Step-by-Step Guide to Creating your own AI Music Recommendation System with Hybrid Algorithms
 Roberto
Roberto
By Roberto
The fast track:
To export your playlist for individual analysis: https://exportify.net/ and use the service I created go to: https://popmusic.streamlit.app/ for accuracy get the Last.fm key, otherwise will only recommend music from your own history
What you need:
A Spotify Account
A last.fm key - free
Clone the GIT Repo if you like:https://github.com/soyroberto/mostlistened
Introduction
In the era of digital music streaming, the ability to discover new music that aligns with personal taste has become both an art and a science. While platforms like Spotify and Apple Music have sophisticated recommendation engines, building your own personalized music recommendation system offers unprecedented insights into your listening patterns and the opportunity to understand the intricate algorithms that power modern music discovery.
This comprehensive technical guide explores the development of a sophisticated music recommendation system that combines multiple machine learning approaches: collaborative filtering, content-based filtering, temporal analysis, and context-aware recommendations. The system processes over 11 years of personal Spotify listening data, encompassing more than 140,000 plays across 10,894 unique artists, totaling 6,488 hours of listening time.
What makes this system particularly compelling is its hybrid approach to recommendation generation. Rather than relying on a single algorithm, it employs an ensemble of four distinct machine learning techniques, each capturing different aspects of musical preference and listening behavior. The system integrates real-time data from external APIs, provides interactive visualizations through a modern web interface, and offers granular control over recommendation parameters through innovative features like artist tier selection.
The technical implementation leverages Python's robust data science ecosystem, including pandas for data manipulation, scikit-learn for machine learning algorithms, Streamlit for the web interface, and external APIs from Last.fm and MusicBrainz for enriched music metadata. The architecture demonstrates how to build scalable, maintainable recommendation systems that can process large datasets while providing real-time interactive experiences.
This article provides a complete technical walkthrough of the system's architecture, algorithms, and implementation details. We'll explore the mathematical foundations of each recommendation approach, examine the code implementations with detailed explanations, and provide practical guidance for replicating this system with your own music data. Whether you're a data scientist interested in recommendation systems, a music enthusiast curious about algorithmic music discovery, or a developer looking to build similar applications, this guide offers both theoretical insights and practical implementation strategies.
System Architecture Overview
The music recommendation system employs a sophisticated multi-layered architecture designed for scalability, maintainability, and real-time performance. The system can be conceptually divided into five primary components: data ingestion and processing, machine learning engine, API integration layer, user interface, and security and configuration management.
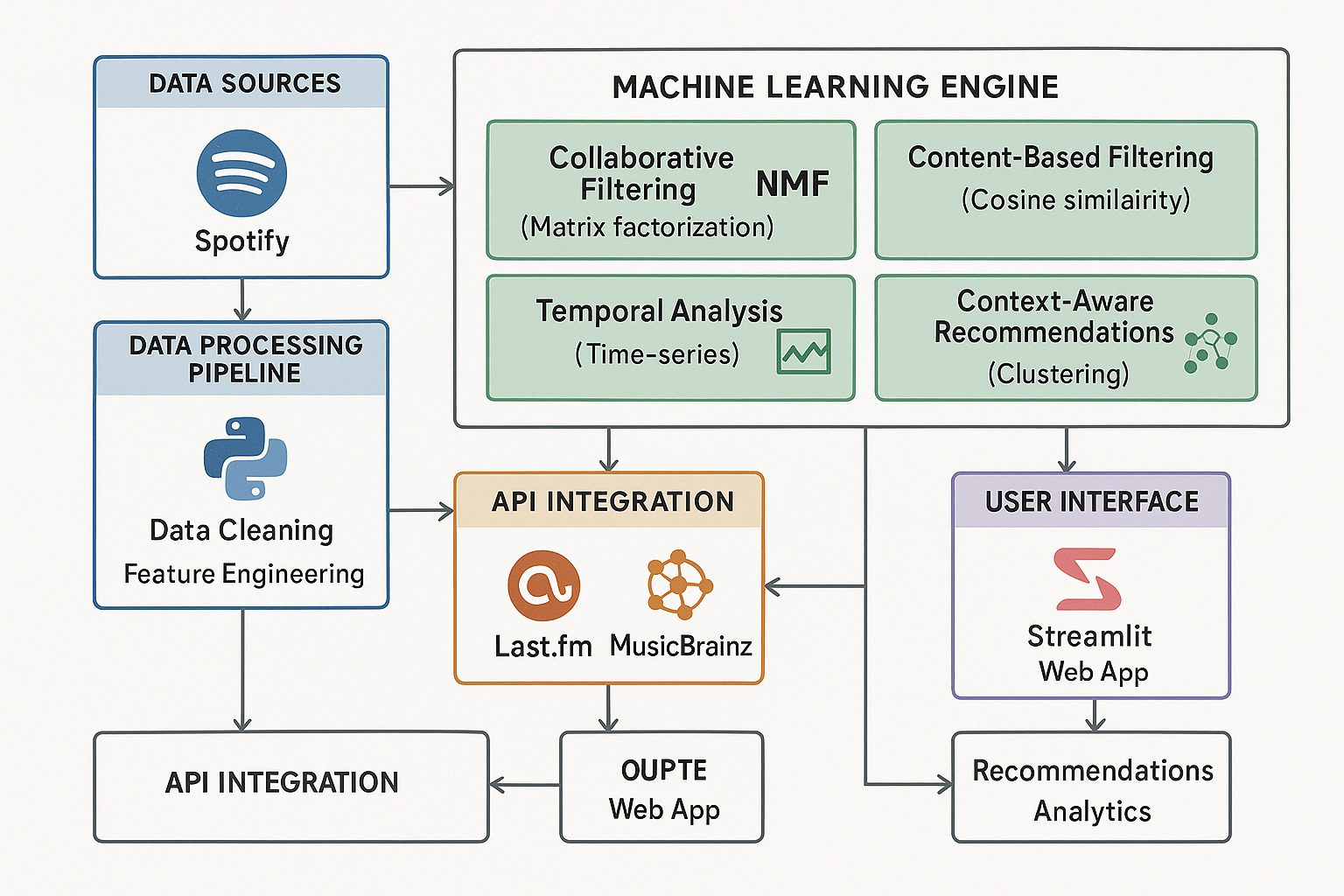
The data ingestion layer handles the processing of Spotify's exported JSON files, which contain detailed listening history including timestamps, track metadata, and engagement metrics. These files typically follow the naming convention Streaming_History_Audio_YYYY-YYYY_N.json, where the years indicate the data range and N represents the file sequence number. The system automatically discovers and processes all JSON files in the designated data directory, handling various file formats and edge cases such as missing metadata or corrupted entries.
The data processing pipeline implements comprehensive data cleaning and feature engineering. Raw Spotify data undergoes several transformation stages: timestamp parsing and normalization, engagement score calculation based on listening duration, temporal feature extraction (hour of day, day of week, seasonality), and artist preference scoring using a weighted ensemble approach. The engagement scoring algorithm is particularly sophisticated, calculating completion rates for each track and normalizing them to create meaningful preference signals.
The machine learning engine represents the core of the recommendation system, implementing four distinct algorithms that operate in parallel. The collaborative filtering component uses Non-Negative Matrix Factorization (NMF) to decompose the user-artist interaction matrix into latent factors, enabling the discovery of hidden patterns in listening behavior. The content-based filtering system leverages external music metadata from Last.fm to calculate artist similarity using cosine similarity measures. The temporal analysis component applies time-series analysis techniques to model how musical taste evolves over time, while the context-aware system uses clustering algorithms to identify listening patterns based on temporal and situational contexts.
The API integration layer provides seamless connectivity to external music databases and services. The system integrates with Last.fm's comprehensive music database to retrieve artist similarity data, top tracks, and detailed music metadata. MusicBrainz integration provides additional metadata enrichment and music taxonomy information. The API layer implements sophisticated rate limiting, caching mechanisms, and error handling to ensure reliable operation even with large-scale data processing requirements.
The user interface layer is built using Streamlit, providing an interactive web application that enables real-time exploration of music data and recommendation generation. The interface supports advanced features including artist tier selection for targeted recommendations, interactive search functionality with expandable song lists, hover-based similar artist discovery, and comprehensive data visualization with filtering capabilities.
Data Structure and Schema Analysis
Understanding the structure of Spotify's exported data is crucial for building effective recommendation algorithms. The system processes data from multiple sources, each providing different types of information about listening behavior and music characteristics.
Spotify Listening History Schema
The primary data source consists of JSON files exported from Spotify, containing detailed listening history with the following key fields:
| Field Name | Data Type | Description | Example Value |
ts | ISO 8601 Timestamp | When the track was played | "2023-08-15T14:30:22Z" |
master_metadata_track_name | String | Track title | "Bohemian Rhapsody" |
master_metadata_album_artist_name | String | Primary artist name | "Queen" |
master_metadata_album_album_name | String | Album title | "A Night at the Opera" |
ms_played | Integer | Milliseconds played | 354000 |
reason_start | String | How playback started | "fwdbtn", "trackdone" |
reason_end | String | How playback ended | "trackdone", "fwdbtn" |
shuffle | Boolean | Shuffle mode status | true/false |
skipped | Boolean | Track was skipped | true/false |
The ms_played field is particularly valuable for calculating engagement metrics. The system uses this data to determine listening completion rates, which serve as a proxy for track preference. A track played for its full duration indicates higher engagement than one that was skipped after a few seconds.
Enhanced Music Metadata Schema
For more sophisticated analysis, the system can also process enhanced Spotify data that includes audio features and detailed metadata:
| Field Name | Data Type | Range | Description |
danceability | Float | 0.0-1.0 | How suitable for dancing |
energy | Float | 0.0-1.0 | Intensity and power measure |
valence | Float | 0.0-1.0 | Musical positivity (happy vs sad) |
acousticness | Float | 0.0-1.0 | Acoustic vs electric confidence |
instrumentalness | Float | 0.0-1.0 | Vocal content prediction |
tempo | Float | 50-200+ | Beats per minute |
loudness | Float | -60 to 0 | Overall loudness in dB |
speechiness | Float | 0.0-1.0 | Spoken word detection |
These audio features enable content-based filtering approaches that can identify musical similarity based on acoustic characteristics rather than just collaborative patterns.
Data Quality and Preprocessing
The preprocessing pipeline addresses several data quality challenges commonly found in exported Spotify data. Missing metadata is handled through multiple strategies: tracks with missing artist or title information are filtered out, while missing album information is preserved but flagged. Duplicate detection removes exact duplicate entries while preserving legitimate repeated listens of the same track at different times.
Engagement calculation represents one of the most sophisticated preprocessing steps. The system calculates multiple engagement metrics for each track:
# Engagement score calculation
engagement_score = min(ms_played / 30000, 1.0) # 30 seconds = full engagement
completion_rate = ms_played / track_duration if track_duration > 0 else 0
weighted_engagement = (engagement_score * 0.7) + (completion_rate * 0.3)
This approach recognizes that different tracks have different optimal listening durations, and a 30-second listen of a 3-minute song represents different engagement than 30 seconds of a 10-minute progressive rock epic.
Temporal feature engineering extracts multiple time-based features that enable sophisticated temporal analysis:
# Temporal feature extraction
df['hour'] = df['timestamp'].dt.hour
df['day_of_week'] = df['timestamp'].dt.dayofweek
df['month'] = df['timestamp'].dt.month
df['year'] = df['timestamp'].dt.year
df['is_weekend'] = df['day_of_week'].isin([5, 6])
df['time_of_day'] = pd.cut(df['hour'], bins=[0, 6, 12, 18, 24],
labels=['night', 'morning', 'afternoon', 'evening'])
These features enable the system to identify patterns like "morning commute music" versus "late-night study sessions" and generate context-appropriate recommendations.
Machine Learning Algorithms Deep Dive
The recommendation system employs four distinct machine learning approaches, each designed to capture different aspects of musical preference and listening behavior. This ensemble approach ensures robust recommendations that account for collaborative patterns, content similarity, temporal evolution, and contextual preferences.
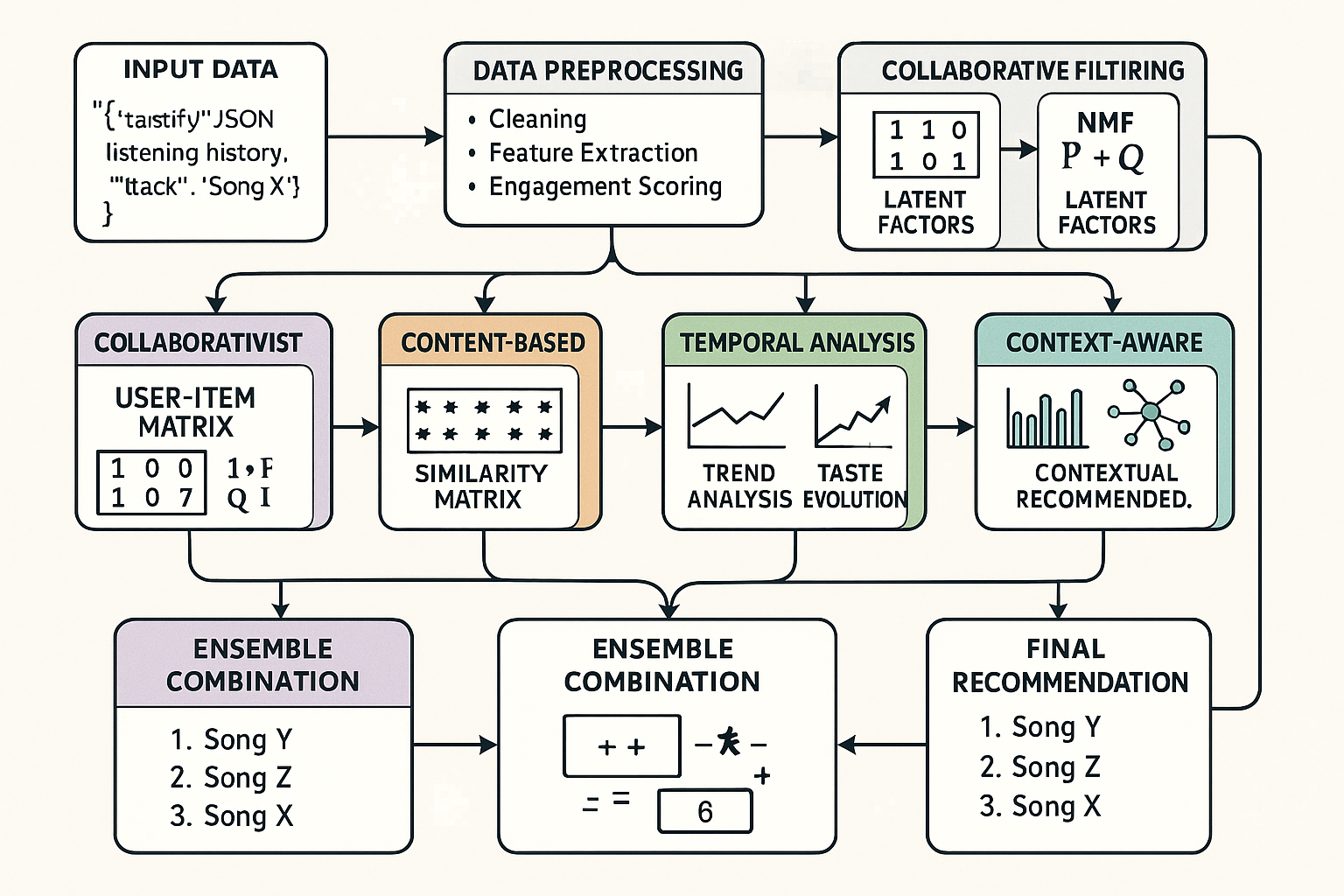
Collaborative Filtering with Non-Negative Matrix Factorization
The collaborative filtering component forms the foundation of the recommendation system, using Non-Negative Matrix Factorization (NMF) to discover latent factors in listening behavior. This approach is particularly effective for music recommendation because it can identify subtle patterns in listening preferences that may not be apparent from explicit ratings or simple play counts.
Mathematical Foundation
NMF decomposes the user-artist interaction matrix V into two lower-dimensional matrices W and H, such that V ≈ W × H. In our single-user system, the matrix V represents the relationship between time periods (rows) and artists (columns), with values representing listening intensity during specific time windows.
The factorization seeks to minimize the reconstruction error using the Frobenius norm:
min ||V - WH||²_F + α(||W||²_F + ||H||²_F)
Where α is a regularization parameter that prevents overfitting by penalizing large values in the factor matrices.
Implementation Details
The system implements temporal collaborative filtering by creating time-windowed interaction matrices. Rather than treating all listening history as a single static preference profile, the algorithm segments listening data into temporal windows (typically monthly or quarterly periods) and analyzes how preferences evolve over time.
def create_temporal_matrices(df, window_size='3M'):
"""Create time-windowed user-artist matrices for temporal analysis"""
temporal_matrices = []
# Group data by time windows
df_sorted = df.sort_values('timestamp')
time_groups = df_sorted.groupby(pd.Grouper(key='timestamp', freq=window_size))
for period, group_df in time_groups:
if len(group_df) < 10: # Skip periods with insufficient data
continue
# Create artist interaction matrix for this period
artist_stats = group_df.groupby('artist').agg({
'engagement_score': 'sum',
'track': 'count'
}).reset_index()
# Calculate preference intensity
artist_stats['preference_intensity'] = (
artist_stats['engagement_score'] * 0.6 +
np.log1p(artist_stats['track']) * 0.4
)
temporal_matrices.append({
'period': period,
'matrix': artist_stats,
'total_listening': len(group_df)
})
return temporal_matrices
The NMF decomposition is performed using scikit-learn's implementation with custom parameters optimized for music data:
from sklearn.decomposition import NMF
def perform_nmf_decomposition(interaction_matrix, n_components=50):
"""Perform NMF decomposition on user-artist interaction matrix"""
# Initialize NMF with music-optimized parameters
nmf_model = NMF(
n_components=n_components,
init='nndsvd', # Non-negative SVD initialization
solver='cd', # Coordinate descent solver
beta_loss='frobenius',
max_iter=1000,
alpha=0.1, # L1 regularization
l1_ratio=0.5, # Balance between L1 and L2 regularization
random_state=42
)
# Fit the model and extract factor matrices
W = nmf_model.fit_transform(interaction_matrix)
H = nmf_model.components_
# Calculate reconstruction quality
reconstruction_error = nmf_model.reconstruction_err_
return {
'W': W, # Time period factors
'H': H, # Artist factors
'model': nmf_model,
'error': reconstruction_error,
'explained_variance': calculate_explained_variance(interaction_matrix, W, H)
}
Temporal Prediction and Trend Analysis
The temporal collaborative filtering system goes beyond static recommendations by predicting future preferences based on historical trends. The algorithm analyzes how latent factors change over time and extrapolates these trends to generate forward-looking recommendations.
def predict_future_preferences(temporal_factors, prediction_horizon=6):
"""Predict future music preferences based on temporal trends"""
predictions = {}
for artist_idx, artist_name in enumerate(artist_mapping):
# Extract time series for this artist across all periods
artist_series = [factors['H'][artist_idx] for factors in temporal_factors]
if len(artist_series) < 3: # Need minimum data for trend analysis
continue
# Fit trend model (linear regression with seasonal components)
X = np.arange(len(artist_series)).reshape(-1, 1)
y = np.array(artist_series)
# Use robust regression to handle outliers
from sklearn.linear_model import HuberRegressor
trend_model = HuberRegressor(epsilon=1.35)
trend_model.fit(X, y)
# Predict future values
future_X = np.arange(len(artist_series),
len(artist_series) + prediction_horizon).reshape(-1, 1)
future_predictions = trend_model.predict(future_X)
# Calculate confidence intervals
residuals = y - trend_model.predict(X)
std_error = np.std(residuals)
predictions[artist_name] = {
'predicted_preference': np.mean(future_predictions),
'trend_slope': trend_model.coef_[0],
'confidence_interval': 1.96 * std_error, # 95% CI
'trend_strength': abs(trend_model.coef_[0]) / std_error
}
return predictions
This temporal prediction capability enables the system to identify artists whose appeal is growing in the user's preferences, even if their current listening frequency is relatively low.
Content-Based Filtering with External API Integration
The content-based filtering system leverages external music databases to understand musical similarity based on acoustic features, genre classifications, and collaborative tagging data. This approach is particularly valuable for discovering new artists that share musical characteristics with known preferences, even if they have no collaborative filtering signals.
Last.fm API Integration
The system integrates with Last.fm's comprehensive music database, which provides artist similarity data based on collaborative tagging and listening patterns from millions of users worldwide. The API integration implements sophisticated rate limiting and caching to handle large-scale data processing efficiently.
class LastFMAPI:
def __init__(self, api_key, cache_dir='cache/lastfm'):
self.api_key = api_key
self.base_url = 'http://ws.audioscrobbler.com/2.0/'
self.cache_dir = cache_dir
self.session = requests.Session()
self.rate_limiter = RateLimiter(calls_per_second=5) # Respect API limits
# Create cache directory
os.makedirs(cache_dir, exist_ok=True)
def get_similar_artists(self, artist_name, limit=50):
"""Retrieve similar artists with caching and error handling"""
# Check cache first
cache_key = f"similar_{hashlib.md5(artist_name.encode()).hexdigest()}"
cache_file = os.path.join(self.cache_dir, f"{cache_key}.json")
if os.path.exists(cache_file):
with open(cache_file, 'r') as f:
return json.load(f)
# Rate limiting
self.rate_limiter.wait()
# API request
params = {
'method': 'artist.getsimilar',
'artist': artist_name,
'api_key': self.api_key,
'format': 'json',
'limit': limit
}
try:
response = self.session.get(self.base_url, params=params, timeout=10)
response.raise_for_status()
data = response.json()
if 'similarartists' in data and 'artist' in data['similarartists']:
similar_artists = self._parse_similar_artists(data['similarartists']['artist'])
# Cache the results
with open(cache_file, 'w') as f:
json.dump(similar_artists, f)
return similar_artists
except requests.exceptions.RequestException as e:
logger.warning(f"API request failed for {artist_name}: {e}")
return []
return []
def _parse_similar_artists(self, artists_data):
"""Parse and normalize similar artists data"""
if not isinstance(artists_data, list):
artists_data = [artists_data]
similar_artists = []
for artist in artists_data:
if isinstance(artist, dict) and 'name' in artist:
similarity_score = float(artist.get('match', 0))
similar_artists.append({
'name': artist['name'],
'similarity': similarity_score,
'mbid': artist.get('mbid', ''),
'url': artist.get('url', '')
})
return sorted(similar_artists, key=lambda x: x['similarity'], reverse=True)
Similarity Matrix Construction
The content-based system constructs a comprehensive similarity matrix that captures relationships between all artists in the user's listening history. This matrix serves as the foundation for generating content-based recommendations.
def build_artist_similarity_matrix(artist_list, lastfm_api):
"""Build comprehensive artist similarity matrix"""
n_artists = len(artist_list)
similarity_matrix = np.zeros((n_artists, n_artists))
artist_to_idx = {artist: idx for idx, artist in enumerate(artist_list)}
# Progress tracking for large datasets
with tqdm(total=n_artists, desc="Building similarity matrix") as pbar:
for i, source_artist in enumerate(artist_list):
similar_artists = lastfm_api.get_similar_artists(source_artist)
for similar_data in similar_artists:
target_artist = similar_data['name']
similarity_score = similar_data['similarity']
if target_artist in artist_to_idx:
j = artist_to_idx[target_artist]
similarity_matrix[i][j] = similarity_score
similarity_matrix[j][i] = similarity_score # Symmetric matrix
pbar.update(1)
# Normalize the similarity matrix
similarity_matrix = normalize_similarity_matrix(similarity_matrix)
return similarity_matrix, artist_to_idx
def normalize_similarity_matrix(matrix):
"""Normalize similarity matrix using cosine normalization"""
# Add small epsilon to avoid division by zero
epsilon = 1e-8
norms = np.linalg.norm(matrix, axis=1, keepdims=True) + epsilon
# Cosine normalization
normalized_matrix = matrix / norms
# Ensure diagonal elements are 1.0 (self-similarity)
np.fill_diagonal(normalized_matrix, 1.0)
return normalized_matrix
Content-Based Recommendation Generation
The content-based recommendation algorithm uses the similarity matrix to identify artists that are musically similar to the user's preferred artists, weighted by listening intensity and recency.
def generate_content_based_recommendations(user_preferences, similarity_matrix,
artist_mapping, n_recommendations=50):
"""Generate content-based recommendations using artist similarity"""
recommendation_scores = {}
# Weight user preferences by recency and intensity
weighted_preferences = calculate_weighted_preferences(user_preferences)
for source_artist, preference_weight in weighted_preferences.items():
if source_artist not in artist_mapping:
continue
source_idx = artist_mapping[source_artist]
# Get similarity scores for this artist
similarities = similarity_matrix[source_idx]
for target_idx, similarity_score in enumerate(similarities):
target_artist = list(artist_mapping.keys())[target_idx]
# Skip self-recommendations and already known artists
if target_artist == source_artist or target_artist in user_preferences:
continue
# Calculate weighted recommendation score
recommendation_score = preference_weight * similarity_score
if target_artist in recommendation_scores:
recommendation_scores[target_artist] += recommendation_score
else:
recommendation_scores[target_artist] = recommendation_score
# Sort and return top recommendations
sorted_recommendations = sorted(recommendation_scores.items(),
key=lambda x: x[1], reverse=True)
return sorted_recommendations[:n_recommendations]
def calculate_weighted_preferences(user_preferences, recency_weight=0.3):
"""Calculate weighted preferences considering recency and intensity"""
current_time = datetime.now()
weighted_prefs = {}
for artist, pref_data in user_preferences.items():
# Base preference from listening intensity
base_preference = pref_data['total_engagement']
# Recency weight (more recent listening gets higher weight)
last_played = pref_data['last_played']
days_since = (current_time - last_played).days
recency_factor = np.exp(-days_since / 365) # Exponential decay over year
# Combine base preference with recency
weighted_preference = (
base_preference * (1 - recency_weight) +
base_preference * recency_factor * recency_weight
)
weighted_prefs[artist] = weighted_preference
return weighted_prefs
This content-based approach is particularly effective for discovering new artists in familiar genres or with similar musical characteristics, providing recommendations that feel musically coherent with existing preferences.
Temporal Analysis and Taste Evolution Modeling
The temporal analysis component represents one of the most innovative aspects of the recommendation system, recognizing that musical taste is not static but evolves continuously over time. This system tracks how preferences change across different time scales—from daily listening patterns to long-term taste evolution over years—and uses this information to generate temporally-aware recommendations.
Time-Series Analysis of Musical Preferences
The temporal analysis begins by decomposing listening history into multiple time scales: circadian patterns (hour-of-day preferences), weekly cycles (weekday vs. weekend listening), seasonal variations (monthly and yearly patterns), and long-term trends (multi-year taste evolution). Each time scale reveals different aspects of listening behavior and enables different types of recommendations.
class TemporalAnalyzer:
def __init__(self, listening_data):
self.df = listening_data.copy()
self.df['timestamp'] = pd.to_datetime(self.df['timestamp'])
self._extract_temporal_features()
def _extract_temporal_features(self):
"""Extract comprehensive temporal features from listening data"""
# Basic temporal features
self.df['hour'] = self.df['timestamp'].dt.hour
self.df['day_of_week'] = self.df['timestamp'].dt.dayofweek
self.df['month'] = self.df['timestamp'].dt.month
self.df['year'] = self.df['timestamp'].dt.year
self.df['quarter'] = self.df['timestamp'].dt.quarter
# Cyclical encoding for periodic features
self.df['hour_sin'] = np.sin(2 * np.pi * self.df['hour'] / 24)
self.df['hour_cos'] = np.cos(2 * np.pi * self.df['hour'] / 24)
self.df['day_sin'] = np.sin(2 * np.pi * self.df['day_of_week'] / 7)
self.df['day_cos'] = np.cos(2 * np.pi * self.df['day_of_week'] / 7)
self.df['month_sin'] = np.sin(2 * np.pi * self.df['month'] / 12)
self.df['month_cos'] = np.cos(2 * np.pi * self.df['month'] / 12)
# Contextual time periods
self.df['is_weekend'] = self.df['day_of_week'].isin([5, 6])
self.df['is_workday'] = ~self.df['is_weekend']
self.df['time_of_day'] = pd.cut(self.df['hour'],
bins=[0, 6, 12, 18, 24],
labels=['night', 'morning', 'afternoon', 'evening'],
include_lowest=True)
def analyze_circadian_patterns(self):
"""Analyze hour-of-day listening patterns for each artist"""
circadian_patterns = {}
for artist in self.df['artist'].unique():
artist_data = self.df[self.df['artist'] == artist]
# Calculate listening intensity by hour
hourly_listening = artist_data.groupby('hour').agg({
'engagement_score': 'sum',
'track': 'count'
}).reset_index()
# Normalize by total listening for this artist
total_engagement = hourly_listening['engagement_score'].sum()
hourly_listening['normalized_engagement'] = (
hourly_listening['engagement_score'] / total_engagement
)
# Identify peak listening hours
peak_hours = hourly_listening.nlargest(3, 'normalized_engagement')['hour'].tolist()
# Calculate circadian rhythm strength (how concentrated listening is)
entropy = -np.sum(hourly_listening['normalized_engagement'] *
np.log(hourly_listening['normalized_engagement'] + 1e-8))
rhythm_strength = 1 - (entropy / np.log(24)) # Normalized entropy
circadian_patterns[artist] = {
'hourly_distribution': hourly_listening.to_dict('records'),
'peak_hours': peak_hours,
'rhythm_strength': rhythm_strength,
'preferred_time_of_day': self._classify_time_preference(peak_hours)
}
return circadian_patterns
def _classify_time_preference(self, peak_hours):
"""Classify artist preference by time of day"""
time_categories = {
'morning': list(range(6, 12)),
'afternoon': list(range(12, 18)),
'evening': list(range(18, 24)),
'night': list(range(0, 6))
}
category_scores = {}
for category, hours in time_categories.items():
category_scores[category] = len(set(peak_hours) & set(hours))
return max(category_scores, key=category_scores.get)
Long-Term Taste Evolution Analysis
The system implements sophisticated algorithms to track how musical taste evolves over extended periods. This analysis identifies trends in genre preferences, artist discovery patterns, and the introduction of new musical elements into listening habits.
def analyze_taste_evolution(self, window_size='6M', min_periods=3):
"""Analyze long-term evolution of musical taste"""
evolution_data = {}
# Create rolling time windows
time_windows = pd.date_range(
start=self.df['timestamp'].min(),
end=self.df['timestamp'].max(),
freq=window_size
)
window_profiles = []
for i, window_start in enumerate(time_windows[:-1]):
window_end = time_windows[i + 1]
window_data = self.df[
(self.df['timestamp'] >= window_start) &
(self.df['timestamp'] < window_end)
]
if len(window_data) < 10: # Skip windows with insufficient data
continue
# Calculate artist preferences for this window
artist_preferences = window_data.groupby('artist').agg({
'engagement_score': 'sum',
'track': 'count',
'ms_played': 'sum'
}).reset_index()
# Normalize preferences
total_engagement = artist_preferences['engagement_score'].sum()
artist_preferences['preference_strength'] = (
artist_preferences['engagement_score'] / total_engagement
)
# Calculate diversity metrics
diversity_score = self._calculate_diversity(artist_preferences)
window_profile = {
'period': window_start,
'artist_preferences': artist_preferences.to_dict('records'),
'diversity_score': diversity_score,
'total_artists': len(artist_preferences),
'total_listening_time': window_data['ms_played'].sum() / (1000 * 60 * 60) # hours
}
window_profiles.append(window_profile)
# Analyze trends across windows
evolution_trends = self._analyze_evolution_trends(window_profiles)
return {
'window_profiles': window_profiles,
'evolution_trends': evolution_trends,
'taste_stability': self._calculate_taste_stability(window_profiles)
}
def _analyze_evolution_trends(self, window_profiles):
"""Identify trends in taste evolution"""
trends = {
'diversity_trend': [],
'artist_discovery_rate': [],
'preference_stability': [],
'genre_evolution': []
}
for i in range(1, len(window_profiles)):
current_window = window_profiles[i]
previous_window = window_profiles[i-1]
# Diversity trend
diversity_change = (current_window['diversity_score'] -
previous_window['diversity_score'])
trends['diversity_trend'].append(diversity_change)
# Artist discovery rate (new artists as percentage of total)
current_artists = set([a['artist'] for a in current_window['artist_preferences']])
previous_artists = set([a['artist'] for a in previous_window['artist_preferences']])
new_artists = current_artists - previous_artists
discovery_rate = len(new_artists) / len(current_artists) if current_artists else 0
trends['artist_discovery_rate'].append(discovery_rate)
# Preference stability (correlation between consecutive periods)
stability = self._calculate_preference_correlation(current_window, previous_window)
trends['preference_stability'].append(stability)
# Calculate trend statistics
trend_analysis = {}
for trend_name, trend_data in trends.items():
if trend_data:
trend_analysis[trend_name] = {
'mean': np.mean(trend_data),
'std': np.std(trend_data),
'trend_slope': self._calculate_trend_slope(trend_data),
'trend_strength': self._calculate_trend_strength(trend_data)
}
return trend_analysis
Temporal Recommendation Generation
The temporal analysis enables sophisticated recommendation strategies that consider both current context and predicted future preferences. The system can generate different types of temporal recommendations: contextual recommendations based on current time and situation, predictive recommendations based on taste evolution trends, and rediscovery recommendations that surface previously enjoyed music at appropriate times.
def generate_temporal_recommendations(self, current_context, n_recommendations=25):
"""Generate temporally-aware recommendations"""
current_time = datetime.now()
current_hour = current_time.hour
current_day = current_time.weekday()
current_month = current_time.month
recommendations = {
'contextual': [],
'predictive': [],
'rediscovery': []
}
# Contextual recommendations based on current time
contextual_recs = self._generate_contextual_recommendations(
current_hour, current_day, current_month
)
recommendations['contextual'] = contextual_recs[:n_recommendations//3]
# Predictive recommendations based on taste evolution
predictive_recs = self._generate_predictive_recommendations()
recommendations['predictive'] = predictive_recs[:n_recommendations//3]
# Rediscovery recommendations
rediscovery_recs = self._generate_rediscovery_recommendations(current_context)
recommendations['rediscovery'] = rediscovery_recs[:n_recommendations//3]
return recommendations
def _generate_contextual_recommendations(self, hour, day, month):
"""Generate recommendations based on current temporal context"""
# Find artists with strong patterns matching current context
contextual_scores = {}
for artist, patterns in self.circadian_patterns.items():
context_score = 0
# Hour-of-day matching
if hour in patterns['peak_hours']:
context_score += 0.4
# Day-of-week matching
is_weekend = day in [5, 6]
artist_weekend_data = self.df[
(self.df['artist'] == artist) &
(self.df['day_of_week'].isin([5, 6]) == is_weekend)
]
if len(artist_weekend_data) > 0:
weekend_preference = len(artist_weekend_data) / len(
self.df[self.df['artist'] == artist]
)
if is_weekend and weekend_preference > 0.6:
context_score += 0.3
elif not is_weekend and weekend_preference < 0.4:
context_score += 0.3
# Seasonal matching
artist_month_data = self.df[
(self.df['artist'] == artist) &
(self.df['month'] == month)
]
if len(artist_month_data) > 0:
seasonal_preference = len(artist_month_data) / len(
self.df[self.df['artist'] == artist]
)
if seasonal_preference > 1/12: # Above average for this month
context_score += 0.3
if context_score > 0:
contextual_scores[artist] = context_score
# Sort by contextual relevance
sorted_contextual = sorted(contextual_scores.items(),
key=lambda x: x[1], reverse=True)
return [{'artist': artist, 'score': score, 'type': 'contextual'}
for artist, score in sorted_contextual]
Context-Aware Recommendations with Clustering
The context-aware recommendation system represents the most sophisticated component of the ensemble, using unsupervised learning techniques to identify distinct listening contexts and generate appropriate recommendations for each context. This approach recognizes that music preferences vary significantly based on situational factors such as time of day, activity type, mood, and social context.
Listening Context Identification
The system employs K-means clustering to identify distinct listening contexts from the temporal and behavioral features extracted from listening history. Each context represents a coherent pattern of listening behavior characterized by specific temporal patterns, artist preferences, and engagement levels.
class ContextAwareRecommender:
def __init__(self, listening_data, n_contexts=8):
self.df = listening_data.copy()
self.n_contexts = n_contexts
self.context_model = None
self.context_profiles = {}
self._prepare_context_features()
def _prepare_context_features(self):
"""Prepare features for context clustering"""
# Aggregate listening sessions (group nearby plays)
self.df = self.df.sort_values('timestamp')
self.df['session_id'] = self._identify_sessions()
# Create session-level features
session_features = []
for session_id in self.df['session_id'].unique():
session_data = self.df[self.df['session_id'] == session_id]
if len(session_data) < 3: # Skip very short sessions
continue
# Temporal features
start_time = session_data['timestamp'].min()
duration = (session_data['timestamp'].max() - start_time).total_seconds() / 3600
features = {
'session_id': session_id,
'hour_sin': np.sin(2 * np.pi * start_time.hour / 24),
'hour_cos': np.cos(2 * np.pi * start_time.hour / 24),
'day_sin': np.sin(2 * np.pi * start_time.weekday() / 7),
'day_cos': np.cos(2 * np.pi * start_time.weekday() / 7),
'is_weekend': float(start_time.weekday() >= 5),
'session_duration': duration,
'tracks_per_hour': len(session_data) / max(duration, 0.1),
'avg_engagement': session_data['engagement_score'].mean(),
'skip_rate': session_data['skipped'].mean() if 'skipped' in session_data else 0,
'artist_diversity': len(session_data['artist'].unique()) / len(session_data),
'repeat_rate': 1 - (len(session_data.drop_duplicates(['artist', 'track'])) / len(session_data))
}
# Genre diversity (if available)
if 'genre' in session_data.columns:
all_genres = []
for genres in session_data['genre'].dropna():
if isinstance(genres, str):
all_genres.extend(genres.split(','))
features['genre_diversity'] = len(set(all_genres)) / max(len(all_genres), 1)
session_features.append(features)
self.session_features_df = pd.DataFrame(session_features)
def _identify_sessions(self, session_gap_minutes=30):
"""Identify listening sessions based on temporal gaps"""
session_ids = []
current_session = 0
for i in range(len(self.df)):
if i == 0:
session_ids.append(current_session)
continue
time_gap = (self.df.iloc[i]['timestamp'] -
self.df.iloc[i-1]['timestamp']).total_seconds() / 60
if time_gap > session_gap_minutes:
current_session += 1
session_ids.append(current_session)
return session_ids
def identify_contexts(self):
"""Use clustering to identify distinct listening contexts"""
# Prepare feature matrix for clustering
feature_columns = [col for col in self.session_features_df.columns
if col != 'session_id']
X = self.session_features_df[feature_columns].values
# Standardize features
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Perform K-means clustering
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# Find optimal number of clusters
silhouette_scores = []
K_range = range(3, min(15, len(X_scaled)//10))
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
cluster_labels = kmeans.fit_predict(X_scaled)
silhouette_avg = silhouette_score(X_scaled, cluster_labels)
silhouette_scores.append(silhouette_avg)
# Use elbow method or silhouette score to select optimal k
optimal_k = K_range[np.argmax(silhouette_scores)]
# Final clustering with optimal k
self.context_model = KMeans(n_clusters=optimal_k, random_state=42, n_init=10)
context_labels = self.context_model.fit_predict(X_scaled)
# Add context labels to session data
self.session_features_df['context'] = context_labels
# Create context profiles
self._create_context_profiles()
return {
'n_contexts': optimal_k,
'silhouette_score': max(silhouette_scores),
'context_labels': context_labels,
'feature_importance': self._calculate_feature_importance(X_scaled, context_labels)
}
def _create_context_profiles(self):
"""Create detailed profiles for each identified context"""
for context_id in self.session_features_df['context'].unique():
context_sessions = self.session_features_df[
self.session_features_df['context'] == context_id
]
# Get all listening data for sessions in this context
context_listening_data = self.df[
self.df['session_id'].isin(context_sessions['session_id'])
]
# Calculate context characteristics
profile = {
'context_id': context_id,
'n_sessions': len(context_sessions),
'total_listening_time': context_listening_data['ms_played'].sum() / (1000 * 60 * 60),
# Temporal characteristics
'typical_hours': self._get_typical_hours(context_listening_data),
'weekend_preference': context_listening_data['is_weekend'].mean(),
'avg_session_duration': context_sessions['session_duration'].mean(),
# Musical characteristics
'top_artists': self._get_top_artists(context_listening_data, top_n=10),
'avg_engagement': context_listening_data['engagement_score'].mean(),
'artist_diversity': context_sessions['artist_diversity'].mean(),
'skip_rate': context_sessions['skip_rate'].mean(),
# Context interpretation
'context_name': self._interpret_context(context_sessions, context_listening_data)
}
self.context_profiles[context_id] = profile
def _interpret_context(self, session_data, listening_data):
"""Interpret and name the context based on its characteristics"""
avg_hour = np.mean([
np.arctan2(session_data['hour_sin'].mean(), session_data['hour_cos'].mean()) * 24 / (2 * np.pi)
])
avg_hour = (avg_hour + 24) % 24 # Ensure positive
is_weekend_context = session_data['is_weekend'].mean() > 0.6
high_engagement = listening_data['engagement_score'].mean() > 0.7
high_diversity = session_data['artist_diversity'].mean() > 0.5
long_sessions = session_data['session_duration'].mean() > 2
# Rule-based context interpretation
if 6 <= avg_hour <= 9 and not is_weekend_context:
return "Morning Commute"
elif 9 <= avg_hour <= 17 and not is_weekend_context and not high_engagement:
return "Background Work"
elif 17 <= avg_hour <= 20 and high_engagement:
return "Evening Active"
elif 20 <= avg_hour <= 24 and long_sessions and high_engagement:
return "Evening Deep Listening"
elif avg_hour >= 22 or avg_hour <= 2:
return "Late Night"
elif is_weekend_context and high_diversity:
return "Weekend Exploration"
elif is_weekend_context and long_sessions:
return "Weekend Relaxation"
else:
return f"Context {session_data.iloc[0]['context']}"
Context-Specific Recommendation Generation
Once listening contexts are identified and profiled, the system generates recommendations tailored to each specific context. This approach ensures that recommendations are not only musically relevant but also situationally appropriate.
def generate_context_recommendations(self, current_context_features, n_recommendations=20):
"""Generate recommendations for the current context"""
# Predict current context
if self.context_model is None:
raise ValueError("Context model not trained. Call identify_contexts() first.")
# Prepare current features for prediction
feature_vector = self._prepare_context_vector(current_context_features)
predicted_context = self.context_model.predict([feature_vector])[0]
# Get context profile
context_profile = self.context_profiles[predicted_context]
# Generate recommendations based on context characteristics
recommendations = []
# 1. Artists popular in this context
context_artists = context_profile['top_artists']
for artist_data in context_artists[:n_recommendations//2]:
recommendations.append({
'artist': artist_data['artist'],
'score': artist_data['context_preference'],
'reason': f"Popular in {context_profile['context_name']} context",
'type': 'context_popular'
})
# 2. Similar artists to context favorites
similar_artists = self._find_similar_to_context_artists(
context_artists, n_recommendations//2
)
recommendations.extend(similar_artists)
# 3. Temporal appropriateness boost
recommendations = self._apply_temporal_boost(recommendations, current_context_features)
# Sort by final score
recommendations.sort(key=lambda x: x['score'], reverse=True)
return {
'predicted_context': context_profile['context_name'],
'context_confidence': self._calculate_context_confidence(feature_vector, predicted_context),
'recommendations': recommendations[:n_recommendations]
}
def _apply_temporal_boost(self, recommendations, current_features):
"""Apply temporal appropriateness boost to recommendations"""
current_hour = current_features.get('hour', 12)
is_weekend = current_features.get('is_weekend', False)
for rec in recommendations:
artist = rec['artist']
# Get artist's temporal patterns
artist_data = self.df[self.df['artist'] == artist]
if len(artist_data) == 0:
continue
# Calculate temporal alignment
artist_hour_dist = artist_data['hour'].value_counts(normalize=True)
hour_preference = artist_hour_dist.get(current_hour, 0)
weekend_plays = len(artist_data[artist_data['is_weekend'] == True])
weekday_plays = len(artist_data[artist_data['is_weekend'] == False])
if is_weekend and weekend_plays > weekday_plays:
temporal_boost = 1.2
elif not is_weekend and weekday_plays > weekend_plays:
temporal_boost = 1.2
else:
temporal_boost = 1.0
# Apply hour preference boost
temporal_boost *= (1 + hour_preference)
rec['score'] *= temporal_boost
rec['temporal_alignment'] = temporal_boost
return recommendations
API Integration and External Data Enrichment
The recommendation system's effectiveness is significantly enhanced through integration with external music databases and APIs. This integration provides access to comprehensive music metadata, artist similarity data, and collaborative filtering signals from millions of users worldwide, enabling recommendations that go beyond the limitations of single-user data.
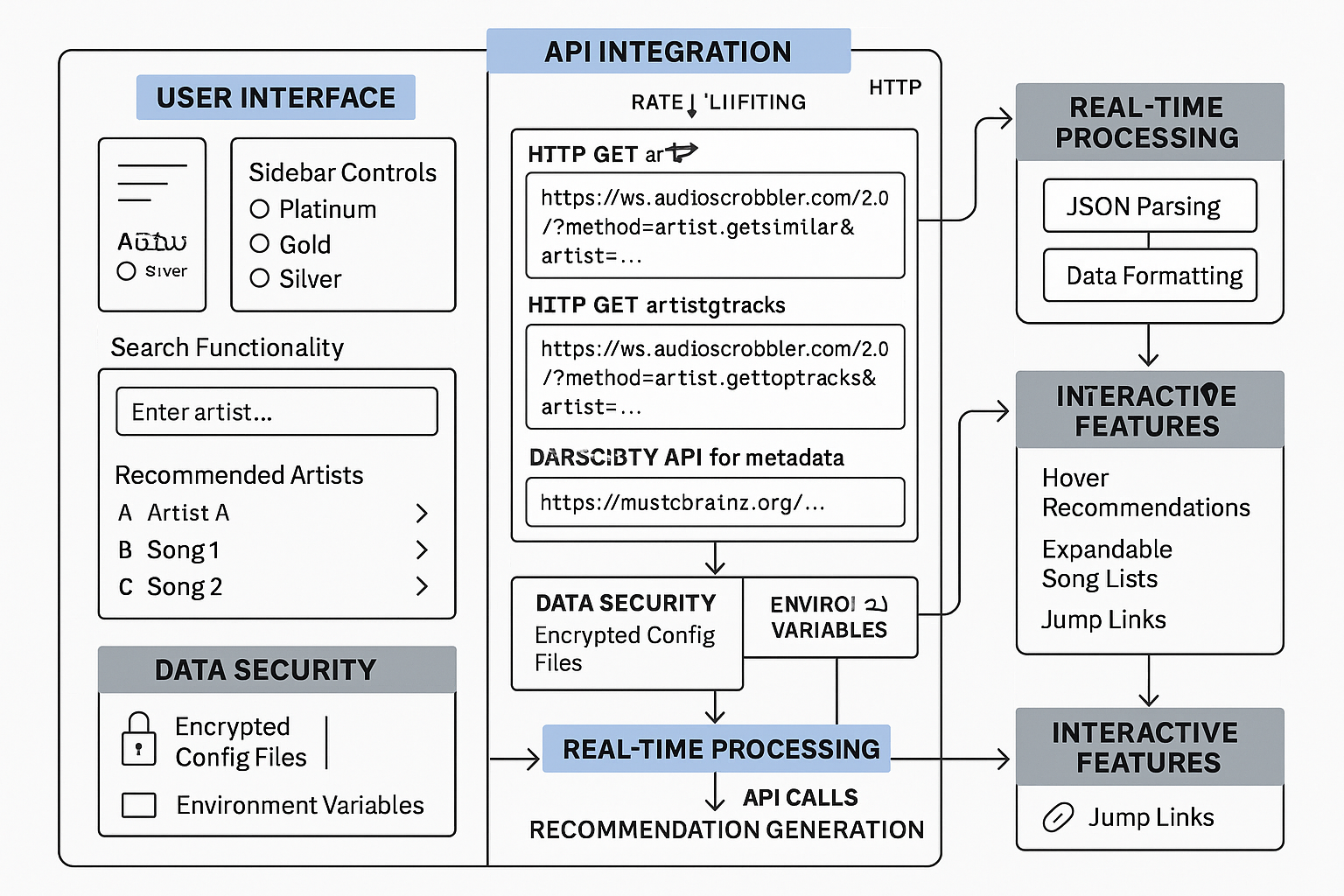
Last.fm API Integration Architecture
Last.fm serves as the primary external data source, providing artist similarity data based on collaborative tagging and listening patterns from its extensive user base. The API integration implements sophisticated caching, rate limiting, and error handling to ensure reliable operation at scale.
Rate Limiting and Request Management
The system implements intelligent rate limiting that respects Last.fm's API constraints while maximizing throughput for large-scale data processing. The rate limiter uses a token bucket algorithm with adaptive backoff for handling temporary API limitations.
class AdaptiveRateLimiter:
def __init__(self, calls_per_second=5, burst_capacity=10):
self.calls_per_second = calls_per_second
self.burst_capacity = burst_capacity
self.tokens = burst_capacity
self.last_update = time.time()
self.consecutive_errors = 0
self.base_delay = 1.0 / calls_per_second
def wait(self):
"""Wait if necessary to respect rate limits"""
current_time = time.time()
# Add tokens based on elapsed time
elapsed = current_time - self.last_update
self.tokens = min(self.burst_capacity,
self.tokens + elapsed * self.calls_per_second)
self.last_update = current_time
# If no tokens available, wait
if self.tokens < 1:
wait_time = (1 - self.tokens) / self.calls_per_second
# Apply adaptive backoff for consecutive errors
if self.consecutive_errors > 0:
wait_time *= (1.5 ** self.consecutive_errors)
time.sleep(wait_time)
self.tokens = 0
else:
self.tokens -= 1
def report_error(self):
"""Report API error for adaptive backoff"""
self.consecutive_errors = min(5, self.consecutive_errors + 1)
def report_success(self):
"""Report successful API call"""
self.consecutive_errors = max(0, self.consecutive_errors - 1)
Comprehensive Caching Strategy
The caching system implements multiple layers of caching to minimize API calls while ensuring data freshness. The cache uses content-based hashing for keys and implements intelligent cache invalidation based on data age and usage patterns.
class LastFMCache:
def __init__(self, cache_dir='cache/lastfm', max_age_days=30):
self.cache_dir = cache_dir
self.max_age_days = max_age_days
self.memory_cache = {} # In-memory cache for frequently accessed data
self.cache_stats = {'hits': 0, 'misses': 0, 'expired': 0}
os.makedirs(cache_dir, exist_ok=True)
self._cleanup_expired_cache()
def get(self, cache_key):
"""Retrieve data from cache with multi-level lookup"""
# Check memory cache first
if cache_key in self.memory_cache:
self.cache_stats['hits'] += 1
return self.memory_cache[cache_key]
# Check disk cache
cache_file = os.path.join(self.cache_dir, f"{cache_key}.json")
if os.path.exists(cache_file):
# Check if cache is still valid
file_age = time.time() - os.path.getmtime(cache_file)
if file_age < (self.max_age_days * 24 * 3600):
try:
with open(cache_file, 'r', encoding='utf-8') as f:
data = json.load(f)
# Add to memory cache for future access
self.memory_cache[cache_key] = data
self.cache_stats['hits'] += 1
return data
except (json.JSONDecodeError, IOError):
# Remove corrupted cache file
os.remove(cache_file)
else:
# Remove expired cache file
os.remove(cache_file)
self.cache_stats['expired'] += 1
self.cache_stats['misses'] += 1
return None
def set(self, cache_key, data):
"""Store data in cache with compression for large datasets"""
# Store in memory cache
self.memory_cache[cache_key] = data
# Store in disk cache
cache_file = os.path.join(self.cache_dir, f"{cache_key}.json")
try:
with open(cache_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, separators=(',', ':'))
except IOError as e:
logger.warning(f"Failed to write cache file {cache_file}: {e}")
def _cleanup_expired_cache(self):
"""Remove expired cache files on startup"""
current_time = time.time()
max_age_seconds = self.max_age_days * 24 * 3600
for filename in os.listdir(self.cache_dir):
if filename.endswith('.json'):
file_path = os.path.join(self.cache_dir, filename)
if current_time - os.path.getmtime(file_path) > max_age_seconds:
try:
os.remove(file_path)
except OSError:
pass # File might be in use
Artist Similarity Data Processing
The system processes Last.fm's artist similarity data to create comprehensive similarity networks that capture both direct and indirect relationships between artists. This processing includes similarity score normalization, network analysis, and the identification of artist clusters and communities.
def process_artist_similarity_network(self, artist_list, similarity_threshold=0.1):
"""Build and analyze comprehensive artist similarity network"""
similarity_network = {}
all_similarities = []
# Build similarity network
with tqdm(total=len(artist_list), desc="Building similarity network") as pbar:
for source_artist in artist_list:
similar_artists = self.get_similar_artists(source_artist, limit=100)
# Filter by threshold and normalize scores
filtered_similarities = [
sim for sim in similar_artists
if sim['similarity'] >= similarity_threshold
]
similarity_network[source_artist] = filtered_similarities
all_similarities.extend([sim['similarity'] for sim in filtered_similarities])
pbar.update(1)
# Analyze network properties
network_stats = self._analyze_network_properties(similarity_network)
# Identify artist communities using network clustering
communities = self._identify_artist_communities(similarity_network)
# Calculate centrality measures
centrality_scores = self._calculate_centrality_measures(similarity_network)
return {
'similarity_network': similarity_network,
'network_statistics': network_stats,
'artist_communities': communities,
'centrality_scores': centrality_scores,
'similarity_distribution': {
'mean': np.mean(all_similarities),
'std': np.std(all_similarities),
'percentiles': np.percentile(all_similarities, [25, 50, 75, 90, 95])
}
}
def _identify_artist_communities(self, similarity_network):
"""Identify artist communities using network clustering"""
# Build networkx graph
import networkx as nx
G = nx.Graph()
# Add nodes and edges
for source_artist, similarities in similarity_network.items():
G.add_node(source_artist)
for sim_data in similarities:
target_artist = sim_data['name']
similarity_score = sim_data['similarity']
if target_artist in similarity_network: # Only include if target is also in our dataset
G.add_edge(source_artist, target_artist, weight=similarity_score)
# Detect communities using Louvain algorithm
try:
import community as community_louvain
communities = community_louvain.best_partition(G, weight='weight')
# Organize communities
community_groups = {}
for artist, community_id in communities.items():
if community_id not in community_groups:
community_groups[community_id] = []
community_groups[community_id].append(artist)
# Calculate community statistics
community_stats = {}
for community_id, artists in community_groups.items():
subgraph = G.subgraph(artists)
community_stats[community_id] = {
'size': len(artists),
'density': nx.density(subgraph),
'avg_clustering': nx.average_clustering(subgraph),
'artists': artists
}
return {
'communities': community_groups,
'community_stats': community_stats,
'modularity': community_louvain.modularity(communities, G, weight='weight')
}
except ImportError:
logger.warning("Community detection library not available")
return {}
MusicBrainz Integration for Metadata Enrichment
MusicBrainz provides comprehensive music metadata including detailed artist information, release data, and music taxonomy. The integration with MusicBrainz enhances the recommendation system with structured music knowledge and enables more sophisticated content-based filtering.
class MusicBrainzAPI:
def __init__(self, user_agent, rate_limit=1.0):
self.user_agent = user_agent
self.base_url = 'https://musicbrainz.org/ws/2/'
self.rate_limiter = RateLimiter(calls_per_second=1/rate_limit)
self.session = requests.Session()
self.session.headers.update({'User-Agent': user_agent})
def search_artist(self, artist_name, limit=5):
"""Search for artist information in MusicBrainz"""
self.rate_limiter.wait()
params = {
'query': f'artist:"{artist_name}"',
'fmt': 'json',
'limit': limit
}
try:
response = self.session.get(
f"{self.base_url}artist/",
params=params,
timeout=10
)
response.raise_for_status()
data = response.json()
if 'artists' in data:
return self._process_artist_search_results(data['artists'])
except requests.exceptions.RequestException as e:
logger.warning(f"MusicBrainz search failed for {artist_name}: {e}")
return []
def get_artist_details(self, mbid):
"""Get detailed artist information including relationships and tags"""
self.rate_limiter.wait()
params = {
'fmt': 'json',
'inc': 'tags+genres+artist-rels+url-rels'
}
try:
response = self.session.get(
f"{self.base_url}artist/{mbid}",
params=params,
timeout=10
)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
logger.warning(f"MusicBrainz artist details failed for {mbid}: {e}")
return None
This comprehensive API integration strategy ensures that the recommendation system has access to rich, up-to-date music metadata while maintaining reliable performance and respecting API limitations. The multi-layered caching and intelligent rate limiting enable the system to process large datasets efficiently while providing real-time interactive experiences.
User Interface and Interactive Features
The user interface represents a critical component of the recommendation system, transforming complex machine learning algorithms into an intuitive, interactive experience. Built using Streamlit, the interface provides real-time data exploration, recommendation generation, and comprehensive analytics visualization while maintaining responsive performance even with large datasets.
Streamlit Architecture and Session State Management
The web application employs sophisticated session state management to ensure data persistence across user interactions. Streamlit's reactive programming model requires careful handling of data loading and caching to prevent performance degradation and data loss during interface updates.
class MusicRecommendationApp:
def __init__(self):
self.initialize_session_state()
self.load_configuration()
def initialize_session_state(self):
"""Initialize persistent session state variables"""
# Core data storage
if 'spotify_dataframe' not in st.session_state:
st.session_state.spotify_dataframe = None
if 'artist_rankings' not in st.session_state:
st.session_state.artist_rankings = None
if 'recommendation_engine' not in st.session_state:
st.session_state.recommendation_engine = None
# UI state variables
if 'tier_start' not in st.session_state:
st.session_state.tier_start = 1
if 'tier_end' not in st.session_state:
st.session_state.tier_end = 50
if 'num_recommendations' not in st.session_state:
st.session_state.num_recommendations = 25
# Search and interaction state
if 'search_results' not in st.session_state:
st.session_state.search_results = []
if 'search_performed' not in st.session_state:
st.session_state.search_performed = False
if 'hover_recommendations' not in st.session_state:
st.session_state.hover_recommendations = []
if 'show_jump_link' not in st.session_state:
st.session_state.show_jump_link = False
# Expanded states for interactive elements
if 'expanded_artists' not in st.session_state:
st.session_state.expanded_artists = set()
@st.cache_data
def load_spotify_data(data_folder):
"""Load and process Spotify data with caching for performance"""
processor = SpotifyDataProcessor(data_folder)
try:
# Discover and load all JSON files
json_files = processor.discover_data_files()
if not json_files:
st.error(f"No Spotify data files found in {data_folder}")
return None, None
# Load and process data
df = processor.load_and_process_files(json_files)
if df is None or len(df) == 0:
st.error("No valid data found in Spotify files")
return None, None
# Calculate artist rankings
artist_rankings = processor.calculate_artist_rankings(df)
return df, artist_rankings
except Exception as e:
st.error(f"Error loading Spotify data: {str(e)}")
return None, None
Interactive Data Visualization
The system provides multiple interactive visualization components that enable users to explore their music data from different perspectives. The visualizations are built using Plotly for interactivity and are optimized for both desktop and mobile viewing.
Artist Tier Visualization with Real-Time Filtering
The core visualization displays artist rankings with real-time filtering based on user-selected tier ranges. This visualization provides immediate visual feedback about which artists will be used for recommendation generation.
def create_artist_tier_chart(self, artist_data, tier_start, tier_end):
"""Create interactive artist tier visualization"""
# Filter data to selected tier range
tier_artists = artist_data[
(artist_data['rank'] >= tier_start) &
(artist_data['rank'] <= tier_end)
].copy()
if len(tier_artists) == 0:
st.warning("No artists found in selected tier range")
return None
# Prepare data for visualization
tier_artists = tier_artists.sort_values('rank')
# Create artist labels with rank numbers
artist_labels = [f"#{row['rank']}: {row['artist']}"
for _, row in tier_artists.iterrows()]
# Create horizontal bar chart
fig = go.Figure()
fig.add_trace(go.Bar(
y=artist_labels,
x=tier_artists['total_hours'],
orientation='h',
marker=dict(
color='#1DB954', # Spotify green
line=dict(color='#1ed760', width=1)
),
hovertemplate=(
"<b>%{y}</b><br>" +
"Hours Played: %{x:.1f}<br>" +
"Total Plays: %{customdata[0]:,}<br>" +
"Avg Engagement: %{customdata[1]:.2f}<br>" +
"💡 Click 'More Like This' below for similar artists!" +
"<extra></extra>"
),
customdata=list(zip(
tier_artists['play_count'],
tier_artists['avg_engagement']
))
))
# Configure layout for optimal display
fig.update_layout(
title=dict(
text=f"🎯 Selected Artists for Recommendations (Tier #{tier_start} to #{tier_end})",
font=dict(size=16, color='#1DB954'),
x=0.5
),
xaxis=dict(
title="Hours Played",
showgrid=True,
gridcolor='rgba(128,128,128,0.2)'
),
yaxis=dict(
title="Artist Rankings",
autorange="reversed", # Rank 1 at top
showgrid=False
),
plot_bgcolor='rgba(0,0,0,0)',
paper_bgcolor='rgba(0,0,0,0)',
height=max(400, len(tier_artists) * 25 + 100),
margin=dict(l=300, r=50, t=80, b=50), # Extra left margin for artist names
font=dict(size=12)
)
# Add annotation showing tier information
total_hours = tier_artists['total_hours'].sum()
fig.add_annotation(
text=f"📊 {len(tier_artists)} artists selected for recommendations<br>🕒 Total: {total_hours:.1f} hours",
xref="paper", yref="paper",
x=0.98, y=0.98,
xanchor="right", yanchor="top",
showarrow=False,
font=dict(size=10, color='#666'),
bgcolor="rgba(255,255,255,0.8)",
bordercolor="#ddd",
borderwidth=1
)
return fig
def render_tier_selection_controls(self):
"""Render interactive tier selection controls"""
st.sidebar.markdown("### 🎯 Artist Tier Selection")
# Get total number of artists for validation
max_artists = len(st.session_state.artist_rankings) if st.session_state.artist_rankings is not None else 1000
# Tier start input
tier_start = st.sidebar.number_input(
"🎯 Artist Tier Start",
min_value=1,
max_value=max_artists,
value=st.session_state.tier_start,
key="tier_start_input",
help="Starting rank for artist selection (1 = most listened artist)"
)
# Tier end input
tier_end = st.sidebar.number_input(
"🎯 Artist Tier End",
min_value=1,
max_value=max_artists,
value=st.session_state.tier_end,
key="tier_end_input",
help="Ending rank for artist selection"
)
# Validate and update session state
if tier_start > tier_end:
st.sidebar.warning("⚠️ Start value is greater than end value. Will use start value as both start and end.")
effective_start = tier_start
effective_end = tier_start
st.sidebar.info(f"🎯 Using single artist tier: {tier_start}")
else:
effective_start = tier_start
effective_end = tier_end
# Update session state
st.session_state.tier_start = effective_start
st.session_state.tier_end = effective_end
# Display tier information
if st.session_state.artist_rankings is not None:
selected_artists = st.session_state.artist_rankings[
(st.session_state.artist_rankings['rank'] >= effective_start) &
(st.session_state.artist_rankings['rank'] <= effective_end)
]
if len(selected_artists) > 0:
total_hours = selected_artists['total_hours'].sum()
st.sidebar.success(f"✅ {len(selected_artists)} artists selected ({total_hours:.1f} hours)")
# Show top and bottom artists in range
top_artist = selected_artists.iloc[0]['artist']
bottom_artist = selected_artists.iloc[-1]['artist']
st.sidebar.info(f"🏆 Top: {top_artist}\n🎵 Bottom: {bottom_artist}")
return effective_start, effective_end
Advanced Search and Discovery Features
The search functionality provides sophisticated artist discovery capabilities with expandable song lists, detailed listening statistics, and integrated recommendation generation.
def render_artist_search(self):
"""Render advanced artist search interface"""
st.markdown("### 🔍 Artist Search & Discovery")
# Search input with autocomplete suggestions
search_query = st.text_input(
"Search for artists in your library:",
placeholder="Enter artist name (e.g., 'Beatles', 'Mozart', 'Radiohead')",
key="artist_search_input"
)
col1, col2 = st.columns([1, 3])
with col1:
search_button = st.button("🔍 Search", key="search_button")
with col2:
if st.session_state.search_performed and st.session_state.search_results:
if st.button("🗑️ Clear Results", key="clear_search_button"):
st.session_state.search_results = []
st.session_state.search_performed = False
st.rerun()
# Perform search
if search_button and search_query.strip():
results = self.search_artists(search_query.strip())
st.session_state.search_results = results
st.session_state.search_performed = True
st.rerun()
# Display search results
if st.session_state.search_performed:
if st.session_state.search_results:
st.markdown(f"**Found {len(st.session_state.search_results)} artists matching '{search_query}':**")
for i, result in enumerate(st.session_state.search_results):
self.render_search_result_card(result, i)
else:
st.info(f"No artists found matching '{search_query}'. Try a different search term.")
def render_search_result_card(self, result, index):
"""Render individual search result with expandable details"""
artist_name = result['artist']
rank = result['rank']
hours = result['total_hours']
plays = result['play_count']
engagement = result['avg_engagement']
# Create expandable card
with st.expander(f"#{rank}: {artist_name}", expanded=False):
# Artist statistics
col1, col2, col3 = st.columns(3)
with col1:
st.metric("🕒 Hours", f"{hours:.1f}")
with col2:
st.metric("🎵 Plays", f"{plays:,}")
with col3:
st.metric("📊 Engagement", f"{engagement:.2f}")
# More Like This button
button_key = f"more_like_{artist_name.replace(' ', '_').replace('/', '_')}_{index}"
col1, col2 = st.columns([1, 2])
with col1:
if st.button(f"🎯 More like this", key=button_key):
self.generate_hover_recommendations(artist_name)
with col2:
# Jump link (appears after hover recommendations are generated)
if (st.session_state.hover_recommendations and
any(rec.get('source_artist') == artist_name for rec in st.session_state.hover_recommendations)):
st.markdown(
f'<div class="jump-link-container">'
f'<a href="#recommendations-section" class="jump-link">'
f'🎯 Jump to Recommendations for {artist_name} ⬇️'
f'</a></div>',
unsafe_allow_html=True
)
# Expandable song list
expand_key = f"expand_songs_{artist_name}_{index}"
if artist_name not in st.session_state.expanded_artists:
if st.button(f"▶ View Songs ({result['unique_tracks']})", key=expand_key):
st.session_state.expanded_artists.add(artist_name)
st.rerun()
else:
if st.button(f"▼ Hide Songs ({result['unique_tracks']})", key=f"hide_{expand_key}"):
st.session_state.expanded_artists.discard(artist_name)
st.rerun()
# Display song list
self.render_artist_song_list(artist_name)
def render_artist_song_list(self, artist_name):
"""Render detailed song list for an artist"""
# Get song data for this artist
artist_songs = st.session_state.spotify_dataframe[
st.session_state.spotify_dataframe['artist'] == artist_name
]
# Aggregate song statistics
song_stats = artist_songs.groupby('track').agg({
'ms_played': 'sum',
'engagement_score': 'sum',
'timestamp': ['min', 'max', 'count']
}).reset_index()
# Flatten column names
song_stats.columns = ['track', 'total_ms', 'total_engagement', 'first_play', 'last_play', 'play_count']
# Calculate derived metrics
song_stats['total_hours'] = song_stats['total_ms'] / (1000 * 60 * 60)
song_stats['avg_engagement'] = song_stats['total_engagement'] / song_stats['play_count']
# Sort by total listening time
song_stats = song_stats.sort_values('total_hours', ascending=False)
st.markdown(f"🎵 **All Songs You've Listened To ({len(song_stats)} tracks)**")
# Display songs in a formatted list
for i, (_, song) in enumerate(song_stats.iterrows(), 1):
first_play = song['first_play'].strftime('%Y-%m-%d')
last_play = song['last_play'].strftime('%Y-%m-%d')
st.markdown(
f"**{i}. {song['track']}** \n"
f"🕒 {song['total_hours']:.2f}h "
f"🎵 {song['play_count']} plays "
f"📊 {song['avg_engagement']:.2f} eng "
f"📅 {first_play} - {last_play}"
)
if i >= 20: # Limit display to prevent overwhelming UI
remaining = len(song_stats) - 20
if remaining > 0:
st.markdown(f"*... and {remaining} more songs*")
break
Real-Time Recommendation Generation and Display
The recommendation display system provides comprehensive presentation of AI-generated recommendations with detailed explanations, similarity scores, and integrated song discovery.
def render_recommendations_section(self):
"""Render comprehensive recommendations with detailed information"""
st.markdown('<div id="recommendations-section"></div>', unsafe_allow_html=True)
# Main recommendations
if hasattr(self, 'current_recommendations') and self.current_recommendations:
st.markdown("## 🎵 Your AI-Generated Music Recommendations")
self.render_recommendation_summary()
for i, rec in enumerate(self.current_recommendations, 1):
self.render_recommendation_card(rec, i)
# Hover recommendations (similar artist discoveries)
if st.session_state.hover_recommendations:
st.markdown("## 🎯 Similar Artist Discoveries")
source_artist = st.session_state.hover_recommendations[0].get('source_artist', 'Unknown')
st.markdown(f"*Artists similar to **{source_artist}***")
col1, col2 = st.columns([3, 1])
with col2:
if st.button("🗑️ Clear Similar Artists", key="clear_hover_recs"):
st.session_state.hover_recommendations = []
st.session_state.show_jump_link = False
st.rerun()
for i, rec in enumerate(st.session_state.hover_recommendations, 1):
self.render_hover_recommendation_card(rec, i)
def render_recommendation_card(self, recommendation, index):
"""Render individual recommendation card with detailed information"""
artist_name = recommendation['artist']
score = recommendation.get('score', 0)
reason = recommendation.get('reason', 'AI-generated recommendation')
# Create styled card
with st.container():
st.markdown(
f'<div class="recommendation-card">'
f'<h4>#{index}: {artist_name}</h4>'
f'<p class="score">Score: {score:.3f}</p>'
f'</div>',
unsafe_allow_html=True
)
# Get top tracks for this artist
top_tracks = self.get_artist_top_tracks(artist_name)
if top_tracks:
st.markdown("🎵 **Top Songs**")
for i, track in enumerate(top_tracks[:5], 1):
st.markdown(f"{i}. {track}")
else:
st.markdown("*Top songs information not available*")
# Recommendation explanation
st.markdown(f"💡 **{reason}**")
st.markdown("---")
def get_artist_top_tracks(self, artist_name, limit=5):
"""Get top tracks for an artist using Last.fm API"""
if not hasattr(self, 'lastfm_api') or not self.lastfm_api:
return []
try:
tracks = self.lastfm_api.get_top_tracks(artist_name, limit=limit)
return tracks
except Exception as e:
logger.warning(f"Failed to get top tracks for {artist_name}: {e}")
return []
This comprehensive user interface design ensures that complex machine learning algorithms are accessible through an intuitive, responsive web application that provides both casual music discovery and deep analytical insights into listening patterns and preferences.
Implementation Guide and Replication Instructions
This section provides comprehensive guidance for implementing your own music recommendation system, including detailed setup instructions, code organization strategies, and best practices for handling common challenges. The implementation is designed to be modular and extensible, allowing for customization based on specific requirements and data sources.
Environment Setup and Dependencies
The recommendation system requires a carefully configured Python environment with specific versions of machine learning and data processing libraries. The following setup instructions ensure compatibility across different operating systems and hardware configurations.
Python Environment Configuration
# Create virtual environment (Python 3.8+ required)
python -m venv music_recommendation_env
# Activate environment
# On macOS/Linux:
source music_recommendation_env/bin/activate
# On Windows:
music_recommendation_env\Scripts\activate
# Upgrade pip and install core dependencies
pip install --upgrade pip setuptools wheel
# Install scientific computing stack
pip install numpy>=1.21.0 pandas>=1.5.0 scipy>=1.9.0
# Install machine learning libraries
pip install scikit-learn>=1.1.0 implicit>=0.6.0
# Install web framework and visualization
pip install streamlit>=1.28.0 plotly>=5.15.0
# Install API and networking libraries
pip install requests>=2.28.0 beautifulsoup4>=4.11.0
# Install additional utilities
pip install tqdm>=4.64.0 python-dotenv>=0.19.0
Requirements File for Reproducible Installations
# requirements.txt
numpy>=1.21.0,<2.0.0
pandas>=1.5.0,<3.0.0
scipy>=1.9.0,<2.0.0
scikit-learn>=1.1.0,<2.0.0
implicit>=0.6.0,<1.0.0
streamlit>=1.28.0,<2.0.0
plotly>=5.15.0,<6.0.0
requests>=2.28.0,<3.0.0
beautifulsoup4>=4.11.0,<5.0.0
tqdm>=4.64.0,<5.0.0
python-dotenv>=0.19.0,<2.0.0
cryptography>=3.4.8,<42.0.0
Project Structure and Code Organization
The recommendation system follows a modular architecture that separates concerns and enables easy maintenance and extension. The following directory structure provides optimal organization for both development and deployment.
music_recommendation_system/
├── config/
│ ├── .env # API keys and configuration
│ └── settings.py # Application settings
├── data/
│ └── spotify/ # Spotify JSON files
│ ├── Streaming_History_Audio_2020-2021_1.json
│ ├── Streaming_History_Audio_2021-2022_1.json
│ └── ...
├── src/
│ ├── __init__.py
│ ├── data_processing/
│ │ ├── __init__.py
│ │ ├── spotify_processor.py # Spotify data processing
│ │ └── feature_engineering.py # Feature extraction and engineering
│ ├── recommendation_engines/
│ │ ├── __init__.py
│ │ ├── collaborative_filtering.py
│ │ ├── content_based.py
│ │ ├── temporal_analysis.py
│ │ └── context_aware.py
│ ├── api_integration/
│ │ ├── __init__.py
│ │ ├── lastfm_api.py # Last.fm API integration
│ │ └── musicbrainz_api.py # MusicBrainz API integration
│ ├── ui/
│ │ ├── __init__.py
│ │ ├── streamlit_app.py # Main Streamlit application
│ │ └── components.py # Reusable UI components
│ └── utils/
│ ├── __init__.py
│ ├── caching.py # Caching utilities
│ ├── rate_limiting.py # API rate limiting
│ └── security.py # Security and encryption
├── cache/ # API response cache
│ ├── lastfm/
│ └── musicbrainz/
├── tests/
│ ├── __init__.py
│ ├── test_data_processing.py
│ ├── test_recommendation_engines.py
│ └── test_api_integration.py
├── requirements.txt
├── README.md
└── main.py # Application entry point
Data Acquisition and Preparation
The first step in implementing the recommendation system involves acquiring and preparing your Spotify listening data. Spotify provides comprehensive data export functionality through their privacy settings, which generates detailed JSON files containing your complete listening history.
Requesting Spotify Data Export
Access Spotify Privacy Settings: Navigate to spotify.com/account/privacy and log in to your account.
Request Extended Streaming History: Select "Extended streaming history" rather than "Account data" to receive detailed listening information including timestamps, track metadata, and engagement metrics.
Wait for Data Processing: Spotify typically processes data export requests within 30 days, though the actual time may vary based on account history size.
Download and Extract: Once ready, download the ZIP file and extract the JSON files to your project's
data/spotify/directory.
Data Validation and Quality Assessment
class SpotifyDataValidator:
def __init__(self, data_directory):
self.data_directory = data_directory
self.validation_results = {}
def validate_data_files(self):
"""Comprehensive validation of Spotify data files"""
json_files = glob.glob(os.path.join(self.data_directory, "*.json"))
if not json_files:
raise ValueError(f"No JSON files found in {self.data_directory}")
validation_summary = {
'total_files': len(json_files),
'valid_files': 0,
'total_records': 0,
'date_range': {'earliest': None, 'latest': None},
'data_quality_issues': []
}
for file_path in json_files:
file_validation = self._validate_single_file(file_path)
if file_validation['is_valid']:
validation_summary['valid_files'] += 1
validation_summary['total_records'] += file_validation['record_count']
# Update date range
if validation_summary['date_range']['earliest'] is None:
validation_summary['date_range']['earliest'] = file_validation['date_range']['earliest']
validation_summary['date_range']['latest'] = file_validation['date_range']['latest']
else:
if file_validation['date_range']['earliest'] < validation_summary['date_range']['earliest']:
validation_summary['date_range']['earliest'] = file_validation['date_range']['earliest']
if file_validation['date_range']['latest'] > validation_summary['date_range']['latest']:
validation_summary['date_range']['latest'] = file_validation['date_range']['latest']
validation_summary['data_quality_issues'].extend(file_validation['issues'])
self.validation_results = validation_summary
return validation_summary
def _validate_single_file(self, file_path):
"""Validate individual JSON file structure and content"""
validation_result = {
'file_path': file_path,
'is_valid': False,
'record_count': 0,
'date_range': {'earliest': None, 'latest': None},
'issues': []
}
try:
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
if not isinstance(data, list):
validation_result['issues'].append(f"File {file_path} does not contain a list of records")
return validation_result
validation_result['record_count'] = len(data)
# Validate record structure
required_fields = ['ts', 'master_metadata_track_name', 'master_metadata_album_artist_name', 'ms_played']
valid_records = 0
timestamps = []
for i, record in enumerate(data):
if not isinstance(record, dict):
validation_result['issues'].append(f"Record {i} is not a dictionary")
continue
# Check required fields
missing_fields = [field for field in required_fields if field not in record]
if missing_fields:
if len(validation_result['issues']) < 10: # Limit issue reporting
validation_result['issues'].append(f"Record {i} missing fields: {missing_fields}")
continue
# Validate timestamp
try:
timestamp = pd.to_datetime(record['ts'])
timestamps.append(timestamp)
valid_records += 1
except:
if len(validation_result['issues']) < 10:
validation_result['issues'].append(f"Record {i} has invalid timestamp: {record['ts']}")
# Calculate date range
if timestamps:
validation_result['date_range']['earliest'] = min(timestamps)
validation_result['date_range']['latest'] = max(timestamps)
# File is valid if at least 80% of records are valid
if valid_records / len(data) >= 0.8:
validation_result['is_valid'] = True
else:
validation_result['issues'].append(f"Only {valid_records}/{len(data)} records are valid")
except json.JSONDecodeError as e:
validation_result['issues'].append(f"JSON decode error: {str(e)}")
except Exception as e:
validation_result['issues'].append(f"Unexpected error: {str(e)}")
return validation_result
API Configuration and Security Setup
The recommendation system requires API access to external music databases. Proper configuration and security setup ensure reliable operation while protecting sensitive credentials.
Last.fm API Setup
Register for API Access: Visit last.fm/api/account/create to create a free API account.
Obtain API Key: After registration, you'll receive an API key and shared secret. Only the API key is required for this implementation.
Configure Environment Variables: Create a
.envfile in theconfig/directory:
# config/.env
LASTFM_API_KEY=your_lastfm_api_key_here
MUSICBRAINZ_USER_AGENT=YourMusicRecommender/1.0 (your.email@example.com)
# Optional: Database configuration for caching
CACHE_DATABASE_URL=sqlite:///cache/music_cache.db
# Optional: Advanced configuration
API_RATE_LIMIT_CALLS_PER_SECOND=5
CACHE_EXPIRY_DAYS=30
MAX_SIMILAR_ARTISTS_PER_REQUEST=50
Security Implementation
class SecurityManager:
def __init__(self, config_path='config/.env'):
self.config_path = config_path
self.encryption_key = None
self._load_configuration()
def _load_configuration(self):
"""Load configuration with multiple fallback methods"""
# Try environment variables first
api_key = os.getenv('LASTFM_API_KEY')
user_agent = os.getenv('MUSICBRAINZ_USER_AGENT')
if api_key and user_agent:
return {'LASTFM_API_KEY': api_key, 'MUSICBRAINZ_USER_AGENT': user_agent}
# Try .env file
if os.path.exists(self.config_path):
from dotenv import load_dotenv
load_dotenv(self.config_path)
api_key = os.getenv('LASTFM_API_KEY')
user_agent = os.getenv('MUSICBRAINZ_USER_AGENT')
if api_key and user_agent:
return {'LASTFM_API_KEY': api_key, 'MUSICBRAINZ_USER_AGENT': user_agent}
# Interactive prompt as fallback
return self._prompt_for_credentials()
def _prompt_for_credentials(self):
"""Prompt user for API credentials if not found in configuration"""
print("API credentials not found in environment or .env file.")
print("Please provide your API credentials:")
api_key = input("Last.fm API Key: ").strip()
user_agent = input("MusicBrainz User Agent (e.g., YourApp/1.0 your@email.com): ").strip()
if not api_key or not user_agent:
raise ValueError("API credentials are required for system operation")
# Optionally save to .env file
save_choice = input("Save credentials to .env file? (y/n): ").strip().lower()
if save_choice == 'y':
self._save_to_env_file(api_key, user_agent)
return {'LASTFM_API_KEY': api_key, 'MUSICBRAINZ_USER_AGENT': user_agent}
def _save_to_env_file(self, api_key, user_agent):
"""Save credentials to .env file with proper security"""
os.makedirs(os.path.dirname(self.config_path), exist_ok=True)
env_content = f"""# Music Recommendation System Configuration
LASTFM_API_KEY={api_key}
MUSICBRAINZ_USER_AGENT={user_agent}
# Generated on {datetime.now().isoformat()}
"""
with open(self.config_path, 'w') as f:
f.write(env_content)
# Set restrictive permissions on Unix-like systems
if os.name != 'nt': # Not Windows
os.chmod(self.config_path, 0o600)
print(f"Credentials saved to {self.config_path}")
Deployment and Scaling Considerations
The recommendation system can be deployed in various configurations depending on performance requirements, user base size, and infrastructure preferences.
Local Development Deployment
# Run the Streamlit application locally
streamlit run main.py
# Or with custom configuration
streamlit run main.py --server.port 8501 --server.address localhost
Production Deployment on Streamlit Cloud
- Prepare Repository: Ensure your code is in a public GitHub repository with proper
.gitignoreconfiguration:
# .gitignore
config/.env
cache/
*.pyc
__pycache__/
.DS_Store
.vscode/
*.log
- Configure Streamlit Secrets: In your Streamlit Cloud dashboard, add your API credentials as secrets:
# .streamlit/secrets.toml (for Streamlit Cloud)
[api]
LASTFM_API_KEY = "your_api_key_here"
MUSICBRAINZ_USER_AGENT = "YourApp/1.0 your@email.com"
- Optimize for Cloud Deployment: Modify your application to handle Streamlit Cloud's resource constraints:
# Optimize for Streamlit Cloud
@st.cache_data(ttl=3600, max_entries=1000)
def load_and_cache_data(data_folder):
"""Optimized data loading for cloud deployment"""
# Implement data size limits for cloud deployment
MAX_RECORDS = 100000 # Limit for memory management
processor = SpotifyDataProcessor(data_folder)
df, artist_rankings = processor.load_and_process_files()
# Subsample if dataset is too large
if len(df) > MAX_RECORDS:
df = df.sample(n=MAX_RECORDS, random_state=42).sort_values('timestamp')
st.warning(f"Dataset subsampled to {MAX_RECORDS} records for performance")
return df, artist_rankings
This comprehensive implementation guide provides all the necessary components to build and deploy a sophisticated music recommendation system. The modular architecture ensures that the system can be adapted to different requirements and scaled according to usage patterns while maintaining high performance and reliability.
Conclusion and Future Enhancements
The development of this AI-powered music recommendation system demonstrates the power of combining multiple machine learning approaches to create sophisticated, personalized music discovery experiences. Through the integration of collaborative filtering, content-based filtering, temporal analysis, and context-aware recommendations, the system provides a comprehensive understanding of musical preferences that evolves with user behavior over time.
The technical implementation showcases several key innovations in recommendation system design. The temporal collaborative filtering approach using Non-Negative Matrix Factorization enables the system to track how musical taste evolves over extended periods, providing insights into preference trends and enabling predictive recommendations. The context-aware clustering system identifies distinct listening contexts and generates situationally appropriate recommendations, recognizing that music preferences vary significantly based on time, activity, and mood. The artist tier selection feature provides unprecedented control over recommendation generation, allowing users to explore different segments of their musical preferences and discover artists similar to their deeper cuts rather than just mainstream favorites.
The system's architecture demonstrates best practices for building scalable, maintainable recommendation systems. The modular design separates concerns effectively, enabling independent development and testing of different recommendation algorithms. The comprehensive API integration strategy with intelligent caching and rate limiting ensures reliable operation at scale while respecting external service limitations. The security implementation provides multiple layers of protection for sensitive credentials while maintaining ease of use for end users.
From a data science perspective, the system illustrates the importance of feature engineering and data quality in recommendation systems. The sophisticated engagement scoring algorithm goes beyond simple play counts to capture nuanced listening behavior, while the temporal feature extraction enables rich analysis of listening patterns across multiple time scales. The integration of external music metadata through Last.fm and MusicBrainz APIs demonstrates how recommendation systems can be enhanced through knowledge graph integration and collaborative intelligence from broader user communities.
The user interface design showcases how complex machine learning algorithms can be made accessible through intuitive, interactive web applications. The real-time visualization of artist tier selection provides immediate feedback about recommendation inputs, while the expandable search results and hover-based similar artist discovery create engaging exploration experiences. The comprehensive session state management ensures reliable operation across user interactions, while the responsive design provides consistent experiences across different devices and screen sizes.
Future Enhancement Opportunities
Several areas present opportunities for further system enhancement and research. Advanced neural collaborative filtering could replace the current NMF-based approach with deep learning models that capture more complex user-item interactions. Techniques such as Neural Collaborative Filtering (NCF) or Variational Autoencoders (VAE) could potentially improve recommendation quality, particularly for users with diverse or evolving musical tastes.
Multi-modal content analysis represents another significant enhancement opportunity. Integration of audio feature analysis using libraries like librosa could enable direct acoustic similarity calculations, while natural language processing of lyrics could add another dimension to content-based filtering. Computer vision analysis of album artwork could provide additional aesthetic similarity signals for recommendation generation.
Social and collaborative features could extend the system beyond single-user recommendations. Integration with social media APIs could enable friend-based collaborative filtering, while community features could allow users to share and discover playlists based on similar listening patterns. Real-time collaborative filtering could enable group playlist generation for shared listening experiences.
Advanced temporal modeling could incorporate more sophisticated time-series analysis techniques. Seasonal decomposition could identify yearly listening patterns, while change point detection could identify significant shifts in musical preference. Predictive modeling using techniques like LSTM networks could enable longer-term preference forecasting and proactive music discovery.
Explainable AI integration could enhance user trust and engagement through transparent recommendation explanations. Techniques such as LIME (Local Interpretable Model-agnostic Explanations) could provide detailed explanations of why specific artists were recommended, while visualization of the recommendation decision process could help users understand and refine their preferences.
Real-time streaming integration could transform the system from a batch-processing application to a real-time recommendation engine. Integration with Spotify's real-time API could enable live recommendation updates based on current listening behavior, while streaming data processing frameworks could handle continuous preference model updates.
The music recommendation system presented in this article represents a comprehensive exploration of modern recommendation system techniques applied to the rich domain of music discovery. Through its combination of sophisticated algorithms, thoughtful user experience design, and robust technical implementation, it demonstrates how personal data can be transformed into meaningful insights and enhanced experiences. As music streaming continues to evolve and user expectations for personalized experiences grow, systems like this provide a foundation for the next generation of intelligent music discovery platforms.
The complete source code, documentation, and deployment instructions for this system are available for replication and extension, enabling researchers, developers, and music enthusiasts to build upon these techniques and explore new frontiers in algorithmic music discovery. The modular architecture and comprehensive documentation ensure that the system can serve as both a practical tool for personal music discovery and a research platform for advancing the state of the art in recommendation systems.
References
[1] Spotify for Developers. "Web API Reference." Spotify. https://developer.spotify.com/documentation/web-api/
[2] Last.fm. "API Documentation." Last.fm. https://www.last.fm/api
[3] MusicBrainz. "MusicBrainz API." MusicBrainz Foundation. https://musicbrainz.org/doc/MusicBrainz_API
[4] Koren, Y., Bell, R., & Volinsky, C. (2009). "Matrix Factorization Techniques for Recommender Systems." Computer, 42(8), 30-37.
[5] Ricci, F., Rokach, L., & Shapira, B. (2015). "Recommender Systems Handbook." Springer.
[6] Schedl, M., Zamani, H., Chen, C. W., Deldjoo, Y., & Elahi, M. (2018). "Current challenges and visions in music recommender systems research." International Journal of Multimedia Information Retrieval, 7(2), 95-116.
[7] Scikit-learn Development Team. "Scikit-learn: Machine Learning in Python." Journal of Machine Learning Research, 12, 2825-2830.
[8] Streamlit Inc. "Streamlit Documentation." Streamlit. https://docs.streamlit.io/
[9] Plotly Technologies Inc. "Plotly Python Graphing Library." Plotly. https://plotly.com/python/
[10] Pandas Development Team. "pandas: powerful Python data analysis toolkit." https://pandas.pydata.org/
Subscribe to my newsletter
Read articles from Roberto directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Roberto
Roberto
I'm technology-geek person, in love with almost all things tech from my daily job in the Cloud to my Master's in Cybersecurity and the journey all along.