Understanding Retrieval Augmented Generation (RAG): A Complete Guide
 Sanjeev Saniel Kujur
Sanjeev Saniel KujurTable of contents
- What is Retrieval Augmented Generation?
- Why RAG is Essential: Solving Critical LLM Limitations
- The RAG Architecture: How It Works
- The Four Essential Stages of RAG
- Advanced Concepts in RAG Implementation
- Real-World Applications and Use Cases
- Benefits of Implementing RAG
- Challenges and Considerations
- The Future of RAG Technology
- Getting Started with RAG
- Conclusion

RAG (Retrieval Augmented Generation) represents a revolutionary approach in artificial intelligence that combines the power of large language models with dynamic information retrieval systems. This technique has emerged as a game-changing solution for addressing the limitations of traditional language models while providing more accurate, contextual, and up-to-date responses.
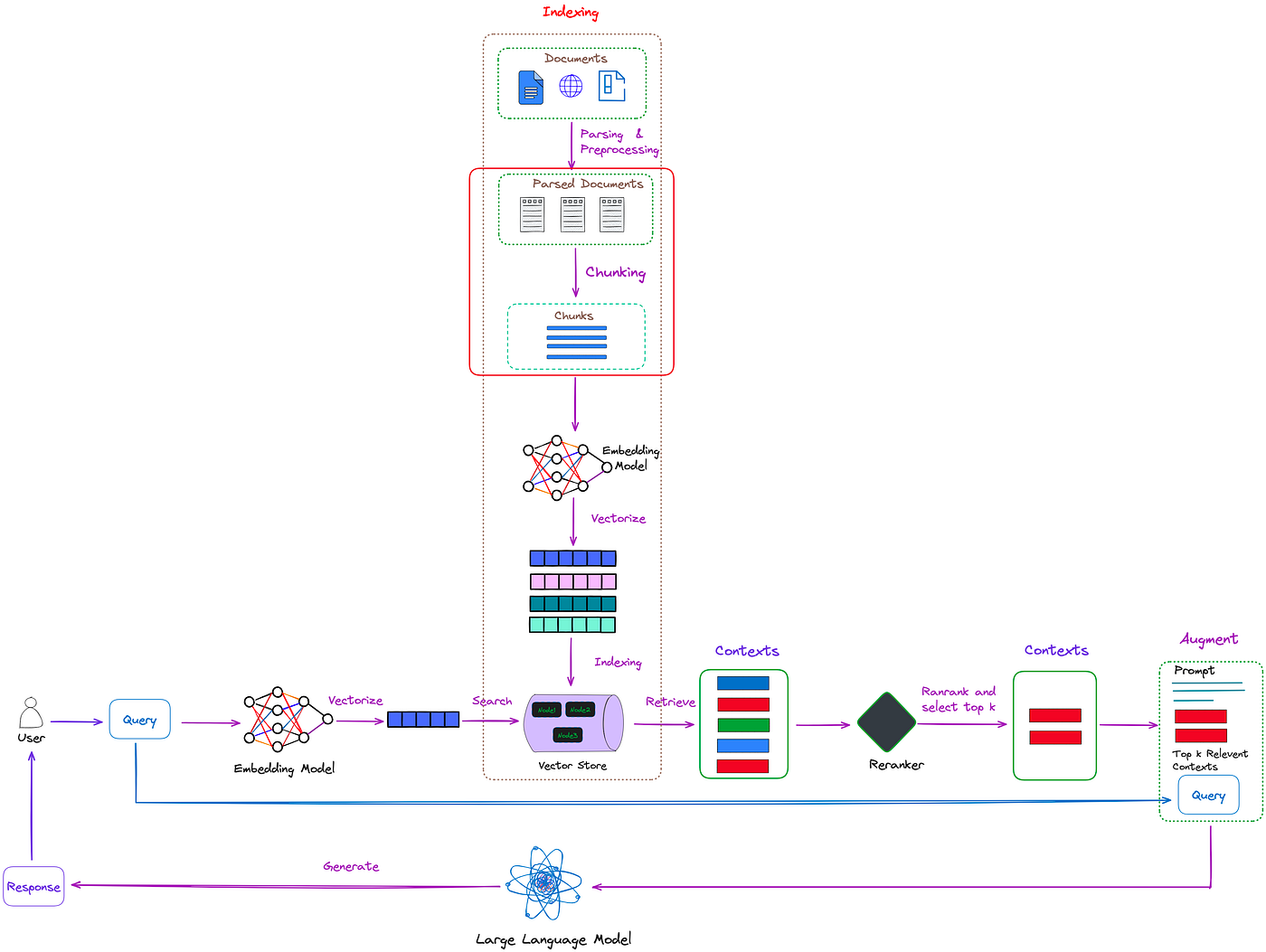
Flowchart showing the detailed RAG pipeline workflow including document parsing, chunking, vectorization, indexing, retrieval, reranking, and query augmentation with a large language model.
What is Retrieval Augmented Generation?
Retrieval Augmented Generation is an architectural approach that enhances large language models (LLMs) by integrating them with external knowledge sources. Instead of relying solely on static training data, RAG systems dynamically retrieve relevant information from databases, documents, or web sources to augment the generation process.
The term was first introduced in a 2020 research paper from Meta, establishing the foundation for what has become one of the most important techniques in modern AI applications. As AWS explains, "RAG is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response".
Why RAG is Essential: Solving Critical LLM Limitations
Traditional large language models face several fundamental challenges that RAG directly addresses:
The Static Knowledge Problem
LLMs are trained on datasets with specific cutoff dates, making them unable to access information beyond their training period. This creates a significant gap when users need current information or domain-specific knowledge that wasn't included in the original training data.
AI Hallucinations
One of the most critical issues with standalone LLMs is their tendency to generate false or misleading information when they don't know the answer. These "hallucinations" can have serious consequences in high-stakes applications like healthcare, legal services, or financial advising.
Lack of Domain Expertise
While LLMs excel at general knowledge tasks, they struggle with specialized domains that require access to specific databases, company policies, or technical documentation.
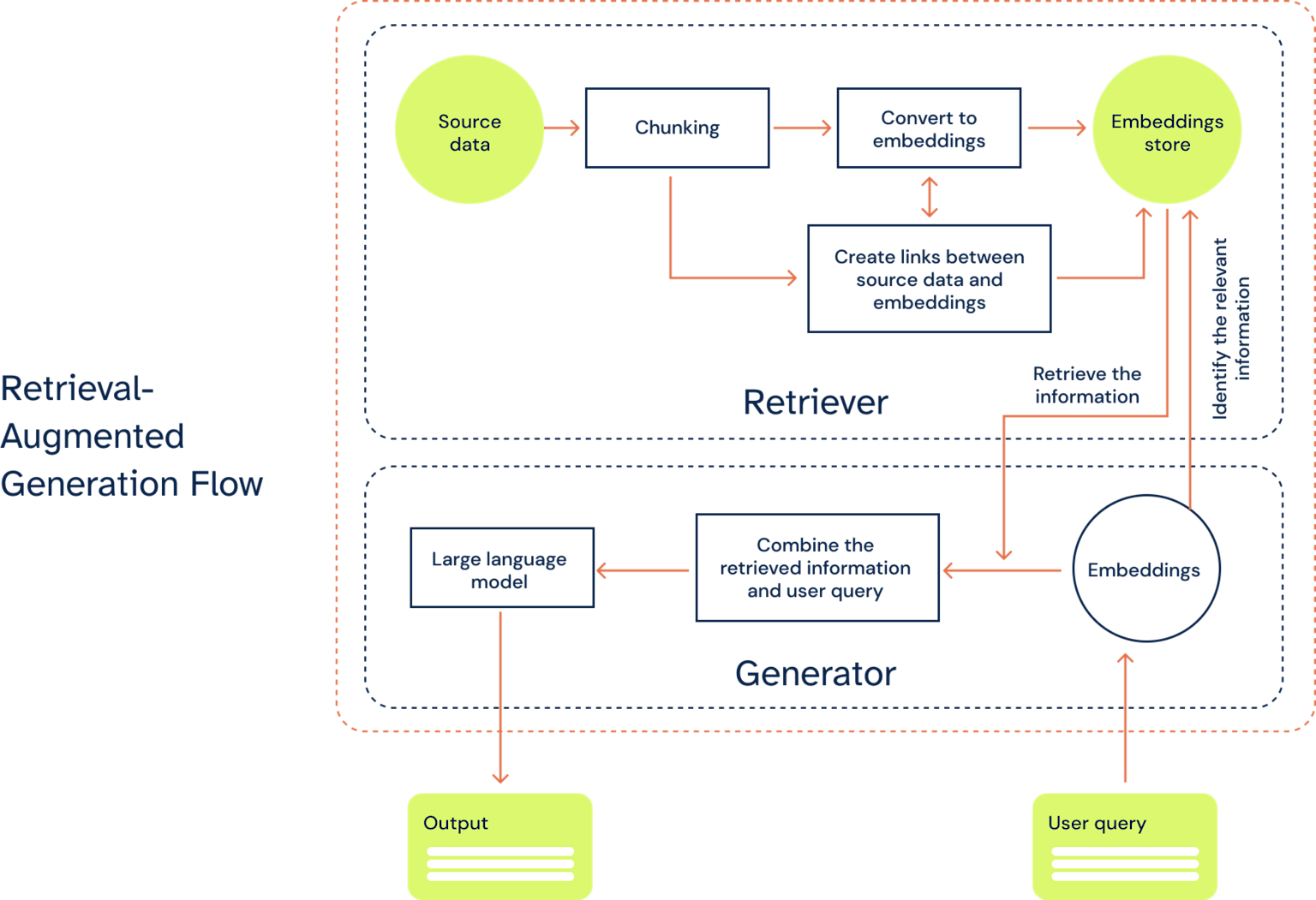
Flowchart illustrating the Retrieval-Augmented Generation (RAG) process, showing the step-by-step data flow from source data to final output via retriever and generator components.
The RAG Architecture: How It Works
RAG systems operate through a two-component architecture that seamlessly integrates retrieval and generation processes:
1. The Retriever Component
The retriever acts as the "research assistant" of the system. When a user submits a query, the retriever:
Encodes the query into a dense vector representation using embedding models like BERT or RoBERTa
Searches the knowledge base using similarity search algorithms to find the most relevant documents
Retrieves the top-K most relevant passages based on vector similarity scores
2. The Generator Component
The generator, typically based on transformer architectures like GPT or BART, takes the retrieved information and:
Combines the original query with the retrieved context through prompt engineering
Generates a response that synthesizes information from both the user's question and the retrieved documents
Produces contextually grounded answers that are more accurate and verifiable
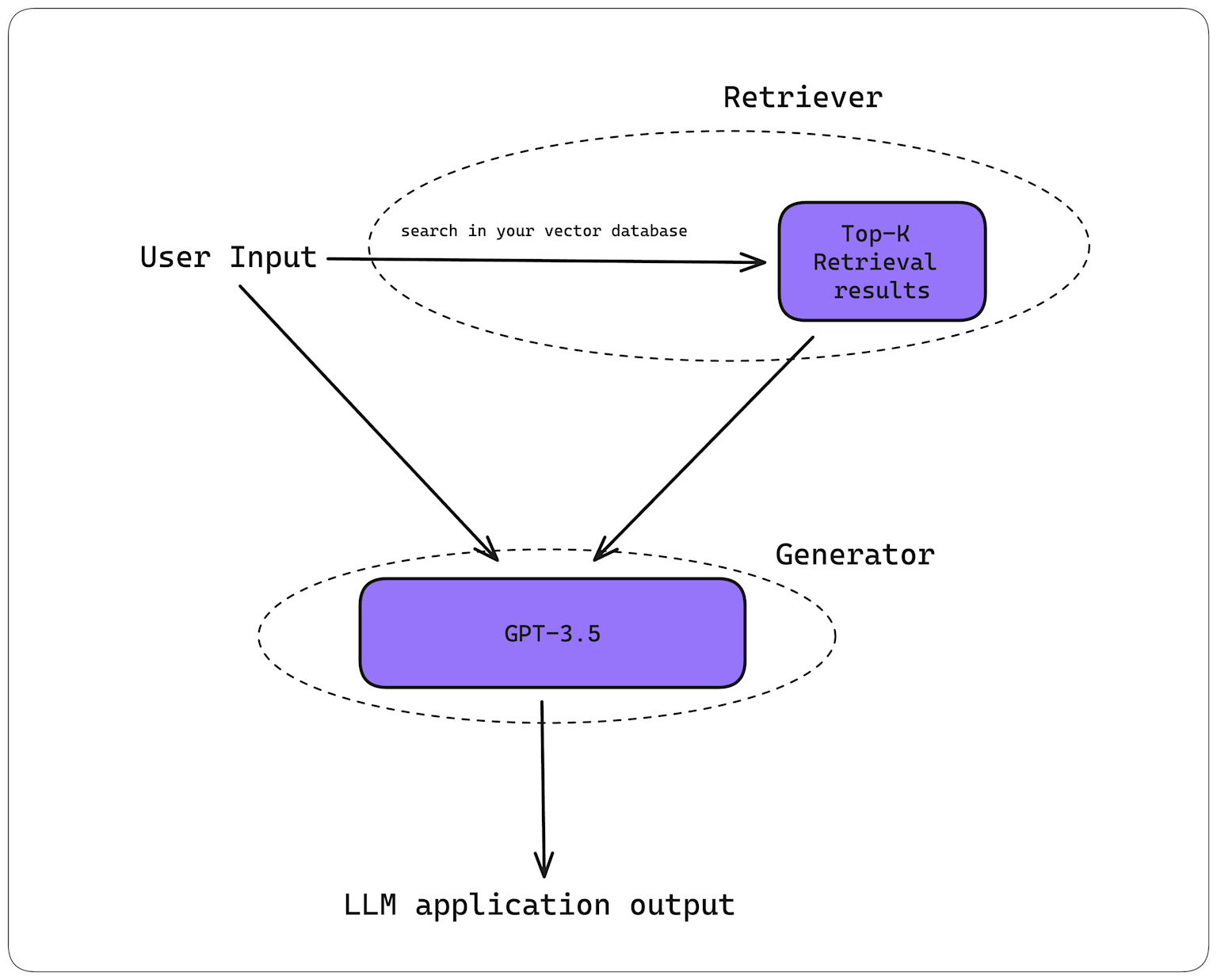
Diagram of Retrieval-Augmented Generation (RAG) showing user input processed by a retriever and GPT-3.5 generator to produce LLM output.
The Four Essential Stages of RAG
Stage 1: Indexing - Building the Knowledge Foundation
The indexing process is the backbone of any RAG system. This offline process involves:
Document Loading: Using document loaders to ingest data from various sources including PDFs, web pages, databases, and internal documents.
Text Chunking: Breaking large documents into smaller, manageable segments. This is crucial because:
LLMs have finite context windows that limit input size
Embedding models also have maximum token limits
Smaller chunks are more searchable and semantically focused
Vector Embedding: Converting text chunks into numerical representations using embedding models. These high-dimensional vectors capture the semantic meaning of the text, allowing for sophisticated similarity comparisons.
Storage: Storing embeddings in vector databases like ChromaDB, Pinecone, or FAISS for efficient retrieval.
Stage 2: Retrieval - Finding Relevant Information
When a user submits a query, the system:
Encodes the query into the same vector space as the stored documents
Performs similarity search using algorithms like cosine similarity or euclidean distance
Returns the most relevant chunks based on semantic similarity scores
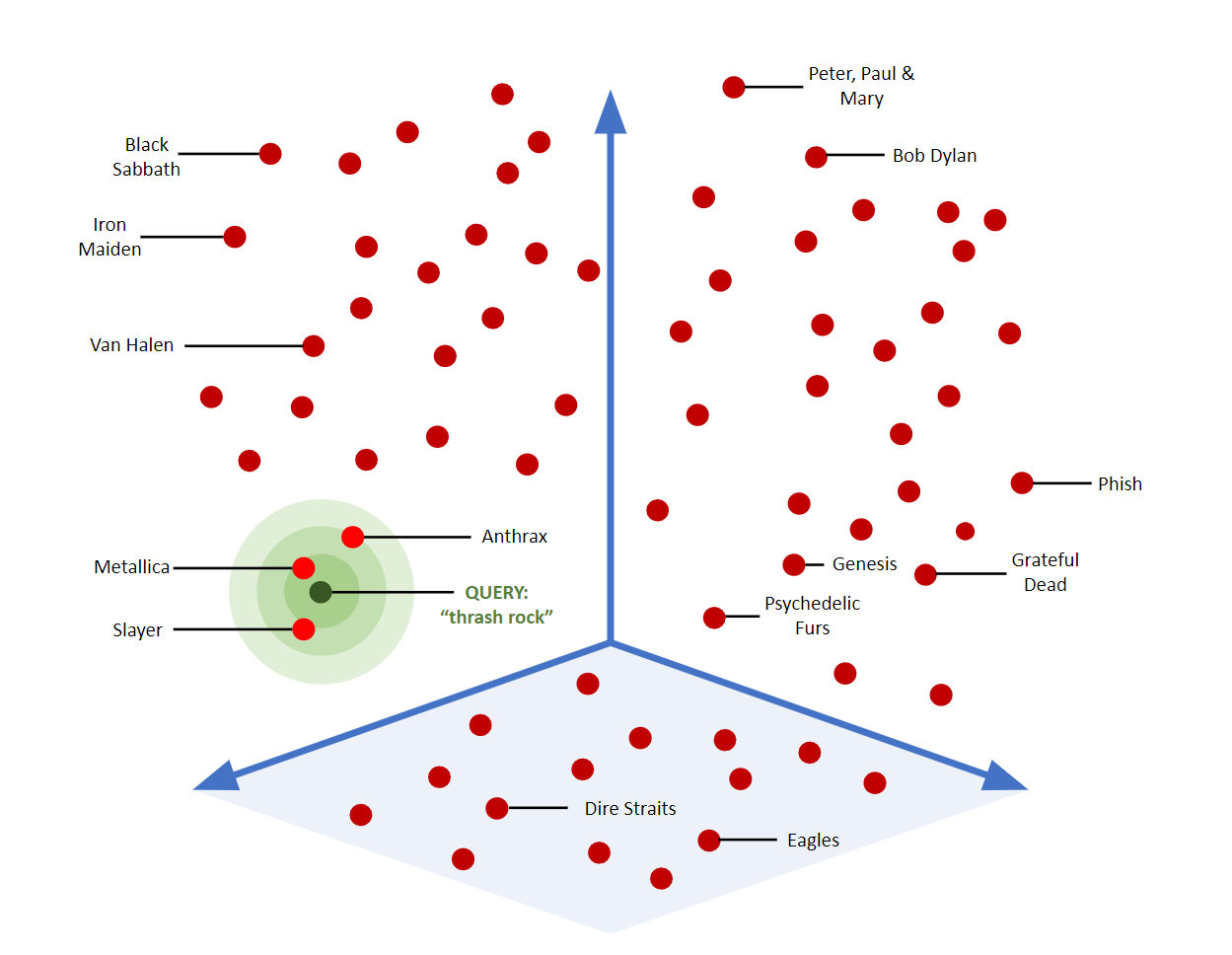
3D visualization of vector embeddings showing similarity search of music bands with a focus on thrash rock genre.
Stage 3: Augmentation - Contextualizing the Query
The retrieved information is integrated with the original query through advanced prompt engineering techniques. This creates a rich context that includes:
The user's original question
Relevant background information from retrieved documents
Specific instructions for the language model
Stage 4: Generation - Creating the Response
The augmented prompt is fed to the language model, which generates a response that:
Draws from both its training knowledge and the retrieved information
Maintains factual accuracy by grounding responses in actual documents
Provides verifiable answers that users can trace back to sources
Advanced Concepts in RAG Implementation
Understanding Vector Embeddings
Vector embeddings are dense numerical representations that capture the semantic meaning of text in high-dimensional space. Similar concepts cluster together, allowing the system to understand relationships between words and phrases beyond simple keyword matching.
Modern embedding models like OpenAI's text-embedding-ada-002, Cohere's embeddings, or open-source alternatives create vectors with hundreds or thousands of dimensions, each capturing different aspects of meaning.
The Art and Science of Chunking
Effective chunking is critical for RAG performance. Key considerations include:
Chunk Size: Typically ranging from 100-1000 tokens, depending on the use case and model context window.
Overlap Strategy: 10-20% overlap between chunks helps preserve context and prevents information loss at chunk boundaries. For example, if one chunk ends mid-sentence about a key concept, the overlap ensures the next chunk maintains that context.
Semantic Awareness: Advanced chunking strategies consider document structure, maintaining complete sentences, paragraphs, or sections rather than arbitrary character limits.
Why We Perform Vectorization
Vectorization transforms text into a format that computers can efficiently process and compare. This mathematical representation allows:
Semantic similarity calculations using distance metrics
Efficient storage and retrieval in specialized vector databases
Scalable search across millions of documents
Real-World Applications and Use Cases
Customer Support Excellence
Companies like Shopify with their Sidekick chatbot leverage RAG to provide precise, contextual customer support by accessing real-time inventory data, order histories, and FAQs. This eliminates generic responses and delivers personalized assistance.
Healthcare Innovation
A major hospital network integrated RAG into their clinical decision support system, achieving 30% reduction in misdiagnoses, 25% decrease in literature review time, and 40% increase in early detection of rare diseases.
Enterprise Knowledge Management
Siemens utilizes RAG to enhance internal knowledge management, allowing employees to quickly retrieve information from vast documentation databases with contextual summaries.
E-commerce Personalization
Amazon's recommendation systems use RAG techniques with knowledge graphs to provide contextually relevant product suggestions based on customer behavior and preferences.
Benefits of Implementing RAG
Accuracy and Reliability
RAG significantly reduces AI hallucinations by grounding responses in actual retrieved documents rather than relying solely on training data. This creates a verifiable foundation for AI-generated content.
Cost-Effectiveness
Unlike fine-tuning large language models, RAG provides a cost-effective approach to incorporating new information without retraining. Organizations can update their knowledge base without massive computational overhead.
Transparency and Trust
RAG systems can cite their sources, allowing users to verify information and understand the basis for generated responses. This transparency is crucial for enterprise applications where accountability matters.
Dynamic Knowledge Updates
When new information becomes available, RAG systems only need their knowledge base updated, not the entire model retrained. This ensures responses remain current and relevant.
Challenges and Considerations
Quality Control
The effectiveness of RAG systems heavily depends on the quality of the underlying knowledge base. Inaccurate, outdated, or biased source material will degrade system performance.
Retrieval Accuracy
Poor retrieval quality directly impacts generation quality. If the system retrieves irrelevant documents, even the best language model cannot generate accurate responses.
Chunking Optimization
Improper chunking strategies can break context, leading to meaningless text segments that confuse the retrieval process. Finding the optimal balance between chunk size, overlap, and semantic coherence requires careful tuning.
The Future of RAG Technology
RAG represents a fundamental shift in how we approach AI-powered applications. As embedding models improve and vector databases become more sophisticated, we can expect even more powerful and accurate RAG systems.
The technology is evolving toward multi-modal capabilities, incorporating images, audio, and structured data alongside text. Advanced techniques like query expansion, document reranking, and adaptive retrieval are making RAG systems more intelligent and context-aware.
Getting Started with RAG
For developers and organizations looking to implement RAG:
Choose appropriate embedding models based on your domain and performance requirements
Design effective chunking strategies that preserve semantic meaning
Select suitable vector databases for your scale and use case
Implement robust evaluation metrics to measure retrieval and generation quality
Plan for continuous knowledge base maintenance to ensure ongoing accuracy
Conclusion
Retrieval Augmented Generation has emerged as a transformative technology that bridges the gap between the vast capabilities of large language models and the need for accurate, up-to-date, domain-specific information. By combining the best of information retrieval with generative AI, RAG systems offer a practical solution for building reliable, transparent, and effective AI applications.
As organizations increasingly rely on AI for critical decision-making, RAG provides the foundation for trustworthy AI systems that can adapt to new information while maintaining accuracy and accountability. The future of AI applications lies not in isolated language models, but in intelligent systems that can dynamically access and synthesize information from the ever-expanding world of human knowledge.
Whether you're building customer support chatbots, internal knowledge management systems, or specialized domain applications, understanding and implementing RAG will be essential for creating AI solutions that truly serve user needs while maintaining the highest standards of accuracy and reliability.
Subscribe to my newsletter
Read articles from Sanjeev Saniel Kujur directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by