Implementing Retrieval-Augmented Generation (RAG) in Azure AI Foundry w/ Microsoft Fabric as a Data Source
 Nalaka Wanniarachchi
Nalaka WanniarachchiTable of contents
- Understanding RAG
- How RAG Works
- The Core Components: Embeddings, Indexes, and Vector Databases
- Typical RAG Workflow
- Approach 1 : Low / No-Code Solution
- Showcase - [ 01 ] with Agents playground UI
- Approach 2: Code-First Implementation
- Showcase - [ 02 ] with Visual Studio code in locally
- Showcase - [ 03 ] using Streamlit Frontend
- Key Takeaways
- Conclusion
- References

The RAG tooling ecosystem has exploded-LangChain, LlamaIndex etc and dozens of specialized vector databases each solve pieces of the puzzle beautifully. But enterprise implementations aren't just about technical capabilities; they're about reducing complexity, maintaining security boundaries, and scaling reliably. When your organization has already invested in the Microsoft stack, Azure AI Foundry with Fabric offers something beyond technical merit. It offers integration depth that external tools simply cannot match.
Here’s what we’re setting out to achieve in final phase…

Understanding RAG
If you've been keeping an eye on AI trends, you've probably heard of RAG ; short for Retrieval-Augmented Generation. It's a method for giving large language models (LLMs) access to your own data, so they can answer questions with accurate, up-to-date, and context-rich information instead of relying only on what they were trained on.
How RAG Works
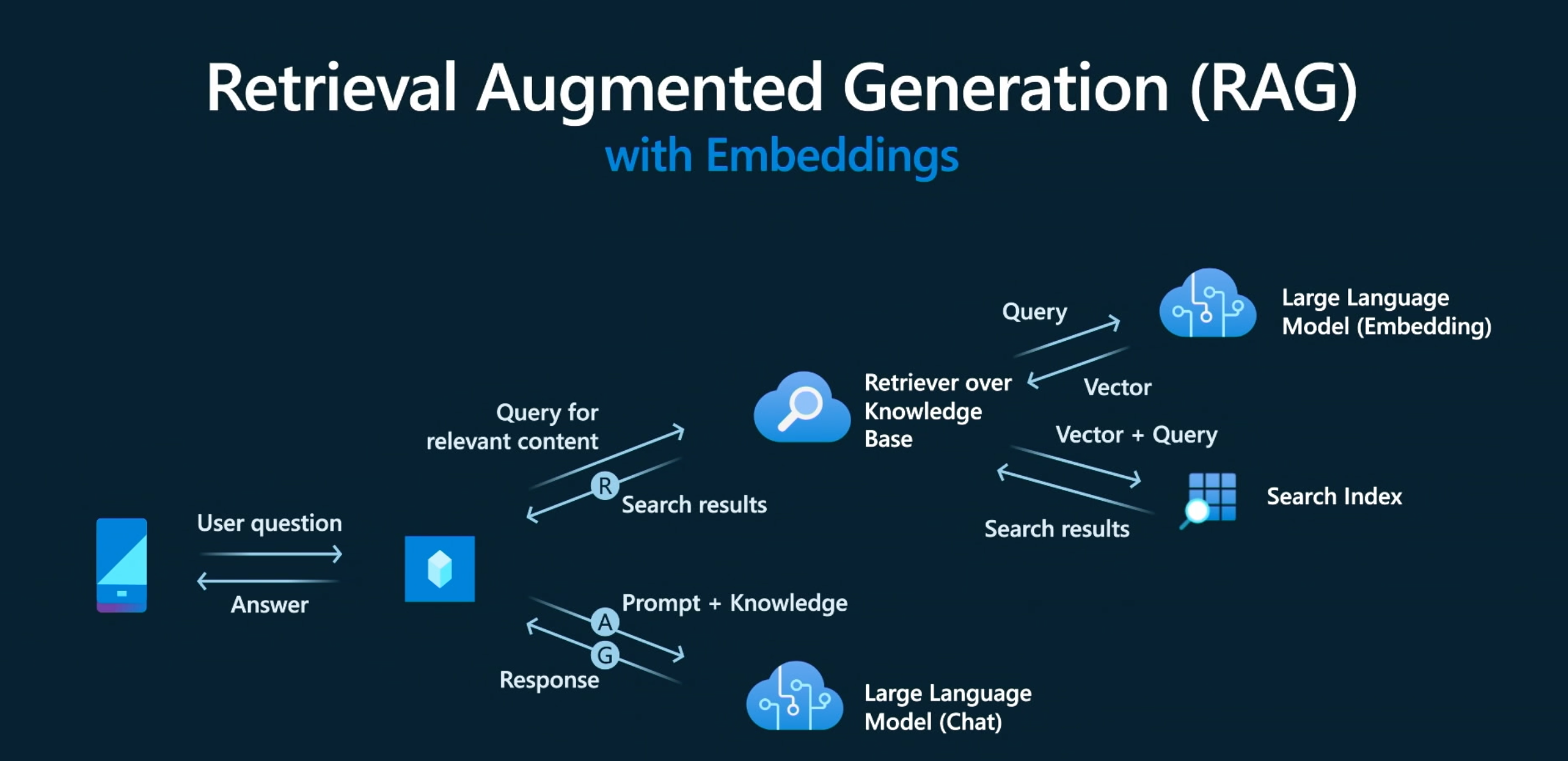
RAG creates a powerful synergy between your data and LLM capabilities. When a user submits a question, the system searches your data repository to find relevant information. The user question is then combined with matching results and sent to the LLM through a carefully crafted prompt. The LLM uses both the question and retrieved context to generate comprehensive, data-driven answers.

The Core Components: Embeddings, Indexes, and Vector Databases
Embeddings are numerical representations of text created by specialized AI models. These models convert words, sentences, or documents into high-dimensional vectors (arrays of numbers) that capture semantic meaning. Similar concepts produce similar vectors "car" and "automobile" become nearly identical number sequences despite being different words.
Indexes serve as the foundation for efficient data retrieval. They're specialized data structures that enable fast, accurate searches across your information repository. RAG indexes combine multiple search methods:
Keyword searches for exact term matching
Semantic searches for conceptual similarity
Vector searches for nuanced content relationships
Hybrid approaches that merge these capabilities
Vector Databases are storage systems optimized specifically for managing and searching embeddings. Unlike traditional databases that rely on exact matches, vector databases excel at similarity searches across millions of vectors in milliseconds.
Typical RAG Workflow
Document Processing: Your documents are broken into chunks and converted into embeddings
Storage: These embeddings are stored in a vector database (your searchable index)
Query Processing: User questions are converted into embeddings using the same model
Retrieval: The vector database finds the most semantically similar content
Generation: Retrieved context plus the original question are sent to the LLM for accurate, contextual answers(Most often using a different model )
This approach ensures responses are grounded in your actual data while leveraging the LLM's natural language capabilities.
RAG patterns that include Azure AI Search
Azure AI Search provides scalable search infrastructure that indexes diverse content types and enables retrieval through APIs, applications, and AI agents. The platform offers native integrations with Azure's AI ecosystem including OpenAI services, AI Foundry, and Machine Learning while supporting extensible architectures for third-party and open-source model integration.
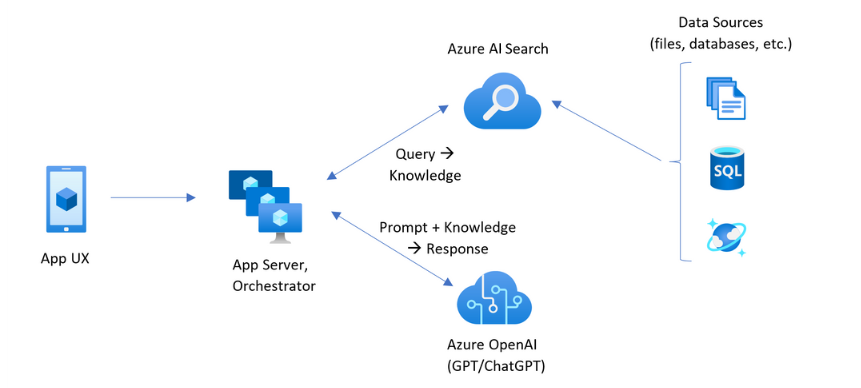
Let’s dive into practical implementation from here onwards.This would include both UI based approach and code first approach.
Note : I have omitted minor or commonly known details, focusing instead on explaining and elaborating the RAG pattern and it’s core setup and flow.
Approach 1 : Low / No-Code Solution
Create an Azure OpenAI resource
The initial step is to create an OpenAI resource in Azure, as illustrated below.
Navigate to the Azure AI Foundry portal and create an embedding deployment. You may select any base model of your choice; in this example, the ‘text-ada’ model has been selected.(text-embedding-ada-002 is part of gpt-3 model family.)

Jump back to Azure portal and create an Azure AI Search Resource (When allocating AI search mindful of the cost of the resource utilization)

Connect the document folder within the Fabric ‘Lakehouse’ files area and vectorize the data.(Once we navigate to the created AI search resource click as below.

Select Fabric OneLake files as source for the vectorization.Since the document I am using is purely text based document ( I used Microsoft Whitepaper on AI governance as my source file which consists 32 pages) and this was uploaded to Fabric Lakehouse files section by creating a folder


Select ‘RAG’

Next, specify the Fabric ‘Lakehouse’ URL along with the folder path where the files are located.

After completing these steps, navigate to the ‘Indexes’ section in the Azure AI Search portal. You will notice that an index is created within a short period of time.

Now we can create a new agent in Azure AI foundry and attach the created Azure AI search resource as a knowledge tool and play with the data in agent playground.

For the search type I have selected Hybrid search (Vector+Keyword)

Finally Try in agent playground 🏐

Showcase - [ 01 ] with Agents playground UI
It can be observed that the reference has been applied correctly, ensuring that no external sources were used as knowledge.(“AI Governance whitepaper.pdf”)

Tool calling succeeded, as confirmed within the thread status.

Approach 2: Code-First Implementation
Azure AI Foundry SDK / AI Projects client library
We'll primarily use the AI Projects client library is part of the Azure AI Foundry SDK, and provides easy access to resources in your Azure AI Foundry Project. ( The 'azure.ai.agents.models' package is a sub-module under this client library that handles agent-related operations.)
Install the libraries - (Note that the dependent package azure-ai-agents will be install as a result, if not already installed, to support .agent operations on the client.)
!pip install --upgrade azure-ai-projects azure-identity load_dotenv
!python -m pip install --upgrade pip
This code loads configuration values (like client ID, secret, tenant ID, and endpoint) from an external .env file (api_settings.env) into Python variables.
import os
from dotenv import load_dotenv
load_dotenv('api_settings.env')
CLIENT_ID = os.getenv("CLIENT_ID")
CLIENT_SECRET = os.getenv("CLIENT_SECRET")
TENANT_ID = os.getenv("TENANT_ID")
PROJECT_ENDPOINT = os.getenv("PROJECT_ENDPOINT")
The script below demonstrates the following steps.
- Authentication and Setup – The script retrieves Azure credentials (Tenant ID, Client ID, Client Secret) from environment variables and authenticates using
ClientSecretCredential. It then initializes theAIProjectClientwith the given project endpoint.
When using the Azure AI Projects library with Entra ID authentication, we must authenticate via a service principal or app registration. To enable this, assign the Azure AI User role (built-in Azure RBAC role) on the Azure AI Foundry resource to your identity. This ensures your service principal has permission to access AI projects using Microsoft Entra ID.
Connection Discovery – It queries the list of configured project connections and identifies the Azure AI Search resource by inspecting connection metadata, extracting the corresponding
connection_id.Tool Initialization – An
AzureAISearchToolinstance is created using the connection ID and a predefined index name, enabling integration of search capabilities into the agent.Agent Creation – A new agent is provisioned with the GPT-4.1-mini model, custom instructions for Retrieval-Augmented Generation (RAG) queries, and the AI Search tool attached as a resource.
Thread Creation – A dedicated conversation thread is established to maintain the dialogue state with the agent.
Interactive Execution Loop –
User inputs are continuously read from the console.
Inputs are posted as messages to the agent.
The agent is executed (
create_and_process), responses are retrieved, and results are displayed.The loop terminates when the user enters
"end", after which the agent is deleted for cleanup.
import os
from azure.ai.projects import AIProjectClient
from azure.identity import ClientSecretCredential
from azure.ai.agents.models import AzureAISearchTool
# Entry point for the script
if __name__ == "__main__":
# Load Azure credentials from environment variables
credential = ClientSecretCredential(
tenant_id=os.getenv("TENANT_ID"),
client_id=os.getenv("CLIENT_ID"),
client_secret=os.getenv("CLIENT_SECRET")
)
# Create a client instance for interacting with the Azure AI Project
project_client = AIProjectClient(
credential=credential,
endpoint=os.environ["PROJECT_ENDPOINT"] # Project endpoint reference
)
# Retrieve available project connections to locate the AI Search resource
conn_list = project_client.connections.list()
conn_id = ""
# Identify the Azure AI Search connection by checking metadata fields
# Assumes only one AI Search connection is configured in the project
for conn in conn_list:
properties = conn.get("properties", {})
metadata = properties.get("metadata", {})
if metadata.get("type", "").upper() == "AZURE AI SEARCH":
conn_id = conn["id"]
break
print(conn_id)
# Reassign the valid connection ID for AI Search
conn_id = conn["id"]
# Configure the Azure AI Search tool with the discovered connection and index name
ai_search = AzureAISearchTool(index_connection_id=conn_id, index_name="rag-1754502262882")
# Provision an AI Agent and attach the AI Search tool for RAG-style queries
agent = project_client.agents.create_agent(
model="gpt-4.1-mini",
name="my-agent-aisearch",
instructions="You are a helpful agent to perform RAG Queries using AI Search",
tools=ai_search.definitions,
tool_resources=ai_search.resources,
)
print(f"Created agent, ID: {agent.id}")
# Initialize a new conversation thread for maintaining dialog state
thread = project_client.agents.threads.create()
print(f"Created thread, ID: {thread.id}")
# Continuous user interaction loop
while True:
user_input = input("User: ")
if user_input.lower() == "end":
project_client.agents.delete_agent(agent.id)
print("Ending the conversation.")
break
# Post user input as a message to the agent
message = project_client.agents.messages.create(
thread_id=thread.id,
role="user",
content=user_input,
)
# Run the agent and process the response
run = project_client.agents.runs.create_and_process(thread_id=thread.id, agent_id=agent.id)
print(f"Run finished with status: {run.status}")
if run.status == "failed":
print(f"Run failed: {run.last_error}")
break
# Fetch and print the agent’s most recent reply
messages = project_client.agents.messages.list(thread_id=thread.id)
for agent_response in messages:
if agent_response.text_messages:
last_text = agent_response.text_messages[-1]
print(f"{agent_response.role}: {last_text.text.value}")
# Final cleanup of the agent instance
project_client.agents.delete_agent(agent.id)
print("Conversation ended")
Showcase - [ 02 ] with Visual Studio code in locally

Showcase - [ 03 ] using Streamlit Frontend
Streamlit is an open-source Python framework that makes it easy to build interactive web apps for data and machine learning projects.
📤I deployed my project on Streamlit Community Cloud and adapted the code to work seamlessly with the Streamlit frontend. This enables me to access the app from anywhere through a customized, user-friendly interface.
By the way, what key information are you looking to extract from that Microsoft whitepaper? 📄🤔
I’ve made it public 🌍, so feel free to give it a try 🚀.
[ Sample Q’s you can try out for:
What specific governance controls do we need to implement for each type of agent creator (End Users, Makers, and Developers) in our organization?
How can we effectively use Microsoft Purview's Data Loss Prevention policies to prevent our agents from accessing highly confidential SharePoint content?
What's the best approach for setting up Power Platform environments and pipelines to ensure secure agent development and deployment across our teams? etc ]
Link : https://ragaifoundry.streamlit.app/

Key Takeaways
Building enterprise RAG solutions with Azure AI Foundry reveals several crucial insights: prioritize data quality over complexity, leverage hybrid search for optimal results, and choose between low-code UI approaches for rapid prototyping or code-first methods for customization. Most importantly, start small and scale gradually while continuously monitoring performance.
Conclusion
Azure AI Foundry transforms enterprise RAG implementation from complex to accessible. Whether you prefer UI-based configuration, programmatic development, or web deployment, the platform provides enterprise-grade security and scalability without sacrificing ease of use.
The three approaches demonstrated Agent playground, Azure AI Foundry SDK, and Streamlit web app showcase the platform's flexibility for different team needs and technical requirements. As organizations increasingly need AI solutions that integrate seamlessly with existing Microsoft infrastructure, Azure AI Foundry offers both immediate value and long-term strategic advantages.
References
Thanks for reading! If you found this guide helpful, consider sharing it with others who might benefit from implementing RAG solutions in their organizations with Microsoft AI Foundry.
Subscribe to my newsletter
Read articles from Nalaka Wanniarachchi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Nalaka Wanniarachchi
Nalaka Wanniarachchi
Nalaka Wanniarachchi is an accomplished data analytics and data engineering professional with over 20 years of working experience. As a CIMA(ACMA/CGMA) UK qualified ex-banker with strong analytical skills, he transitioned into building robust data solutions. Nalaka specializes in Microsoft Fabric and Power BI, delivering advanced analytics and engineering solutions. He holds a Microsoft certification as a Fabric Analytic Engineer and Power BI Professional, combining technical expertise with a deep understanding of financial and business analytics.