Exploring the Benefits and Drawbacks of Data Lakes
 Community Contribution
Community Contribution
A data lake serves as a central repository that stores all types of data, including structured, semi-structured, and unstructured data. Many organizations see a data lake as a solution to centralizing analytics and handling massive data volumes. According to recent surveys, 69% of organizations have implemented a data lake, and 92% believe it is the right approach for managing data. A data lake offers key benefits such as scalability, flexibility, and the ability to mix different data types. However, challenges remain. Many teams struggle with data duplication and disconnected tools, while IT specialists spend almost as much time preparing data as they do analyzing it.
Key survey findings:
87% of data lake users report better decision-making.
38% of organizations with a data lake respond to data requests within an hour.
Risks include data swamps and the need for strong metadata management.
Comparing a data lake to other solutions and building a thoughtful strategy helps organizations maximize value while avoiding common pitfalls.
Key Takeaways
Data lakes store all types of data in their original form, offering great flexibility and scalability for big data needs.
They help organizations save costs and support advanced analytics, real-time processing, and machine learning.
Strong data governance, quality control, and security are essential to prevent data lakes from becoming disorganized or risky.
Choosing the right strategy and tools, plus ongoing monitoring, ensures data lakes deliver reliable insights and business value.
Collaboration and training empower teams to use data lakes effectively and drive faster, smarter decisions.
Data Lake Overview
What Is a Data Lake
A data lake is a centralized storage system that holds vast amounts of data in its native format. Organizations use a data lake to store structured, semi-structured, and unstructured data without the need for upfront modeling. This approach allows teams to collect raw data from multiple sources, including databases, logs, images, and documents. Unlike traditional data warehouses, a data lake supports schema-on-read, which means users define the structure only when they access the data. This flexibility enables exploratory analysis and supports a wide range of analytics and machine learning tasks.
A data lake often leverages cloud object storage, such as Amazon S3 or Azure Blob Storage, to separate storage from compute resources. This separation allows organizations to scale storage and processing independently, making the data lake both cost-effective and adaptable. Data ingestion and integration processes play a crucial role in moving raw data into the data lake, ensuring that all types of data are available for analysis. Teams can use open file formats like Iceberg or Delta Lake, which support schema evolution and ACID transactions, to improve data quality and management.
Note: A data lake can store any data type, making it a foundational component for modern analytics and data science.
Role in Data Architecture
In modern data architecture, the data lake serves as the primary storage layer. It acts as the source of truth for all organizational data, supporting both operational and analytical workloads. The architecture typically follows a sequence: ingest, transform, model, and serve. Data ingestion and integration bring raw data into the data lake, where it remains accessible for transformation and modeling.
Data lakes enable organizations to use ELT (extract, load, transform) processes, loading raw data first and transforming it later. This method contrasts with the ETL (extract, transform, load) approach used in traditional warehouses. The data lake supports logical zoning, such as Raw, Enriched, and Curated zones, which helps improve data quality and governance. Teams can use external processing tools like Apache Spark to analyze data, supporting advanced analytics, machine learning, and data science use cases.
A data lake also provides federated access to external data sources, offering a unified view of data across the organization. This capability enhances integration and supports collaboration between teams. The separation of storage and compute in data lakes allows for scalable and flexible processing, making them ideal for big data environments.
| Data Lake Features | Traditional Data Warehouse Features |
| Stores all data types | Focuses on structured data |
| Schema-on-read | Schema-on-write |
| ELT process | ETL process |
| Scalable, cloud-based | Limited scalability |
| Supports advanced analytics | Optimized for BI reporting |
Data Lake Benefits
Scalability
A data lake delivers unmatched scalability for organizations managing massive data volumes. Unlike traditional data warehouses, which require structured data and upfront schema definitions, a data lake stores all types of data in their native format. This approach enables organizations to handle petabytes of data—one petabyte equals one million gigabytes—without performance loss or excessive costs. Data lakes use cloud-based storage solutions, such as AWS or Azure, that expand as data grows. This architecture supports rapid scaling, allowing organizations to ingest and store data from thousands of sources efficiently.
Transactional frameworks like Apache Hudi and Delta Lake enable ACID transactions, supporting data integrity at scale.
Metadata management aids data discovery, governance, and compliance.
Data redundancy through multiple copies protects against data loss and improves query performance.
Retention policies help manage the data lifecycle, controlling storage costs and compliance.
Data catalogs centralize metadata, improving discoverability and governance.
Continuous monitoring and optimization ensure operational efficiency and scalability over time.
A recent survey of IT professionals at large enterprises found that over 20% of organizations pull data from more than 1,000 different sources. This demonstrates the scale at which a data lake operates, supporting diverse analytics needs and enabling organizations to adapt quickly to changing business requirements.
Flexibility
The flexibility of a data lake stands out as a core benefit. Organizations can ingest structured, semi-structured, and unstructured data—such as financial records, social media feeds, IoT sensor logs, images, videos, and emails—without enforcing predefined structures. This schema-on-read approach allows teams to explore and analyze data retrospectively, supporting both real-time and batch processing. Technologies like Apache Kafka and Spark enable organizations to process streaming data, further enhancing flexibility and agility.
| Data Type | Example Sources | Benefit to Organization |
| Structured | Financial records | Reliable reporting and compliance |
| Semi-structured | JSON, XML, sensor logs | IoT analytics, operational insights |
| Unstructured | Images, videos, emails | AI/ML, customer sentiment analysis |
A data lake empowers organizations to leverage data for machine learning, predictive analytics, and rapid decision-making. This flexibility and agility enable teams to respond to new business opportunities and challenges without the constraints of rigid data models.
Cost-Effectiveness
Cost-effectiveness is a significant advantage of a data lake. Organizations achieve substantial savings compared to traditional data warehouses, especially for incremental data ingestion and storage. Industry reports show a 77% to 95% reduction in compute costs for incremental data ingestion. Over 50% of surveyed organizations expect cost savings exceeding 50%, with nearly one-third anticipating savings above 75%. These savings result from reduced data replication, lower egress fees, and efficient compute usage.
| Aspect | Details |
| Cost Savings Range | 77% to 95% reduction in compute costs for incremental data ingestion |
| Expected Cost Savings | Over 50% compared to data warehouses |
| Large Organization Savings | Nearly one-third expect savings exceeding 75% |
| Key Benefit | Substantial cost reduction and scalability outweigh minor performance trade-offs |
Cloud-based data lakes also impact the total cost of ownership for large-scale data storage and analytics. Azure, for example, offers the most cost-effective option for annual and three-year TCO, while AWS, GCP, and Snowflake incur higher costs.
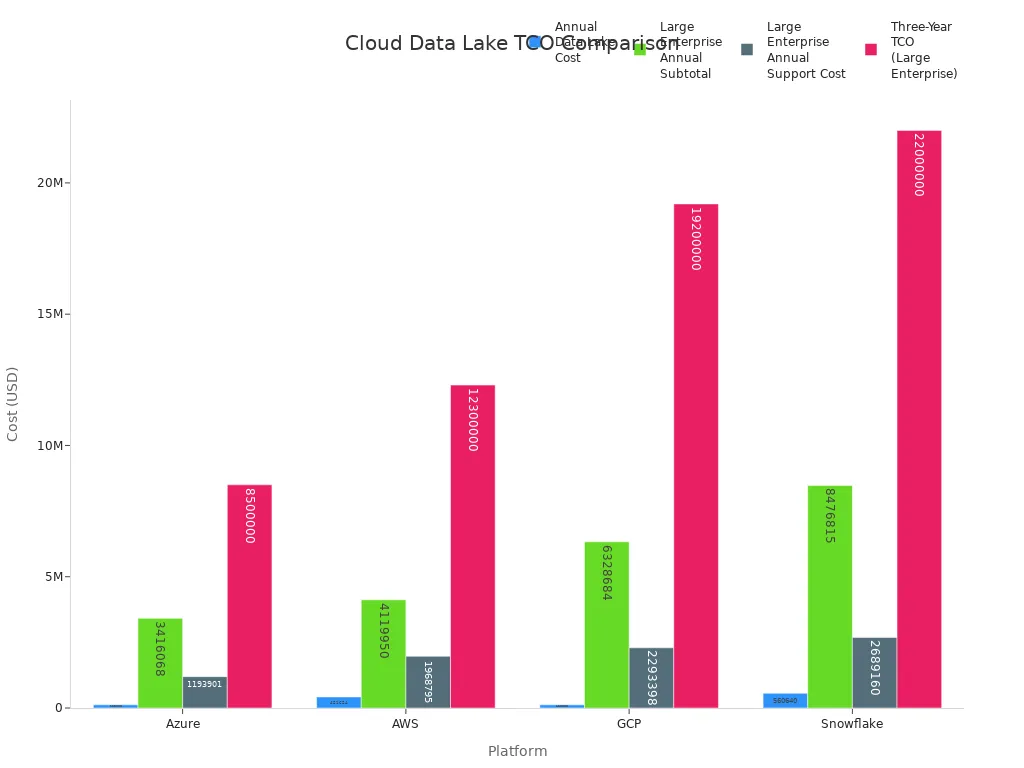
These cost advantages make a data lake an attractive solution for organizations seeking to scale analytics without excessive financial investment.
Analytics
A data lake enhances analytics capabilities by supporting real-time and advanced analytics across all data types. Organizations can ingest data in real-time from multiple sources, enabling flexible analytics without predefined schemas. Data lakes integrate with tools like Apache Spark, Presto, and Azure Synapse Analytics, allowing large-scale data processing and real-time querying.
Data lakes support diverse analytics workloads, including SQL queries, big data analytics, and machine learning.
Data scientists and analysts use their preferred tools directly on the data lake, increasing productivity.
Real-time data processing enables instant analysis of streaming data, supporting faster and more agile decision-making.
Organizations gain predictive insights for sales forecasting, fraud detection, and operational optimization.
By centralizing data and breaking down silos, a data lake democratizes data use and accelerates improved decision-making. Teams can discover new information models and respond rapidly to market changes.
Collaboration
Collaboration represents a key benefit of a data lake. By providing self-service access to data, a data lake reduces reliance on IT and empowers data scientists, analysts, and business users to work together. Shared workspaces, robust metadata layers, and easy-to-use interfaces lower technical barriers, enabling users to share insights, comments, and prepared datasets.
Azure Databricks, for example, demonstrates how a data lake facilitates collaboration. Shared notebooks, role-based access controls, and collaborative tools allow teams to work together seamlessly. A retail company reduced data processing time by 60% through collaboration between data engineers and analysts. A healthcare provider unified data from multiple sources, enabling clinicians and data scientists to build predictive models that improved patient care. Other organizations have increased sales, reduced churn, and improved operational efficiency by leveraging collaborative analytics in a data lake environment.
Tip: To maximize the benefits of collaboration, organizations should invest in governance, metadata management, and security. These measures ensure data reliability and usability, supporting productive teamwork and innovation.
Data Lake Challenges
Data Quality
Organizations often face significant data lake challenges related to data quality. As data lakes store massive volumes of raw, unstructured, and structured data, they become vulnerable to a range of quality issues. Common problems include missing data, duplicate records, erroneous entries, obsolete information, inconsistent formats, and hidden or orphaned data. These issues frequently arise from human error, lack of data standards, or poor formatting. Without systematic management, a data lake can quickly turn into a "data swamp," making it difficult to extract reliable insights.
Missing or duplicate data leads to operational inefficiencies.
Erroneous or obsolete data undermines trust in analytics.
Incompatible formats and hidden data complicate integration and reporting.
The business impact of poor data quality is substantial. On average, organizations lose between $12.9 million and $15 million annually due to these issues. Data engineers spend up to 61% of their time fixing data problems instead of innovating. Departments such as marketing, finance, and sales experience delays, while executives hesitate to act on unreliable data. Customer experience suffers from duplicate communications, incorrect support, and billing errors. These cascading effects highlight the importance of robust data quality management in every data lake.
Note: Proactive governance, continuous monitoring, and machine learning-driven validation rules help maintain high data quality and prevent costly business disruptions.
Governance
Effective governance stands at the core of successful data lake management. Without clear policies, roles, and responsibilities, organizations risk losing control over their data assets. Strong governance frameworks ensure consistency, accountability, and compliance across the data lifecycle. Industry leaders recommend standardizing data formats, implementing metadata management, and enforcing access controls such as role-based permissions and multi-factor authentication.
Establish clear policies and assign data stewardship roles.
Standardize data formats and maintain comprehensive metadata.
Enforce access controls and conduct regular audits.
Deloitte’s framework emphasizes the need for defined processes, technology implementation, and governance controls. These measures maximize data value, improve operational effectiveness, and support regulatory compliance. Organizations that benchmark their governance maturity using KPIs and gap analysis achieve better data democratization, standardized data, and enhanced security. However, challenges such as organizational resistance and integration complexity require cross-functional collaboration and ongoing data quality management.
Security
Security remains one of the most pressing data lake challenges. Data lakes store vast amounts of raw, unfiltered data, often without strict ingestion rules. This flexibility increases both organizational and regulatory risks. Compared to data warehouses, which benefit from mature security practices and structured environments, data lakes have less established security measures. The lack of governance and prioritization further compounds compliance risks.
Data lakes are inherently less secure due to their scale and lack of selectivity.
Data warehouses enforce data integrity and operate in controlled environments.
Security measures in data lakes are evolving but still lag behind traditional systems.
Organizations must safeguard sensitive data against unauthorized access and comply with regulations such as GDPR and CCPA. The exponential growth of both structured and unstructured data, persistent siloes, and rising cyber threats make security management complex. Integrating new technologies like AI and blockchain adds further challenges. To address these risks, organizations invest in advanced security frameworks, continuous staff training, and proactive regulatory measures.
Performance
Performance is a critical consideration when evaluating data lake challenges. Data lakes use schema-on-read, which provides flexibility but often results in slower query performance compared to data warehouses. Data warehouses, optimized for structured analytics, deliver faster and more consistent results for common workloads. For example, a global retail chain using a data warehouse achieved a 70% reduction in report generation time and real-time inventory management, outperforming data lakes in speed and reliability.
| System Type | Query Performance | Use Case Suitability |
| Data Warehouse | Sub-second to minutes | Fast, structured analytics |
| Data Lake | Minutes or longer | Flexible, exploratory analytics |
Several factors affect query performance in a data lake:
Data volume and frequency
Complexity of data transformations
Data organization (partitioning, compression, file formats)
Storage tiering and compute resource management
Metadata management and indexing
Mitigation strategies include efficient partitioning, using columnar file formats like Parquet, right-sizing compute resources, and implementing metadata management tools. These approaches help reduce data scanned, optimize compute usage, and improve query speed.
Skills Needed
Building and maintaining a data lake requires specialized skills and organizational commitment. Teams must understand distributed storage architectures, data ingestion pipelines, metadata management, security frameworks, and advanced analytics. Expertise in data governance, quality monitoring, and security protocols is essential to prevent the data lake from becoming unmanageable.
Data engineers must validate, cleanse, and monitor data continuously.
Security experts design and enforce protection measures.
Data stewards oversee governance and compliance.
Organizational adoption depends on cultural and talent transformation. Executive involvement in talent strategy aligns capability development with business objectives, improving productivity. Companies like Unilever have demonstrated success by embedding analytics professionals in business units, launching data literacy programs, and formalizing data-driven decision processes. These initiatives led to significant business improvements, including media savings, reduced downtime, and higher product success rates.
Transitioning from traditional reporting to exploratory analytics demands ongoing training and change management. Successful data lake adoption relies on both technical expertise and a culture that supports data-driven decision-making.
Data Lake vs Data Warehouse
Structure
Organizations often compare the structure of a data lake to that of a data warehouse when designing their data management strategies. A data warehouse stores processed, structured data using a schema-on-write approach. This means teams define the schema before loading any data, which ensures consistency and quality. In contrast, a data lake holds raw, native data in various formats, including structured, semi-structured, and unstructured data. The schema-on-read method allows users to define the structure only when they access the data, providing greater flexibility.
| Feature | Data Warehouse | Data Lake |
| Data format | Processed, structured data | Raw, native format including structured, semi-structured, and unstructured data |
| Schema approach | Schema-on-write (predefined schema before loading) | Schema-on-read (schema defined at query time) |
| Flexibility | Less flexible, designed for specific data types | Highly flexible, supports diverse data types |
| Data ingestion method | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
| Governance | Strong governance and data quality controls | Often lacks robust governance, risk of becoming data swamp |
| Performance | Optimized for fast, complex queries | Variable performance, requires optimization |
| Setup effort | More upfront work for schema design and curation | Easier initial setup, but may require more processing later |
| Use cases | Business intelligence, reporting, historical data analysis | AI, data science, IoT data storage, exploratory analytics |
These structural differences influence how organizations manage data, optimize performance, and control costs.
Use Cases
The choice between a data lake and a data warehouse depends on the specific use cases and the types of data involved. A data warehouse excels at handling structured data for business intelligence, analytics, and batch processing. It supports regulated environments where clean, organized data is essential for trusted insights. A data lake, on the other hand, supports both structured and unstructured data, making it ideal for data science, AI, machine learning, and rapid ingestion of diverse data types.
| Aspect | Data Warehouse | Data Lake |
| Data Type | Structured data only | Both structured and unstructured data |
| Use Cases | Business intelligence, analytics, batch processing | Data science, AI, machine learning, IoT, exploratory analytics |
| Data Quality | Clean, organized, high-quality data | Stores raw data; requires governance |
| Scalability | Scales well for structured data | Highly scalable for diverse formats |
| Performance | Consistent, high-performing for structured workloads | Flexible, may need optimization |
| Benefits | Faster insights, cost efficiency, supports decision-making | Quick ingestion, productivity, accessibility |
| Challenges | Not suited for unstructured data | Risk of data swamp without governance |
| Emerging Solutions | Cloud data warehouses | Cloud data lakehouses |
Organizations often adopt hybrid solutions, such as data lakehouses vs. data warehouses, to leverage the strengths of both systems.
Pros and Cons
Data lakes and data warehouses each offer distinct advantages and disadvantages. A data lake provides scalable, cost-effective storage for large volumes of diverse data. It supports flexible schema-on-read, making it suitable for evolving analytics and machine learning. However, inconsistent data quality and governance challenges can complicate management. Query performance may be slower, and security risks require careful attention.
A data warehouse delivers high-quality, structured data optimized for fast, complex queries and business intelligence. Strong governance and access controls ensure reliability and compliance. The main drawbacks include higher costs, complex ETL processes, and limited support for unstructured data.
Data lake advantages:
Stores large volumes of raw data in multiple formats.
Handles structured, semi-structured, and unstructured data.
Ideal for machine learning, big data analytics, and exploratory analysis.
-
Data quality can be inconsistent.
Requires significant processing and governance to remain useful.
Data warehouse advantages:
Provides high-quality data for analysis and reporting.
Optimized for complex queries and business intelligence.
Data warehouse disadvantages:
Expensive to implement and maintain.
Limited to structured data.
Organizations increasingly explore data lakehouses vs. data warehouses to combine flexibility, governance, and performance for modern analytics needs.
Data Lake Strategy
Implementation
A successful data lake strategy begins with careful planning. Organizations must define clear objectives and scope for their data lake. They assess data sources to understand volume and diversity. Designing the data lake architecture requires attention to scalability and interoperability. Teams implement robust APIs to connect legacy systems with modern data lakes, reducing integration complexity. Standardized data formats such as JSON, CSV, and Apache Avro streamline data ingestion and integration. Metadata management and cataloging tools improve data discovery and usability. Employee training and managed services address the shortage of skilled resources. Real-time analytics performance improves with columnar storage formats, indexing, and query optimization. Cloud-based storage, compression, and deduplication help manage scalability and costs.
| Step Number | Recommended Implementation Step | Common Challenges Encountered During Deployment |
| 1 | Define Objectives and Scope | Managing data volume and diversity |
| 2 | Assess Data Sources | Integration and architecture complexity |
| 3 | Design Data Lake Architecture | Data ingestion and processing difficulties |
| 4 | Data Governance and Compliance | Ensuring data accessibility and usability |
| 5 | Data Ingestion and Storage | Maintaining data quality and consistency |
| 6 | Metadata Management | Security and privacy concerns |
| 7 | Data Processing and Transformation | Cost management and optimization |
| 8 | Data Quality and Integration | Need for technical expertise and resource allocation |
| 9 | Security and Access Control | |
| 10 | User Training and Adoption | |
| 11 | Monitoring and Maintenance | |
| 12 | Continuous Evaluation and Improvement |
Best Practices
Organizations enhance their data lake strategy by following best practices for data quality, governance, and security. They organize data into logical zones based on sensitivity, simplifying management and improving security. Encryption protects data at rest and in transit, while secure key management ensures privacy. Role-based access control restricts data access according to user roles, applying the principle of least privilege. Data masking and tokenization anonymize sensitive data for testing and analytics. Comprehensive logs track data access and modifications, supporting audits and compliance. Regular security audits and anomaly detection identify vulnerabilities and emerging risks. Employee training raises awareness and ensures compliance with governance policies.
Tip: Automated governance policies and data lineage tracking help maintain data integrity and support improved decision-making.
Trends
Recent trends shape the evolution of data lake strategy. Organizations increasingly adopt unified platforms that manage data lakes, IoT analytics, and computing resources centrally. Automation tools such as AWS Glue and Azure Data Factory accelerate data lake creation and management. Familiar query languages like SQL improve accessibility and collaboration. Data lakehouses combine the strengths of data lakes and warehouses, supporting both traditional analytics and machine learning. AI-driven optimization, data mesh architectures, serverless computing, and edge computing enhance efficiency and real-time analytics. Industry forecasts predict rapid growth in the data lake market, driven by AI, cloud adoption, and IoT expansion. By 2025, most enterprises will use unified platforms and data lakehouses to support complex analytics and regulatory compliance. Organizations in retail, healthcare, and financial services leverage data lakehouses for real-time analytics, improved decision-making, and cost efficiency.
Data lakes offer organizations scalability, flexibility, and cost savings, but they also present challenges in data quality, governance, and security. To maximize value, teams should:
Define clear objectives and align data lake strategy with business goals.
Implement robust data governance, access controls, and metadata management.
Design scalable architectures and automate data ingestion for efficiency.
Staying informed about new data technologies, best practices, and emerging trends helps organizations maintain effective data management and drive innovation.
FAQ
What is the main difference between a data lake and a data warehouse?
A data lake stores raw data in many formats. A data warehouse stores structured data for reporting. Data lakes use schema-on-read. Data warehouses use schema-on-write.
Tip: Data lakes support more data types and analytics use cases.
How can organizations prevent a data lake from becoming a data swamp?
Teams should use strong governance, metadata management, and regular data quality checks.
Assign data stewards
Use data catalogs
Monitor data ingestion
These steps help maintain order and usability.
Are data lakes secure enough for sensitive information?
Data lakes can protect sensitive data with encryption, access controls, and monitoring. Security depends on proper setup and ongoing management.
| Security Feature | Purpose |
| Encryption | Protects data |
| Access Control | Limits exposure |
| Monitoring | Detects threats |
What skills do teams need to manage a data lake?
Teams need skills in cloud storage, data engineering, security, and analytics. Data stewards, engineers, and analysts work together.
Note: Ongoing training helps teams keep up with new tools and best practices.
Can a data lake support real-time analytics?
Yes. Data lakes process streaming data using tools like Apache Kafka and Spark. This supports real-time dashboards and alerts.
Real-time analytics
Faster decision-making
Improved business agility
Subscribe to my newsletter
Read articles from Community Contribution directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by