Top Picks for Data Streaming Technologies and Tools in 2025
 Community Contribution
Community ContributionTable of contents
- Key Takeaways
- Data Streaming Technologies in 2025
- Top Streaming Analytics Tools
- Data Stream Processing Comparison
- Real-Time Data Enrichment
- Choosing the Right Data Streaming Solution
- Implementation Best Practices
- FAQ
- What is real-time data enrichment?
- How do bounded and unbounded streams differ?
- Which industries benefit most from data streaming technologies?
- What are the main challenges in implementing data streaming solutions?
- How does AI enhance data streaming platforms?
- Are open source or cloud-based streaming tools better?
- What security features do modern streaming platforms provide?
- Can data streaming tools integrate with existing analytics systems?

The top data streaming technologies for 2025 include Apache Kafka, Apache NiFi, AWS Glue, Google Cloud Dataflow, Estuary Flow, Amazon Kinesis, Apache Flink, Apache Spark, AutoMQ, and Snowflake. These streaming data tools deliver unmatched scalability, robust security, and seamless integration with modern enterprise systems. Each data streaming platform enables organizations to process streaming data at scale, supporting real-time data enrichment and analytics. Real-time data enrichment drives value by transforming streaming data into actionable insights. Real-time data, when enriched, powers advanced analytics, operational intelligence, and instant decision-making. Streaming data solutions now prioritize real-time data enrichment as a core feature, ensuring businesses achieve faster, smarter outcomes across all real-time workflows.
Key Takeaways
Data streaming technologies like Apache Kafka, AWS Glue, and Google Cloud Dataflow enable real-time data processing and enrichment for faster, smarter decisions.
Real-time data enrichment transforms streaming data into actionable insights, improving analytics, customer experiences, and operational efficiency.
Bounded streams handle finite data in batches, while unbounded streams process continuous data in real time, each suited for different business needs.
AI integration enhances streaming platforms by automating tasks, improving content quality, and boosting viewer engagement and operational efficiency.
Choosing the right streaming tool depends on factors like scalability, latency, security, integration, and cost to match specific business goals.
Open source tools offer flexibility and control but require more management, while cloud-based services provide ease of use and rapid scaling with pay-as-you-go pricing.
Strong security features such as encryption, access control, and compliance support protect sensitive streaming data and ensure regulatory adherence.
Effective planning, optimization, and continuous monitoring are essential to build reliable, scalable, and cost-efficient real-time data streaming pipelines.
Data Streaming Technologies in 2025
Real-Time Data Trends
Data streaming technologies have become essential in modern data streaming architecture. Enterprises rely on real-time data processing to drive instant insights and operational intelligence. Streaming data now powers live content formats across platforms such as YouTube, Facebook, Twitch, Instagram, and TikTok. E-sports live streaming and gamification attract younger audiences, while live stream eCommerce integrates shopping with video content on platforms like Pinterest and TikTok Shop. OTT platforms monetize streaming data through subscriptions and partnerships, offering original content to younger demographics.
Organizations prioritize real-time data pipelines that validate, cleanse, transform, and enrich streaming data. Monitoring and alerting mechanisms maintain pipeline health and reliability. Storage strategies balance scalability and performance for both real-time and historical data. Deployment flexibility allows enterprises to choose between managed cloud services and self-hosted environments, supporting data sovereignty and governance. Integration with orchestration tools and data science workflows embeds real-time data streams into broader analytical processes. Capacity-based pricing models help predict and control costs as real-time data initiatives scale.
Real-time data processing capabilities influence tool selection based on data volume, velocity, latency, scalability, data quality, security, and budget. Architectural trends include the convergence of streaming and batch processing, unified platforms like data lakehouses, and event-driven architectures. Decentralized data management approaches such as data mesh and data fabric improve real-time data accessibility and governance.
Bounded vs Unbounded Streams
Stream processing systems handle two main types of streaming data: bounded and unbounded streams. Bounded streams represent finite datasets processed in batches, while unbounded streams are infinite and require continuous real-time stream processing. The table below highlights key differences:
| Aspect | Bounded Data Streams (Batch Processing) | Unbounded Data Streams (Stream Processing) |
| Data Size | Finite dataset with a clear start and end | Infinite, continuous, and potentially never-ending |
| Processing Style | Batch processing: ingest all data before computation | Real-time or near-real-time continuous processing |
| Query Semantics | All data available at once | Data arrives over time, requiring incremental processing |
| State Management | Minimal state retention; can drop state after processing | Must retain state to handle late or out-of-order events |
| Use Cases | ETL, reporting, historical analytics | Real-time analytics, monitoring, alerting |
| Optimizations | Sorting, global aggregations, blocking operators possible | Requires event time processing, windowing, fault tolerance |
Batch processing suits historical analytics and scheduled jobs, offering high latency but reliable completion. Stream processing systems manage unbounded streams, enabling real-time decision-making with low latency. These differences shape processing strategies: batch jobs run during low resource usage periods, while real-time stream processing demands constant resource availability and fault tolerance.
AI Integration
Artificial intelligence transforms data streaming technologies in 2025. AI integration leverages machine learning, computer vision, and natural language processing to automate technical tasks, enhance content quality, and enable real-time analytics. Tools such as Restream + AI Analytics and Streamlabs AI provide background removal, noise cancellation, automated chat moderation, and personalized recommendations. Enterprises benefit from measurable improvements: up to 30% decrease in viewer dropout rates, 25-30% higher engagement, 20% increase in production quality, and 40% reduction in technical issues.
AI enables streaming data to multiple platforms simultaneously and delivers real-time insights for dynamic content adjustments. Real-world examples show companies increasing viewer engagement and production quality using AI-powered tools. Emerging trends include hyper-personalized experiences, AI co-hosts for moderation and content creation, immersive mixed reality integrations, and predictive analytics for forecasting engagement. Applied AI enhances operational efficiency, personalization, and decision-making in real-time data processing technologies, driving cost savings and productivity gains.
Top Streaming Analytics Tools
Apache Kafka
Features
Apache Kafka stands as a distributed event streaming platform designed for high-throughput, fault-tolerant, and scalable data pipelines. Kafka supports publish-subscribe messaging, stream processing, and persistent storage of event logs. The platform enables organizations to build robust architectures for real-time analytics and real-time data enrichment. Kafka Connect and Kafka Streams provide built-in connectors and stream processing capabilities, making integration with external systems seamless. The platform supports exactly-once semantics, strong durability, and horizontal scalability.
Use Cases
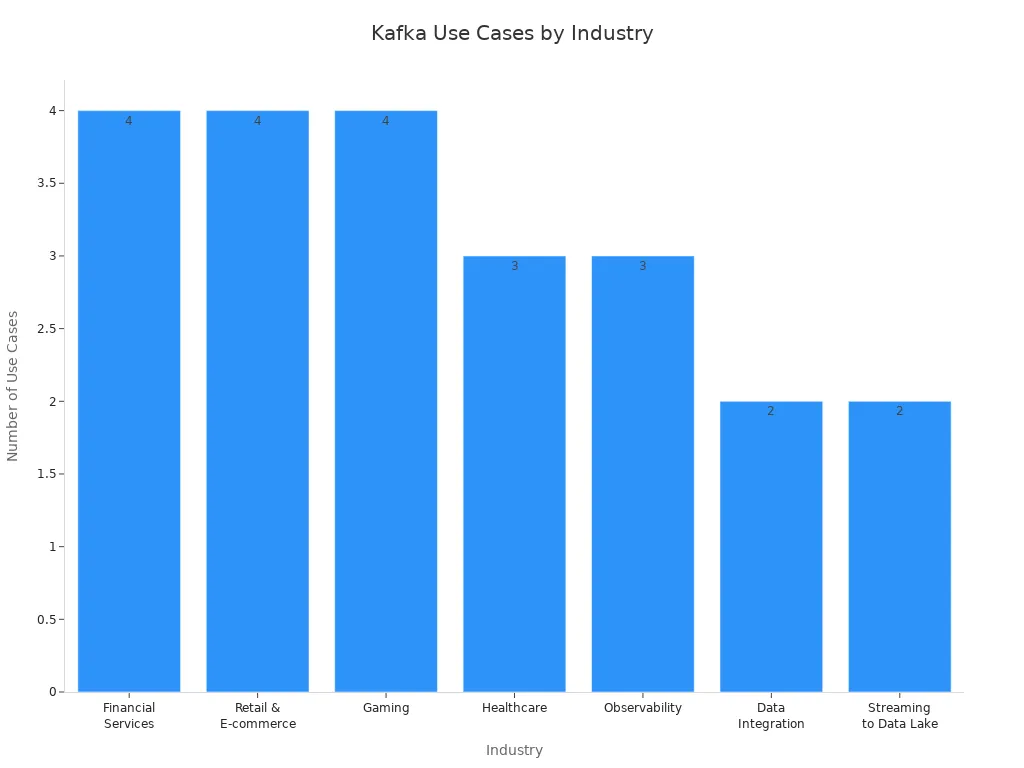
| Industry | Primary Use Cases & Applications | Real-life Examples / Notes |
| Financial Services | Real-time data processing, fraud detection, transaction monitoring, market analysis | Barclays, Jack Henry, Rabobank use Kafka for market monitoring and fraud detection |
| Retail & E-commerce | Real-time inventory updates, customer behavior analysis, personalized experiences, dynamic pricing | Walmart uses Kafka to process transaction data and adjust pricing dynamically |
| Gaming | Real-time player interaction analytics, in-game advertising, matchmaking, virtual goods markets | Devsisters and ironSource use Kafka for game service logs and real-time player action processing |
| Healthcare | Real-time patient data management, diagnostics, predictive analytics | Edenlab uses Kafka to manage patient records and support timely care |
| Observability | Operational monitoring, log aggregation, metrics collection | Kafka collects logs and metrics for real-time infrastructure and application health monitoring |
| Data Integration | Streaming data integration across systems, eliminating data silos | Kafka acts as a central hub for real-time data flow between transactional and analytical systems |
| Streaming to Data Lake | Real-time ingestion of data into data lakes for long-term analysis and machine learning | Kafka enables scalable, raw data storage in platforms like Amazon S3 or Azure Data Lake |
Strengths
Kafka delivers unmatched scalability and reliability for real-time analytics. The platform excels in real-time data enrichment, supporting high-volume streaming data analytics across diverse industries. Kafka’s ecosystem, including Confluent and open-source extensions, ensures rapid innovation and broad community support. Organizations leverage Kafka to unify data pipelines, reduce latency, and enable instant insights. Kafka’s architecture supports both streaming and batch workloads, making it a versatile choice for modern data analytics.
Apache NiFi
Features
Apache NiFi provides a powerful, web-based interface for automating the movement and transformation of data between systems. NiFi supports real-time data enrichment through its drag-and-drop flow designer, enabling users to build complex data flows without writing code. The platform offers over 300 processors for data ingestion, routing, transformation, and delivery. NiFi’s data provenance tracking ensures transparency and traceability for every data event. Built-in security features include SSL, authentication, and fine-grained access control.
Use Cases
Enterprises use NiFi to orchestrate real-time analytics pipelines, integrating data from IoT devices, cloud services, and on-premises systems.
Healthcare providers rely on NiFi for secure, real-time data enrichment of patient records and diagnostics.
Financial institutions automate regulatory reporting and fraud detection workflows using NiFi’s streaming analytics tools.
Retailers implement NiFi to synchronize inventory, customer, and transaction data across multiple platforms.
Strengths
NiFi stands out for its ease of use and rapid deployment. The platform enables organizations to implement real-time data enrichment and streaming analytics tools without deep programming expertise. NiFi’s visual interface accelerates development and troubleshooting. Its flexible architecture supports both batch and streaming data analytics, making it suitable for hybrid environments. NiFi’s robust security and data lineage features ensure compliance and operational transparency.
AWS Glue
Features
AWS Glue is a fully managed, serverless ETL service optimized for cloud-native data integration within the AWS ecosystem. Glue automates code generation for data extraction, transformation, and loading. The centralized Data Catalog enables unified metadata management across AWS services. Glue supports native connectors for Amazon S3, Redshift, Athena, DynamoDB, and RDS, streamlining integration for real-time analytics and real-time data enrichment workflows.
Use Cases
Organizations use AWS Glue to automate ETL pipelines for data lakes and data warehouses, enabling real-time analytics on AWS-native platforms.
Data engineers leverage Glue for real-time data enrichment of streaming data from Amazon Kinesis and change data capture (CDC) from AWS Database Migration Service.
Enterprises with large AWS footprints use Glue to centralize data analytics and reporting, reducing manual effort and operational overhead.
Strengths
AWS Glue excels in seamless integration with AWS-native services, providing a unified experience for cloud-based data analytics. The serverless architecture reduces infrastructure management and scales automatically with workload demands. Glue’s automation features accelerate real-time data enrichment and analytics, supporting rapid deployment of streaming analytics tools. However, Glue is less flexible for multi-cloud or hybrid scenarios and offers limited real-time streaming capabilities compared to specialized platforms like Google Cloud Dataflow or StreamSets.
Major players in the streaming analytics tools market in 2025 include Amazon Web Services, Microsoft Corporation, IBM Corporation, Oracle Corporation, SAP SE, TIBCO Software Inc., and Confluent. Product innovation and integration with cloud-native services drive adoption across industries.
Google Cloud Dataflow
Features
Google Cloud Dataflow delivers a fully managed service for building and operating data pipelines. The platform automates resource provisioning and management, reducing operational overhead for teams. Developers use a unified programming model to process both batch and streaming data within the same pipeline. Dataflow supports multiple SDKs, including Java, Python, and Go, which enables flexible development across different environments. The service integrates seamlessly with Google Cloud products such as BigQuery, Datastore, and Pub/Sub, allowing organizations to create comprehensive workflows for real-time data enrichment.
| Feature | Description |
| Fully Managed | Google Cloud handles resource provisioning and management, reducing operational overhead. |
| Unified Programming Model | Supports both batch and stream processing within the same pipeline. |
| Apache Beam SDK Support | Compatible with Java, Python, and Go SDKs for flexible development. |
| Seamless Google Cloud Integration | Integrates with BigQuery, Datastore, Pub/Sub, and other Google Cloud services. |
| Automatic Scaling | Dynamically scales resources based on workload demands. |
| Workflow Templates | Offers predefined and custom templates for easy pipeline creation and deployment. |
| Real-Time Low-Latency Processing | Enables real-time data processing with minimal delay. |
| Pay-as-You-Go Pricing | Charges based on actual compute and memory usage, optimizing cost efficiency. |
Use Cases
Organizations rely on Google Cloud Dataflow for a variety of data processing needs. Data engineers build ETL workflows that combine batch and streaming data, supporting unified pipelines for real-time analytics. Retailers use Dataflow to enrich transaction data in real time, enabling instant recommendations and personalized experiences. Healthcare providers process patient records and sensor data, ensuring timely interventions and improved outcomes. Financial institutions deploy Dataflow to monitor transactions and detect fraud as events occur. The platform’s integration with other Google Cloud services streamlines data movement and analysis, making it a preferred choice for cloud-based streaming analytics.
Strengths
Google Cloud Dataflow stands out for its scalability and automation. The platform automatically adjusts resources to handle fluctuating data volumes, ensuring consistent performance. Its unified programming model simplifies pipeline development, reducing complexity for teams managing both batch and streaming workloads. Dataflow’s tight integration with Google Cloud services enhances real-time data enrichment, supporting advanced analytics and operational intelligence. The pay-as-you-go pricing model helps organizations optimize costs, making Dataflow an efficient solution for real-time analytics and streaming analytics tools.
Estuary Flow
Features
Estuary Flow offers advanced capabilities for real-time data enrichment and unified data management. The platform integrates with Apache Iceberg, enabling real-time streaming into Iceberg tables. Estuary Flow supports schema evolution, allowing teams to modify data structures without disrupting pipelines. The service unifies batch and streaming workloads into a single table format, reducing operational complexity. Efficient data management features include partitioning, compaction, and organization, which optimize both cost and performance. Estuary Flow ensures data governance at scale, providing time-travel queries and data retention policies for compliance.
Streams data from sources like Kafka and Google Pub/Sub with consistency and zero data loss.
Offers over 200 pre-built connectors for rapid integration.
Handles schema changes in real-time streams without breaking pipelines.
Provides unified pipelines for batch and real-time data enrichment.
Optimizes scalability for cost and performance.
Use Cases
Enterprises use Estuary Flow to unify batch and streaming data for analytics and reporting. Retailers leverage the platform to enrich customer and transaction data in real time, supporting personalized marketing and inventory management. Financial organizations deploy Estuary Flow to monitor transactions and detect anomalies, improving risk management. Healthcare providers use the service to manage patient records and sensor data, enabling timely interventions. The platform’s integration with Apache Iceberg and support for schema evolution make it ideal for organizations seeking flexible, scalable solutions for real-time data enrichment.
Users report a learning curve when adopting Estuary Flow due to its advanced streaming features and terminology. The connector ecosystem, while extensive, remains limited compared to some competitors, especially for batch processing and legacy system integration. Cost concerns arise from unpredictable streaming volumes, which can lead to unexpected computing expenses. Documentation for complex connectors can be challenging, but most users find it manageable within minutes.
Strengths
Estuary Flow excels in unifying batch and streaming workloads, simplifying data management for enterprises. The platform’s support for schema evolution and real-time data enrichment ensures flexibility and reliability. Efficient partitioning and compaction features optimize performance and cost, making Estuary Flow suitable for large-scale deployments. Data governance capabilities, such as time-travel queries and retention policies, help organizations maintain compliance and operational transparency. Despite a learning curve and some limitations in connector breadth, Estuary Flow remains a powerful tool for streaming analytics tools and cloud-based streaming analytics.
Amazon Kinesis
Features
Amazon Kinesis provides a robust platform for real-time data enrichment and analytics at scale. The service handles massive data volumes and supports hundreds of thousands of data producers, making it ideal for organizations with high-throughput requirements. Kinesis operates as a serverless solution, allowing users to pay only for consumed resources and optimize costs. The platform integrates tightly with the AWS ecosystem, including S3, Redshift, and DynamoDB, facilitating efficient data storage, processing, and visualization. Kinesis offers automatic and seamless scalability, ensuring reliable performance during peak loads.
Enables real-time data streaming for immediate insights and faster decision-making.
Supports automatic scaling to handle fluctuating and large data volumes.
Provides cost-effectiveness through a pay-as-you-go pricing model.
Integrates with AWS services for comprehensive data workflows.
Ensures durability and reliability for mission-critical applications.
Use Cases
Streaming platforms such as Netflix use Amazon Kinesis to analyze viewer data in real time, optimizing content delivery and enhancing customer experiences. E-commerce companies monitor user interactions to personalize shopping and deliver targeted promotions. Financial institutions rely on Kinesis for fraud detection, analyzing transactions as they occur. Healthcare providers process patient data for timely interventions and improved outcomes. IoT applications leverage Kinesis to manage data from connected devices, supporting smart cities and industrial automation. Organizations across industries benefit from Kinesis’s ability to deliver real-time analytics and real-time data enrichment.
Strengths
Amazon Kinesis stands out for its scalability and reliability. The platform’s serverless architecture eliminates infrastructure limitations, allowing organizations to scale operations without manual intervention. Kinesis’s integration with AWS services streamlines data movement and analysis, supporting advanced real-time analytics and streaming analytics tools. The pay-as-you-go pricing model reduces upfront costs and ongoing maintenance, making Kinesis a cost-effective solution for cloud-based streaming analytics. Enhanced security and risk management features enable real-time threat detection and anomaly monitoring, ensuring continuous data availability for mission-critical workflows. Organizations achieve faster operational responses and improved customer experiences through real-time data enrichment.
Apache Flink
Features
Apache Flink delivers a powerful framework for real-time, stateful stream processing. The platform supports event-driven applications and complex event processing at scale. Flink’s architecture enables sub-second latency and high throughput, often reaching tens of millions of events per second. Developers benefit from advanced windowing, state management, and fault tolerance. Flink integrates with popular data sources and sinks, including Kafka, Kinesis, and various databases. The system supports both batch and streaming workloads, allowing organizations to unify their data processing pipelines.
Use Cases
Real-time analytics for telemetry and sensor data in IoT environments.
Anomaly detection in financial transactions and cybersecurity.
Monitoring and alerting for infrastructure and application health.
Complex event processing in logistics and supply chain management.
Real-time personalization and recommendation engines for e-commerce.
Flink’s event-driven model suits applications that require immediate insights and rapid response to changing data. Organizations in finance, telecommunications, and online services deploy Flink to power mission-critical analytics and operational dashboards.
Strengths
Apache Flink excels in low-latency, high-throughput stream processing.
The platform handles backpressure effectively through built-in flow control, maintaining stability under high load.
Flink’s event-driven architecture and stateful processing enable it to outperform Spark in real-time scenarios.
Benchmarks show Flink achieves lower latency than Spark, especially in use cases like telemetry analysis and anomaly detection.
Flink supports fault tolerance, scalability, and external state management, enabling sustained performance at scale.
Flink’s advanced stateful processing and windowing features make it ideal for applications that demand complex calculations and data consistency. Organizations choose Flink for real-time, stateful stream processing where accuracy and speed are critical.
Apache Spark
Features
Apache Spark provides a unified analytics engine for large-scale data processing. The platform supports both batch and streaming workloads through its Structured Streaming API. Spark offers in-memory computation, distributed processing, and seamless integration with machine learning libraries such as MLlib. The system connects to diverse data sources, including HDFS, S3, Kafka, and JDBC databases. Spark’s flexible programming model supports Python, Scala, Java, and R, making it accessible to a broad range of developers.
Use Cases
| Use Case Category | Description | Industry Examples & Results |
| Streaming ETL | Continuous cleaning and aggregation of streaming data before storage | General use case |
| Data Enrichment | Combining live streaming data with static data for real-time analysis | Online advertising: personalized, targeted ads in real-time |
| Trigger Event Detection | Detecting rare/unusual events for immediate response | Finance: real-time fraud detection; Healthcare: patient vital sign monitoring with automatic alerts |
| Complex Session Analysis | Grouping and analyzing live session events for insights and recommendations | Netflix: real-time user engagement insights and movie recommendations |
| Machine Learning | Running scalable ML algorithms for predictive intelligence, segmentation | Finance: customer churn reduction by 25%; Network security: real-time threat detection |
| Network Security | Real-time inspection of data packets for malicious activity | Security providers: evolving threat detection |
| Interactive Analysis | Fast exploratory queries and interactive analytics on live data | Spark 2.0 Structured Streaming enables interactive queries on live web sessions |
| Fog Computing & IoT | Distributed processing of sensor and machine data for IoT applications | Emerging use case for managing massive IoT data streams |
Organizations such as Netflix process 450 billion events daily for real-time recommendations. Financial institutions have reduced customer churn by 25% using Spark. Media companies like Conviva improved video streaming quality and reduced churn by managing billions of video feeds monthly.
Strengths
Spark stands out for its versatility and scalability. The platform handles both batch and streaming data, supporting a wide range of analytics and machine learning workloads. Spark’s in-memory processing delivers fast performance for large datasets. The system integrates with popular data sources and visualization tools, enabling interactive analytics. Organizations benefit from Spark’s robust ecosystem, active community, and proven track record in production environments.
Spark Structured Streaming is optimized for batch processing but can handle streaming workloads with higher latency compared to Flink. Spark’s strength lies in its ability to unify data processing, machine learning, and interactive analytics within a single platform.
AutoMQ
Features
AutoMQ introduces a modern approach to data streaming with a storage-computation separation architecture. The platform leverages shared storage based on S3, allowing independent scaling of compute and storage resources. AutoMQ employs second-level partition migration technology, enabling rapid elasticity and swift traffic balancing during scale-out or scale-in operations. The system isolates storage and computation, preventing cold read operations from impacting write throughput. AutoMQ automates traffic rebalancing and scaling based on cluster traffic and CPU metrics, dynamically adding or removing broker nodes.
Use Cases
Large-scale observability platforms requiring zero downtime during peak events.
Real-time analytics for e-commerce and financial services with fluctuating workloads.
Cloud-native data streaming solutions seeking cost optimization and operational efficiency.
Scenarios demanding rapid scaling and stable performance under high concurrency.
In a real-world deployment, Poizon’s observability platform used AutoMQ to sustain 100% traffic load with zero downtime during peak events. The organization reduced cloud billing costs by over 50% and replaced nearly a thousand cores of computing resources while maintaining tens of GiB/s throughput.
Strengths
AutoMQ’s storage-computation separation architecture avoids scalability constraints and costly data duplication seen in traditional systems.
The platform achieves about five times better cold read performance than Kafka, even under high concurrency, without affecting real-time writes.
Second-level partition migration ensures near-instantaneous scaling and traffic balancing.
AutoMQ delivers significant cost reductions, improved resource utilization, and operational efficiency.
The system maintains stable performance under peak loads, making it suitable for mission-critical, cloud-native streaming analytics.
AutoMQ differentiates itself from legacy streaming systems by offering rapid elasticity, automated scaling, and superior cold read efficiency. Organizations seeking high performance and cost savings in cloud environments increasingly adopt AutoMQ for their streaming analytics needs.
Snowflake
Features
Snowflake delivers a cloud-native data platform that supports both batch and streaming analytics. The architecture separates storage and compute, which allows organizations to scale workloads independently. Snowflake Streams enable change data capture (CDC) for tracking inserts, updates, and deletes in near real time. Snowpipe Streaming ingests data continuously, making it possible to build event-driven pipelines and automate data flows. Dynamic Tables and Hybrid Tables provide flexible options for managing both streaming and batch data within the same environment.
Key features include:
Near real-time ingestion with Snowpipe Streaming.
Change data capture using Streams for automated transformations.
Hybrid Tables for rapid inserts and transactional workloads.
Dynamic Tables for scheduled or automated data refreshes.
Separation of storage and compute for parallel processing and cost management.
Integration with cloud ecosystems for seamless data movement.
Snowflake’s platform supports event-driven architectures and real-time dashboards, enabling decision-makers to access live metrics and insights.
Use Cases
Organizations deploy Snowflake for a variety of streaming analytics scenarios. Retailers use Snowflake to personalize customer experiences by analyzing live transaction data. Financial institutions monitor transactions for fraud detection and anomaly identification. Media companies power real-time dashboards to track user engagement and optimize content delivery. Healthcare providers integrate Snowflake with IoT devices to process patient data and trigger timely interventions.
| Industry | Streaming Analytics Use Case | Benefit |
| Retail | Real-time personalization | Improved customer engagement |
| Finance | Fraud detection and anomaly monitoring | Faster response to suspicious activity |
| Media | Live dashboards for user engagement | Optimized content delivery |
| Healthcare | IoT data integration for patient monitoring | Timely interventions and alerts |
| Operations | Automated event-driven pipelines | Streamlined workflows and reporting |
Snowflake’s support for CDC and automated transformations helps organizations maintain up-to-date data models and respond quickly to changing business conditions.
Strengths
Snowflake offers flexibility and ease of use for streaming analytics. The platform’s separation of storage and compute allows teams to scale workloads as needed, supporting both batch and streaming data flows. Users benefit from simplified pipeline management and integration with cloud services. Snowflake enables real-time dashboards, live metrics, and automated event processing, which drive operational efficiency and informed decision-making.
However, Snowflake faces challenges with very large data volumes and high concurrency typical in streaming analytics. The distributed MPP design can introduce data skew and network latency, which may impact performance. Tuning options remain limited, often requiring increased compute resources or data reduction strategies, leading to higher costs. Snowflake is not optimized for ultra-low-latency, sub-second event processing, so organizations with rapid event scenarios may encounter bottlenecks. Frequent ingestion and scaling demand strong DevOps and DataOps practices to maintain data integrity and control expenses.
Snowflake provides a robust foundation for near real-time streaming analytics, but users must carefully design and monitor pipelines to balance performance, cost, and complexity. The platform excels in flexibility and integration, yet scaling for high-volume, high-concurrency workloads requires strategic planning and ongoing optimization.
Data Stream Processing Comparison
Performance
Performance remains a critical factor in evaluating data stream processing systems. Apache Kafka and Amazon Kinesis both deliver high-throughput, low-latency real-time data processing. Kafka, as an open-source distributed platform, offers flexibility through partitioning and replication. Organizations often choose Kafka for its ability to handle massive streaming data processing workloads and support real-time data enrichment. Kinesis, managed by AWS, provides automatic scaling and minimal operational overhead, making it suitable for businesses seeking serverless real-time stream processing. Both platforms integrate seamlessly with stream processing systems like Apache Flink, which excels in sub-second latency and stateful real-time processing.
Apache Flink stands out for unified batch and stream processing. It supports advanced operators for filtering, mapping, and windowing, enabling real-time data enrichment and real-time insights. Flink’s architecture allows organizations to process millions of events per second, making it ideal for real-time analytics and complex event-driven applications. Real-time stream processing systems such as Flink and Spark Structured Streaming deliver consistent performance for streaming data processing, supporting both historical and live data analysis.
Real-time data processing platforms must maintain low latency and high throughput to support real-time insights and operational intelligence. The choice between self-hosted and managed services impacts performance, with managed platforms like Kinesis offering on-demand scaling and reduced DevOps effort.
Scalability
Scalability defines the ability of data stream processing systems to handle increasing data volumes and velocity. In 2025, organizations rely on real-time data enrichment using cloud services like AWS Lake Formation and Amazon Kinesis. These platforms support continuous ingestion and transformation, enabling immediate access to high-quality data for analytics and machine learning. Gartner reports that 71% of organizations require real-time data to make informed decisions, and 75% will use real-time analytics by 2025.
Data streaming technologies now replace traditional batch processing with real-time stream processing, reducing latency and supporting high-velocity data flows. Enterprises leverage unified storage architectures optimized for AI workloads, such as Dell PowerScale, to scale real-time data enrichment and real-time processing. The adoption of managed, serverless streaming data processing services allows pipelines to scale dynamically, supporting seamless ingestion, transformation, and loading into cloud storage solutions.
Approximately 90% of the largest global businesses use data stream processing to improve services and customer experience. Scalable architectures enable organizations to process petabyte-scale data and deliver real-time insights without performance degradation.
Integration
Integration capabilities play a vital role in the effectiveness of stream processing systems. Leading platforms offer extensive connectors for cloud data warehouses and analytics tools. Informatica PowerCenter provides low-code and no-code workflow simplification, supporting integration with AWS, Azure, and Google Cloud. Estuary automates schema evolution and handles both batch and streaming data processing, enabling real-time data enrichment across diverse sources and destinations.
Fivetran and Matillion deliver automated data integration with pre-built connectors for Snowflake, BigQuery, and Redshift. These platforms support real-time replication and transformation, ensuring that organizations can maintain up-to-date analytics environments. Modern stream processing systems provide REST APIs, webhook support, and secure pipelines for integrating with ERP, CRM, and accounting systems.
| Tool / Platform | Integration Capabilities and Features |
| RudderStack | Real-time data streaming at scale; routes processed data to 200+ destinations including data warehouses, dashboards, and business apps. |
| Apache Flink | Stateful stream processing with low latency; integrates with modern data warehouses for real-time analytics. |
| Apache Spark Structured Streaming | Unified batch and stream processing; supports integration with cloud data warehouses and analytics platforms. |
| Materialize | SQL interfaces for streaming data enabling direct querying and integration with analytics platforms. |
| Debezium | Open-source CDC tool capturing real-time database changes; streams data into analytics platforms and warehouses. |
Integration and automation capabilities extend the reach of real-time data enrichment, allowing organizations to connect stream processing systems with popular analytics platforms and business applications.
Cost
Cost plays a significant role when organizations select data streaming technologies. Each platform offers different pricing models, which can affect budgets and long-term planning. Managed cloud services such as Amazon Kinesis and Google Cloud Dataflow use pay-as-you-go pricing. This model allows companies to pay only for the resources they consume. Serverless architectures help reduce infrastructure costs and maintenance. Organizations often choose these platforms for real-time data enrichment because they can scale up or down without large upfront investments.
Open-source solutions like Apache Kafka and Apache Flink provide flexibility. Companies can deploy these tools on-premises or in the cloud. While open-source platforms eliminate licensing fees, they require investment in hardware, skilled personnel, and ongoing support. Real-time data enrichment with open-source tools may lead to unpredictable costs if data volumes spike or if scaling becomes necessary. Enterprises must consider the total cost of ownership, including hardware, software, and operational expenses.
Snowflake and AWS Glue offer cost optimization features. Snowflake separates storage and compute, allowing teams to manage costs by scaling resources independently. AWS Glue automates ETL processes, which reduces manual effort and operational overhead. Both platforms support real-time data enrichment, but frequent scaling or high concurrency can increase expenses. Companies must monitor usage patterns and optimize pipelines to avoid unexpected charges.
AutoMQ introduces cost savings through storage-computation separation. This architecture enables organizations to scale compute and storage independently, which reduces resource duplication. Real-time data enrichment becomes more efficient, and companies can achieve better performance without overspending. Estuary Flow also helps manage costs by unifying batch and streaming workloads. Efficient partitioning and compaction features optimize resource usage, making real-time data enrichment more affordable.
Pricing transparency and predictability remain important. Organizations should evaluate pricing calculators, capacity-based models, and usage dashboards. These tools help teams forecast expenses and adjust strategies for real-time data enrichment. Cost management features such as automated scaling, resource tagging, and budget alerts support financial planning. Companies benefit from reviewing contract terms and service-level agreements to ensure alignment with business goals.
Tip: Regularly review pipeline performance and data volumes. Optimize resource allocation to maintain cost efficiency while supporting real-time data enrichment.
Security
Security stands as a top priority for organizations processing streaming data. Leading data streaming platforms provide advanced features to protect sensitive information and ensure compliance. Companies rely on these tools to support real-time data enrichment while maintaining privacy and regulatory standards.
Real-time visibility and control over sensitive data help organizations monitor data flows in platforms such as Confluent, Kafka, Amazon Kinesis, and Google Cloud Pub/Sub.
Discovery and classification of sensitive data allow teams to identify and manage information as it moves downstream. This process supports secure real-time data enrichment.
Governance of data access uses roles and permissions to enforce least privilege. Only authorized users can access sensitive streams, which reduces risk during real-time data enrichment.
Dynamic masking of sensitive data within streams protects privacy. Organizations maintain business insights while limiting exposure during real-time data enrichment.
Management of sensitive data sprawl involves discovering sensitive data in messaging topics. Centralized data scanning prevents uncontrolled proliferation and supports secure real-time data enrichment.
Automation of data privacy operations streamlines compliance. Features include data mapping, handling data subject requests, conducting assessments, managing consent, and responding to breaches. These capabilities enhance real-time data enrichment workflows.
Integration with major cloud platforms such as AWS, GCP, Azure, Databricks, and Snowflake supports hybrid and multicloud environments. Secure real-time data enrichment extends across diverse infrastructures.
Compliance with global privacy regulations such as GDPR, CPRA, LGPD, PIPEDA, and PIPL ensures organizations meet legal requirements during real-time data enrichment.
Advanced features include data security posture management, AI security and governance, data access intelligence, breach impact analysis, and data flow governance. These tools strengthen privacy and compliance in real-time data enrichment environments.
Security features must evolve as threats change. Organizations should implement monitoring, alerting, and auditing for all real-time data enrichment pipelines. Encryption, authentication, and fine-grained access controls protect data at rest and in transit. Regular security assessments and updates help maintain a strong defense against emerging risks.
Note: Security and compliance require ongoing attention. Teams should stay informed about new regulations and best practices to safeguard real-time data enrichment processes.
Real-Time Data Enrichment
Enrichment Tools
Organizations in 2025 rely on advanced enrichment tools to enhance real-time data pipelines and deliver real-time insights. These platforms automate data validation, integrate with popular CRMs, and support scalable real-time data ingestion. The following table highlights leading enrichment tools and their effectiveness:
| Tool Name | Key Effectiveness Evidence | Accuracy/Performance Metrics | AI & Automation Features | Integration & Pricing Highlights | Market Impact & Case Studies |
| Clearbit AI | Real-time enrichment, CRM integrations, customizable fields | Robust AI, not quantified | Automated validation, customizable fields | Salesforce, HubSpot; tiered pricing | 25% market growth; lead enrichment, customer profiling |
| ZoomInfo Intelligence Cloud | Over 95% accuracy in B2B contact data, improved sales | \>95% accuracy | NLP, machine learning extraction | 100+ integrations; customized pricing | Increased qualified leads, customer interactions |
| People Data Labs (PDL) | 1.5B+ profiles, AI-powered filtering and verification | AI filtering supports accuracy | API-first, scalable integration | API pricing, free tier; cost-effective | 25% market growth; large-scale enrichment |
| Lusha Intelligence Platform | Real-time contact verification, machine learning algorithms | Up to 95% accuracy | ML for accuracy and completeness | Focus on real-time verification | 95% accuracy supports effectiveness |
| SuperAGI Enrichment Suite | Agent-based AI, automated enrichment, continuous learning | High accuracy, not quantified | AI agents learn and improve | Integration, security, compliance | 30% increase in customer engagement for enrichment tool users |
These data ingestion tools offer robust data integration capabilities, supporting real-time data processing across diverse environments. AI-powered automation and customizable workflows enable organizations to maintain high data quality and accuracy in real-time data pipelines.
Use Cases
Companies deploy real-time data enrichment to power a wide range of real-time applications. They use change data capture and event-driven architectures to create always-on real-time data pipelines. These pipelines support millisecond-level data freshness, which is essential for AI-driven decision-making and real-time data processing applications.
Real-time analytics: Teams analyze large volumes of data instantly to drive quick decisions.
IoT data processing: Organizations monitor and respond to events from IoT devices in real time.
Log aggregation: IT departments collect and process logs for system monitoring and troubleshooting.
Personalized customer experiences: Businesses track session state and use real-time data to deliver targeted recommendations and advertising.
Dynamic data enrichment: Data teams augment datasets with information from demographics, social media, or market data.
AI-driven decision-making: Enterprises leverage fresh data to support AI models and automated decisions.
Netflix, Amazon, and Uber use real-time data enrichment to gain faster insights and improve customer experience. Netflix analyzes viewer behavior to personalize recommendations. Amazon tailors product suggestions using real-time purchase and browsing data. Uber optimizes pricing and routing by instantly analyzing traffic and demand patterns.
Gartner reports a 10-15% revenue increase and a 5-10% cost reduction for companies using real-time data enrichment. Forrester finds a 20-30% improvement in customer satisfaction and a 10-20% increase in customer loyalty. A MongoDB survey shows 70% of companies consider real-time data enrichment critical, with 60% already using it to drive decisions.
Benefits
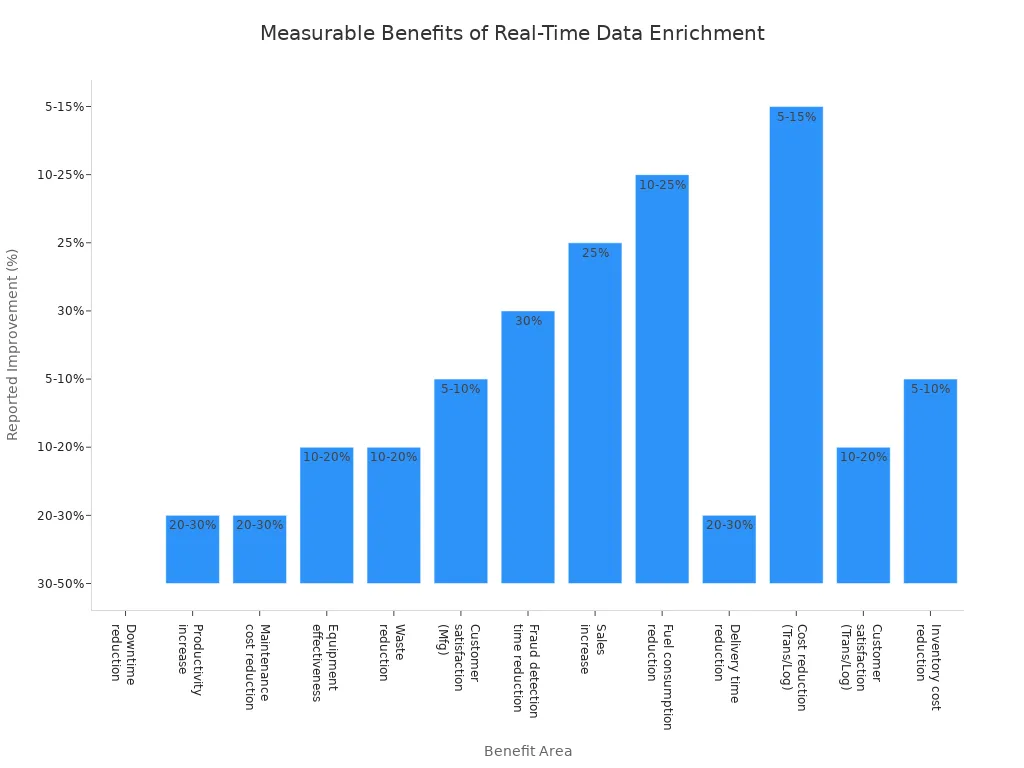
Real-time data enrichment delivers measurable improvements across industries. Manufacturing companies report a 30-50% reduction in downtime and a 20-30% increase in productivity. Financial services achieve a 30% reduction in fraud detection time and automate manual processes for greater efficiency. Retailers see a 25% increase in sales after implementing real-time data processing. Transportation and logistics firms reduce fuel consumption by up to 25% and delivery times by 30%. Customer satisfaction rises by 10-20% in logistics and manufacturing.
| Industry | Benefit Area | Measurable Benefit | Source/Example |
| Manufacturing | Downtime reduction | 30-50% reduction in downtime | MarketsandMarkets |
| Manufacturing | Productivity increase | 20-30% increase in productivity | MarketsandMarkets |
| Manufacturing | Maintenance cost reduction | 20-30% reduction in maintenance costs | Sigmoid Analytics |
| Manufacturing | Equipment effectiveness | 10-20% increase | Sigmoid Analytics |
| Manufacturing | Waste reduction | 10-20% reduction in waste | Cognex |
| Manufacturing | Customer satisfaction | 5-10% increase | Cognex |
| Financial Services | Fraud detection time | 30% reduction in fraud detection time | SuperAGI client example |
| Financial Services | Operational efficiency | Automation of manual processes, improved efficiency | General industry observation |
| Retail | Sales increase | 25% increase in sales | SuperAGI client example |
| Transportation/Logistics | Fuel consumption reduction | 10-25% reduction in fuel consumption | McKinsey, Routed |
| Transportation/Logistics | Delivery time reduction | 20-30% reduction in delivery times | Routed, DHL |
| Transportation/Logistics | Cost reduction | 5-15% reduction in transportation/logistics costs | McKinsey, DHL |
| Transportation/Logistics | Customer satisfaction | 10-20% improvement | Gartner |
| Transportation/Logistics | Inventory cost reduction | 5-10% reduction | Gartner |
Real-time data processing and real-time data ingestion enable organizations to respond quickly to market changes and optimize operations. Real-time insights from enriched data drive better decision-making and improve customer experience. Companies that invest in real-time data enrichment gain a competitive edge in data analytics and real-time applications.
Choosing the Right Data Streaming Solution
Business Needs
Organizations must align their data streaming technology with core business objectives. The right solution supports real-time data enrichment, enabling teams to act on fresh insights and drive data-driven decision making. Decision makers should evaluate several criteria before selecting a platform. The following table outlines key considerations:
| Criterion | Description & Key Considerations |
| Pipeline Functionality | Supports log-based change data capture, in-flight transformations, and schema evolution for real-time data enrichment. |
| Ease of Use | Reduces development effort through automation, intuitive interfaces, and modular pipeline reconfiguration. |
| Support for Unstructured Data | Ingests and transforms unstructured data, such as text or images, for AI workflows and real-time analytics. |
| Ecosystem Integration | Connects with diverse data sources, targets, formats, and programming languages to future-proof real-time data enrichment. |
| Governance | Tracks data lineage, manages metadata, enforces access control, and protects sensitive data during real-time data enrichment. |
| Performance & Scalability | Delivers low latency, high throughput, and scales on demand for real-time data enrichment and analytics. |
Business leaders should prioritize platforms that enable real-time data enrichment and seamless integration with existing systems. Solutions must support rapid adaptation to changing market demands and facilitate data-driven decision making across departments.
Technical Requirements
Technical requirements shape the effectiveness of any data streaming solution. Enterprises need platforms that deliver real-time data enrichment and support both structured and unstructured data. The following features are essential:
Latency service-level agreements must define which operations fall within the real-time window.
Integration with streaming and batch sources ensures a unified data ecosystem for real-time analytics.
Immediate access to historical streamed data supports continuous real-time data enrichment.
Flexible retention and deletion policies allow granular control over data lifecycle.
Streaming data should connect to ontology objects, providing semantic context for real-time interpretation.
Versioning and branching of streamed data enable granular replay and collaboration.
Real-time transformation capabilities allow continuous builds and rapid integration of new datasets.
Architecture should include ingestion, transformation, and consumption components for real-time data enrichment.
Pre-built connectors to popular streaming sources reduce integration costs and accelerate deployment.
Event-driven architectures, multi-tiered storage, container orchestration, and load testing ensure robust enterprise deployment.
Technical teams must select solutions that support real-time data enrichment, maintain low latency, and provide fault tolerance. These capabilities ensure reliable data-driven decision making and operational efficiency.
Scalability
Scalability determines how well a data streaming platform handles growth in data volume and velocity. Modern organizations require solutions that support real-time data enrichment at scale. Key scalability features include:
Horizontal scaling and partitioning to manage increasing data volumes for real-time analytics.
Low latency processing to minimize delays and support immediate real-time insights.
Fault tolerance mechanisms to ensure data integrity and recovery during failures.
High throughput to process large streams efficiently and maintain real-time data enrichment.
Stateful processing for complex event correlation and advanced real-time analytics.
Adoption of event-driven architectures enhances flexibility and scalability.
Multi-tiered storage strategies optimize cost and performance for real-time data enrichment.
Container orchestration, such as Kubernetes, enables scalable and fault-tolerant deployments.
Regular load testing and performance tuning maintain system reliability and efficiency.
Organizations must choose platforms that scale seamlessly and support real-time data enrichment as business needs evolve. Scalable solutions empower teams to maintain data-driven decision making and respond quickly to new opportunities.
Cost Factors
Cost plays a central role when organizations select a data streaming solution for real-time data enrichment. Each platform introduces unique expenses that impact both short-term budgets and long-term financial planning. Open source tools such as Apache Kafka often require significant management overhead. Teams must handle cluster administration, performance monitoring, and ongoing maintenance. These tasks demand skilled personnel, which increases operational costs. Integration with other systems may also require additional software and developer resources, especially when building custom connectors for real-time data enrichment.
Cloud-based streaming services, including managed Kafka or Amazon Kinesis, shift the cost model. These platforms eliminate upfront hardware investments and reduce the need for in-house expertise. Instead, organizations pay subscription or licensing fees, which can rise as data volumes grow. Data transfer costs in cloud environments often become substantial, particularly for high-throughput real-time data enrichment pipelines. Performance benchmarks reveal that open source Kafka may need larger clusters to meet strict latency targets, which further increases infrastructure expenses.
A careful cost analysis should consider the following:
Initial setup and deployment costs, including hardware or cloud resource provisioning.
Ongoing operational expenses, such as monitoring, scaling, and support for real-time data enrichment.
Integration and customization costs for connecting to diverse data sources and analytics platforms.
Data transfer and storage fees, which can escalate with large-scale real-time data enrichment.
Potential savings from automation, serverless architectures, or unified batch and streaming pipelines.
Tip: Regularly review usage patterns and optimize resource allocation. This practice helps control costs while maintaining the performance required for real-time data enrichment.
Open Source vs Cloud
Choosing between open source and cloud-based data streaming solutions shapes flexibility, control, and total cost of ownership for real-time data enrichment. Open source platforms, such as OpenStack or Apache Kafka, provide complete control over hardware and software. Organizations avoid vendor lock-in and can customize every aspect of their real-time data enrichment pipelines. However, these benefits come with high initial investments and longer deployment times. Teams must possess deep technical expertise to manage and scale these systems.
Cloud-based solutions, such as AWS or Google Cloud Dataflow, offer rapid deployment and managed services. These platforms abstract infrastructure complexity, allowing organizations to focus on real-time data enrichment rather than system maintenance. Pay-as-you-go pricing models remove upfront costs but may lead to higher expenses at scale. Vendor lock-in becomes a concern as integration with cloud ecosystems deepens.
The following table summarizes key differences:
| Factor | Open Source (OpenStack) | Cloud-Based (AWS) |
| Initial Investment | High upfront costs for hardware, deployment expertise, and operations | No upfront costs; pay-as-you-go pricing |
| Total Cost of Ownership | Lower costs at scale due to ownership and no recurring platform fees | Higher costs at scale; costs increase with usage, including data transfer and support fees |
| Flexibility | Complete control and customization; no vendor lock-in; full hardware and software control | Limited control; constrained by managed services; vendor lock-in due to ecosystem integration |
| Deployment Time | Weeks to months due to setup complexity | Minutes for basic resources; rapid deployment |
| Vendor Lock-in | None; fully portable and open source | High; integration and operational practices create switching barriers |
| Operational Model | Self-managed; requires deep technical expertise | Managed services; abstracts infrastructure complexity |
| Real-World Examples | CERN handles massive custom configurations and scale; PayPal chose OpenStack for vendor independence | Netflix migrated to AWS for operational simplicity and rapid scaling despite lock-in risks |
Open source solutions suit organizations that prioritize flexibility and control in real-time data enrichment. Cloud-based platforms appeal to those seeking convenience, scalability, and faster time to value. The right choice depends on business priorities, technical resources, and the scale of real-time data enrichment initiatives.
Implementation Best Practices
Planning
Effective planning forms the foundation of successful data streaming projects. Large organizations must address several critical factors to ensure robust and scalable solutions. Teams begin by defining clear objectives for real-time data enrichment. They identify business goals, target use cases, and expected outcomes. This approach helps align technical requirements with organizational priorities.
Project leaders select appropriate tools and technologies based on scalability, fault tolerance, and integration capabilities. Platforms such as Apache Kafka, Apache Flink, and Spark Streaming offer proven support for real-time data enrichment. Teams evaluate each option for compatibility with existing systems and future growth.
Organizations optimize data processing pipelines to reduce latency and increase throughput. They use in-memory processing, parallel execution, and efficient serialization. These techniques enable rapid real-time data enrichment and support high-volume workloads. Engineers design ingestion pipelines that handle both structured and unstructured data, ensuring flexibility for evolving business needs.
Error handling and recovery mechanisms play a vital role in maintaining reliability. Teams implement error detection, automatic retries, and failover support. These features protect real-time data enrichment workflows from disruptions and data loss. Resilient architectures, such as Kafka replication and distributed processing, further enhance system stability.
Data quality and consistency remain essential for accurate insights. Teams enforce validation, cleansing, and schema management throughout the pipeline. Anomaly detection tools identify irregularities before they impact real-time data enrichment. Schema evolution strategies allow data models to change without breaking downstream consumers, supporting backward compatibility.
Scalability drives long-term success. Organizations enable dynamic scaling of clusters to accommodate fluctuating data volumes. Backpressure mechanisms help manage producer-consumer speed mismatches, preventing bottlenecks and data loss. Disaster recovery and backup strategies, including data replication across availability zones, ensure business continuity for real-time data enrichment.
Edge computing offers additional benefits for IoT scenarios. Processing data at the source reduces latency and bandwidth usage. This approach supports real-time data enrichment for sensor networks and remote devices.
Expert tips such as event sourcing help maintain immutable event logs. These logs assist with debugging and state rebuilding, providing transparency for real-time data enrichment. Continuous monitoring of pipelines allows teams to identify bottlenecks and optimize performance. Fine-tuning configurations ensures that real-time data enrichment remains efficient and reliable.
Tip: Early collaboration between business stakeholders and technical teams accelerates project delivery. Clear communication of requirements and constraints leads to better outcomes for real-time data enrichment initiatives.
Key Planning Checklist
Define business objectives and use cases for real-time data enrichment.
Select scalable, fault-tolerant tools and platforms.
Optimize ingestion pipelines for low latency and high throughput.
Implement robust error handling and recovery mechanisms.
Enforce data quality, validation, and schema management.
Design for resilience, scalability, and disaster recovery.
Incorporate edge computing for IoT and remote data sources.
Use event sourcing and schema evolution for flexibility.
Monitor pipelines continuously and fine-tune configurations.
A well-structured planning process ensures that organizations achieve reliable, scalable, and secure real-time data enrichment. Teams that follow these best practices deliver actionable insights and maintain operational excellence.
Optimization
Optimization plays a vital role in maximizing the value of data streaming technologies. Teams must focus on improving every stage of the pipeline to achieve efficient real-time data enrichment. Engineers analyze bottlenecks and identify areas where latency or throughput can be improved. They use profiling tools to monitor resource consumption and pinpoint inefficient operations.
Organizations often implement the following optimization strategies:
Partitioning and Parallelism: Teams divide workloads into smaller partitions. This approach allows systems to process data in parallel, which increases throughput and supports scalable real-time data enrichment.
Resource Allocation: Engineers allocate CPU, memory, and storage based on workload demands. Dynamic scaling ensures that real-time data enrichment pipelines remain responsive during peak usage.
Windowing and State Management: Developers use windowing techniques to group events and manage state efficiently. This method reduces memory usage and improves the accuracy of real-time data enrichment.
Backpressure Handling: Systems must handle backpressure to prevent overload. By controlling the flow of data, teams maintain stability and ensure consistent real-time data enrichment.
Serialization and Compression: Optimized serialization formats and data compression reduce network traffic. These techniques speed up real-time data enrichment and lower infrastructure costs.
Tip: Regular performance reviews help teams identify new optimization opportunities. Continuous improvement ensures that real-time data enrichment pipelines adapt to changing business needs.
The following table summarizes common optimization techniques and their impact on real-time data enrichment:
| Optimization Technique | Impact on Real-Time Data Enrichment |
| Partitioning | Increases throughput and scalability |
| Dynamic Scaling | Maintains responsiveness during peak loads |
| Windowing | Improves accuracy and reduces memory usage |
| Backpressure Handling | Prevents system overload and data loss |
| Compression | Speeds up data transfer and lowers costs |
Engineers also automate pipeline tuning using machine learning models. These models predict resource requirements and adjust configurations for optimal real-time data enrichment. Automated alerts notify teams when performance drops, allowing quick intervention.
Code optimization remains essential. Developers refactor inefficient code and remove unnecessary computations. They use efficient algorithms to process streaming data, which enhances real-time data enrichment.
Organizations benefit from regular load testing. Simulated workloads reveal weaknesses in the pipeline. Teams use these insights to strengthen real-time data enrichment and maintain high performance.
Continuous monitoring and feedback loops drive ongoing optimization. Teams set clear metrics for latency, throughput, and error rates. They track these metrics to ensure that real-time data enrichment meets business objectives.
Note: Optimization is not a one-time effort. Teams must revisit strategies as data volumes and business requirements evolve. Proactive optimization guarantees that real-time data enrichment delivers consistent value.
A comparative analysis of streaming frameworks reveals that Apache Flink delivers the lowest latency and efficient CPU usage, while Apache Spark leads in throughput but uses more memory. The table below summarizes key findings:
| Framework | Latency | Throughput | Resource Usage | Popularity |
| Flink | Lowest | High | Low CPU | High |
| Spark | Higher | Highest | High Memory | Highest |
| Storm | Moderate | Moderate | Low Memory | Moderate |
Selecting the right platform for real-time data enrichment ensures that organizations meet both technical and business goals. Teams should pilot solutions, consult experts, and monitor emerging trends. Real-time data enrichment drives operational excellence, supports real-time analytics, and enables organizations to respond quickly to change. Real-time data enrichment remains essential for competitive advantage. Real-time data enrichment improves decision-making and customer experience. Real-time data enrichment supports scalable, reliable pipelines. Real-time data enrichment enables seamless integration with analytics tools. Real-time data enrichment reduces latency and increases throughput. Real-time data enrichment ensures data quality and compliance. Real-time data enrichment optimizes resource usage. Real-time data enrichment supports innovation. Real-time data enrichment prepares organizations for future growth. Real-time data enrichment remains a top priority for data-driven enterprises.
FAQ
What is real-time data enrichment?
Real-time data enrichment adds context or value to streaming data as it flows through a pipeline. Teams use this process to improve data quality, support analytics, and enable faster business decisions.
How do bounded and unbounded streams differ?
Bounded streams contain a fixed amount of data and support batch processing. Unbounded streams have no defined end and require continuous processing. Each type suits different analytics and operational needs.
Which industries benefit most from data streaming technologies?
Industries such as finance, retail, healthcare, manufacturing, and media gain significant advantages. They use streaming tools for fraud detection, personalized marketing, patient monitoring, and operational efficiency.
What are the main challenges in implementing data streaming solutions?
Teams face challenges with scalability, integration, security, and cost management. They must also ensure low latency, high throughput, and data quality across complex environments.
How does AI enhance data streaming platforms?
AI automates data processing, improves anomaly detection, and enables predictive analytics. It helps organizations personalize experiences, optimize operations, and respond quickly to changing data patterns.
Are open source or cloud-based streaming tools better?
Open source tools offer flexibility and control. Cloud-based solutions provide rapid deployment and managed services. The best choice depends on business needs, technical skills, and budget.
What security features do modern streaming platforms provide?
Modern platforms offer encryption, access controls, data masking, and compliance tools. These features protect sensitive information and help organizations meet regulatory requirements.
Can data streaming tools integrate with existing analytics systems?
Most leading platforms support integration with data warehouses, BI tools, and machine learning frameworks. Teams can connect streaming data to existing analytics environments for unified insights.
Subscribe to my newsletter
Read articles from Community Contribution directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by