ETL Alternatives for Data Engineers: What’s New in 2025
 Community Contribution
Community ContributionTable of contents
- Key Takeaways
- Why ETL Alternatives Matter
- Top ETL Alternatives 2025
- ETL Alternatives Comparison
- Deep Dive: Leading ETL Alternatives
- Choosing the Right ETL Alternative
- Getting Started with ETL Alternatives
- FAQ
- What is the main difference between ETL and ELT?
- How do open source ETL tools compare to commercial solutions?
- Which ETL tools support real-time data processing?
- Can low-code ETL platforms handle complex data workflows?
- What are the key security features in modern ETL tools?
- How does reverse ETL benefit business teams?
- What should teams consider before migrating to a new ETL platform?
- Are cloud-native ETL tools better for scalability?

Data integration has transformed rapidly as organizations seek scalable, intelligent ETL solutions. In 2025, top ETL alternatives include platforms like Apache Hadoop with Amazon EMR, Google BigQuery, Airflow, Amazon Kinesis, Snowflake, MongoDB, Cassandra, Dell Boomi, Airbyte, Fivetran, Integrate.io, and Google Cloud Dataflow. The market now favors cloud-native, AI-driven, and low-code ETL tools, reflecting the need for automated, real-time data integration.
The table below highlights the most widely adopted ETL alternatives and their strengths:
| ETL Alternative | Primary Use Case / Strengths | Market Adoption Insight / Usage Context |
| Apache Hadoop (with Amazon EMR) | Big data architecture and optimization | Widely used for large-scale batch processing in big data domains |
| Google BigQuery | Real-time analytics and lightning-fast querying | Popular cloud-native data warehouse for analytics workloads |
| Airflow / Cloud Composer | Orchestration of complex data pipelines | Leading tool for managing and scheduling ETL workflows |
| Amazon Kinesis | Real-time data streaming | Adopted for streaming data ingestion and processing |
| Snowflake | Cloud-native data warehousing | Rapidly growing due to scalability and ease of use |
| MongoDB | Flexible, document-oriented data management | Favored for distributed, schema-flexible data storage |
| Cassandra | High-availability distributed data infrastructure | Used in scenarios requiring fault tolerance and scalability |
| Dell Boomi AtomSphere | Cloud-native iPaaS with integration and API management | Chosen for hybrid environments and low-code integration |
| Airbyte | Open-source, connector-centric ELT platform | Increasing adoption due to extensibility and open-source model |
| Fivetran | Automated ELT with extensive connectors | Popular for ease of use and automated schema management |
| Integrate.io | Low-code ETL/ELT platform with strong customer support | Preferred for user-friendly interfaces and flexible transformations |
| Google Cloud Dataflow | Unified batch and streaming data processing | Used for serverless, scalable data pipelines on Google Cloud |
Key Takeaways
Modern ETL tools focus on real-time data processing, cloud-native design, and AI-driven automation to meet growing data needs.
Many new ETL alternatives offer scalable, flexible, and easy-to-use platforms that reduce manual work and speed up data integration.
Open source ETL frameworks like Airflow and Airbyte provide strong customization and community support for building tailored data pipelines.
ELT and reverse ETL tools enable faster analytics and connect data warehouses directly to business applications for real-time insights.
Choosing the right ETL solution depends on factors like data volume, compliance needs, team skills, and cloud ecosystem compatibility.
Security features such as encryption, role-based access, and audit logs are essential in modern ETL platforms to protect sensitive data.
Planning and testing carefully during ETL migration helps avoid common pitfalls and ensures smooth transitions with minimal disruption.
Future-proof ETL solutions support both batch and streaming data, offer modular designs, and enable easy scaling and governance.
Why ETL Alternatives Matter
Data Architecture Shifts
Organizations have experienced major changes in data architecture over the past few years. Enterprises now move away from legacy batch ETL systems and embrace real-time data ingestion. This shift allows faster analytics and improves operational responsiveness. Many companies adopt cloud-native architecture, which supports managed ETL services and reduces infrastructure overhead. AI-driven automation in ETL tools helps improve pipeline reliability by detecting anomalies and suggesting intelligent transformation options.
Enterprises transition from batch ETL to real-time data ingestion for quicker analytics.
Cloud-native architecture encourages the use of managed ETL services, lowering infrastructure costs.
AI-driven automation enhances reliability and transformation accuracy.
ELT and zero-ETL patterns emerge, embedding transformation within platforms and reducing latency.
Modern ETL tools focus on modularity, observability, error handling, version control, and hybrid or multi-cloud integration.
Legacy ETL systems struggle to scale and adapt to new data sources or real-time processing needs.
Modern ETL platforms support compliance, operational control, and flexible data integration.
Case Study: Pionex US reduced data latency from 30 minutes to under 30 seconds and cut operational costs by adopting zero-ETL with AWS services. This enabled near real-time analytics and improved risk control.
Traditional ETL Limitations
Traditional ETL tools present several challenges for data engineering teams. Data quality issues often arise due to diverse sources, leading to inconsistencies and errors. Scalability becomes a problem as data volume and variety increase, causing performance bottlenecks. Batch processing design makes real-time processing difficult, forcing teams to adopt streaming technologies for low-latency data integration.
Data quality issues require complex validation steps.
Scalability problems limit performance as data grows.
Batch processing leads to stale data and slow analytics.
Modifying transformation logic demands changes to entire pipelines, increasing risk and effort.
Dedicated middleware and specialized tools raise maintenance and infrastructure costs.
Security and governance concerns arise from decentralized control, risking redundant pipelines and inconsistent data definitions.
Low-code or no-code ETL tools struggle with customized logic, advanced error handling, and deep integration into specialized systems.
Many teams find that legacy ETL systems cannot handle highly customized transformation logic or advanced error scenarios. These limitations drive the search for modern ETL alternatives that offer greater flexibility and scalability.
New Trends in ETL
ETL technology continues to evolve rapidly. In 2025, several trends shape the future of data integration and processing. Embedded analytics and AI-driven insights become more common, allowing organizations to extract value from data faster. Edge computing integration supports data workflows closer to the source, improving efficiency. DataOps practices gain traction, helping teams manage data pipelines with greater agility and reliability.
Embedded analytics and AI-driven insights enhance transformation and decision-making.
Edge computing integration enables efficient data workflows at the source.
DataOps practices improve pipeline management and operational excellence.
Cloud-native architecture drives adoption of scalable ETL solutions.
Artificial intelligence and machine learning integrate with ETL tools for smarter automation.
IoT data integration expands, requiring flexible and robust ETL platforms.
The rising complexity of data integration and the need for real-time processing push organizations to explore new ETL alternatives. These trends help companies stay competitive and responsive to changing business needs.
Top ETL Alternatives 2025
Commercial ETL Alternatives
Commercial ETL alternatives in 2025 offer advanced features for organizations seeking robust data integration and cloud-based data management. These platforms focus on automation, scalability, and ease of use. Many vendors have introduced significant updates to address the growing demand for real-time processing and AI-driven transformation.
5X
Launched in 2025, 5X stands out as an AI-ready, cloud-native ETL platform. It removes the Java dependency and complexity found in older tools like Talend. The platform provides over 500 pre-built connectors, automatic updates, and AI-powered data transformation. Users benefit from real-time processing, transparent pricing, and enterprise-grade security. Implementation takes less than 48 hours, making it suitable for fast-paced environments.Airbyte
Airbyte has expanded its connector library to over 600 in 2025. The platform uses an open-source, API-first architecture. It supports real-time sync and offers multiple deployment options, including cloud, self-hosted, and hybrid. Airbyte eliminates proprietary lock-in and licensing complexity, making it attractive for organizations seeking flexibility.Matillion
Matillion released major updates in 2025, focusing on cloud-native data transformation. The platform leverages the computing power of cloud data warehouses, improving performance and scalability. Matillion’s visual orchestration tools help teams build and manage ETL pipelines efficiently.
Other notable commercial ETL alternatives include Informatica Intelligent Data Management Cloud, Oracle Cloud Infrastructure Integration, Rivery, Talend, Pentaho Data Integration, CloverDX, GeoKettle, Hevo, Skyvia, Azure Data Factory, AWS Glue, Boomi, SnapLogic, Workato, Fivetran, Alteryx Designer, TIBCO Platform, and Tableau Prep. Each solution offers unique strengths in data integration, transformation, and processing.
The following table highlights key differentiators among leading ETL alternatives:
| ETL Alternative | Key Differentiators | Core Strengths / Features | Trade-offs / Cons |
| Apache Airflow | Python code-first approach, extensive community contributions, fine-grained workflow control | Unlimited customization, 200+ operators/hooks, scalable execution, rich monitoring | Steep learning curve, requires technical expertise, not a traditional ETL tool |
| AWS Glue | AI-powered code generation, massive scalability on Apache Spark, deep AWS ecosystem integration | Serverless, 100+ connectors, automatic data catalog, multi-engine support | Vendor lock-in, steep learning curve, potential high costs |
| Apache NiFi | Visual drag-and-drop interface, comprehensive data provenance, 200+ built-in processors | User-friendly GUI, real-time and batch processing, strong security features | Resource intensive, infrastructure management needed, learning curve for advanced features |
| Meltano | Open-source ELT, native dbt integration, GitOps workflows, CLI-first development | 600+ Singer connectors, version control integration, built-in orchestration | Requires technical expertise, less mature than commercial tools, limited GUI |
| Informatica PowerCenter | Enterprise data management leader, comprehensive governance, master data management, advanced metadata | 500+ enterprise connectors, AI-powered operations, regulatory compliance | High cost, complex licensing, long implementation timelines |
| Matillion | Cloud data warehouse specialization, pushdown ELT processing, visual orchestration | Optimized for Snowflake, BigQuery, Redshift, cloud-native, visual development | Limited to cloud warehouses, credit-based pricing complexity, learning curve for advanced features |
| Fivetran | Fully automated pipelines, large connector library, minimal maintenance | 500+ connectors, automated schema management, real-time sync, enterprise-grade reliability | Limited customization, higher cost, premium pricing |
| Airbyte | Largest open-source connector catalog, AI-powered connector building, transparent pricing | 600+ connectors, open-source flexibility, self-hosted and cloud options | Requires technical expertise, variable connector quality, infrastructure management for self-hosted |
| Microsoft Azure Data Factory | Deep Microsoft ecosystem integration, hybrid cloud support, serverless scalability | 90+ connectors, visual ETL/ELT design, advanced monitoring, enterprise-grade security | Complexity for advanced transformations, potential high costs, Microsoft ecosystem focus |
Many commercial ETL alternatives now emphasize real-time ETL, AI-driven automation, and seamless integration with cloud-based data management platforms.
Open Source ETL Frameworks
Open source ETL frameworks continue to gain popularity in 2025. These tools provide flexibility, transparency, and strong community support. Organizations use open source ETL frameworks to build custom data workflows and manage complex data integration tasks.
| Framework | GitHub Stars | Contributors | Key Features & Community Adoption Highlights |
| Apache Airflow | 36k+ | 3k+ | Highly popular workflow management with DAG-based pipelines, large community, scalable for enterprise use. |
| Luigi | 17k+ | 500+ | Python-based batch pipeline framework, strong in managing complex dependencies and failure recovery. |
| Prefect | 15k+ | 200+ | Pythonic workflow automation with dynamic workflows, retries, caching, and real-time monitoring. |
| Dagster | 11k+ | 400+ | Declarative data orchestration, integrated lineage, observability, and testability. |
| Kedro | 9k+ | 200+ | Modular, reproducible Python pipelines emphasizing code quality and collaboration. |
| Mage | 8k+ | 100+ | No-code/low-code interface, supports batch and streaming, real-time debugging, and modular connectors. |
| Metaflow | 8k+ | <100 | Human-centric workflow management, data versioning, lineage tracking, supports Python and R. |
| Apache Beam | 7k+ | 1k+ | Unified batch and streaming model, portable across execution engines, rich SDK ecosystem. |
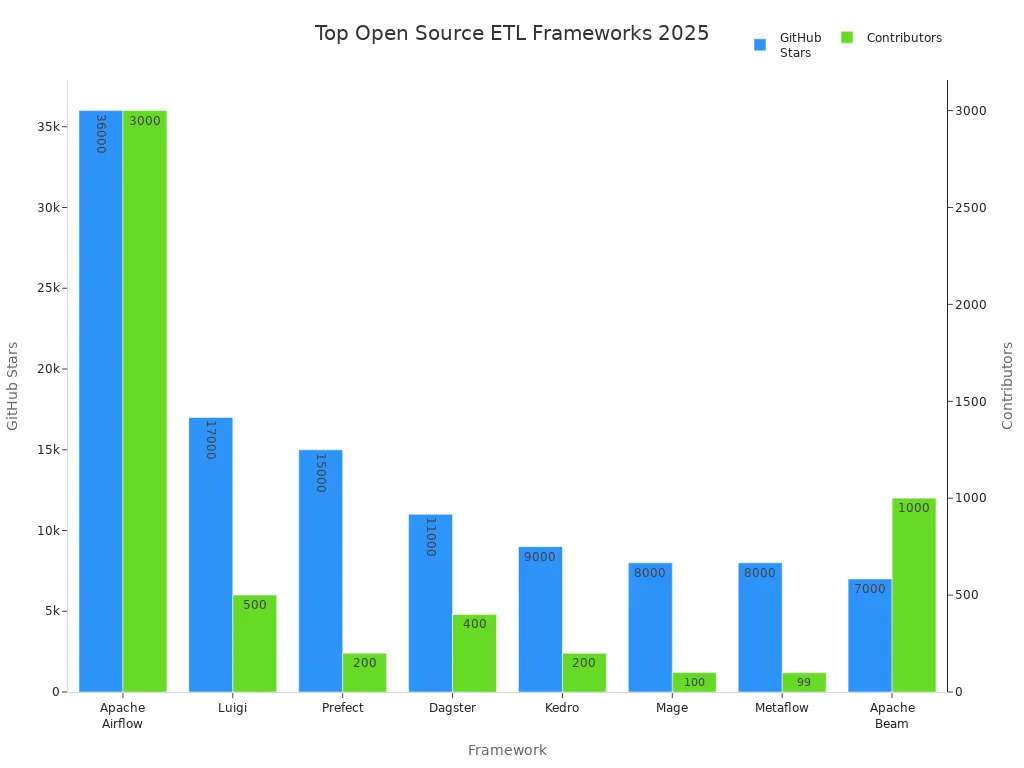
These open source ETL frameworks enable organizations to design, schedule, and monitor ETL pipelines for a wide range of data integration scenarios. Apache Airflow leads with its code-first approach and large community. Luigi and Prefect offer strong support for batch processing and workflow automation. Dagster and Kedro focus on modularity and reproducibility, while Mage and Metaflow provide user-friendly interfaces and support for both batch and streaming data workflows. Apache Beam stands out for its unified model that supports both batch and streaming processing.
Open source tools empower teams to customize data integration solutions and adapt quickly to new requirements.
ELT and Reverse ETL Tools
ELT and reverse ETL tools have changed the landscape of data integration. ELT tools load raw data into cloud data warehouses and perform transformation after loading. This approach enables faster processing and supports large-scale analytics. Reverse ETL tools extract processed data from warehouses and sync it back to business applications, closing the loop between analytics and operations.
| Feature | ETL | ELT |
| Data Transformation | Transformation happens before loading | Transformation happens after loading |
| Data Quality | High emphasis on data cleaning upfront | Less emphasis on upfront cleaning |
| Processing Time | Longer due to transformation step | Faster due to parallel processing |
| Data Volume | Better suited for smaller datasets | Efficient handling of large datasets |
| Flexibility | Less flexible | More flexible due to availability of raw data |
Reverse ETL tools enable real-time business actions by syncing data from warehouses to operational systems. Sales teams receive customer insights in real time by connecting data warehouses to CRM systems. Marketing teams optimize campaigns by sending performance metrics to marketing automation platforms. Customer support tools improve service by syncing customer data. Financial processes accelerate as data moves into ERP systems for better reporting. Product development benefits from linking usage metrics to product management tools.
Reverse ETL fundamentally differs from ETL and ELT. It extracts processed and cleaned data from data warehouses and loads it into business systems such as CRM, marketing, or support platforms. This enables operational workflows and real-time business actions. ETL focuses on data migration and warehousing, while ELT optimizes for big data analytics. Reverse ETL operationalizes data insights for improved decision-making and personalization.
ELT and reverse ETL tools support modern data integration strategies by enabling real-time processing, operational analytics, and seamless data workflows across business functions.
ETL Alternatives Comparison
Evaluation Criteria
Selecting the right ETL solution requires a clear understanding of what matters most for modern data engineering. Enterprises now face stricter regulations, such as GDPR and HIPAA, which demand advanced data lineage and governance. Tools must offer column-level lineage for rapid root-cause analysis, reducing downtime and supporting compliance. Role-based access control, encryption, and audit logs have become essential for security.
Connector breadth and extensibility allow integration with diverse data sources, including SaaS applications and legacy systems. Pricing models should be transparent to avoid hidden costs. Airbyte, for example, demonstrates these priorities with its extensive connectors, advanced lineage, and predictable pricing.
Performance and speed remain critical for real-time decision-making. Scalability ensures that ETL tools can handle growing data volumes without complexity. Ease of use, such as drag-and-drop interfaces and templates, helps teams adopt new solutions quickly. Data transformation capabilities must align with specific business needs. Integration options, including compatibility with cloud data warehouses and on-premises sources, support flexible workflows. Cost considerations include both usage-based and fixed pricing models.
Tip: Enterprises should benchmark ETL tools using realistic workloads that include incremental extraction, record-level deletions, and table optimization. This approach reveals true performance and cost trade-offs.
| Evaluation Criteria | Explanation |
| Cloud-based connectivity | Supports remote work and real-time data operations. |
| Data warehousing functionality | Integrates data from multiple sources; must be scalable and cost-effective. |
| Ease of use | No-code interfaces and templates enable quick adoption. |
| SaaS data integrations | Compatible with modern SaaS apps and APIs. |
| Scalability without complexity | Cloud data lakes and CDC methods allow easy scaling. |
| Data warehouse interoperability | Enables switching warehouses without changing ETL pipelines. |
| Pricing model alignment | Matches business needs and controls total cost. |
| Ready-to-use ETL solutions | Pre-built integrations for rapid deployment. |
| Custom ETL connectors | Supports unique, unstructured data sources. |
| Ingest on-premises data sources | Compatible with legacy databases and CRM systems. |
Performance and speed drive operational efficiency.
Scalability supports seamless growth in data volume.
Ease of use improves productivity.
Data transformation capabilities match business requirements.
Integration options provide versatile connectivity.
Cost aligns with budget and usage patterns.
Recent benchmarks show that AWS EMR, Databricks, and Snowflake differ in performance, scalability, and cost. Load operations can consume up to half of ETL runtime. Data lakehouse technologies and open table formats add compute overhead, especially for update and delete operations. Cloud infrastructure offers elastic scaling, but inefficient resource provisioning may increase costs. No single platform excels in every scenario. Cost-performance trade-offs depend on workload patterns and concurrency.
Comparison Matrix
The following matrix compares leading ETL alternatives across key criteria. This table helps data engineers quickly identify which solution best fits their needs.
| ETL Tool | Use Case | Connectors | Features | Deployment | Performance | Security & Governance | Cost Model |
| Airbyte | ELT, SaaS, cloud | 600+ | Open-source, lineage | Cloud, hybrid | High | RBAC, encryption | Capacity-based |
| AWS Glue | Big data, cloud | 100+ | Serverless, AI-gen code | Cloud | High | Audit logs, RBAC | Usage-based |
| Matillion | Cloud warehouse | 100+ | Visual ELT, pushdown | Cloud | High | Role-based access | Credit-based |
| Fivetran | Automated ELT | 500+ | Schema mgmt, auto sync | Cloud | High | Enterprise-grade | Usage-based |
| Informatica | Enterprise ETL | 500+ | Governance, metadata | Cloud, on-prem | High | Advanced compliance | Subscription |
| Apache NiFi | Real-time, batch | 200+ | Visual, provenance | On-prem, cloud | Medium | SSL, audit logs | Open-source |
| Meltano | ELT, dbt-native | 600+ | CLI, GitOps, orchestration | Cloud, hybrid | Medium | Version control | Open-source |
| Azure Data Factory | Hybrid, cloud | 90+ | Visual, monitoring | Cloud | High | Enterprise security | Usage-based |
Note: Data engineers should match ETL alternatives to their specific use case, considering connector support, deployment flexibility, and cost structure. Real-world workloads and compliance needs often determine the best fit.
Deep Dive: Leading ETL Alternatives
Informatica
Informatica remains a leader among ETL platforms in 2025. The platform uses a metadata-driven approach to optimize database operations and supports integration across cloud and on-premises environments. Informatica’s data transformation engine offers rich capabilities for aggregation, cleansing, masking, and filtering. The platform enforces data quality rules, identifies errors, and tracks inconsistencies. Informatica provides robust data security through masking, access controls, encryption, and credential management. API integration supports REST, SOAP, and Open Data protocols, connecting systems and applications for seamless data processing.
| Feature | Description |
| Metadata-driven approach | Optimizes database operations and supports integration across cloud and on-premises environments. |
| Data Quality | Identifies and corrects errors, inconsistencies, and duplicates; enforces data quality rules and tracking. |
| Data Security | Employs data masking, access controls, encryption, and credential management to protect sensitive data. |
| API Integration | Supports REST, SOAP, and Open Data protocols to connect systems and applications seamlessly. |
| Database Management | Connects to various databases using metadata-driven optimization for performance. |
| Data Transformation | Offers rich transformations like aggregation, cleansing, masking, and filtering to refine data effectively. |
| Orchestration | Uses Data Integration Hub to coordinate and manage data movement across systems for smooth workflows. |
| Access Control | Provides granular permission settings at database, domain, and security rule levels for fine-tuned control. |
Informatica’s strengths include fine-tuned access control and advanced data security. The platform suits enterprises that require strict governance and compliance. Pricing follows a subscription model, which may be costly for smaller teams.
Matillion
Matillion specializes in cloud-based ETL workflows. The platform pushes transformations directly into cloud data warehouses, improving performance and scalability. Matillion offers an intuitive low-code interface, making it accessible for technical and non-technical users. The platform supports advanced transformations and provides templates and custom jobs through Matillion Exchange.
Pros:
Easy visual builder for workflow creation
Flex Connectors enable custom API integrations
Strong security certifications (SOC 2 Type II, ISO 27001, GDPR)
Active community and support
Cloud deployment keeps data processing within customer environment
Built-in collaboration and version control
Cons:
Requires engineering effort for setup and maintenance
No built-in reverse ETL or visual UI for non-technical users
Manual resource management needed for scaling
Pricing can become expensive at scale
Limited connector library compared to competitors
Primarily designed for ELT, not heavy in-flight ETL transformations
Matillion’s pricing starts around $1,000 per month and scales with vCPU usage. The platform fits teams focused on data warehousing and large-scale data processing.
Airbyte
Airbyte stands out among open source ETL frameworks. The platform’s open source model gives users full ownership of their data and fosters a collaborative ecosystem. Companies can report issues or contribute fixes, which reduces bugs and development effort. Airbyte’s low-code Connector Development Kit accelerates connector development, allowing developers to build and maintain integrations quickly. The community is active, with over 20,000 members on Slack. More than 40,000 companies have adopted Airbyte in the last two years.
Open source tools provide control, flexibility, and community support.
Airbyte’s transparent licensing and open development roadmap build trust and encourage ongoing collaboration.
The platform supports real-time processing and efficient data integration.
Open source ETL frameworks like Airbyte enable fast interactions among users and companies, driving innovation.
Airbyte’s popularity reflects a broader trend toward open source ETL frameworks in data infrastructure. The platform suits organizations that value control, flexibility, and rapid connector development.
Apache NiFi
Apache NiFi stands out among open source etl frameworks for its visual interface and strong support for real-time data movement. Many organizations use NiFi to automate and manage complex etl pipelines. The platform helps teams design, monitor, and control data flows with minimal coding.
NiFi supports a wide range of use cases in modern data engineering:
Data ingestion from sources like sensors, medical devices, and electronic records.
Real-time data transformation and enrichment for interoperability.
Intelligent data routing and prioritization based on urgency.
Data security through masking, encryption, and monitoring.
Integration with big data ecosystems such as Hadoop and Spark.
Automated data flow management using a drag-and-drop interface.
Real-time data streaming for immediate insights.
NiFi’s strengths include its ability to handle both batch and streaming data, making it a flexible choice for many teams. The platform’s visual interface reduces the need for manual coding, which speeds up pipeline development. NiFi also offers strong security features, including data masking and encryption, to protect sensitive information.
However, NiFi can require significant resources for large deployments. Teams may need to invest time in learning advanced features. As an open source tool, NiFi benefits from community support but may lack the dedicated support found in commercial etl platforms.
Talend
Talend is a commercial etl solution known for its broad capabilities and integration options. It offers both open source etl frameworks and enterprise-grade platforms. Talend supports etl, ESB, iPaaS, and API gateway functions, making it more complex than tools focused only on etl or elt.
Talend’s pricing structure is less transparent than many competitors. The cost depends on deployment type, data volume, connectors, and number of users. Teams must often request custom quotes, which can make budgeting difficult. The table below summarizes Talend’s pricing tiers:
| Plan Type | Estimated Annual Cost | Target Market | Key Limitations |
| Open Studio (Free) | $0 | Individual devs | No cloud, no support, limited connectors |
| Cloud Starter | $12,000 - $30,000 | Small teams | Basic integrations only |
| Cloud Premium | $50,000 - $100,000 | Mid-market | Limited data governance |
| Data Fabric Enterprise | $150,000 - $500,000+ | Large enterprise | Requires implementation services |
Additional costs may include professional services, training, and infrastructure. Talend’s complexity and higher price point can be a challenge for smaller teams. The platform requires dedicated etl teams and longer implementation times. Despite these challenges, Talend remains popular for organizations needing advanced data integration and governance.
AWS Glue
AWS Glue is a cloud-native etl service that integrates tightly with the AWS ecosystem. It connects with services like Amazon S3, Redshift, Athena, Lambda, and AWS Lake Formation. This integration allows seamless data ingestion, transformation, and loading within AWS.
Key features of AWS Glue include:
Centralized metadata management with the AWS Glue Data Catalog.
Automated schema discovery using crawlers.
Visual pipeline design with Glue Studio.
Workflow automation with triggers for scheduled or event-based jobs.
Support for custom transformations in Python or Scala.
Serverless architecture with automatic scaling and pay-as-you-go pricing.
AWS Glue’s integration capabilities make it a preferred choice for teams already using AWS. The platform simplifies etl pipeline creation and management, especially for cloud-based data workflows. Its serverless model ensures scalability and cost efficiency. Teams benefit from AWS’s security features and ongoing enhancements.
Tip: AWS Glue works best for organizations seeking a fully managed, scalable etl solution within the AWS environment.
Fivetran
Fivetran has become a leading choice for organizations that need scalable etl solutions. The platform supports over 700 managed connectors, which automate the movement of data from extraction to loading. Companies use Fivetran to connect SaaS applications, databases, files, and event streams. The platform automatically detects schema changes and updates pipelines without manual intervention. This automation reduces the workload for engineering teams and ensures that data stays fresh.
Fivetran’s cloud-hosted architecture removes infrastructure management concerns. Enterprises can scale their etl pipelines as data needs grow. The platform supports near-real-time syncing, but this feature is available only on higher-tier enterprise plans. Fivetran’s pricing model is based on Monthly Active Rows (MAR), which means costs can increase as data volume grows. Organizations must monitor usage to avoid unexpected expenses.
“Advances in cloud technology over the past decade have unlocked new opportunities, especially with modern data warehouses and lakes, which are 100x better than on-premise systems. The key challenge now is ensuring scalable, automated data integration for companies managing thousands of locations across multiple geographies. Manual processes can’t keep up, and automated, managed tools like Fivetran are essential for applying proper governance, security, and profiling during data movement.” —Taylor Brown, COO and co-founder of Fivetran
Fivetran excels in automation and reliability. It handles schema drift and supports change data capture (CDC) for syncing updates. However, limited customization and premium pricing may not suit every team. Fivetran works best for large organizations that prioritize automated etl and need to integrate data from many sources.
Hevo
Hevo offers a modern etl platform designed for real-time data integration. The platform supports change data capture (CDC), which enables high-throughput and low-latency loading without affecting source systems. Hevo automatically detects schema changes and updates pipelines, allowing dynamic schema management. Intelligent recovery features include error detection, automatic retries, and checkpointing to prevent data loss.
| Feature Category | Description |
| Change Data Capture (CDC) | High throughput, low latency loading without impacting source. |
| Schema Drift Management | Automatic detection and propagation of source schema changes. |
| Intelligent Recovery | Advanced error detection, retries, and checkpointing. |
| Cloud Warehouse Integration | Seamless integration with Snowflake, BigQuery, Databricks. |
| Real-time Alerts & Visibility | Alerts on latency and schema changes; pipeline visibility and audit logs. |
| Data Transformation | Pre-load transformations for analytics-ready data. |
| No-code UI | Enables non-engineers to build and manage pipelines. |
| Incremental Data Loading | Real-time streaming and incremental loading for data freshness. |
Hevo’s no-code interface empowers non-engineers to create and manage etl pipelines. The platform supports pre-load transformations, which help with compliance and cost optimization. Hevo provides predictable, event-based pricing, making budgeting easier for organizations. The platform bridges etl and elt workflows, offering speed, flexibility, and accessibility.
Hevo supports real-time data replication for operational analytics and dashboards.
It allows data transformations before loading, which helps with compliance and cost savings.
The intuitive interface enables teams to build pipelines without coding.
Predictable pricing avoids cost volatility.
Hevo combines speed and flexibility for modern analytics platforms.
Other Notable ETL Alternatives
Several other etl tools have introduced innovative features in 2025. Rivery now supports real-time data processing and customizable transformations. Matillion has launched PipelineOS for intelligent orchestration and seamless cloud integration. Azure Data Factory offers no-code pipelines and autonomous etl with CI/CD integration. Google Dataflow uses streaming AI and machine learning for real-time analytics. Informatica PowerCenter provides AI-powered automation and strong governance for complex workflows.
| ETL Tool | Innovative Features / Integrations in 2025 | Notable Details |
| Rivery | Real-time processing, customizable transformations, acquired by Boomi | Flexible setup for complex workflows |
| Matillion | PipelineOS, seamless cloud integration | Optimized for cloud data warehouses |
| Azure Data Factory | No-code pipelines, autonomous etl, CI/CD integration | Over 90 connectors, serverless model |
| Google Dataflow | Streaming AI and ML, batch and streaming processing | Apache Beam unified model, serverless infrastructure |
| Informatica PowerCenter | AI-powered automation, role-based tools, collaboration, governance | Enterprise-grade integration for complex workflows |
| Skyvia | No-code integration, easy on-premise access, scalable pricing | Cloud platform for teams with limited technical expertise |
| AWS Glue | Auto-detect schema, visual transformation, dynamic scaling | Serverless etl for AWS-centric organizations |
| IBM Infosphere | System integration, governance, analytics, scalable MPP capabilities | Suitable for enterprises with complex data needs |
| SSIS | Robust error handling, customizable tasks with .NET, vast integration options | Best for Microsoft environments |
| Stitch | Flexible scheduling, fault tolerance, continuous monitoring | Open-source, cloud-first platform for rapid data movement |
These alternatives provide organizations with a range of etl and data integration options. Teams can select platforms based on workflow complexity, cloud compatibility, and pricing needs.
Choosing the Right ETL Alternative
Matching to Use Cases
Selecting the right ETL alternative starts with understanding the specific business scenario. Organizations must evaluate several factors to ensure the chosen solution aligns with their goals and technical environment.
Data accuracy and compliance play a crucial role, especially in regulated industries like healthcare or finance. ETL processes that transform data before loading help maintain clean and validated information.
Legacy system compatibility matters for companies with older on-premise infrastructure. ETL often integrates better with these systems.
Speed and scalability become essential when handling large data volumes or real-time analytics. ELT solutions, which load data first and transform it later, offer faster ingestion and better scalability in cloud environments.
Infrastructure requirements differ. ELT leverages cloud-native architectures, while traditional ETL may need more hardware for scaling.
Data quality risks can arise with ELT, since transformation happens after loading. Strong governance helps mitigate these risks.
Security concerns must be addressed, especially when raw data enters storage before transformation.
Business goals influence the choice. Real-time analytics and rapid scalability favor ELT, while structured, pre-processed data needs favor ETL.
Tip: Organizations should also consider interoperability, adaptability, and long-term business value when choosing an ETL alternative. The right fit supports both current and future data workflows.
Team Skills and Resources
The skills and resources available within a team directly impact the selection of an ETL tool. Teams with limited engineering support often benefit from no-code or low-code platforms, such as Hevo Data or Fivetran. These tools automate many tasks and allow non-developers to manage data pipelines, increasing agility and efficiency.
Enterprise IT managers in regulated sectors may require platforms with strong governance and security features, like Informatica or IBM DataStage. Data engineers who seek customization and control often prefer open-source or flexible platforms, such as Airbyte or Keboola, which allow tailored data pipeline design.
Teams working within a specific cloud ecosystem should select native ETL tools optimized for that environment, such as AWS Glue, Azure Data Factory, or Google Cloud Dataflow. AI-powered ETL solutions can further reduce manual intervention and adapt to changing data environments, which is valuable for teams with limited technical resources.
Note: Understanding the team's workflow, size, and technical expertise ensures the chosen ETL tool aligns with their ability to manage and govern data workflows effectively.
Future-Proofing
Future-proofing an ETL solution means preparing for evolving data needs and technology changes. Organizations should prioritize scalability by choosing cloud-native solutions and distributed processing frameworks, such as Databricks or Snowflake. Integration strategies that use unified data models and API-driven connections help link diverse data sources efficiently.
Security remains a top priority. Encryption, role-based access controls, and regular audits protect data integrity. Cost management strategies, like pay-as-you-go cloud models and automation, help maintain efficiency as data volumes grow.
Key strategies for future-proofing include:
Supporting both batch and real-time data workflows.
Using modular, microservices-based designs for flexible scaling.
Employing metadata management and lineage tracking for governance.
Implementing version control and CI/CD pipelines for reliable deployment.
Ensuring easy deployment across cloud and on-premise environments.
Organizations that invest in adaptable, secure, and scalable ETL solutions can respond quickly to new business requirements and maintain efficient data pipeline design over time.
Getting Started with ETL Alternatives
Implementation Tips
Starting with a new ETL alternative requires careful planning and a step-by-step approach. Teams should design a specialized data pipeline architecture that fits their unique challenges. For example, manufacturing companies often deal with diverse data formats and need high availability with low latency. Connecting source systems comes next. Teams integrate with systems like SCADA, MES, IoT sensors, and ERP using specialized connectors or APIs. They must consider polling frequency to avoid putting stress on production systems.
Data transformation processes play a key role. Teams often perform unit conversions, normalize time-series data, detect anomalies, and run quality control calculations. Many organizations stage simple transformations near the source and handle complex processing downstream. In high-volume environments, an ELT approach can help. Teams load raw data first and then transform it within the target database, using its processing power.
Security remains essential. Teams should encrypt data in transit and at rest, apply role-based access control, and use audit logging. Secure transfer methods like VPNs or staging databases add another layer of protection. Regulatory compliance must be maintained throughout the ETL process. Automation helps, too. Event-based triggers, such as sensor thresholds, can start data extraction and transformation, reducing manual work and enabling timely insights.
Common Pitfalls
Migrating to a new ETL platform brings several risks. Teams should avoid unnecessary changes to schemas and formats, as these can make migration more complex. Creating a unified connection framework streamlines data access. Verifying date formats prevents query failures, while ensuring data consistency and accuracy remains critical during migration.
Clear communication with stakeholders about progress and issues helps keep everyone aligned. Teams should always test migration pipelines in a simulated environment before going live. Backing up all data before migration protects against loss. A slow rollout strategy minimizes the impact of unexpected errors. Preparing a detailed release checklist guides production deployment.
After migration, teams must monitor and optimize query performance. Setting up alerts for pipeline failures, delays, or resource spikes ensures quick response to problems. Data quality checks help detect mismatches early. Engaging stakeholders early, establishing governance, and using automation tools all contribute to a smoother transition.
Further Resources
Teams can find many resources to support ongoing learning about ETL alternatives and best practices. Comprehensive guides cover automation, testing, documentation, and continuous monitoring. Recommended tools for ETL testing include JUnit for unit testing, Selenium for UI testing, Apache JMeter for performance, Postman for APIs, and SQLUnit for database testing.
Good documentation strategies include recording data source details, transformation logic, mapping, error handling, business rules, workflow overviews, and version control. Continuous monitoring and optimization use tools like Apache NiFi, Talend, Informatica, ELK Stack, and Splunk. Teams should also explore platform overviews, feature lists, connectors, and security information to deepen their understanding.
Case studies show the benefits of automation and integration. Articles on topics such as Reverse ETL, Data Extraction Tools, Data Wrangling, and Cloud ETL provide further insights. Talend offers resources on managing data quality in both ETL and ELT environments. Exploring new tools and strategies helps teams stay current in the evolving data landscape.
Staying current with ETL alternatives in 2025 helps teams boost efficiency and drive innovation. Modern ETL tools automate pipelines, improve data quality, and enable real-time processing. Teams should use the comparison matrix to guide their selection process. When evaluating new ETL solutions, consider scalability, ease of use, integration, transformation features, and security.
| Next Step | Description |
| Confirm business fit | Ensure the ETL tool matches your specific use case and data requirements. |
| Assess total cost | Review all costs, including licensing and scaling, to fit your budget. |
| Verify security | Check for strong encryption and compliance with regulations. |
Choosing the right ETL solution ensures data pipelines support both current and future business needs. Teams that keep learning and adapting will lead in the evolving data engineering landscape.
FAQ
What is the main difference between ETL and ELT?
ETL transforms data before loading it into a target system. ELT loads raw data first, then transforms it inside the data warehouse. ELT works best with cloud-based platforms that handle large data volumes.
How do open source ETL tools compare to commercial solutions?
Open source ETL tools offer flexibility and community support. Commercial solutions provide dedicated support, advanced features, and easier setup. Teams choose based on budget, technical skills, and project needs.
Which ETL tools support real-time data processing?
Many modern ETL tools support real-time processing. Examples include Apache NiFi, AWS Glue, Hevo, and Fivetran. These platforms help organizations process streaming data for immediate analytics and decision-making.
Can low-code ETL platforms handle complex data workflows?
Low-code ETL platforms simplify pipeline creation. They work well for standard workflows. For highly customized or complex logic, teams may need traditional or open source tools with more control.
What are the key security features in modern ETL tools?
Modern ETL tools offer encryption, role-based access control, audit logs, and compliance support. These features protect sensitive data and help organizations meet regulatory requirements.
How does reverse ETL benefit business teams?
Reverse ETL moves processed data from warehouses back into business applications. Sales, marketing, and support teams use this data for real-time insights, improved personalization, and faster decision-making.
What should teams consider before migrating to a new ETL platform?
Teams should assess data compatibility, connector support, security, and total cost. Testing pipelines in a safe environment and backing up data help ensure a smooth migration.
Are cloud-native ETL tools better for scalability?
Cloud-native ETL tools scale easily with growing data needs. They offer elastic resources, automatic updates, and integration with cloud services. These features make them ideal for organizations expecting rapid growth.
Subscribe to my newsletter
Read articles from Community Contribution directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by