What Is Incremental Computation and Why It Matters
 Community Contribution
Community ContributionTable of contents
- Key Takeaways
- Incremental Computation Basics
- How Incremental Computing Works
- Core Mechanisms
- Benefits and Importance
- Applications of Incremental Computation
- Challenges
- Getting Started
- FAQ
- What is the main advantage of incremental computation?
- Can incremental computation work with any programming language?
- How does incremental computation improve user experience?
- Is incremental computation suitable for real-time applications?
- What are some common challenges when using incremental computation?
- Does incremental computation help reduce cloud costs?
- How does incremental computation handle errors or data quality issues?
- Where can someone learn more about incremental computation?

Incremental computation updates only the parts of a system that change instead of recalculating everything from scratch. Imagine editing a large document: rather than rewriting the entire file after each typo, a person corrects only the affected words. This approach mirrors how incremental computation works. Recent research shows that it improves efficiency by continuously adapting to new data and discarding used samples, which minimizes computational overhead. Systems using incremental computation achieve near real-time responsiveness and optimal resource utilization, making them far more adaptive than traditional methods.
Key Takeaways
Incremental computation updates only the parts of a system that change, saving time and resources compared to full recomputations.
This method improves system responsiveness, enabling near real-time updates in applications like software development, data processing, and stream analytics.
Key techniques such as dependency graphs and dirty marking help track changes efficiently and update only affected components.
Demand-driven incremental computing further optimizes performance by updating results only when they are needed.
Incremental computation reduces resource use, lowers costs, and supports scalability in large and complex systems.
Popular tools and frameworks like React, Apache Flink, and dbt support incremental computation for user interfaces and data pipelines.
While powerful, incremental computation can be complex to implement and may not suit all projects, especially those with poor data quality or lacking expert input.
Incremental Computation Basics
Definition
Incremental computation refers to a method in computer science where systems update only the affected parts of a computation when inputs change, rather than performing a full recompute. This approach allows programs to adapt quickly and efficiently as new data arrives or as users interact with software. In incremental computing, the system tracks changes and applies updates directly to the relevant outputs. This process resembles editing a document: instead of rewriting the entire text after each correction, a person simply fixes the specific words that need attention. Incremental computing relies on mathematical principles such as change structures and derivatives, which enable the system to update outputs based on input modifications. These foundations support modular and recursive program evaluation, making incremental computing robust and adaptable for a wide range of applications.
Note: The algebraic and domain-theoretic foundations of incremental computing, including concepts like directed-complete partial orders and Boolean algebras, provide a rigorous basis for handling complex program semantics and ensuring stable updates.
Key Concepts
Incremental computing builds on several key ideas that enable efficient updates and adaptability. The most cited concepts in academic literature include:
| Key Concept | Description | Supporting References and Notes |
| Incrementalization | The core of incremental computing; similar to discrete differentiation in calculus, it forms the basis for systematic program and algorithm optimization. | Highlights the Iterate-Incrementalize-Implement approach. |
| Dependency Analysis & Caching | Tracks dependencies and stores intermediate results, allowing the system to avoid unnecessary recompute steps. | Foundational work by Abadi et al. (1996) on dependency analysis and caching. |
| Self-Adjusting Computation | Enables programs to adapt automatically to input changes, supporting efficient incremental updates. | Overview by Umut A. Acar (2009) and related research. |
| Symbolic and Algebraic Manipulation | Uses symbolic methods and algebraic algorithms to support incremental computing in complex domains. | Included in index terms of key papers; supports algorithmic approaches. |
| High-Level Abstractions | Provides data, control, and module abstractions for designing efficient incremental algorithms and precise complexity analysis. | Emphasized in recent literature for new programming systems. |
| Programming Language Design | Incorporates language features and formal semantics that support composable and demand-driven incremental computing. | Discussed in "Incremental computation with names" (2015) and related work on Adapton. |
| Application Domains | Applies to database queries, software engineering, and algorithm design, demonstrating the broad relevance of incremental computing. | Highlighted across multiple documents. |
Incremental computing systems often use composable, demand-driven approaches. These systems focus on reusing previous computations and minimizing the need to recompute large outputs. Programming languages and frameworks that support incremental computing provide abstractions and semantics that make it easier to build efficient, adaptable software.
Comparison to Traditional Methods
Traditional computing methods typically recompute entire outputs whenever any input changes. This approach can waste significant time and resources, especially in large-scale systems or real-time applications. Incremental computing, in contrast, updates only the necessary parts, reducing the need to recompute everything from scratch.
Consider a scenario in software development where a developer modifies a small section of code. With traditional methods, the system might recompute the entire program, leading to long wait times. Incremental computing, however, identifies the affected components and updates only those, resulting in faster feedback and improved productivity.
Empirical studies highlight the dramatic performance differences between incremental computing and full recompute approaches. The following chart illustrates average and worst-case deletion times for various methods, showing how incremental computing outperforms exhaustive recompute strategies:
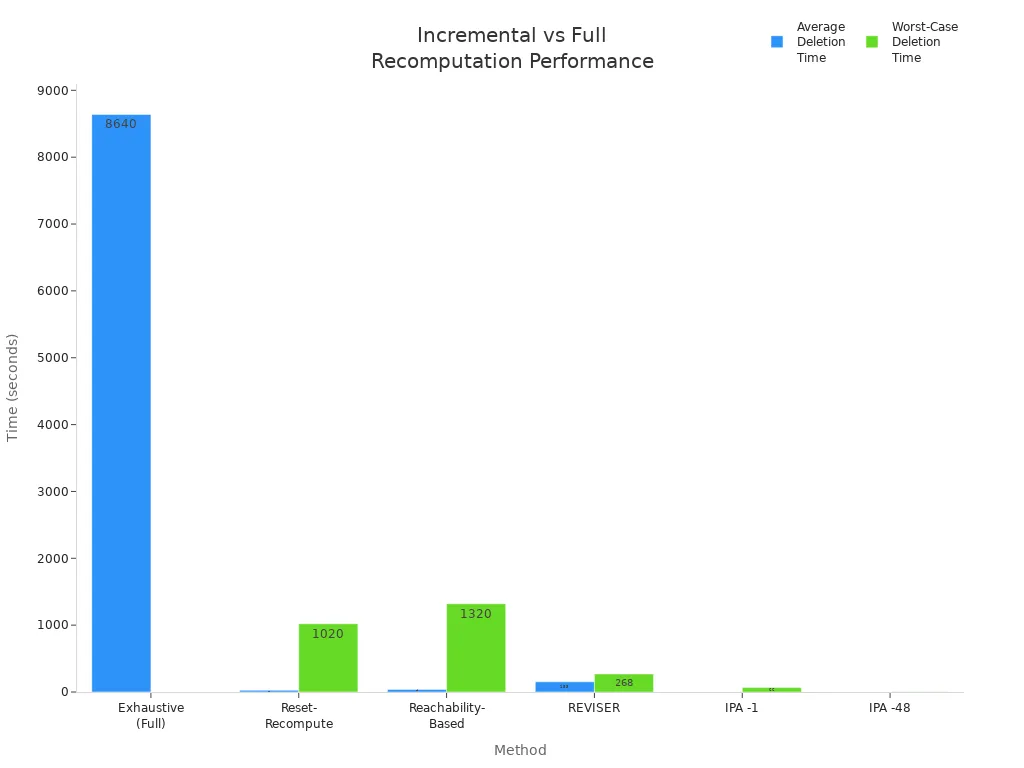
In large-scale benchmarks, full recompute methods often require hours to process changes, while incremental computing completes updates in milliseconds or seconds.
Even in worst-case scenarios, incremental computing maintains significant speed advantages, reducing deletion handling times from hours to seconds.
Incremental computing achieves speedups of 2 to 5 orders of magnitude over traditional recompute methods, and it scales effectively to millions of nodes and edges.
Incremental computing also excels in real-world applications. In healthcare, it enables real-time AI inference for instant medical image analysis and continuous patient monitoring. Autonomous vehicles rely on incremental computing for split-second obstacle detection and route optimization, where traditional recompute methods would introduce dangerous delays. Financial services use incremental computing for microsecond trading decisions and immediate fraud detection, while manufacturing benefits from instant equipment monitoring and predictive maintenance.
How Incremental Computing Works
Process Overview
Incremental computing operates through a structured sequence of steps that ensure only the necessary parts of a system update when inputs change. This approach avoids the inefficiency of a full recompute, which would otherwise process all data regardless of what actually changed. The process typically follows these steps:
Identify the Current State
The system determines its current state. This state can be a first run, a new model introduction, models being out of sync, or a standard run. Each state requires a different approach to incremental updates.Define Processing Boundaries
The system sets boundaries using timestamps, such aslower_limitandupper_limit, to select relevant events for processing. This step ensures that incremental computing focuses only on the affected data range.Detect New Events
The system identifies new events since the last run and determines which session identifiers are associated with these events. This targeted detection prevents unnecessary recompute cycles.Retrieve Session Data
The system retrieves all events for the identified sessions, sometimes including events outside strict time boundaries. This ensures complete and accurate session processing.Process the Subset of Events
Only the subset of events identified in the previous steps undergoes processing. This selective approach optimizes performance and supports rapid stabilization.Configure Processing Scope
Configuration variables, such assnowplow__backfill_limit_daysandsnowplow__lookback_window_hours, control the scope and duration of incremental processing. These settings help balance speed and accuracy.Monitor State and Progress
The system continuously monitors its state and progress by querying the incremental manifest and using helper models. This monitoring supports ongoing stabilization and ensures that the incremental computing process remains accurate without disrupting operations.
Tip: By following these steps, incremental computing systems maintain high efficiency and avoid the costly delays of a full recompute, especially in large-scale or real-time environments.
Change Detection
Change detection forms the backbone of incremental computing. The system must quickly and accurately identify which parts of the data or computation have changed since the last update. Advanced algorithms play a crucial role in this process. Researchers have developed methods for detecting changes in evolving data structures, such as graph streams, using concept drift detection and graph embedding techniques. These methods allow the system to adapt to dynamic data and maintain stabilization.
In practical applications, algorithms like incrementalRobustRandomCutForest and incrementalOneClassSVM process streaming data in real time. These models continuously adapt to changes in data distribution and detect anomalies by computing scores as new data arrives. This real-time adaptation ensures that incremental computing systems can respond to changes without requiring a full recompute. The stabilization process relies on these algorithms to maintain system accuracy and performance as data evolves.
Incremental computing leverages these change detection techniques to minimize unnecessary recompute operations. The system focuses only on the affected components, which leads to faster updates and more stable outputs. Stabilization becomes more reliable because the system can isolate and address changes as they occur, rather than waiting for a scheduled full recompute.
Output Updates
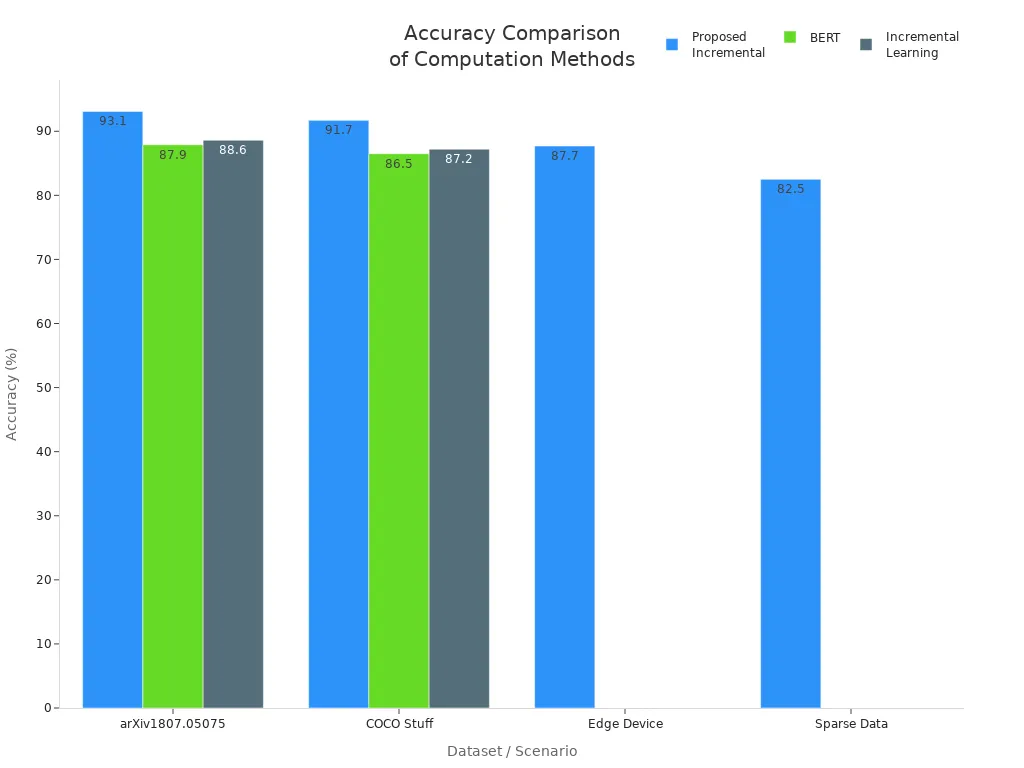
Output updates in incremental computing differ significantly from those in traditional computation. Instead of recalculating all outputs, the system updates only the affected results. This targeted approach reduces computation time and enhances stabilization. Benchmark studies highlight these differences:
| Dataset / Scenario | Method | Wall Clock Time | Accuracy (%) | Notes |
| arXiv1807.05075 (1.5 TB) | Proposed Incremental | 42 min | 93.1 | Faster and more accurate than BERT and incremental learning methods |
| BERT | 175 min | 87.9 | Longer time, lower accuracy | |
| Incremental Learning | 78 min | 88.6 | Intermediate performance | |
| COCO Stuff (1.5 TB) | Proposed Incremental | 48 min | 91.7 | Outperforms BERT and incremental learning in both speed and accuracy |
| BERT | 182 min | 86.5 | Slower and less accurate | |
| Incremental Learning | 82 min | 87.2 | Less efficient than proposed method | |
| Edge Device (Raspberry Pi 4B) | Proposed Incremental | 2.2 - 2.8 min | 87.1 - 88.3 | Shorter time and higher accuracy than BERT and incremental learning |
| Sparse Data (60% sparsity) | Proposed Incremental | 55 min | 82.5 | Better efficiency and accuracy compared to BERT and incremental learning |
The incremental computing method uses a first-order approximation to update model parameters. This approach modifies the network structure in a single step, which avoids the multiple iterations required by traditional methods. As a result, the system achieves faster computation times and improved stabilization. The incremental method also dynamically increases the number of hidden neurons to capture dynamic changes in data, which enhances convergence speed and accuracy. In contrast, traditional methods require repeated recompute cycles to update parameters, leading to longer computation times and less stable outputs.
Incremental computing systems demonstrate less fluctuation in computation time and more stable results across repeated runs. The stabilization achieved through incremental updates ensures that outputs remain accurate and reliable, even as data changes rapidly. This efficiency makes incremental computing the preferred choice for applications that demand real-time responsiveness and robust stabilization.
Core Mechanisms
Dependency Graphs
Dependency graphs form the backbone of incremental computing. By modelling computation as a graph, developers can break down complex tasks into smaller, manageable sub-tasks. Each node in the graph represents a computation, while edges capture the dependencies between them. This structure allows incremental computing systems to update only the affected nodes when inputs change, rather than recalculating everything. Modelling computation as a graph also enables parallel processing, as independent sub-tasks can run simultaneously. Research shows that the efficiency of incremental computing often depends on the size of the largest connected component in the dependency graph. For certain types of problems, such as those without cycles in their dependencies, algorithms can achieve polynomial time complexity. By exploiting the structure of dependencies, incremental computing systems can modularly and efficiently update results, even in large-scale applications.
Dependency graphs help identify loops and bottlenecks in dependencies, allowing systems to optimize updates and avoid unnecessary work.
Dirty Marking
Dirty marking is a technique that further enhances the efficiency of incremental computing. When a change occurs, the system marks affected nodes or fields as "dirty," indicating that their values may be outdated. This marking propagates through the dependencies, ensuring that only the necessary parts of the computation receive updates. The process works as follows:
The system marks changed fields as dirty.
Dirty bits travel through dependent fields, focusing updates only where needed.
Advanced algorithms, such as Double Dirty Bit, add summary bits to nodes, allowing entire subtrees without dirty nodes to be skipped.
Newer methods, like Spineless Traversal, access only dirty nodes, minimizing unnecessary checks and improving performance.
Dirty marking allows incremental computing systems to concentrate resources on changed or affected areas. This approach reduces cache misses and avoids redundant computation, which is especially important in latency-sensitive environments like web browsers. By managing dependencies efficiently, dirty marking ensures that incremental computing delivers fast and reliable updates.
Demand-Driven Incremental Computing
Demand-driven incremental computing takes optimization a step further by updating results only when there is a demand for them. Instead of updating all outputs after every change, the system waits until a user or process requests a specific result. This approach reduces unnecessary computation and improves responsiveness. Demand-driven incremental computing, as seen in frameworks like HadInc, enables efficient reuse of previously computed results. The system quickly identifies and merges only the changes, or deltas, instead of recomputing entire datasets. By using techniques such as content-defined chunking, demand-driven incremental computing maintains stable performance even when data splits change significantly. This method saves time and computational resources, which is critical for processing large, incrementally growing datasets. Case studies show that demand-driven incremental computing avoids costly full recomputation, often saving over 85% of computation time in big data scenarios. By focusing on demand and dependencies, this approach ensures that incremental computing remains efficient and scalable.
Demand-driven incremental computing excels in environments where users or systems frequently request updates, such as analytics dashboards or real-time monitoring tools.
Benefits and Importance
Efficiency
Incremental computation delivers significant efficiency gains by updating only the necessary parts of a system. This approach eliminates the need to recompute entire outputs when only a small portion of the input changes. In machine learning, active learning algorithms demonstrate this advantage. These algorithms can reduce the amount of training data required by 30% to 90% while maintaining the same model performance as random sampling methods. For instance, the QBC algorithm achieves similar prediction accuracy using just 30 to 35% of the data needed by other methods. In some cases, it identifies as little as 10% of the band gap data for training without any loss in performance. This translates into a three- to tenfold boost in sampling efficiency. By focusing on relevant changes, incremental computation minimizes wasted effort and accelerates workflows.
Performance
System performance improves dramatically when incremental computation replaces traditional full recompute strategies. Real-world benchmarks, such as VDBBench 1.0, simulate continuous data ingestion and concurrent queries to reflect production workloads.
VDBBench shows that Pinecone maintains higher query per second (QPS) and recall during active ingestion compared to Elasticsearch, which only surpasses Pinecone after a lengthy index optimization step.
Elasticsearch exhibits erratic performance during ingestion, while Pinecone delivers stable results without the need for costly recompute cycles.
Filter complexity and selectivity also affect incremental computation. High selectivity filters, which exclude more than 99% of data, can cause query speed fluctuations and recall instability. Milvus, however, maintains stable recall even as filter selectivity changes, while OpenSearch suffers from unstable recall and performance drops under these conditions.
VDBBench’s incremental load testing captures system stability, accuracy, and performance evolution over time, providing insights that static benchmarks often miss.
These findings highlight how incremental computation supports stable, predictable performance, especially in environments with frequent data updates. Systems avoid the delays and instability that often result from full recompute operations.
Resource Savings
Resource savings represent another major benefit of incremental computation.
Incremental computation avoids recomputing entire dataflows by updating outputs only when input changes are significant, leading to savings in CPU, network, and I/O bandwidth.
In sensor data monitoring, dataflow execution is delayed until enough input changes accumulate, reducing unnecessary processing.
This method trades a manageable error margin for substantial resource savings, while still providing useful outputs for decision making.
The Fluχy framework uses dynamic Quality of Data constraints and Fuzzy Boolean Nets to learn input-output error correlations, enabling fewer dataflow executions while keeping results within acceptable error bounds.
Experiments with Fluχy show optimized resource utilization and probabilistic guarantees on maximum error and output convergence.
When multiple dataflows share infrastructure, such as in cloud environments, these savings become even more impactful, freeing resources for other jobs or reducing operational costs.
By reducing the need to recompute large datasets, organizations can allocate resources more effectively and maintain high system availability.
Applications of Incremental Computation
Software Development
Incremental computation has transformed modern software development by enabling faster feedback and more efficient workflows. Developers now rely on incremental compilation in languages such as Rust and Java. These compilers track code changes and recompile only the affected sections, which significantly reduces build times. Integrated development environments (IDEs) like Visual Studio Code and runtimes such as Deno use incremental formatting and linting. This approach updates only the changed lines, so developers see immediate feedback without waiting for a full refresh after every keystroke.
Frameworks like React have adopted incremental DOM updating. When a user interacts with an application, React updates only the necessary parts of the user interface. This method improves performance and provides a smoother user experience. Databases also benefit from incremental computation through techniques like Incremental View Maintenance and materialized views. These features allow databases to update only the changed data, supporting data-centric and write-centric architectures.
Key Applications in Software Development:
Incremental DOM updating in React
Incremental formatting and linting in IDEs like VS Code and Deno
Incremental View Maintenance in modern databases
Data Processing
Data processing pipelines handle massive volumes of information. Incremental computation helps organizations process only new or changed data, which reduces costs and accelerates insights. Companies can run more frequent queries on smaller, precomputed datasets, lowering the time needed to gain valuable information. This capability supports near real-time updates, which is essential for analytics-driven decision-making.
Many industry tools support incremental data processing, including Snowflake materialized views, Databricks Delta Live Tables, DBT incremental jobs, Apache Spark, Apache Flink, and streaming databases like Materialize. These platforms enable organizations to scale efficiently and maintain data freshness.
| Aspect | Explanation | Impact |
| Reduced Latency & Data Freshness | Processes only changed data, leading to faster updates and fresher data. | Up to 90% latency reduction compared to batch processing. |
| Increased Scalability & Cost Reduction | Less data processed and stored, enabling easier scaling and lower storage costs. | Cloud storage costs decrease, supporting public cloud growth. |
| Improved Data Quality | Avoids data duplication by loading only changed data, reducing errors. | Fewer data quality issues and reduced duplication. |
| Pipeline Optimization Strategies | Includes data partitioning, parallel processing, and minimizing serialization to enhance performance. | Distributed computing frameworks like Spark and Hadoop recommended. |
User Interfaces
User interfaces demand responsiveness and smooth interactions. Incremental computation enables applications to update only the visible or changed elements, which keeps interfaces fast and efficient. Modern web frameworks, such as React and Angular, use incremental updates to refresh only the necessary components when users interact with the page. This approach reduces flicker and lag, creating a seamless experience.
IDEs and code editors also leverage incremental computation. As developers type, the editor highlights errors, formats code, and provides suggestions in real time. These features rely on updating only the affected lines or tokens, which maintains high performance even in large projects.
Incremental computation ensures that user interfaces remain responsive, even as applications grow in complexity. This technology supports real-time collaboration, live previews, and instant feedback, all of which are essential for modern digital experiences.
Stream Processing
Stream processing handles continuous flows of data in real time. Incremental computation plays a crucial role in this domain by enabling systems to process only new or changed data as it arrives. This approach supports applications that require immediate insights, such as fraud detection, sensor monitoring, and social media analytics.
Modern stream processing frameworks, including Apache Flink, Apache Kafka Streams, and Materialize, rely on incremental computation to deliver low-latency results. These systems break incoming data into small chunks or events. Each event triggers updates only for the affected computations, which minimizes resource usage and reduces processing time.
Note: Incremental computation allows organizations to analyze massive data streams without overwhelming their infrastructure. This efficiency makes real-time analytics feasible for businesses of all sizes.
Key benefits of incremental computation in stream processing include:
Reduced Latency: Systems update results almost instantly as new data arrives. This speed supports use cases like live dashboards and automated alerts.
Scalability: Incremental updates allow systems to handle millions of events per second. Companies can scale their analytics without a linear increase in hardware costs.
Fault Tolerance: Many frameworks use checkpointing and state snapshots. Incremental computation ensures that, after a failure, only the most recent changes need reprocessing.
Resource Efficiency: By updating only what changes, systems save CPU, memory, and network bandwidth. This efficiency lowers operational costs and energy consumption.
A typical stream processing workflow using incremental computation might look like this:
The system ingests a continuous stream of events, such as sensor readings or user actions.
Each event updates only the relevant parts of the computation graph.
The system emits updated results to dashboards, alerts, or downstream applications.
Checkpoints capture the current state, enabling fast recovery if needed.
| Framework | Incremental Feature | Example Use Case |
| Apache Flink | Stateful stream operators | Real-time fraud detection |
| Kafka Streams | Incremental aggregations | Social media trend analysis |
| Materialize | Incremental SQL views | Live business intelligence |
Incremental computation transforms how organizations process streaming data. Teams can react to trends, anomalies, or threats as they happen. This capability supports industries ranging from finance and e-commerce to healthcare and IoT.
Stream processing powered by incremental computation delivers the speed and efficiency that modern data-driven applications demand.
Challenges
Limitations
Incremental computation offers many advantages, but it does not fit every scenario. Some processes require frequent revisiting of earlier steps due to data quality issues. In these cases, incremental updates may not provide the expected benefits. The need for domain expert involvement also limits the effectiveness of incremental computation. Without expert input, systems may struggle to handle inconsistencies or add the tacit knowledge necessary for accurate results. Certain learning scenarios, such as class-incremental learning, present additional challenges. Parameter regularization methods often fail because they cannot compare classes that have not been observed together. Functional regularization with stored data can help, but it still falls short of optimal performance. Task-incremental and domain-incremental learning require careful handling and remain less explored, which introduces uncertainty about their suitability for incremental approaches.
Complexity
Implementing incremental computation introduces a higher level of complexity compared to traditional methods. The following table highlights key differences between the two approaches:
| Aspect | Traditional Implementation Science | Complexity Science (Incremental Computation) |
| Task | Focuses on specific, standardized tasks to translate evidence into practice | Context-dependent tasks requiring tailored, adaptive interventions |
| Theoretical Assumptions | Relies on diverse, often linear and reductionist theories | Based on universal principles of unpredictability, emergence, and interconnection |
| Intervention Approach | Standardized to allow generalizability | Adapted to meet dynamic and complex contextual needs |
| Context Consideration | Views context as confounders to control or solve | Treats context as an intrinsic, dynamic part of the system requiring ongoing adaptation |
| Methods and Tools | Uses traditional evaluation methods like randomized controlled trials | Employs iterative, participatory, and system-mapping methods to manage complexity |
Incremental computation requires ongoing adaptation and the ability to anticipate multiple outcomes. Developers must manage dynamic contexts and tailor interventions to specific needs. This complexity can slow down initial development and demand specialized skills. Teams must also monitor stabilization closely, as unpredictable changes in data or context can disrupt the incremental update process.
When Not to Use
Incremental computation does not suit every project. Experts have identified several scenarios where it may not deliver the desired results:
Projects lacking domain expert involvement often fail to benefit from incremental process discovery.
Data quality problems force teams to repeat previous steps, reducing the value of incremental updates.
Processes that cannot be fully automated or require sequential, iterative corrections do not align well with incremental methods.
Class-incremental learning scenarios, where parameter regularization cannot compare unseen classes, make incremental computation ineffective.
Functional regularization with anchor points improves results but still does not match optimal performance.
Task-incremental learning needs careful management to achieve positive transfer; otherwise, incremental computation may not help.
Domain-incremental learning remains underexplored, so its challenges and suitability are not well understood.
Teams should evaluate their context and requirements before choosing incremental computation. In some cases, traditional methods may offer greater simplicity and reliability, especially when stabilization or expert input cannot be guaranteed.
Getting Started
Tools
Developers can choose from a variety of tools to implement incremental computation. Many programming languages offer built-in support or external libraries for this purpose. For those working in C++, a c++ library for incremental computing provides efficient data structure updates and dependency tracking. These libraries often include features such as change detection, dirty marking, and dependency graphs. Python users may explore frameworks like Dask or Apache Beam, which support incremental data processing in distributed environments. JavaScript developers benefit from libraries such as Svelte and React, which use incremental updates to optimize user interfaces. Data engineers often rely on platforms like dbt, Apache Flink, and Materialize for incremental data pipelines. Each tool offers unique strengths, so teams should evaluate their project requirements before selecting a solution.
| Tool/Library | Language | Key Feature |
| c++ library for incremental computing | C++ | Efficient dependency management |
| Dask, Apache Beam | Python | Distributed incremental processing |
| dbt, Materialize | SQL/General | Incremental data models |
| React, Svelte | JavaScript | Incremental UI updates |
Learning Resources
A strong foundation in incremental computation begins with quality learning materials. Many open-source projects provide documentation and tutorials that guide users through setup and best practices. Online courses on platforms like Coursera and Udemy introduce the core concepts and practical applications. Technical blogs and community forums offer real-world examples and troubleshooting advice. For those interested in C++, documentation for a c++ library for incremental computing often includes sample code and integration guides. Academic papers, such as those by Umut A. Acar, explain the theoretical underpinnings and advanced techniques. Reading these resources helps developers understand both the principles and the practical challenges of incremental computation.
Tip: Start with official documentation and hands-on tutorials before exploring advanced academic literature.
Implementation Tips
Successful incremental computation projects follow several best practices:
1. Process only new or updated rows to maximize efficiency and avoid full dataset reloads. 2. Use a reliable timestamp column, such as updated_at, to identify changes since the last run. 3. Retrieve the most recent timestamp from the incremental table to filter new data. 4. Apply conditional filters in queries to select only rows with timestamps greater than the cutoff. 5. Configure the incremental model in your tool (for example, dbt) to enable incremental materialization. 6. Choose incremental strategies based on data volume, unique key reliability, and platform capabilities. 7. Monitor performance and tune the process to ensure data accuracy and cost efficiency.
Teams should also validate data accuracy, handle errors promptly, and monitor system performance. Incremental computation promotes data accuracy, boosts performance, and reduces costs by minimizing unnecessary processing. Adapting these strategies ensures that systems remain responsive and scalable in fast-paced environments.
Incremental computation delivers efficiency, scalability, and adaptability across dynamic environments. Organizations benefit from reduced computational overhead, improved responsiveness, and enhanced privacy through techniques like incremental unlearning. Real-world deployments, such as ARRC, demonstrate up to 7.7× better compute utilization and significant workload reductions.
Key advantages include:
Lower resource consumption
Support for privacy and regulatory compliance
Those interested in deeper learning can:
Explore advanced topics like incremental inference and grounding.
Review practical code examples and external blogs.
Study algorithmic trade-offs and optimization strategies.
Incremental computation stands as a vital tool for building efficient, responsive, and future-ready systems.
FAQ
What is the main advantage of incremental computation?
Incremental computation updates only the changed parts of a system. This method saves time and resources. It allows systems to respond quickly to new data or user actions.
Can incremental computation work with any programming language?
Most modern languages support incremental computation through libraries or frameworks. Developers can find tools for Python, JavaScript, C++, and SQL-based platforms.
How does incremental computation improve user experience?
Users see faster feedback and smoother interactions. Applications update only the necessary elements, which reduces lag and improves responsiveness.
Is incremental computation suitable for real-time applications?
Yes. Incremental computation excels in real-time environments. It processes new data instantly and keeps outputs up to date without full recomputation.
What are some common challenges when using incremental computation?
Developers face challenges such as increased system complexity and the need for careful dependency management. Not all tasks benefit from incremental updates.
Does incremental computation help reduce cloud costs?
Yes. By processing only changed data, incremental computation lowers CPU, memory, and storage usage. Organizations can scale efficiently and save on operational expenses.
How does incremental computation handle errors or data quality issues?
Systems must monitor data quality closely. If errors occur, incremental updates may not fix all issues. Sometimes, a full recompute becomes necessary to restore accuracy.
Where can someone learn more about incremental computation?
Many open-source projects, online courses, and technical blogs offer tutorials and guides. Academic papers by experts like Umut A. Acar provide deeper insights into theory and practice.
Subscribe to my newsletter
Read articles from Community Contribution directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by