a free plan with basic features and limited data volume. Paid plans start at $15 per month and increase with more connectors, higher data volume, and advanced features. Enterprise plans provide premium support and custom options. Users can try Skyvia with a free trial before committing to a paid plan.
Portable.io
Overview
Portable.io is a cloud-based ETL platform that focuses on long-tail SaaS integrations. The platform helps businesses connect to hundreds of niche SaaS applications. Portable.io stands out by building custom connectors on demand. Many organizations use Portable.io to automate data movement from less common sources into their data warehouses.
Features
Custom Connector Development: Portable.io builds new connectors for clients within days. This feature helps businesses integrate unique or rare SaaS tools.
No-Code Pipeline Creation: Users can set up data pipelines without writing code.
Automated Data Sync: The platform schedules and automates data extraction and loading.
Support for Major Data Warehouses: Portable.io integrates with Snowflake, BigQuery, Redshift, and other popular destinations.
Monitoring and Alerts: Users receive notifications about pipeline status and errors.
Secure Data Handling: The platform uses encryption and secure authentication for all data transfers.
Scalable Infrastructure: Portable.io handles growing data volumes without manual intervention.
Portable.io’s focus on custom connectors fills a gap for businesses with unique integration needs.
Pros and Cons
| Pros | Cons |
| Rapid custom connector delivery | Limited transformation capabilities |
| No-code setup for pipelines | Smaller connector library for mainstream apps |
| Strong support for niche SaaS tools | Pricing may rise with many custom connectors |
| Automated scheduling and monitoring | Less suitable for highly technical teams |
| Good integration with major data warehouses | Newer platform with smaller user community |
Pricing
Portable.io uses a usage-based pricing model. The platform offers a free trial for new users. Pricing depends on the number of connectors, data volume, and frequency of data syncs. Custom connector development may incur additional fees. Businesses can contact Portable.io for a detailed quote based on their integration needs.
Apache Hop
Overview
Apache Hop is an open-source data orchestration and ETL platform. The Apache Software Foundation maintains the project. Many data engineers use Apache Hop to design, manage, and monitor complex data workflows. The platform supports both batch and streaming data processing. Apache Hop appeals to organizations that want flexibility and control over their ETL pipelines.
Features
Visual Pipeline Designer: Apache Hop provides a graphical interface for building data workflows.
Extensible Architecture: Users can add plugins and custom scripts to extend functionality.
Support for Batch and Streaming: The platform handles both scheduled and real-time data processing.
Integration with Big Data Tools: Apache Hop works with Apache Beam, Spark, and Flink.
Metadata-Driven Design: The system manages workflows using metadata, which improves reusability.
Cross-Platform Support: Apache Hop runs on Windows, macOS, and Linux.
Active Community: The open-source community contributes plugins, documentation, and support.
Apache Hop’s open-source model gives organizations full control over their data integration environment.
Pros and Cons
| Pros | Cons |
| Free and open-source | Steep learning curve for beginners |
| Highly customizable with plugins | Requires technical expertise |
| Supports both batch and streaming workflows | Limited commercial support |
| Integrates with big data frameworks | User interface may feel less modern |
| Strong community involvement | Documentation can be inconsistent |
Pricing
Apache Hop is free to use under the Apache License. Organizations can download and deploy the platform without licensing fees. Commercial support is available from third-party vendors. These vendors may offer training, consulting, and managed services for an additional cost. Most users rely on community support and documentation for help with setup and troubleshooting.
Singer
Overview
Singer provides an open-source standard for writing scripts that move data between databases, web APIs, and files. Data engineers and analysts use Singer to build modular ETL pipelines. The platform uses two main components: "Taps" extract data from sources, and "Targets" load data into destinations. Singer's design encourages reusability and community sharing. Many organizations choose Singer for its flexibility and strong open-source ecosystem.
Features
Modular Architecture: Singer separates extraction and loading into independent modules. Users can mix and match Taps and Targets for different workflows.
JSON-Based Data Streams: Singer uses JSON to move data between Taps and Targets. This approach simplifies data handling and debugging.
Wide Connector Library: The community has created many Taps and Targets for popular databases, SaaS apps, and file formats.
Command-Line Interface: Users run Singer pipelines from the command line. This feature supports automation and scripting.
Extensibility: Developers can write custom Taps or Targets in Python. Singer's open specification makes it easy to contribute new connectors.
Community Support: Singer benefits from an active open-source community. Users share connectors, documentation, and troubleshooting tips.
Singer's modular approach helps teams build custom ETL solutions without starting from scratch.
Pros and Cons
| Pros | Cons |
| Free and open-source | Requires Python skills for custom connectors |
| Large library of community connectors | Limited official support |
| Flexible and modular design | No built-in scheduling or orchestration |
| Easy to extend with new Taps/Targets | Documentation varies by connector |
| Works well with other ETL tools | Some connectors may lack maintenance |
Pricing
Singer is free to use under the Apache 2.0 license. Users can download, modify, and deploy Singer without cost. Organizations may incur indirect costs for development, maintenance, or third-party support. Many companies pair Singer with orchestration tools like Airflow for production use.
Airflow
Overview
Apache Airflow is an open-source platform for orchestrating complex data workflows. Data engineers use Airflow to schedule, monitor, and manage ETL pipelines. Airflow organizes workflows as Directed Acyclic Graphs (DAGs), where each node represents a task. The platform supports both batch and streaming data processes. Many organizations rely on Airflow for its flexibility and strong community support.
Features
Workflow Orchestration: Airflow manages dependencies between tasks. Users define workflows as Python code.
Extensible Operators: The platform includes operators for databases, cloud services, and APIs. Users can create custom operators for unique tasks.
Scheduling: Airflow schedules workflows to run at specific times or intervals.
Monitoring and Logging: The web-based UI displays workflow status, logs, and execution history.
Scalability: Airflow supports distributed execution across multiple workers.
Integration: Airflow connects with ETL tools, cloud platforms, and data warehouses.
Community Plugins: The ecosystem offers many plugins for new integrations and features.
Airflow gives teams control over every step of the data pipeline, from extraction to loading.
Pros and Cons
| Pros | Cons |
| Highly flexible and customizable | Steep learning curve for beginners |
| Strong community and plugin ecosystem | Requires Python programming knowledge |
| Scalable for large workflows | Manual setup and configuration needed |
| Detailed monitoring and logging | No built-in data connectors |
| Open-source and free to use | Can become complex for simple ETL tasks |
Pricing
Airflow is free and open-source under the Apache 2.0 license. Users can run Airflow on their own infrastructure at no cost. Managed Airflow services, such as Google Cloud Composer or Astronomer, charge based on usage, resources, and support. Organizations should consider costs for hardware, cloud resources, and maintenance when deploying Airflow at scale.
Estuary
Overview
Estuary offers a real-time data integration platform focused on streaming ETL. The platform helps organizations move data continuously between sources and destinations. Estuary uses a cloud-native architecture and supports both structured and semi-structured data. Many companies choose Estuary for its low-latency streaming and ease of use.
Features
Real-Time Data Streaming: Estuary moves data with minimal delay. This feature supports instant analytics and event-driven applications.
Pre-Built Connectors: The platform provides connectors for databases, cloud storage, SaaS apps, and message queues.
Schema Evolution: Estuary adapts to changes in data structure automatically.
No-Code Interface: Users can set up pipelines without writing code. The visual interface simplifies configuration and monitoring.
Data Transformation: Estuary supports in-stream transformations using SQL or built-in functions.
Scalability: The platform handles high data volumes and scales with demand.
Monitoring and Alerts: Users receive real-time notifications about pipeline health and performance.
Estuary enables organizations to react to data changes as they happen, supporting modern analytics and automation.
Pros and Cons
| Pros | Cons |
| Real-time streaming with low latency | Newer platform with smaller user base |
| No-code setup for fast deployment | Fewer connectors than legacy ETL tools |
| Automatic schema handling | Advanced features may require paid plans |
| Scalable and cloud-native | Documentation still growing |
| Supports both structured and semi-structured data | Less community support than open-source leaders |
Pricing
Estuary uses a usage-based pricing model. The platform offers a free tier with limited data volume and connectors. Paid plans scale with data throughput, number of pipelines, and advanced features. Organizations can contact Estuary for enterprise pricing and custom support. The company provides a pricing calculator on its website to help estimate costs.
Oracle Data Integrate
Overview
Oracle Data Integrate stands as a comprehensive data integration platform from Oracle. Many enterprises use this tool to manage ETL, ELT, and data migration tasks. Oracle Data Integrate supports both cloud and on-premises environments. The platform helps organizations move, transform, and synchronize data across databases, applications, and data warehouses. Oracle designed this tool for scalability and reliability in large-scale enterprise settings.
Features
Broad Connectivity: Oracle Data Integrate connects to a wide range of Oracle and non-Oracle databases, cloud services, and applications.
Advanced Data Transformation: The platform provides a rich set of transformation functions for cleansing, enriching, and validating data.
Real-Time and Batch Processing: Users can run both scheduled batch jobs and real-time data integration tasks.
Workflow Orchestration: The tool offers visual workflow design, scheduling, and monitoring.
Data Quality and Governance: Built-in tools help maintain high data quality and support regulatory compliance.
Hybrid Deployment: Oracle Data Integrate works in cloud, on-premises, or hybrid environments.
Security: The platform includes encryption, access controls, and auditing features.
Oracle Data Integrate helps organizations unify data from multiple sources, supporting analytics and business intelligence.
Pros and Cons
| Pros | Cons |
| Strong integration with Oracle ecosystem | Steep learning curve for new users |
| Scalable for large enterprise workloads | Pricing can be high for small businesses |
| Supports hybrid and multi-cloud deployments | Complex setup and configuration |
| Advanced data governance and quality tools | Best suited for organizations using Oracle |
| Reliable performance and security | Some features require premium licenses |
Pricing
Oracle Data Integrate uses a custom pricing model. Organizations must contact Oracle for a quote. Pricing depends on deployment type, data volume, and required features. Oracle offers both subscription and perpetual licensing. Cloud-based deployments use a pay-as-you-go model. Enterprise licenses include advanced features and premium support.
Hadoop
Overview
Hadoop is an open-source framework for distributed storage and processing of large data sets. The Apache Software Foundation maintains Hadoop. Many organizations use Hadoop to manage big data workloads. Hadoop uses a cluster of computers to store and process data in parallel. The platform supports both ETL and analytics tasks.
Features
Distributed Storage: Hadoop uses the Hadoop Distributed File System (HDFS) to store data across many nodes.
Parallel Processing: The platform processes data using the MapReduce programming model.
Scalability: Hadoop scales horizontally by adding more nodes to the cluster.
Fault Tolerance: The system replicates data across nodes to prevent data loss.
Open-Source Ecosystem: Hadoop integrates with tools like Hive, Pig, Spark, and HBase.
Batch Processing: The platform excels at processing large volumes of structured and unstructured data.
Flexible Deployment: Organizations can deploy Hadoop on-premises or in the cloud.
Hadoop enables organizations to process petabytes of data efficiently and cost-effectively.
Pros and Cons
| Pros | Cons |
| Handles massive data volumes | Steep learning curve for beginners |
| Open-source and free to use | Complex setup and maintenance |
| Highly scalable and fault-tolerant | Not ideal for real-time processing |
| Strong ecosystem of related tools | Requires significant hardware resources |
| Flexible for many data types | Performance tuning can be challenging |
Pricing
Hadoop itself is free and open-source. Organizations pay for hardware, cloud resources, and maintenance. Many cloud providers offer managed Hadoop services, such as Amazon EMR or Azure HDInsight. These services charge based on compute, storage, and usage. Costs vary depending on cluster size and workload.
SQL Server Integration Services (SSIS)
Overview
SQL Server Integration Services (SSIS) is a data integration tool from Microsoft. SSIS helps organizations extract, transform, and load data across databases, files, and cloud services. The platform is part of Microsoft SQL Server. Many businesses use SSIS for ETL, data migration, and workflow automation.
Features
Visual Workflow Designer: SSIS provides a drag-and-drop interface for building data pipelines.
Wide Data Source Support: The tool connects to SQL Server, Oracle, flat files, Excel, and more.
Data Transformation: SSIS offers built-in transformations for cleansing, merging, and aggregating data.
Scheduling and Automation: Users can schedule ETL jobs and automate workflows.
Error Handling and Logging: The platform includes robust error handling and detailed logging.
Integration with Microsoft Ecosystem: SSIS works seamlessly with other Microsoft products, such as Azure and Power BI.
Security: The tool supports encryption, authentication, and role-based access.
SSIS provides a reliable solution for organizations invested in the Microsoft data stack.
Pros and Cons
| Pros | Cons |
| Easy-to-use visual interface | Windows-only deployment |
| Strong integration with Microsoft products | Limited support for non-Microsoft platforms |
| Reliable performance for ETL tasks | Can be resource-intensive for large jobs |
| Affordable for SQL Server users | Cloud integration requires extra setup |
| Good error handling and logging | Some advanced features need scripting |
Pricing
SSIS comes included with Microsoft SQL Server licenses. Organizations pay for SQL Server Standard or Enterprise editions. Pricing depends on the number of cores or server licenses. Microsoft offers a free Developer edition for testing and development. Cloud-based SSIS integration with Azure Data Factory incurs additional charges based on usage and resources.
SQLMesh
Overview
SQLMesh is a modern data transformation and orchestration tool designed for analytics engineering teams. It helps users manage, test, and deploy SQL-based data pipelines efficiently. SQLMesh focuses on version control, data quality, and workflow automation. Many organizations use SQLMesh to simplify the development and maintenance of data models in cloud data warehouses.
SQLMesh stands out by offering a declarative approach to data transformation. Users define data models using SQL, and the platform handles dependency management and scheduling. The tool integrates with popular data warehouses such as Snowflake, BigQuery, and Databricks. SQLMesh appeals to teams that want to improve collaboration, reduce errors, and accelerate analytics projects.
SQLMesh empowers data teams to build reliable, maintainable, and scalable data pipelines using familiar SQL syntax.
Features
SQLMesh provides a robust set of features for data transformation and workflow management:
Declarative SQL Modeling: Users define data models and transformations using standard SQL. The platform automatically manages dependencies between models.
Version Control Integration: SQLMesh connects with Git, allowing teams to track changes, review code, and collaborate on data projects.
Automated Testing: The tool includes built-in testing for data quality and model validation. Users can run tests before deploying changes to production.
Incremental Data Processing: SQLMesh supports incremental builds, which process only new or changed data. This feature saves time and resources.
Environment Management: Teams can create multiple environments (development, staging, production) to test changes safely.
Change Auditing and Data Lineage: SQLMesh tracks changes to data models and provides clear lineage for auditing and troubleshooting.
Workflow Orchestration: The platform schedules and manages data pipeline execution. Users can monitor job status and receive alerts for failures.
Integration with Major Warehouses: SQLMesh works with Snowflake, BigQuery, Databricks, and other cloud data platforms.
Rich Documentation Generation: The tool generates documentation from SQL code and metadata, making it easy to share knowledge.
Pros and Cons
| Pros | Cons |
| Familiar SQL-based modeling | Requires SQL knowledge |
| Strong version control and collaboration | Limited support for non-SQL transformations |
| Automated testing improves data quality | Smaller community compared to dbt |
| Incremental processing saves resources | Fewer integrations than legacy ETL tools |
| Clear data lineage and auditing | Some advanced features still evolving |
| Environment management for safe deployments | May need technical setup for orchestration |
SQLMesh offers a powerful solution for teams that prioritize code quality, collaboration, and efficient data workflows. However, it may not suit organizations that need extensive support for non-SQL data sources or require a large connector ecosystem.
Pricing
SQLMesh offers both open-source and commercial options:
Open-Source Edition: Free to use under the Apache 2.0 license. This version includes core features such as SQL modeling, version control, and basic orchestration.
Enterprise Edition: Pricing is available upon request. The enterprise version adds advanced features like enhanced security, priority support, and integrations with enterprise systems.
Cloud-Hosted Option: SQLMesh provides a managed cloud service with usage-based pricing. Costs depend on the number of models, environments, and compute resources used.
Teams can start with the open-source edition to evaluate SQLMesh. Organizations with advanced needs or large-scale deployments may contact the vendor for enterprise pricing and support.
ETL Tools Comparison Table
Choosing the right etl tool requires careful comparison of both features and pricing. Organizations often evaluate these aspects to ensure the selected solution meets their data integration needs and fits within their budget. The following tables and explanations help clarify how leading etl platforms differ in their capabilities and cost structures.
Feature Comparison
Feature sets can vary widely among top etl tools. Some platforms focus on automation and ease of use, while others provide advanced customization or strong data quality controls. The table below highlights key features of five leading etl solutions in 2025:
| ETL Tool | Key Feature Highlights |
| Talend Data Fabric | Extensive cloud and hybrid environment support; 1000+ connectors; Talend Trust Score for data quality. |
| Informatica PowerCenter | Metadata-driven platform; multiple service levels (Standard, Advanced, Premium); supports semi-structured and unstructured data in Premium edition. |
| Fivetran | Automated data pipeline management; real-time analytics capabilities. |
| Stitch | Data replication; scalability with self-managing connectors; advanced security features. |
| Xplenty (Integrate.io) | Low-code drag-and-drop interface; supports 100+ native data sources; advanced security (FLE, hashing, 2FA, masking); coding customization options. |
Each etl tool brings unique strengths. Talend Data Fabric stands out for its broad connector library and data quality scoring. Informatica PowerCenter offers deep metadata management and supports a wide range of data types. Fivetran focuses on automation and real-time analytics, making it suitable for fast-moving businesses. Stitch provides strong security and scalable replication, while Xplenty (Integrate.io) appeals to users who want a low-code experience with advanced security.
When selecting an etl platform, teams should consider which features align best with their current and future data integration requirements.
Pricing Comparison
Pricing models for etl tools differ based on company size, usage, and support needs. Some platforms use tiered or usage-based pricing, while others require custom quotes. The table below summarizes how leading etl solutions structure their pricing for small, medium, and large enterprises:
| ETL Tool | Pricing Model | Small Enterprise Pricing | Medium Enterprise Pricing | Large Enterprise Pricing | Notes |
| IBM Informix | Tiered instance-based pricing | $1,250 per instance | $2,200 per instance | $4,000 per instance | Also offers an extra-large package at $8,000 per instance; free developer edition available |
| Tapdata | Core-based predictable pricing | Forever Free Tier available | Pricing based on cores | Pricing based on cores | Custom connector development costs $1000 each |
| Fivetran | Credit-based (usage-based) | Based on monthly active row threshold (MARS); exact pricing not publicly disclosed | Same as small, usage-based | Same as small, usage-based | Detailed pricing requires visiting website |
| Airbyte | Credit-based (usage-based) | Based on MARS; exact pricing not publicly disclosed | Same as small, usage-based | Same as small, usage-based | Detailed pricing requires visiting website |
| Integrate.io | Not publicly disclosed | N/A | N/A | N/A | Offers 7-day free trial after demo request |
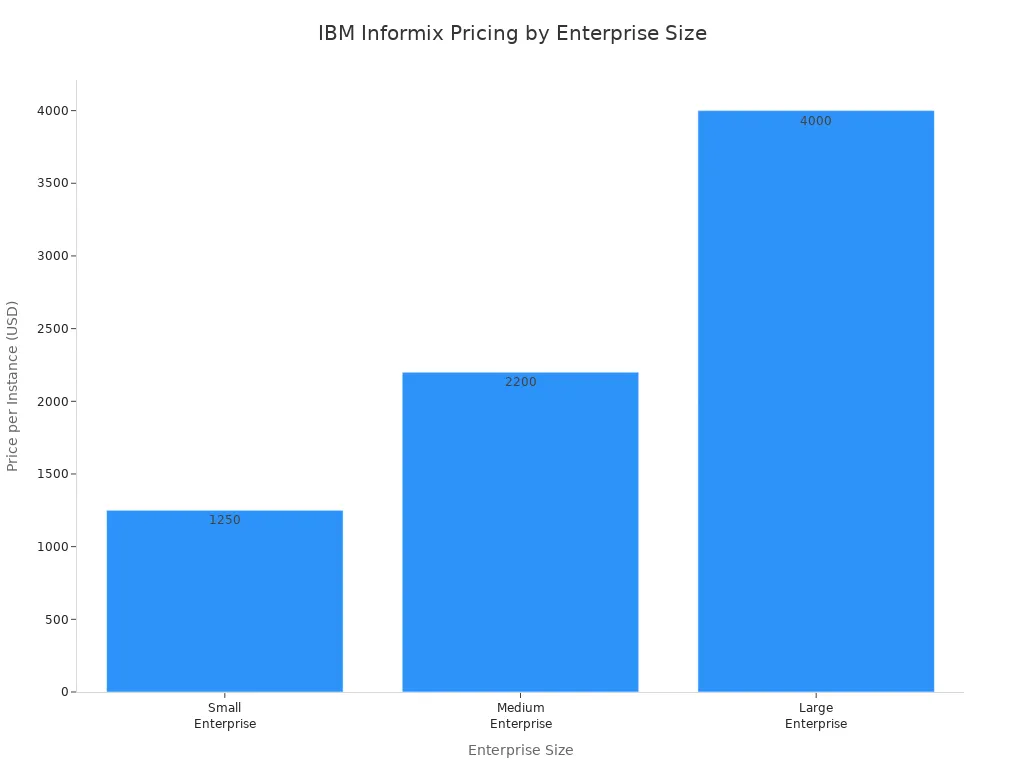
Pricing transparency varies among etl vendors. IBM Informix provides clear instance-based pricing, which helps organizations estimate costs. Tapdata offers a free tier and predictable core-based pricing, making it accessible for startups and growing companies. Fivetran and Airbyte use usage-based models, which scale with data volume but may require direct contact for detailed quotes. Integrate.io offers a free trial but does not disclose standard pricing publicly.
Teams should review pricing models carefully. They should consider both current data volumes and expected growth to avoid unexpected expenses as their etl needs expand.
Data Integration Trends 2025
Unified ETL and Reverse ETL
Unified ETL and reverse ETL have become central to modern data integration strategies in 2025. Organizations now expect seamless movement of data not only into data warehouses but also back into operational systems. This approach ensures that insights from analytics reach business tools where teams can act on them quickly. Companies use unified ETL to extract, transform, and load data into central repositories. They then rely on reverse ETL to sync curated data back into SaaS platforms, CRMs, and marketing tools.
Several trends shape this landscape:
No-code and low-code ETL tools empower non-technical users to manage data integration independently.
Real-time data integration replaces traditional batch processing, enabling immediate insights and faster decision-making.
Cloud-native architectures offer scalability and cost efficiency for both ETL and reverse ETL.
Automation and AI integration reduce manual intervention, streamlining workflows and minimizing errors.
Hybrid ETL/ELT models combine pre- and post-load transformations for greater flexibility.
Integration with DataOps and CI/CD practices improves pipeline reliability and team collaboration.
Reverse ETL tools, such as Hightouch and Census, focus on real-time audience activation, SQL-based modeling, and strong governance.
Best practices include starting with high-value syncs, implementing governance, and monitoring sync performance.
Reverse ETL has become critical for activating governed warehouse data as a single source of truth. Teams often begin with one high-value sync to prove return on investment, then expand as they validate model freshness and monitor latency.
No-Code and Low-Code ETL
No-code and low-code ETL platforms have transformed the data integration landscape. These tools allow users with varying technical skills to participate in building and managing data pipelines. Visual interfaces, such as drag-and-drop workflows, make it easy to automate complex processes without writing code. Prebuilt connectors for popular data sources further streamline integration and reduce setup time.
No-code ETL tools offer several advantages:
They democratize data integration, enabling business analysts and other non-engineers to contribute.
Automation features handle metadata processing, schema detection, and data cleansing, reducing manual effort.
Visual tools foster collaboration across teams and accelerate pipeline development.
Built-in best practices support data quality assurance, version control, and user access management.
Organizations can create and manage data products and private data marketplaces, improving accessibility and collaboration.
These platforms reduce reliance on specialized technical resources and make data integration more scalable and cost-effective. Many companies now choose no-code and low-code ETL solutions to speed up development and lower costs.
Real-Time and Hybrid ETL
Real-time and hybrid ETL approaches have gained momentum as organizations seek faster insights and greater flexibility. Real-time data integration enables businesses to process and analyze information as soon as it arrives. This capability supports use cases such as fraud detection, personalized marketing, and live dashboards. Hybrid ETL models combine real-time and batch processing, allowing teams to balance speed and resource efficiency.
Key benefits of real-time data integration include:
Immediate access to up-to-date information for decision-making.
Enhanced responsiveness to market changes and customer behavior.
Improved operational efficiency by automating data flows.
Hybrid ETL solutions provide flexibility by supporting both scheduled and continuous data processing. Companies can process critical data streams in real time while handling large historical datasets in batches. This approach ensures that data integration strategies remain adaptable to changing business needs.
Open-Source Growth
Open-source ETL tools have seen remarkable growth in 2025. Many organizations now prefer open-source solutions for data integration. These tools offer flexibility, transparency, and community-driven innovation. Companies can customize open-source ETL platforms to fit unique business needs. This trend has changed how teams approach data integration projects.
Several factors drive the rise of open-source ETL:
Cost Savings: Open-source tools often have no licensing fees. Teams can allocate budgets to other priorities.
Community Support: Developers worldwide contribute to open-source projects. This collaboration leads to rapid bug fixes and new features.
Transparency: Open-source code allows users to inspect and modify the software. This transparency builds trust and improves security.
Vendor Independence: Organizations avoid vendor lock-in. They can switch providers or self-host solutions as needed.
Innovation: Open-source projects often adopt new technologies quickly. Teams benefit from the latest advancements in data engineering.
Note: Open-source ETL tools like Airbyte, Apache NiFi, Singer, and dbt have become household names in data engineering teams. These platforms support both small startups and large enterprises.
A comparison of popular open-source ETL tools in 2025:
| Tool | Key Strengths | Typical Use Cases |
| Airbyte | Fast connector development | Cloud data integration |
| Apache NiFi | Visual flow design, scalability | Real-time and batch processing |
| Singer | Modular, easy to extend | Custom data pipelines |
| dbt | SQL-based transformation | Analytics engineering |
| Apache Hop | Flexible orchestration | Complex workflow management |
Open-source ETL adoption has also encouraged best practices in data integration. Teams now focus on:
Data Observability: Monitoring data flows and pipeline health.
Automation: Reducing manual tasks with scripts and scheduling.
Collaboration: Sharing connectors and workflows within the community.
Many organizations choose open-source ETL for hybrid and multi-cloud environments. These tools adapt well to changing infrastructure. Companies can deploy them on-premises or in the cloud. Open-source ETL also supports integration with modern data warehouses and streaming platforms.
Challenges remain. Open-source tools may require more technical expertise. Some organizations invest in training or seek commercial support from vendors. However, the benefits often outweigh the drawbacks.
Open-source growth in ETL reflects a broader shift toward open, collaborative technology. This trend empowers teams to innovate and build reliable data integration pipelines for the future. 🚀
Selecting the best etl tools in 2025 requires careful evaluation of business needs and future data integration trends. Teams should compare features, test shortlisted platforms, and review scalability, support, and integration capabilities. Many organizations benefit from starting a free trial or consulting with vendors. User reviews also provide valuable insights. Readers can share their experiences or ask questions to help others make informed decisions about etl and data integration.
FAQ
What is the main purpose of an ETL tool?
An ETL tool helps organizations move data from different sources, change it into a usable format, and load it into a storage system. This process supports better reporting and analytics.
How does ETL differ from ELT?
ETL stands for Extract, Transform, Load. ELT stands for Extract, Load, Transform. ETL changes data before loading it. ELT loads data first, then changes it inside the storage system. ELT works well with modern cloud data warehouses.
Are open-source ETL tools safe for business use?
Open-source ETL tools can be safe if teams follow best practices. Regular updates, strong access controls, and community support help maintain security. Many large companies use open-source ETL tools for flexibility and cost savings.
How do real-time ETL tools benefit organizations?
Real-time ETL tools process data as soon as it arrives. This helps companies react quickly to new information. Real-time ETL supports instant dashboards, fraud detection, and live customer insights.
What factors should teams consider when choosing an ETL tool?
Teams should look at scalability, ease of use, integration options, pricing, and security features. They should also test the tool with real data and review support options.
Can non-technical users work with ETL tools?
Many modern ETL tools offer no-code or low-code interfaces. These features allow non-technical users to build and manage data pipelines using drag-and-drop tools and visual workflows.
Do ETL tools support both cloud and on-premises data sources?
Most leading ETL tools connect to both cloud and on-premises data sources. This flexibility helps organizations manage data across different environments and supports hybrid data strategies.
How often should organizations update their ETL pipelines?
Teams should review and update ETL pipelines regularly. Changes in data sources, business needs, or regulations may require updates. Regular testing ensures data quality and pipeline reliability.
Subscribe to my newsletter
Read articles from Community Contribution directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by