A Developer’s Journey to the Cloud 6: My Path to Kubernetes and IaC
 Arun SD
Arun SDFrom Herding Servers to Building Worlds with Code
I had done it. I had achieved high availability. My application was running on a fleet of two identical servers, managed by a smart load balancer. If one server went down, the other would seamlessly take over. My application was resilient. It was professional. I felt invincible.
That feeling lasted until it was time to deploy a new feature.
My beautiful, simple CI/CD pipeline was now obsolete. It was designed to update one server. How was I supposed to update a whole fleet? My first attempt was a clumsy bash script a for loop that would SSH into each server, one by one, pull the latest code, and restart the container.
The first time I ran it, my heart was in my throat. I watched the logs scroll by, praying that server #1 would come back online before server #2 went down. It was a "rolling update" in the most literal, terrifying sense of the word. My fleet wasn't a clean, unified entity; it was a messy collection of individuals that I had to wrangle personally. I wasn't a developer anymore; I was the stressed-out admiral of a small, complicated armada, and I was spending all my time just keeping the ships sailing in the same direction.
Chapter 1: The Fleet Commander
My life was no longer about building features. It was about managing the fleet. My evenings were spent writing and debugging deployment scripts. My anxieties shifted. "What if the deployment script fails halfway through?" "How do I roll back an update across all servers at once?" "What happens when I need to scale from two servers to five? Or ten?" I was back to micromanaging machines, and it felt like a huge step backward.
This constant, low-grade fear of things getting out of sync led me down a late-night research rabbit hole of "container orchestration." My first stop was my cloud provider's own solution, Amazon ECS (Elastic Container Service). It seemed like the logical next step simple, deeply integrated, and less complex than the other options. It felt like the "easy" path.
But then I hesitated. A familiar feeling crept in the same feeling I had when I chose the "easy" path of running Redis in a Docker container. Was I about to tie my entire application's fate to a single cloud provider's proprietary system? What if I wanted to move to another cloud in the future? Or run a hybrid setup? All my knowledge of ECS would be useless. I would be locked in. I had learned my lesson: the easy path is often a trap.
This time, I decided to invest in the long term. I chose the other path, the one that was known for being more complex, but also more powerful and universal: Kubernetes.
Learning Kubernetes felt like learning a new language. The initial tutorials were a flood of new concepts: Pods, Services, Deployments, ReplicaSets. It wasn't a tool you could master in an afternoon. But as I pushed through, a fundamental, game-changing idea began to crystallize.
With my bash script, I was giving the servers a list of imperative commands: "Go here. Stop this. Pull that. Start this." I was the micromanager.
Kubernetes didn't want my instructions. It wanted my intent.
I stopped telling my servers what to do. Instead, I wrote a configuration file that declared the state I wanted, and Kubernetes worked tirelessly, like a powerful robot, to make that state a reality.
I no longer commanded; I declared.
Instead of a script that says "update server 1, then update server 2," I now wrote a Deployment manifest a simple YAML file that acted as the sheet music for my application's orchestra.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-awesome-app
spec:
replicas: 3 # <-- I declare I want 3 copies.
template:
spec:
containers:
- name: app-container
image: myusername/my-awesome-app:v1.1 # <-- I declare which version to run.
ports:
- containerPort: 3001
To perform an update, I just changed the image tag in this file and applied it. Kubernetes handled the zero-downtime rolling update. If a server died, Kubernetes would just reschedule its containers elsewhere. The individual machines had become an invisible, abstract resource. I had finally stopped being an admiral and could go back to being an architect.
Chapter 2: The Fragile Ground Beneath My Feet
I had done it. My application was now managed by a powerful, automated fleet commander. I felt unstoppable. I decided to create a staging environment a perfect replica of production for testing. So I went to my cloud provider's console to start building it all again.
And that's when a quiet, sinking feeling set in.
How did I create my production Kubernetes cluster in the first place? I had clicked through dozens of web UI forms. I had configured VPCs, subnets, security groups, and IAM roles manually. It had taken me a whole day. I had no record of what I did. I couldn't remember every setting. My entire production environment, the ground upon which my perfect Kubernetes setup stood, was a fragile, hand-made artifact. How could I ever hope to recreate it perfectly? What if I accidentally deleted something? The whole thing felt like a house of cards.
I had automated my application, but the infrastructure itself was still a manual, brittle mess. This led me to my next discovery: Infrastructure as Code (IaC). The idea is to do for your infrastructure what Docker did for your application environment: define it all in code. For this, I found a powerful duo: Terraform for provisioning the infrastructure, and Ansible for configuring it.
With Terraform, I could write files that described my entire cloud setup the "what."
# main.tf
# Define the Virtual Private Cloud (VPC)
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
}
# Define a managed Kubernetes cluster within our VPC
resource "aws_eks_cluster" "production" {
name = "my-awesome-app-cluster"
role_arn = aws_iam_role.eks_cluster_role.arn
vpc_config {
subnet_ids = [ ... ]
}
}
# Provision a separate EC2 instance to be our secure "bastion" host
resource "aws_instance" "bastion" {
ami = "ami-0c55b159cbfafe1f0" # An Amazon Linux 2 AMI
instance_type = "t2.micro"
subnet_id = # ...
}
Terraform was brilliant at creating the empty house, but how did I install the specific tools I needed on that bastion host? That's where Ansible came in. It handled the "how" the configuration of the software on the machines Terraform built. I wrote an Ansible "playbook" to define the desired state of my bastion server.
# playbook.yml
---
- hosts: bastion_hosts # This group is defined in an inventory file
become: yes
tasks:
- name: Ensure standard monitoring tools are installed
apt:
name:
- htop
- ncdu
state: latest
update_cache: yes
- name: Create a specific user for developers
user:
name: dev_user
state: present
shell: /bin/bash
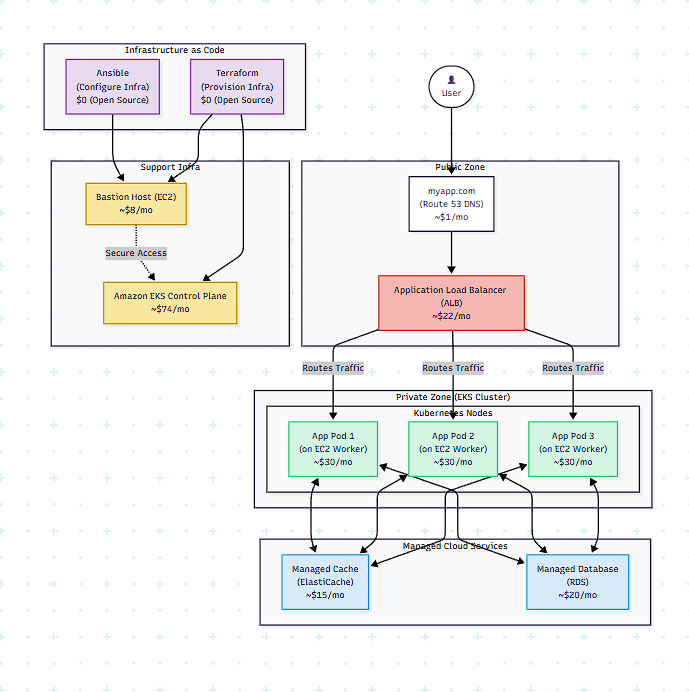
I spent a week converting my entire hand-clicked setup into these declarative files. When I was done, I could destroy and recreate my entire production network, Kubernetes cluster, and all its supporting services from scratch with a single command: terraform apply, followed by ansible-playbook playbook.yml.
My infrastructure was no longer a fragile artifact; it was now a set of version-controlled text files living in my Git repository. Creating an identical staging environment was now as simple as running the same commands with a different variable.
I had finally reached a new level of automation. Everything, from the virtual network cables up to the application replicas, was now code. The system felt truly robust. With a few keystrokes, I could scale my application containers, and with a few more, I could scale the very cluster they ran on. The system felt unstoppable. And as more users flocked to the app, I saw my cluster effortlessly adding more resources to meet the demand. But all this traffic, all these new users, were all being funneled to one place. The bottleneck had moved again. My application servers and infrastructure were an army, but they were all trying to get through a single door: my database.
next post: A Developer’s Journey to the Cloud 7: Advanced Database Scaling.
Subscribe to my newsletter
Read articles from Arun SD directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by