Community Experiences with Apache Hudi: Challenges and Wins
 Community Contribution
Community ContributionTable of contents
- Key Takeaways
- Apache Hudi Challenges
- Hudi Solutions and Wins
- User Stories
- Community Collaboration
- FAQ
- What is the best way to optimize Apache Hudi compaction?
- How does Apache Hudi handle schema evolution?
- Can Apache Hudi integrate with cloud platforms like AWS Glue or Databricks?
- What are the main differences between Copy-on-Write and Merge-on-Read tables?
- Where can users find resources for hudi vs delta vs iceberg comparisons?

“Has anyone managed to optimize compaction in Apache Hudi for large datasets?” a user asked in the Hudi community Slack. Many professionals share their experiences with Hudi, revealing both technical wins and persistent challenges. The hudi community values every lesson learned, whether from troubleshooting schema evolution or celebrating apache hudi momentum. These experiences with hudi highlight the importance of collaboration and practical insight. Users rely on the community to turn obstacles into opportunities.
Key Takeaways
Apache Hudi users face challenges with performance, integration, and usability, especially when handling large datasets and complex workflows.
Technical innovations like scalable metadata servers and non-blocking concurrency control improve Hudi's speed, reliability, and ability to handle many users at once.
Many companies successfully migrated to Hudi, gaining faster data ingestion, better data quality, and real-time analytics capabilities.
The active Hudi community shares knowledge through forums, events, and documentation, helping users solve problems and adopt best practices.
Regular tuning, monitoring, and participation in the community help users optimize Hudi’s features and keep up with improvements.
Apache Hudi Challenges
Performance Issues
Performance remains a central topic in the hudi community. Many users report that the complexity of apache hudi's system design can lead to performance degradation, especially when managing very large datasets. For example, datasets with more than 500 million entries often experience slowdowns. Community discussions frequently highlight several recurring pain points:
The system's index management, particularly when storing all indexes in RocksDB State, can drive up storage costs.
Data consistency issues arise when multiple engines read or write, which can disrupt the state’s index.
Tuning parameters, such as the bucket number for the Bucket Index, proves challenging and directly impacts both performance and small file management.
Hudi’s original batch-processing design sometimes struggles to adapt to streaming scenarios, increasing system complexity and maintenance overhead.
Upsert mechanisms and indexing strategies can introduce additional performance and usability concerns.
A production job using apache hudi 0.12.1 on AWS Glue 4.0 and Spark 3.3.0 demonstrated a slowdown from 5 minutes to 15 minutes per run, even though the data volume remained unchanged. The root cause was metadata accumulation in the .hoodie directory, including timeline and archive files. Additional processing steps, such as FSUtils and CleanPlanActionExecutor, became bottlenecks. When the same data was loaded into a new hudi table, the job completed in the expected 5 minutes, confirming that metadata buildup caused the slowdown. This pattern of performance degradation due to metadata and cleanup overhead appears in many production environments.
Benchmark studies comparing hudi to other data lake solutions, such as Delta Lake and Apache Iceberg, reveal that standard benchmarks often favor append-only workloads. Hudi’s default upsert mode introduces write overhead, which requires configuration adjustments for fair comparisons. However, advanced benchmarking frameworks that include data mutations and concurrency show that hudi maintains better longevity and resilience over time. Walmart’s engineering team found that hudi outperformed Delta Lake and Iceberg in demanding, update-heavy, and concurrent workloads. These results highlight hudi’s superior performance and robustness in real-world mutable and concurrent data lake scenarios.
Note: The hudi community continues to share best practices for tuning and optimizing performance, especially as new releases address these challenges.
Integration Barriers
Integration with other platforms presents another set of challenges for hudi users. Many organizations seek to connect hudi with platforms like Databricks and Microsoft Fabric. However, differences in data formats, metadata handling, and concurrency control often complicate these integrations. Users frequently ask about compatibility and best practices for connecting hudi with existing data management pipelines.
Some users encounter issues when integrating hudi with Spark or AWS Glue, especially when dealing with schema evolution or compaction.
The lack of standardized connectors for certain platforms can slow down adoption and increase engineering effort.
Data consistency and index management become more complex when multiple engines interact with the same hudi table.
Peloton’s experience, shared during a community sync, highlighted practical integration challenges. Their team built a hudi-powered data lake using change data capture (CDC) but struggled to maintain data quality and freshness. They developed an auto-healing pipeline to address these issues, demonstrating the need for innovative solutions when operationalizing hudi for analytics and machine learning.
Tip: The hudi community recommends reviewing documentation for each key release and participating in community calls to stay updated on integration improvements.
Usability Questions
Usability remains a frequent topic in community forums and Slack channels. New users often express confusion about hudi’s features, such as schema evolution, compaction, and incremental processing. The learning curve can be steep, especially for teams transitioning from other data lake solutions.
Many users find the documentation for advanced features lacking in practical examples.
Questions about parameter tuning, especially for compaction and indexing, appear regularly in community discussions.
The original batch-oriented design of hudi sometimes creates friction for teams aiming to implement real-time or streaming data pipelines.
The hudi community has seen a surge in questions following each of the key releases, especially after the hudi 1.0 release. Users want to understand how new features impact existing workflows and what best practices to follow. Community members often share code snippets and troubleshooting tips, but the need for clearer guidance persists.
Block Quote: “How do I enable incremental processing without breaking existing queries?” is a question that surfaces repeatedly, reflecting the ongoing need for accessible, actionable documentation.
Despite these challenges, the hudi community remains active in addressing usability concerns. Each release brings improvements, but users continue to request more comprehensive guides and real-world examples to ease adoption.
Hudi Solutions and Wins
Technical Innovations
The hudi community has introduced several technical innovations that directly address performance and scalability challenges. These advancements reflect a commitment to both enterprise-grade reliability and open-source agility. The following table summarizes key innovations and their impact on system performance:
| Innovation | Description | Impact on Performance and Scalability |
| Scalable Metadata Server (Metaserver) | Introduces a dedicated metadata server using local RocksDB and REST API to efficiently manage table metadata, reducing expensive cloud storage listings and enabling horizontal scaling and improved security. | Improves metadata management efficiency and scalability for large numbers of tables, reducing latency and resource usage. |
| Asynchronous Metadata Indexing | Enables creation of various indices without blocking writes, reducing contention between writing and indexing activities. | Enhances write latency and throughput by allowing concurrent indexing and writing operations. |
| Non-blocking Concurrency Control (NBCC) | Implements lock-free MVCC and optimistic concurrency control allowing multiple writers and table services to operate concurrently with early conflict detection. | Supports high concurrency with consistent snapshot isolation, improving scalability and write performance. |
| Multi-tenant Lake Cache | Provides a shared caching layer across query engines that stores pre-merged file slices, reducing storage access costs and improving query speed. | Balances fast data writing with optimal query performance, reducing I/O and resource consumption. |
| Multi-modal Indexing Subsystem | Incorporates various index types (file listings, bloom filters, column stats, expression indexes) to speed up record location and query planning. | Accelerates both write transactions and query performance on large and wide tables. |
| Automated Table Services (Clustering, Compaction, Cleaning) | Offers inline or asynchronous services to optimize storage layout and metadata management, including grouping records, merging files, and removing obsolete data. | Maintains efficient storage and metadata, reducing I/O and improving overall system performance and scalability. |
Recent releases have delivered measurable performance enhancements. For example, partial updates using MERGE INTO SQL statements now achieve a 2.6x performance increase and reduce write amplification by 85%. These improvements result from modifying only changed fields instead of entire rows. Non-blocking concurrency control allows multiple writers and compactions to operate simultaneously, increasing reliability in concurrent environments. The introduction of a revamped LSM timeline enables scalable storage of action history, supporting long-term table history retention. These technical advancements collectively deliver faster, more efficient, and more reliable data processing for hudi users.
Apache hudi 1.0 introduced positional merging and enhanced partial update support. Positional merging processes updates at the record position level, enabling page skipping and faster operations. Partial updates rewrite only modified columns, leading to a 2.6x improvement in query performance and an 85% reduction in write amplification on large datasets. These features reduce operational costs and maintain fast query performance as datasets scale, demonstrating the impact of community-driven development on data lakehouse solutions.
Migration Success
Enterprises have achieved significant wins by migrating to hudi. The platform supports snapshot isolation and atomic batch writes, which enable consistent and reliable data ingestion. Incremental pull capabilities and built-in deduplication maintain data quality, which is critical for modern data management pipelines. Hudi’s design allows it to run on various cloud storage systems, ensuring flexibility and scalability for diverse environments.
Walmart’s migration to hudi resulted in over 5X faster ingestion compared to previous ORC pipelines.
Complex ingestion patterns were efficiently handled, with batch ingestion jobs completing in about 15 minutes and compactions in approximately 50 minutes using 150 cores.
Query performance benchmarks showed that while Delta Lake was generally faster by about 40%, hudi provided significantly faster deduplicated real-time views, which are essential for real-time data accuracy.
Hudi’s architecture supported snapshot isolation, atomic writes, incremental pulls, and deduplication, ensuring data consistency and quality.
Operational metrics for hudi (commit, clean, rollback) were monitored using tools like M3, Prometheus, Graphite, and JMX, demonstrating enterprise-grade operational stability.
Walmart’s technology selection process considered availability, compatibility, cost, performance, roadmap, support, and total cost of ownership, with hudi emerging as the preferred solution.
The migration succeeded at scale across a diverse technology stack, leveraging over 600,000 Hadoop and Spark cores in multiple cloud environments.
These outcomes highlight hudi’s ability to deliver enterprise-grade performance and reliability, making it a trusted choice for large-scale data lakehouse solutions.
Lessons Learned
Community members have shared valuable lessons from overcoming technical and operational challenges with hudi. Their experiences offer practical guidance for future adopters:
Concurrency Control: Amazon faced massive concurrency with thousands of concurrent table updates and hundreds of billions of rows ingested daily. Initially, they used Optimistic Concurrency Control (OCC), which led to frequent retries and failures under high contention. The team redesigned table structures to minimize concurrent insertions, enabling OCC to work effectively and reducing job failures.
Metadata Table Management: The metadata table improved performance by indexing files and avoiding expensive cloud storage listings. Amazon started with synchronous cleaning but switched to asynchronous cleaning to reduce job runtimes. However, async cleaning caused metadata inconsistencies due to a known issue, forcing a revert to synchronous cleaning to ensure correctness.
Cost Management: Operational costs were dominated by API interactions (PUT and GET requests) with S3 rather than storage size. Heavy update concentration in single partitions increased costs. To optimize, Amazon adopted S3 Intelligent-Tiering, EMR auto-scaling, and tuned hudi configurations to reduce file churn and unnecessary operations.
Peloton’s journey also provides important insights:
Copy-on-Write (CoW) vs Merge-on-Read (MoR): Peloton initially used CoW tables for simplicity and Redshift Spectrum compatibility but encountered performance bottlenecks with high-frequency updates and large commit retention. Migrating to MoR tables and reducing commit retention improved ingestion latency and resource efficiency.
Async vs Inline Table Services: Asynchronous cleaning and compaction improved throughput but introduced operational edge cases such as job conflicts, race conditions causing intermittent read failures, and compaction disruptions due to node terminations. Peloton mitigated these by implementing DynamoDB locks and eventually switched to inline table services with custom logic to balance reliability and latency.
Schema Management Challenges: Peloton faced schema versioning limits with AWS Glue, indicating ongoing operational challenges in schema evolution.
The hudi community balances enterprise needs with open-source development through a community-first, user-centric approach. Under the governance of The Apache Software Foundation, hudi maintains neutral oversight and long-term sustainability. This model supports enterprise reliance by providing stability and openness, avoiding vendor lock-in. The project’s self-managing tables and open compute services deliver enterprise-grade features within an open-source framework, allowing users to benefit from automation and efficiency without sacrificing openness.
Vinoth Chandar, co-creator of hudi, emphasizes that adopting The Apache Way enables collaboration among diverse contributors. This approach allows the project to evolve by addressing real-world enterprise challenges while fostering innovation. Uber’s extensive use of hudi—managing over 4,000 tables and several petabytes of data—demonstrates scalability and efficiency improvements, such as reducing Hadoop warehouse access latency from hours to under 30 minutes. These examples illustrate how community-driven development under neutral governance balances enterprise requirements like scalability and operational efficiency with open-source values.
Tip: The hudi community encourages users to participate in releases, share feedback, and contribute to ongoing performance enhancements. This collaborative spirit ensures that hudi continues to meet the evolving needs of both enterprises and the broader open-source ecosystem.
User Stories
Adoption Journeys
Many organizations have shared their adoption journeys with hudi, highlighting both challenges and achievements. Teams often begin by seeking a solution for real-time data ingestion and efficient data management. They encounter initial hurdles with integration and tuning, but the hudi community provides guidance and practical advice. For example, ByteDance adopted hudi to manage over 400PB of data, demonstrating the platform’s scalability and reliability. JobTarget migrated to hudi to address data duplication and storage inefficiencies. After the transition, they reported faster insights and improved data quality. Uber developed hudi to meet the need for low-latency data lakes, enabling rapid data availability and unified serving layers. These experiences show that organizations can achieve significant improvements by leveraging hudi’s features and the support of the community.
Business Impact
Organizations that implement hudi often see measurable business benefits:
Incremental processing reduces unnecessary data scans and controls operational costs.
Multi-modal indexing accelerates queries by up to 100 times, supporting faster analytics.
Flexible storage layouts, such as Copy-on-Write and Merge-on-Read, allow teams to optimize for either read or write workloads.
Real-time analytics become possible, with sub-minute latency and support for frequent updates.
Major companies like ByteDance and Uber have demonstrated hudi’s ability to scale and enhance analytics capabilities.
JobTarget’s migration to hudi resulted in faster, more accurate insights and significant cost savings. The use of ACID transactions and efficient querying addressed data duplication and optimized storage. Uber reduced data latencies to minutes and improved both compute and storage efficiency, directly impacting business performance.
| Aspect | Description |
| Business Challenge | Performance limits, data duplication, consistency issues, and high latency in batch and streaming workloads |
| Solution | Adoption of Apache Hudi for incremental updates, unified batch and streaming pipelines |
| Performance Improvement | 5× speedup in a critical batch job; reduced data duplication; improved ingestion performance |
| Data Freshness & Consistency | Near real-time analytics enabled; consistent, up-to-date data visible to consumers |
| Storage & Query Impact | Reduced data store size by removing redundant copies; improved query performance |
| Integration & Compatibility | Compatible with existing Spark versions; fits open-source strategy; avoids vendor lock-in |
| Business Impact | Modernized data architecture; enabled real-time use cases; ongoing expansion across enterprise |
Community Voices
The hudi community plays a vital role in supporting new adopters and sharing best practices. Members frequently discuss their experiences in forums and Slack channels, offering troubleshooting tips and success stories. Many users highlight the value of open collaboration and knowledge sharing. One user noted, “The community helped us resolve a critical compaction issue, saving hours of engineering time.” These collective experiences foster a culture of continuous improvement and innovation. The hudi community remains a cornerstone for organizations seeking to maximize the value of their data platforms.
Community Collaboration
Engagement Channels
The Apache Hudi community thrives through multiple engagement channels that support technical discussions and collaborative problem-solving. Members interact on GitHub, mailing lists, Slack, and dedicated boards. Each channel serves a unique purpose, from real-time chat to formal decision-making. The following table highlights the most active channels and their participation metrics:
| Engagement Channel | Description / Usage | Participation Metrics / Activity Level |
| GitHub Issues & Pull Requests | Technical discussions and support | 1841 interactions; steady growth in open PRs and issues |
| Developer Mailing List | Major decisions, RFCs | 158 emails, 38 topics, 41 participants; recent uptick in conversations |
| Slack | Real-time community interaction | Nearly 500 members; ~500 messages; fluctuating engagement |
| Monthly Developer Sync Calls | Technical deep dives, updates | Regularly held; ~10 contributors per walkthrough |
| Community Boards | Contribution prioritization and support | Organizes user support and PR review work |
| RFC Discussions on cWiki | Design document discussions | Over 200 interactions |
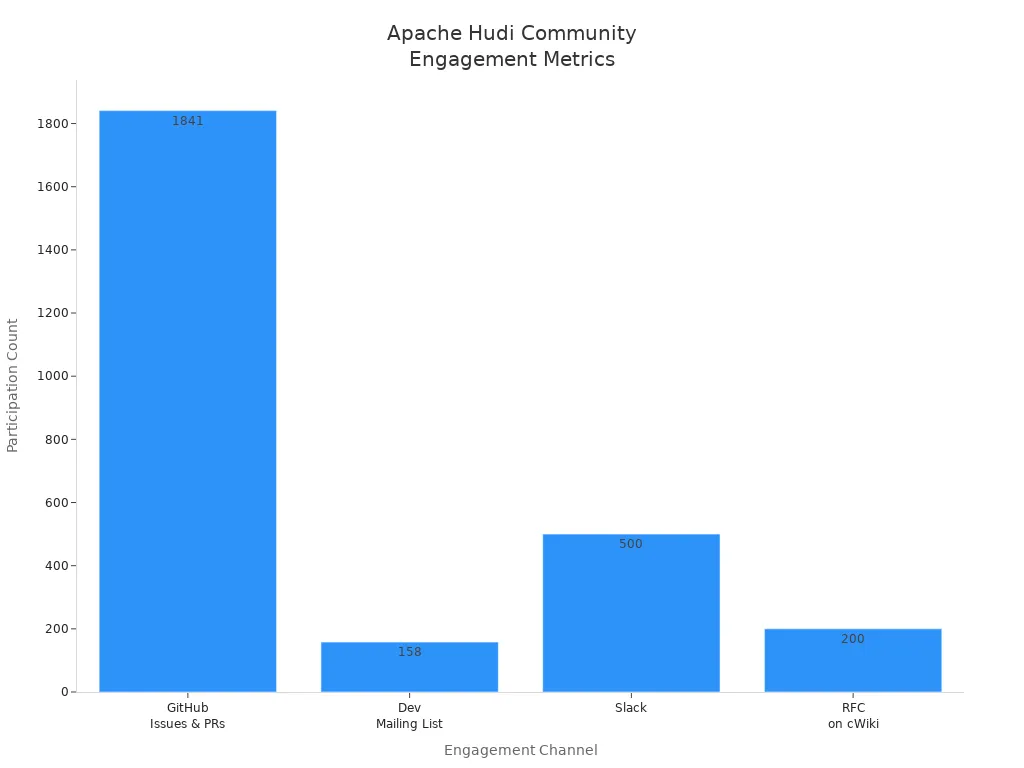
These channels foster collaboration within the open-source community and encourage active participation. The hudi community continues to grow, with increasing committers and ongoing improvements in infrastructure and review turnaround.
Knowledge Sharing
Knowledge sharing drives community growth and supports both new and experienced users. Members contribute blog posts and technical articles that explain Apache Hudi features and use cases. Social media platforms, including LinkedIn and YouTube, distribute community content and educational updates. Weekly office hours with PMC members provide direct access to expert guidance. The Slack channel, with thousands of users, enables interactive discussions and peer support. Community-hosted sessions, such as “Lakehouse Chronicles with Apache Hudi,” offer hands-on tutorials and demonstrations. These practices encourage learning and foster a supportive environment.
Community-driven articles and blog posts
Social media updates and educational content
Interactive Slack discussions
Weekly office hours with experts
Structured event series for tutorials
Opportunities for contributions and involvement
Tip: Regular sharing of best practices and real-world implementations helps users solve complex problems and accelerates adoption.
Events and Calls
Community events play a central role in bringing members together. Monthly virtual meetups, weekly office hours, and monthly community calls create opportunities for collaboration and learning. The hudi community hosts sessions on best practices, technical deep dives, and comparisons with other lakehouse technologies. Popular topics include performance benchmarks, serverless analytics, and integration with DBT. Major industry events, such as Databricks Data+AI Summit and Trino Fest, feature presentations and demos from community members. Participation rates reflect the vibrancy of the community, with thousands of LinkedIn followers and hundreds of reactions to community content.
Monthly virtual meetups via Zoom
Weekly office hours for direct Q&A
Monthly community calls for sharing projects
Presentations at major industry events
High engagement on topics like real-time analytics and data lake integrations
These events strengthen collaboration and support ongoing innovation within the hudi community.
The Apache Hudi community continues to grow, as shown in the table below. Users have faced challenges with performance, integration, and usability, but they have also celebrated technical wins and successful migrations. Regular review and open collaboration drive progress. The year in review highlights strong engagement, with over 2,200 pull requests and 800 organizations sharing use cases.
| Aspect | Key Takeaway |
| Community Growth | Slack users doubled to 2,600; 600+ GitHub users |
| Major Feature Releases | Schema evolution, data encryption, Flink enhancements, native Presto and Trino connectors |
| Performance Improvements | Optimizations and Long Term Support releases |
| Collaboration | Global events, monthly meetups, weekly office hours |
Members contribute thousands of messages and pull requests.
The community updates documentation and shares best practices.
Open forums and regular events foster ongoing learning.
The Apache Hudi community thrives on shared knowledge and active participation. New contributors help shape the future of hudi by joining discussions, sharing feedback, and supporting others.
FAQ
What is the best way to optimize Apache Hudi compaction?
Users should schedule compaction during low-traffic periods. They can tune parallelism and file size parameters for better performance. Monitoring compaction metrics helps identify bottlenecks and maintain efficient operations.
How does Apache Hudi handle schema evolution?
Apache Hudi supports schema evolution by allowing users to add or remove fields. The system manages backward and forward compatibility. Users should validate schema changes in a test environment before applying them to production tables.
Can Apache Hudi integrate with cloud platforms like AWS Glue or Databricks?
Yes, Apache Hudi integrates with AWS Glue, Databricks, and other cloud platforms. Users may need to configure connectors and review compatibility notes for each platform. Community forums provide guidance for common integration scenarios.
What are the main differences between Copy-on-Write and Merge-on-Read tables?
Copy-on-Write tables rewrite entire files during updates, offering simpler read paths. Merge-on-Read tables store changes separately and merge them during reads, which improves write performance but may increase read complexity.
Where can users find resources for hudi vs delta vs iceberg comparisons?
The Apache Hudi community provides blog posts and presentations that discuss hudi vs delta vs iceberg comparisons. Users can review these resources to understand feature differences, performance benchmarks, and use cases.
Subscribe to my newsletter
Read articles from Community Contribution directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by