My RAG Pipeline Keeps Failing: Here’s How I’m Fixing It
 Shivprasad Roul
Shivprasad Roul
I’ve been going deep on Retrieval-Augmented Generation (RAG) lately. The basic idea is simple and powerful: give a Large Language Model (LLM) access to your own data via vector search. It’s the foundation for almost every modern AI application that needs to reason over private knowledge.
But when I started moving past simple prototypes and thinking about building a real-world system, I hit a massive wall. The classic "garbage in, garbage out" problem wasn't just a theoretical annoyance it was a critical failure point.
A simple RAG pipeline works great when the user's query is perfect. But what happens when the input has a spelling mistake, misses the right keywords, or is just plain ambiguous? The whole thing falls apart. The retriever, which relies on precise vector similarity, fetches irrelevant documents. Then, the LLM, fed with this garbage context, confidently hallucinates a useless answer.
I see this all the time in other products. On Google or YouTube, if you type something with a typo, they instantly suggest a correction.They don’t just fail; they guide you. So the question I asked myself was: what changes can I make in my RAG pipeline to overcome this exact problem?
The First Fix: Query Rewriting
My initial thought was to stop the bad query before it ever hits the vector database.This means adding a step right at the beginning that I'm calling "Query Translation" or "Query Rewriting".

The idea is to use a small, fast "micro" LLM whose only job is to clean up and enhance the user's input before retrieval. This model acts as an intelligent pre-processor.
This rewriting step can handle several common issues:
Spelling and Grammar: It fixes the simple mistakes that throw off vector search, like converting "wht r the benfits of advnced rag" into "What are the benefits of advanced RAG?".
Ambiguity and Vague Language: A user might ask, "Tell me about that new feature." A rewriter with access to conversation history could transform this into, "Explain the new 'Corrective RAG' feature announced in the latest update."
Keyword Expansion: A novice user might not know the right terminology. A query like "how to make my search better" could be enhanced to "What are techniques for improving information retrieval accuracy in a RAG system, such as query expansion or reranking?”.
Once the query is rewritten, we can create the vector embedding and perform the search. This leads to much better, more relevant chunks being retrieved from the database, giving our main LLM higher-quality material to work with.
The Obvious Trade-Off: Time, Latency, and Cost
This seems like a solid solution, but it introduces its own set of problems.The big trade-offs are time, latency, and cost.
Every time we call that query-rewriting LLM, we're adding another network hop and another model inference to our pipeline. This adds precious milliseconds to the response time and, depending on the model, can increase the cost per query.It left me wondering: is there any other solution for this?
A Smarter Pipeline: Adding a "Judge"
After more thought, I realized that rewriting the query is only half the battle. What if the rewritten query accidentally drifts away from the user's original intent?

This led me to a more advanced architecture that involves a second check after retrieval. Let's call it a "Judge" or a re-ranking module.The vector search will return many chunks, so we can keep a judge which will give a quality score based on the user's original query.
Here’s how it works:
The user submits their (potentially messy) query.
The query rewriter cleans it up and expands it.
Vector search retrieves the top N chunks (e.g., 10-20) based on the rewritten query.
Here’s the key step: The Judge module scores the relevance of those retrieved chunks against the original user query, not the rewritten one.
Why is this so important? The original query, with all its flaws, contains the user's raw, unfiltered intent. By re-ranking the results based on the original input, we ensure our "helpful" query rewriting didn't misunderstand the user and send the retriever down a rabbit hole. This gets us the best of both worlds: a broad search from the rewritten query and a precise relevance check from the original.
This "Judge" is often a cross-encoder. Unlike the bi-encoder used for retrieval (which creates separate embeddings for the query and documents), a cross-encoder takes both the query and a document as a single input and outputs a relevance score. They are much more accurate for ranking but too slow for initial retrieval, making them perfect for this re-ranking step on a small set of candidate chunks.
Going Deeper: Formalizing the Concepts
As I dug into this, I found formal research and names for these ideas. It turns out I was stumbling upon powerful, well-established techniques.
Corrective RAG (CRAG)
My "Judge" idea is a core component of a strategy called Corrective-Augmented Generation (CRAG) . CRAG formalizes this self-correction loop. It uses a lightweight retrieval evaluator to assess the relevance of any retrieved document, assigning a score of "correct," "incorrect," or "ambiguous."

If the documents are deemed correct, the pipeline proceeds as normal.
If they are incorrect, the system knows it has bad information and won't pass it to the LLM, preventing hallucination.
If they are ambiguous, CRAG triggers an action. It can use a web search engine to find more targeted information, which is then filtered and added to the context for the LLM.
This is a huge step up.Instead of just failing on a bad retrieval, the system can actively try to fix it.
Hypothetical Document Embeddings (HyDE)
Another powerful technique I found is HyDE, or Hypothetical Document Embeddings. This flips query rewriting on its head. Instead of rewriting the user's question, you use an LLM to generate a hypothetical answer—a document that could be the correct response.
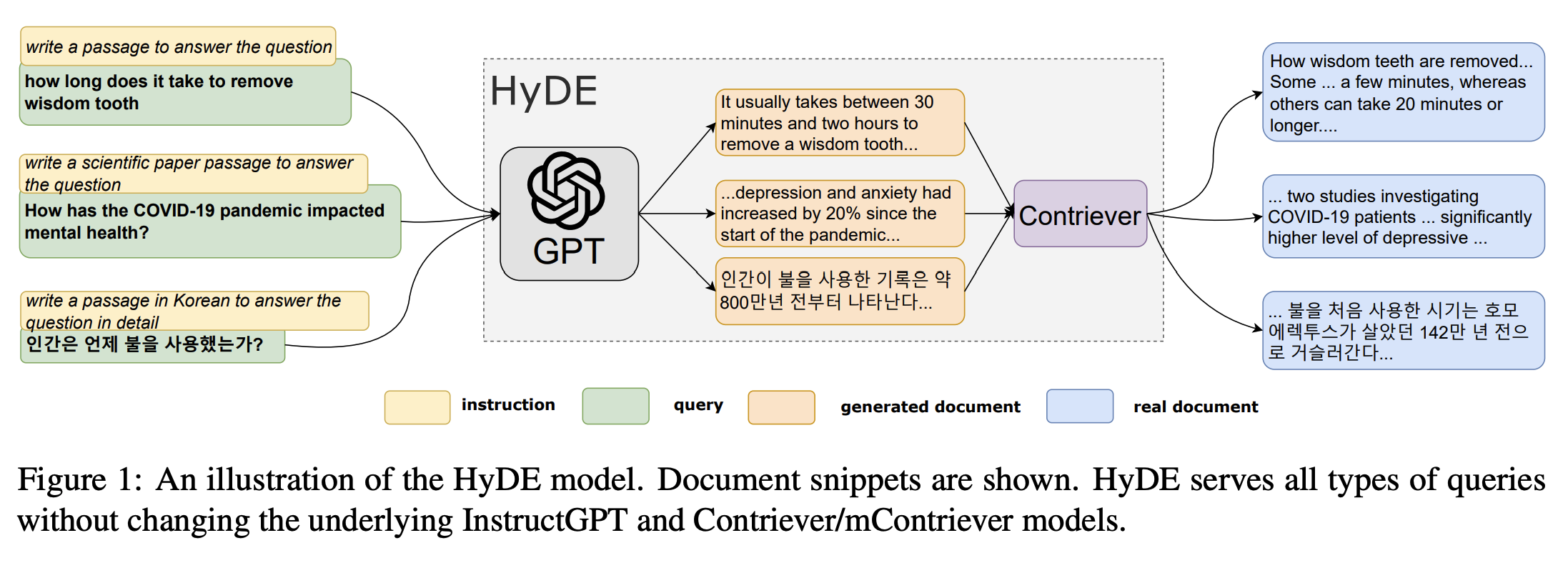
You then create a vector embedding of this fake, generated document and use that to search for similar, real documents in your database.
The intuition here is brilliant. Questions and answers are often semantically different. A question is short and direct, while an answer is dense with information. This "semantic gap" can make vector search difficult. By generating a hypothetical answer, HyDE creates an embedding that is already in the "answer space" of your vector database, making it much more likely to find the true, relevant documents.
My Proposed Advanced RAG Pipeline
So, here’s the production-grade RAG pattern I'm moving toward. It combines these ideas into a single, robust pipeline designed to handle the unpredictability of real users.

This flow starts with transforming the user query, uses that for an initial broad retrieval, then uses a more precise judge (with the original query's intent) to re-rank the results before finally passing the best possible context to the generator LLM.
Mini-FAQ
Q: Isn't adding a rewriter and a judge too slow for a real application? A: It definitely adds latency. The key is using very small, optimized models for these tasks. A distilled model for rewriting or a lightweight cross-encoder for judging can execute in milliseconds. You have to measure if the trade-off between higher accuracy and slightly higher latency is acceptable for your use case.
Q: How do I measure if these changes are actually improving my RAG system? A: You need a proper evaluation framework. For retrieval, you can use metrics like Hit Rate (did the right document appear in the top K results?) and Mean Reciprocal Rank (MRR). For the final generated answer, you can use metrics like RAGAs, which evaluate faithfulness (does the answer stick to the context?) and answer relevance.
Q: When should I stick with a simple RAG pipeline? A: If you're building an internal tool where users are experts and the domain vocabulary is fixed, a simple RAG might be all you need. This advanced pipeline is most valuable when you're facing the general public and can't control the quality or diversity of the input queries.
Conclusion and Next Steps
Moving from a prototype RAG to a production-ready one means confronting the messiness of human language. A simple vector search on a raw query is too brittle for the real world.
My key takeaway is that the retrieval process itself needs to be intelligent. It's an evolution:
Naive RAG: Directly embed and search the user query.
Pre-Processing RAG: Add a query transformation step (rewriting, HyDE) to improve the search.
Post-Processing RAG: Add a re-ranking or judging step to refine the retrieved results.
Self-Correcting RAG: Use a framework like CRAG to detect and actively fix bad retrievals.
By layering these techniques, we can build a system that is far more resilient, accurate, and genuinely helpful. It’s an investment in complexity, but it’s one that pays off in the quality and reliability of the final output.
I’m currently experimenting with different small models for the rewriting and judging steps. What techniques are you using to make your RAG systems more robust? I’d love to hear about them.
Subscribe to my newsletter
Read articles from Shivprasad Roul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shivprasad Roul
Shivprasad Roul
Software developer with a strong foundation in React, Node.js, PostgreSQL, and AI-driven applications. Experienced in remote sensing, satellite image analysis, and vector databases. Passionate about defense tech, space applications, and problem-solving. Currently building AI-powered solutions and preparing for a future in special forces.