Understanding Checkpointing and Its Importance
 Community Contribution
Community Contribution
Checkpointing refers to saving the state of a system or application at specific intervals, allowing restoration after unexpected failures. Organizations face increasing risks from data breaches and cyberattacks, with average costs reaching $4.88 million per incident in 2024 and human factors causing most breaches.
Checkpointing minimizes data loss and supports business continuity by enabling quick recovery and reducing downtime in mission-critical environments.
Modern databases, long-running applications, and AI model training jobs rely on checkpointing for fault tolerance and efficient resource management, reflecting its widespread adoption across industries.
Key Takeaways
Checkpointing saves a system's state regularly to help recover quickly from failures and reduce data loss.
It improves system reliability by maintaining consistent data and supports fast recovery to minimize downtime.
Checkpointing is widely used in databases, data pipelines, and AI to ensure smooth operations and protect important data.
Choosing the right checkpoint type and frequency balances performance with recovery speed and storage needs.
Regular testing and monitoring of checkpoints help maintain system health and ensure recovery plans work well.
Definition of Checkpointing
What Is Checkpointing
Checkpointing stands as a foundational concept in computer science and data management. The formal definition of checkpointing describes it as a technique for capturing and saving the state of a process or system at specific points in time. This saved state, called a checkpoint, allows a system to recover from failures by resuming from the last checkpoint rather than starting over. In high-performance computing and distributed systems, checkpointing strategies play a critical role in ensuring system reliability and efficient recovery. For example, in database management systems, a checkpoint marks a consistent state where all transactions are committed. This process enables recovery and maintains data integrity. SQL Server, for instance, writes modified in-memory pages and transaction log information to disk during a checkpoint, ensuring that the system can restore to a stable state after a crash.
Note: The definition of checkpointing highlights its importance in both fault tolerance and data consistency. By periodically saving the system state, organizations can minimize the impact of unexpected failures.
Checkpointing involves several core processes:
Saving the intermediate data and computations, known as the "state," at regular intervals.
Using event-based, time-based, or manual triggers to create checkpoints.
Storing checkpoints in reliable and durable storage systems, such as distributed cloud storage.
Balancing the frequency of checkpoints to optimize performance and minimize overhead.
Why Use Checkpointing
Organizations implement checkpointing for several essential reasons. The primary motivation centers on protecting data integrity and ensuring rapid recovery after failures. When a system experiences a crash or interruption, checkpointing allows it to revert to the last stable checkpoint, reducing data loss and downtime.
Key benefits of checkpointing include:
Fault Tolerance: Systems can recover from failures by restarting from the last checkpoint, which minimizes data loss and avoids full reprocessing.
System Reliability: Checkpointing maintains verified data states, supporting consistent operations and reducing the risk of data corruption.
Operational Efficiency: By reducing recovery time and resource overhead, checkpointing increases overall efficiency.
Data Security: Checkpoints enable recovery from breaches or corruption, safeguarding data integrity.
Compliance and Auditing: Organizations can verify data states at various stages, supporting regulatory compliance and audit requirements.
Checkpointing also supports performance optimization. Strategies such as incremental checkpointing and selective checkpoint frequency help organizations balance overhead with system availability. In practice, checkpointing appears in database management, software development version control, and data analysis reproducibility. These applications demonstrate how checkpointing maintains consistency and stability across diverse environments.
Key Aspects of Checkpointing
Fault Tolerance
Fault tolerance stands as one of the most important key aspects of checkpointing. In distributed computing systems, checkpointing periodically saves the state of applications or processes to stable storage. This approach allows systems to restart from the last checkpoint after a failure, which avoids starting from the beginning. Coordinated checkpointing synchronizes all processes to ensure a consistent global state, while uncoordinated checkpointing lets processes save their state independently. Both methods help maintain fault tolerance by preserving progress and reducing recovery time. Real-world systems such as Hadoop Distributed File System and Amazon DynamoDB use checkpointing to maintain consistent states and enable fast recovery after failures.
Checkpointing reduces downtime by enabling quicker recovery from failures.
It supports scalability, from small applications to large distributed systems.
Combining checkpointing with message logging further enhances fault tolerance.
Tip: Regular checkpoint creation helps organizations avoid the domino effect, where one failure leads to a cascade of issues across the system.
Data Integrity
Data integrity ensures that information remains accurate and consistent during operations and after unexpected events. Checkpointing plays a critical role in maintaining data integrity, especially during system failures. Checkpoint-restart mechanisms, such as those using DMTCP, periodically save computational states. This process enables jobs to resume from the last checkpoint, preserving data integrity and computational continuity. Analyses of memory and CPU utilization show that checkpointing introduces some overhead, but it remains essential for system resilience. Checkpointing supports job preemption, migration, and recovery from hardware or power failures without data loss or corruption. Empirical data from high-performance computing environments confirm that checkpointing is indispensable for maintaining data integrity during failures.
Checkpointing preserves data integrity by allowing recovery to a recent, verified state.
It prevents data corruption and loss during unexpected shutdowns.
The ability to resume jobs from checkpoints reduces time and resource costs.
Recovery
Recovery defines how quickly and effectively a system can return to normal operations after a failure. Checkpointing provides granular recovery options, allowing restoration of entire systems or specific files from a checkpoint. Frequent and well-planned checkpoint schedules aligned with business needs enhance recovery speed. These schedules enable near-instant recovery without manual intervention. For example, PostgreSQL systems use checkpoint intervals between 30 minutes and 1 hour to optimize recovery speed. New features like asynchronous prefetching during recovery further improve recovery times. Enterprise systems that use virtualization and storage snapshots can reduce recovery time objectives to just a few minutes for critical applications. Automated failover and failback scripts restore service quickly, eliminating long manual recovery processes. Checkpointing, when combined with replication and backup, ensures comprehensive data protection and supports rapid recovery.
Shorter checkpoint intervals decrease the work needed during recovery.
Checkpointing enables organizations to meet strict recovery point objectives.
Integration with other data protection strategies, such as replication and backup, provides robust recovery options.
Note: Continuous Data Protection uses checkpoint-like restore points to allow recovery to very recent states, complementing traditional backup strategies and minimizing data loss.
Data Checkpoint in Practice
Databases
Modern database management systems rely on data checkpoint strategies to maintain consistency and durability. Incremental checkpoint methods record only changes since the last checkpoint, which reduces the volume of data written and improves performance. Popular systems such as PostgreSQL and Oracle offer configurable checkpoint intervals, allowing administrators to optimize recovery speed and minimize logging overhead. Distributed databases implement global and local checkpoint protocols to synchronize data across nodes.
Incremental checkpointing reduces overhead and increases throughput.
Consistent checkpointing protocols ensure rapid recovery and data integrity.
dbms checkpoints balance checkpoint frequency with recovery time, using mathematical models to determine optimal intervals.
Administrators continuously monitor checkpoint activity and tune intervals to achieve optimal performance and reliability.
Data Pipelines
Data checkpoint mechanisms play a vital role in pipeline architectures. Engineers save checkpoints at regular intervals, enabling the system to restart from the last successful stage after a failure.
Data ingestion checkpoints assess raw data for inconsistencies.
Data staging checkpoints apply quality checks before further processing.
Data transformation checkpoints verify cleaning and enrichment steps.
Data loading checkpoints catch issues before final storage.
Retry mechanisms and idempotent processing steps further enhance recovery, allowing safe retries without side effects. This approach minimizes downtime and reduces the need for full reprocessing.
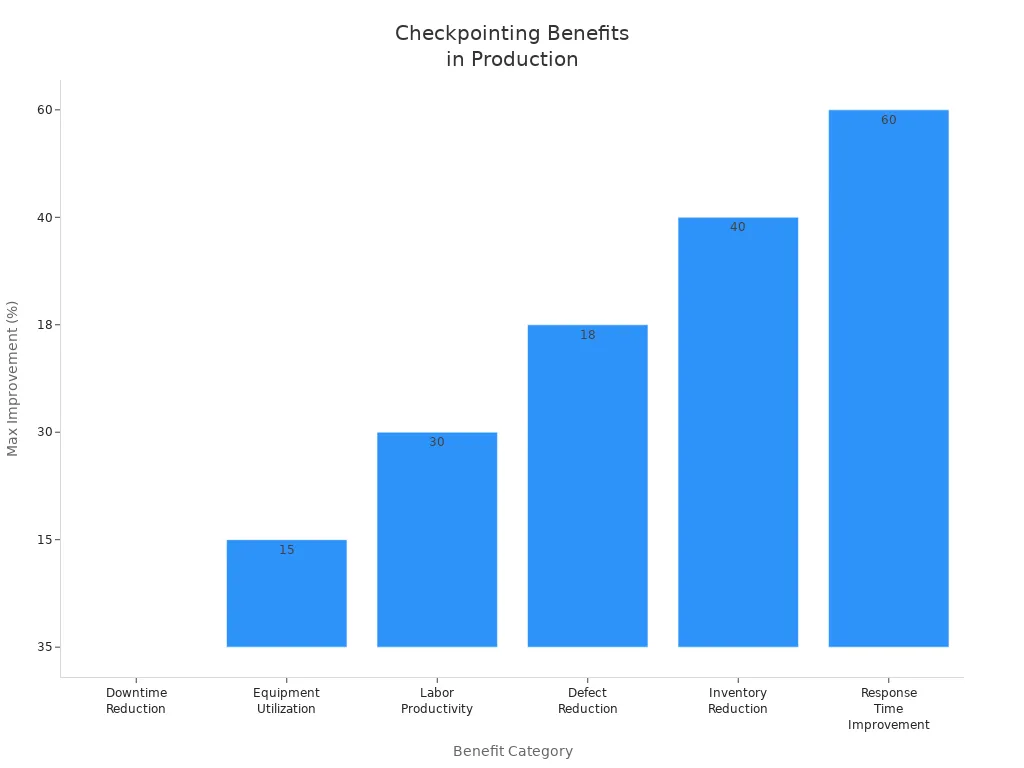
| Benefit Category | Quantitative Improvement | Description |
| Downtime Reduction | Up to 35% | Reduced unplanned stoppages through predictive maintenance and real-time monitoring. |
| Equipment Utilization | 10-15% improvement | Maximized uptime via planned maintenance and efficient scheduling. |
| Labor Productivity | 15-30% increase | Optimized workflows and elimination of bottlenecks. |
| Defect Reduction | 18% reduction | Quality control checkpoints integrated in production processes. |
| Inventory Reduction | 15-40% decrease | Just-in-time ordering and balanced stock levels. |
| Response Time Improvement | 40-60% faster | Faster detection and correction of production variances. |
AI and Machine Learning
AI and machine learning workflows depend on robust data checkpoint solutions. Engineers save model weights, optimizer states, and metadata at each checkpoint, enabling recovery from interruptions without losing progress.
Checkpoints support rollback, experimentation, and fine-tuning.
High-performance storage solutions reduce I/O bottlenecks, keeping GPUs fully utilized.
Distributed storage architectures ensure checkpoint data integrity and availability.
Recent advancements include multi-tier checkpointing, which uses RAM, in-cluster replication, and cloud storage to accelerate checkpoint writes and restores. Hybrid storage approaches balance speed and capacity, supporting large-scale model training and legal compliance.
Checkpoints preserve training metadata, ensuring reproducibility and consistent model behavior across experiments.
Checkpoint Mechanisms
Types of Checkpoints
Different checkpoint types serve distinct purposes in state management. Full checkpointing captures the entire application state at each checkpoint, making recovery straightforward but requiring significant storage and time. Incremental checkpointing, in contrast, saves only the changes since the last checkpoint, which reduces storage needs and speeds up the process. This method works well for large-scale systems with slowly changing data.
| Aspect | Full Checkpointing | Incremental Checkpointing |
| Checkpoint Scope | Entire application state | Only changes since last checkpoint |
| Storage Requirement | High | Much lower |
| Duration | Longer (e.g., 50–65 seconds) | Shorter (e.g., 3–5 seconds) |
| Scalability | Less scalable for large states | More scalable |
| Recovery Complexity | Simple | More complex |
Full checkpointing is often used for debugging or when a complete snapshot is needed. Incremental checkpointing is preferred in production environments where performance and storage efficiency matter most.
Note: Choosing the right checkpoint type depends on system size, performance needs, and recovery requirements.
Implementation Tips
Effective checkpoint implementation requires careful planning. Teams should monitor checkpoint duration, size, and alignment time using tools like Prometheus or Grafana. Parallelizing state access across multiple nodes improves performance, especially in distributed systems. Adjusting checkpoint intervals is crucial; frequent checkpoints reduce recovery time but can increase overhead and impact normal operations. Experts recommend starting with intervals of 10–15 minutes and tuning based on system behavior.
Clean up unnecessary data to optimize state size.
Use asynchronous checkpointing to minimize processing delays.
Ensure compatibility between model architecture and checkpoint format, especially in cloud environments.
Select storage solutions that match checkpoint size and network conditions. For large models, network file systems (NFS) offer faster uploads and better reliability than local storage.
Tip: Regularly test recovery from checkpoints to verify that state management strategies work as intended.
Organizations recognize recovery as a critical factor in maintaining business continuity and data protection. They measure recovery efficiency using metrics such as restart time, sustainable throughput, and invalid checkpoints. Case studies show that recovery improvements include faster maintenance cycles, better scheduling, and enhanced collaboration.
Teams optimize recovery by monitoring performance, validating benefit estimates, and documenting lessons learned.
Leaders should evaluate recovery strategies and adopt best practices to ensure operational reliability and minimize downtime.
Improved prioritization and scheduling
Enhanced collaboration between teams
Optimization of preventive maintenance
Better tracking and documentation
FAQ
What is the difference between checkpointing and traditional backup?
Checkpointing saves the system state at specific intervals for quick recovery. Traditional backup copies entire datasets for long-term storage. Checkpointing focuses on minimizing downtime, while backup protects against data loss over extended periods.
Tip: Use both strategies for comprehensive data protection.
How often should a system create checkpoints?
The optimal checkpoint frequency depends on system workload and recovery needs. Most organizations schedule checkpoints every 10–30 minutes. Frequent checkpoints reduce recovery time but may increase resource usage.
Monitor system performance to adjust intervals.
Test recovery regularly.
Can checkpointing slow down application performance?
Checkpointing may introduce minor delays during state saving. Incremental checkpointing and asynchronous methods help minimize impact. Engineers optimize checkpoint intervals and storage solutions to balance performance and reliability.
| Method | Impact on Performance |
| Full Checkpointing | Higher |
| Incremental | Lower |
| Asynchronous | Minimal |
Is checkpointing necessary for cloud-based systems?
Cloud-based systems benefit from checkpointing by enabling rapid recovery and maintaining data integrity. Distributed architectures and virtual machines rely on checkpoints to restore services quickly after failures.
Note: Cloud providers often offer built-in checkpointing tools.
What types of data can be checkpointed?
Systems can checkpoint application states, database transactions, machine learning models, and pipeline stages. The choice depends on business requirements and technical constraints.
Application state
Database logs
Model weights
Pipeline progress
Subscribe to my newsletter
Read articles from Community Contribution directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by