Protocol Buffers versus XML and JSON Which Serialization Format Wins in 2025
 Community Contribution
Community ContributionTable of contents
- Key Takeaways
- Data Serialization Format Comparison
- Protocol Buffers (Protobuf) in 2025
- JSON in 2025
- XML in 2025
- Alternative Serialization Formats
- Choosing the Best Format
- FAQ
- What makes Protocol Buffers faster than JSON and XML?
- Can JSON replace Protocol Buffers in microservices?
- Is XML still relevant for new projects in 2025?
- How do Protocol Buffers handle schema evolution?
- Which format is best for debugging and manual inspection?
- Are there security concerns with any serialization format?
- Can a system use multiple serialization formats together?
- What are the main drawbacks of Protocol Buffers?

In 2025, protocol buffers set the standard for serialization efficiency and speed. Recent benchmarks reveal that protobuf delivers message serialization in under 2,000 nanoseconds per operation with minimal memory overhead, outperforming JSON and XML by a wide margin.
| Format | Latency (ns/op) | Memory (bytes/op) | Best Use Case |
| Protocol Buffers | ~1,827 | ~1,856 | Inter-service communication |
| JSON | ~7,045 | ~2,288 | Web APIs, debugging |
| XML | Higher | Higher | Document-centric, legacy |
JSON and XML still provide value for human-readability, schema validation, and legacy integration. Readers should weigh factors like performance, scalability, and future adaptability when selecting a serialization format.
Key Takeaways
Protocol Buffers offer the fastest and most efficient serialization, ideal for high-performance and scalable systems.
JSON remains popular for web APIs and debugging due to its human-readable format and broad compatibility.
XML excels in strict schema validation and complex document handling, making it suitable for legacy and regulated environments.
Choosing a serialization format depends on your needs for speed, readability, schema validation, and system compatibility.
Binary formats like Protocol Buffers reduce data size and latency but require extra tools for debugging and schema management.
New formats like Avro, MessagePack, and CBOR provide alternatives with good performance and flexibility for modern applications.
For real-time systems, prioritize fast, compact formats like Protocol Buffers or MessagePack to ensure responsiveness.
Using multiple formats together can balance human-readability and performance, such as JSON for external APIs and Protocol Buffers internally.
Data Serialization Format Comparison
Strengths Overview
| Format | Performance | Scalability | Human-Readability | Schema Validation | Future Relevance |
| Protocol Buffers | Fastest, binary | Excellent | Low | Limited (.proto) | High (microservices) |
| JSON | Moderate | Good | High | Moderate (JSON Schema) | High (web APIs) |
| XML | Slowest | Moderate | High | Strong (XSD) | Moderate (legacy) |
Protocol buffers deliver outstanding performance and scalability. Recent industry benchmarks show that protobuf processes requests up to six times faster than JSON in microservices environments. The binary serialization format and schema enforcement enable efficient data transfer and minimal payload size. Protobuf supports robust cross-platform data interchange and zero-copy formats, making it ideal for distributed systems.
JSON stands out for its human-readability and universal compatibility. Developers favor JSON for web APIs and debugging due to its simple text format and broad support across platforms. JSON Schema provides moderate schema validation, addressing type-safety and backward compatibility. JSON remains future-proof for web and mobile applications.
XML excels in schema validation through XSD, supporting complex data structures and strict data integrity. Enterprises rely on XML for document-centric workflows and legacy integration. XML offers high human-readability and mature tooling, though its verbosity limits performance in modern systems.
Tip: When selecting a data serialization format, consider the application's need for speed, scalability, and schema validation. Protocol buffers suit high-performance, scalable systems. JSON fits web APIs and front-end development. XML remains relevant for legacy and enterprise scenarios.
Weaknesses Overview
Protocol buffers lack human-readability due to their binary format. Developers face challenges during debugging and manual inspection. The smaller community and limited resources compared to JSON may hinder adoption in some environments. Schema validation in protobuf is less expressive, focusing on efficient binary serialization rather than rich validation features.
JSON suffers from slower performance and larger payloads compared to zero-copy formats like protocol buffers. The absence of strong typing and limited schema enforcement can lead to data inconsistencies. JSON Schema tooling continues to improve but does not match the strictness of XML's XSD.
XML introduces significant performance overhead due to its verbose structure. Serialization and deserialization require more computational resources, impacting scalability. XML's complexity and legacy status make it less attractive for new projects focused on speed and efficiency.
Performance, payload size, and computational resource usage remain critical for scalability.
Compatibility with system architecture and scalability requirements influences long-term maintainability.
Data complexity, schema validation, and schema evolution affect system stability.
Security considerations, such as avoiding vulnerabilities and supporting encryption, are essential.
Efficient data design and robust deserialization practices help maintain responsiveness and backward compatibility.
Note: Zero-copy formats like protocol buffers and MessagePack reduce memory usage and improve serialization speed, supporting scalable and responsive systems.
Protocol Buffers (Protobuf) in 2025
Features
Protocol buffers stand out in 2025 due to their binary serialization format, which delivers unmatched efficiency. This binary approach produces compact payloads, reducing network usage and storage requirements. Developers benefit from strong typing enforced by schema definitions, which ensures data consistency and minimizes runtime errors. Automated code generation from .proto files accelerates development and maintains consistency across multiple programming languages. Protobuf supports schema evolution, allowing backward and forward compatibility as systems grow. The format enables high performance in distributed environments, especially when paired with grpc services and HTTP/2. Multiplexing and near-zero latency become achievable, making protobuf a top choice for demanding applications.
Key features include:
Compact binary serialization format for smaller data sizes.
Strongly-typed schemas that enforce data structure at compile time.
Automated code generation for multiple languages.
Backward and forward compatibility for evolving schemas.
Support for complex data types, such as 'Any' and 'oneof'.
High performance and speed in serialization and deserialization.
Optimized for grpc services and distributed systems.
Use Cases
Organizations choose protocol buffers for scenarios where speed and efficiency are critical. Microservices architectures rely on protobuf to handle high-throughput inter-service communication. Real-time systems, such as financial trading platforms and IoT networks, benefit from the format’s low latency and minimal overhead. Cloud applications use protobuf to optimize data transfer and reduce operational costs. grpc services leverage the binary format to achieve near-zero latency and multiplexing, outperforming traditional REST APIs. Protobuf also fits well in environments where strong typing and schema evolution are essential for long-term maintainability.
Common use cases:
Microservices communication in distributed systems.
Real-time data streaming and processing.
Remote procedure calls (RPC) using grpc services.
Cloud-native applications requiring high performance.
Scenarios demanding schema evolution and backward compatibility.
Limitations
Despite its strengths, protobuf introduces several challenges. The binary format lacks human-readability, making manual inspection and debugging more difficult. Teams must invest in additional tools and services to manage schema files and code generation. Some organizations find the operational complexity of integrating protocol buffers into existing workflows significant. The requirement to tie data models to schemas may not suit every development team, especially those accustomed to more flexible formats. Protobuf is less suitable for direct browser consumption or scenarios where data transparency is a priority. Case studies, such as LinkedIn’s experience, highlight the complexity of dynamic schema generation and the need for gradual client reconfiguration, which can add development overhead.
Note: Teams should evaluate their readiness for schema-driven development and consider the operational impact before adopting protocol buffers for new projects.
JSON in 2025
Features
JSON remains a cornerstone of data interchange in 2025. Its lightweight, text-based structure allows developers to parse and transmit data quickly. The format is language-independent, which means teams can use it across all major programming languages. JSON uses simple key-value pairs, making data easy to understand and map to domain objects. Developers appreciate its seamless integration with JavaScript frameworks, especially in environments like Node.js. The format requires minimal coding and memory, which supports large object graphs and fast data interchange. Open-source libraries for JSON are widely available and do not require extra dependencies. Every modern browser supports JSON, which increases its accessibility for web development.
Lightweight and easy to parse
Language-independent and widely compatible
Simple key-value data modeling
Seamless integration with JavaScript and Node.js
Minimal coding and memory requirements
Open-source libraries with no extra dependencies
Universal browser support
JSON also plays a growing role in AI and automation. Developers use JSON prompting to structure outputs for AI models and configure autonomous agents. The format supports multi-modal integration, orchestrating text, image, audio, and video inputs. Industry-specific standards for JSON prompting are emerging, especially in fields like finance and medicine.
Tip: JSON’s open standard and interoperability make it a preferred choice for cloud computing and API-driven environments.
Use Cases
JSON dominates modern web and mobile development. It serves as the standard for API communication, enabling data exchange between servers and web applications. Developers use JSON for configuration files, storing operational parameters and application settings. NoSQL databases, such as MongoDB, rely on JSON-like formats for flexible data storage. Mobile apps consume JSON from servers to update content dynamically. The format supports both simple messages and complex nested data models, which makes it ideal for dynamic applications.
1. Web APIs for data exchange between servers and clients 2. Configuration files for application settings 3. Data storage in NoSQL databases 4. Serialization and deserialization of complex data 5. Logging and monitoring in structured formats 6. Client-server communication in web development 7. Mobile app data exchange via RESTful APIs 8. Data interchange in IoT ecosystems
JSON’s language-independent nature allows diverse systems to exchange data easily. Its lightweight format and broad support make it the preferred choice for transferring data between servers and web applications.
Limitations
Despite its popularity, JSON faces several limitations in 2025. Its textual and verbose nature increases network bandwidth usage and latency, which can impact performance. The format lacks native binary data support, forcing inefficient encoding and decoding processes. Deeply nested JSON structures require recursive parsing, which adds computational overhead. String manipulation in JSON is slower than binary data handling. The format supports only a limited set of data types, leading to inefficient data representations. Larger payload sizes and longer transfer times result from its verbosity.
Many technology companies, including LinkedIn and Uber, have adopted binary serialization formats like Protocol Buffers and MessagePack to overcome these challenges. These alternatives offer better speed and smaller payload sizes, especially for high-performance applications.
Note: JSON’s lack of strong typing and performance limitations make it less suitable for scenarios that demand maximum efficiency or strict data validation.
XML in 2025
Features
XML continues to offer robust features for organizations that require complex data validation and strict schema enforcement. Its self-describing nature allows developers to define intricate data structures with clarity. Mature tooling supports schema validation through technologies like XSD, which ensures data integrity and consistency. XML provides strong interoperability, making it suitable for integration across diverse platforms and legacy systems. The format supports namespaces, enabling modular design and reducing conflicts in large-scale projects. Many enterprise environments rely on XML for its ability to handle hierarchical and document-centric data efficiently.
XML’s mature ecosystem includes validators, editors, and transformation tools, which streamline development and maintenance for large-scale applications.
Use Cases
Many industries continue to depend on XML for mission-critical applications. The finance, healthcare, and government sectors use XML to maintain data accuracy and support complex data representation. API development often favors XML, with about 20% of APIs choosing it for strict validation and schema enforcement. Enterprise applications, such as those built with Apache and Spring Framework, utilize XML configuration files for clear formatting and reliable validation. Content Management Systems structure content dynamically using XML, with approximately 15% of leading CMSs supporting it natively in 2025. Hybrid mobile applications, including those developed with Apache Cordova, define user interface layouts using XML for cross-platform compatibility. Machine learning pipelines employ XML for data interchange, metadata management, and configuration files, which improves reproducibility and model reliability. Blockchain integration benefits from XML’s structured format, enhancing data integrity and interoperability. Accessibility improvements leverage XML-based markup languages to create semantic documents that assistive technologies can interpret effectively.
Finance, healthcare, and government sectors
API development with strict schema enforcement
Enterprise configuration files (Apache, Spring Framework)
Content Management Systems (CMS)
Hybrid mobile applications (Apache Cordova)
Machine learning pipelines
Blockchain integration
Accessibility improvements
Limitations
XML presents notable limitations in terms of verbosity and performance overhead. The format’s repetitive tag names increase file size, which leads to higher storage and transmission costs, especially for large datasets. This space inefficiency creates performance penalties for applications that process significant data volumes. XML’s self-describing nature, while beneficial for clarity, results in increased overhead. Processing XML documents requires traditional text parsing methods that tokenize data into many string objects, causing slow processing and high memory consumption. General-purpose processors do not optimize for the repetitive operations needed for XML parsing, which further restricts performance. Benchmarks indicate that XML processing throughput often falls short of available network bandwidth, making parsing speed a critical bottleneck in enterprise scenarios. Efforts to improve performance, such as binary XML formats, often compromise human readability and schema flexibility. Some innovative approaches attach a parsed binary state to the original XML document, enhancing performance without sacrificing readability.
Developers should consider XML’s trade-offs between data integrity and operational efficiency when selecting a serialization format for modern systems.
Alternative Serialization Formats
New Formats
Developers in 2025 have access to a growing range of serialization formats beyond Protocol Buffers, JSON, and XML. Several new and emerging formats have gained notable traction due to their performance, compactness, and suitability for modern applications.
Apache Avro has become a staple in big data environments, especially with Hadoop. Its binary format and self-describing schemas enable fast serialization and efficient storage.
MessagePack, favored in mobile and embedded systems, offers a compact binary structure similar to JSON. Its design supports bandwidth-constrained and resource-limited environments.
CBOR (Concise Binary Object Representation) stands out for its compactness and speed. The cbor-x implementation for NodeJS/JavaScript outperforms many MessagePack and Avro libraries. CBOR’s IETF standardization and extension support make it ideal for browsers and IoT devices.
JSON BinPack, an open-source binary JSON format, focuses on space efficiency. It supports both schema-driven and schema-less modes using JSON Schema 2020-12. Benchmarks show JSON BinPack outperforms twelve alternative binary formats in space efficiency, often surpassing general-purpose compressors like GZIP and LZMA. Its optimization for low-bandwidth and unreliable connections makes it suitable for mobile and IoT systems.
Developers select these formats for applications that demand high performance, compact payloads, and flexibility in schema evolution.
Comparison
The following table summarizes how Avro, MessagePack, and CBOR compare to Protocol Buffers, JSON, and XML in terms of speed, efficiency, and ease of use:
| Format | Serialized Size (bytes) | Serialization Time (ms) | Schema Support | Human-Readability | Typical Use Cases |
| Avro | ~133 | ~0.0051 | Dynamic, runtime | Low | Big data, Hadoop, streaming |
| Protocol Buffers | ~155 | ~0.0077 | Strong, code-gen | Low | Microservices, real-time systems |
| MessagePack | ~230 | ~0.0296 | Optional | Low | Mobile, embedded, IoT |
| CBOR | ~230 | ~0.0296 | Optional, extensible | Low | IoT, browsers, resource-limited |
| JSON | ~290 | ~0.0333 | Moderate (JSON Schema) | High | Web APIs, debugging |
| XML | ~571 | ~0.1025 | Strong (XSD) | High | Enterprise, legacy, documents |
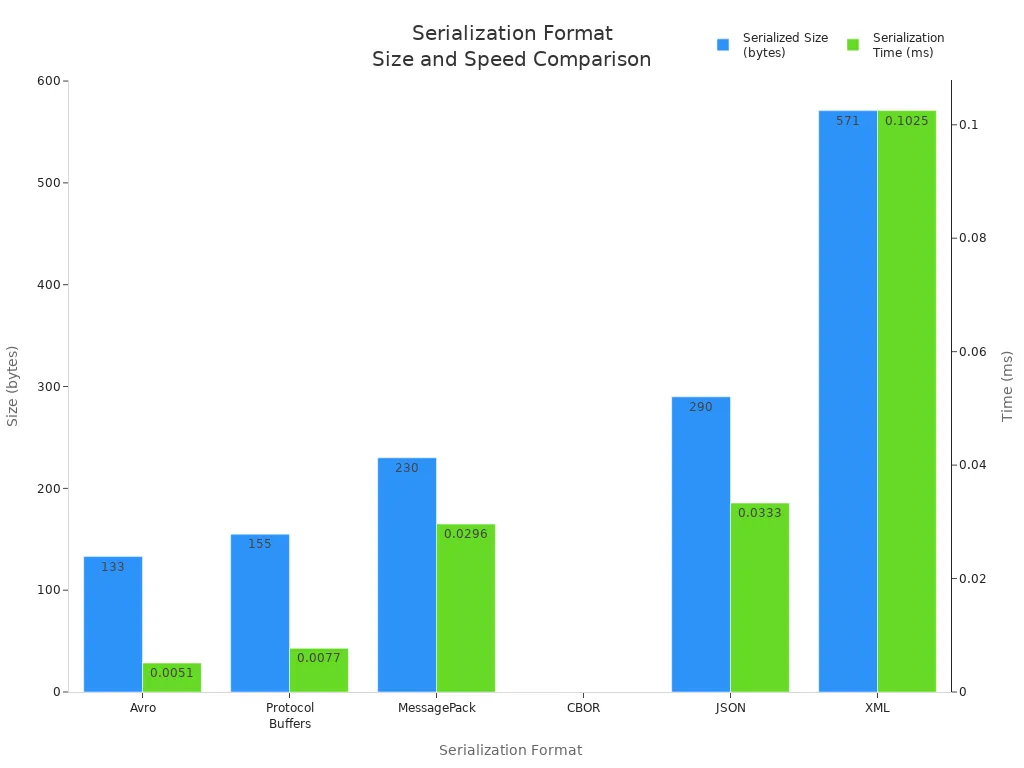
Avro and Protocol Buffers lead in speed and compactness, making them suitable for high-throughput and storage-sensitive environments. Avro’s dynamic typing and runtime schema usage simplify development in dynamic languages, while Protocol Buffers require predefined schemas and code generation for optimal performance. MessagePack and CBOR offer flexibility without mandatory schemas, supporting bandwidth-constrained devices and resource-limited systems. CBOR’s extensions and standardization provide additional advantages in browser and IoT contexts. JSON and XML, while slower and less efficient, remain popular for their human-readability and broad compatibility.
Zero-copy formats such as Protocol Buffers, Avro, and MessagePack reduce memory usage and improve serialization speed, supporting scalable and responsive systems. Developers must consider the trade-offs between performance, schema flexibility, and ease of use when selecting a serialization format for modern applications.
Choosing the Best Format
Real-Time Systems
Selecting a serialization format for real-time systems in 2025 requires a focus on speed, compactness, and compatibility. High-performance systems demand formats that minimize latency and maximize throughput. Binary formats such as Protocol Buffers and MessagePack excel in these environments. They offer rapid serialization and deserialization, which is essential for real-time processing. These formats also reduce payload size, lowering storage and network costs.
Key criteria for real-time and performance-sensitive applications include:
Serialization/Deserialization Speed: Fast processing ensures system responsiveness.
Data Compactness: Smaller payloads reduce bandwidth and storage requirements.
Schema Evolution: Formats like Protocol Buffers support backward and forward compatibility, easing maintenance.
Cross-Platform Compatibility: Broad language support enables interoperability.
Memory Usage: Predictable and low memory consumption benefits embedded and IoT devices.
Zero-copy formats such as FlatBuffers and Cap’n Proto further enhance performance by allowing direct data access without deserialization. While human readability can aid debugging, it remains secondary in performance-critical systems. JSON, though widely supported, cannot match the efficiency of binary formats in these scenarios.
Tip: For high-throughput, low-latency environments, Protocol Buffers and similar binary formats provide the best balance of speed, compactness, and maintainability.
Web APIs
Web APIs in 2025 continue to favor JSON as the primary serialization format. JSON’s simple syntax and clear structure make it easy to write, read, and debug. Its widespread support across programming languages ensures seamless integration between front-end and back-end systems. RESTful APIs benefit from JSON’s hierarchical key-value structure, which naturally represents structured data.
| Aspect | Explanation |
| Preferred Format | JSON is the most commonly recommended serialization format for web APIs in 2025. |
| Reasons | - Simple and clear syntax, easy to write and read |
| - Wide support across almost all mainstream programming languages | |
| - Natural fit for structured data transmission between front-end and back-end systems | |
| - Efficient for RESTful API data communication | |
| Advantages | - Conciseness reduces human errors |
| - Hierarchical key-value structure supports structured data | |
| Disadvantages | - No native comment support, complicating maintenance |
| - Limited native data types (e.g., no dedicated date/time type) requiring additional handling | |
| Additional Context | Other formats like YAML, TOML, and XML are discussed but not highlighted as primary choices. |
| Swift serialization discussions reinforce JSON's prominence with format-specific coders. |
Developers often choose JSON for its ease of use and compatibility with modern frameworks. However, JSON lacks native support for comments and advanced data types, which may require additional handling. For APIs that demand maximum efficiency or binary data transfer, Protocol Buffers or Avro may serve as alternatives, but JSON remains the default for most web-facing interfaces.
Human-Readability
Human-readability plays a crucial role in scenarios where developers need to inspect, debug, or manually edit data. Syntax simplicity, support for comments, and verbosity all influence how easily a format can be understood. JSON stands out for its minimalistic syntax, making it approachable for both developers and non-technical stakeholders. XML offers structured markup and supports comments, but its verbosity can make large documents cumbersome. Protocol Buffers, with their binary encoding, do not support human readability, which complicates debugging and manual inspection.
| Factor | JSON | XML | Protocol Buffers (Protobuf) |
| Syntax Simplicity | Simple, minimalistic syntax | Structured with nested elements | Binary format, not human-readable |
| Support for Comments | No native support; workaround needed | Supports comments via markup | No support, binary format |
| Verbosity | Moderate; concise but no comments | Verbose and complex | Very concise due to binary encoding |
| Data Type Support | Supports strings, numbers, booleans, null; no dates | Supports complex types with schema validation | Supports many primitive types and custom types |
| Human Readability | Rated 5/10; human-readable but limited by lack of comments | Human-readable, highly structured but verbose | Rated 1/10; not designed for human readability |
| Language Support | Very broad | Broad | Supports multiple languages but requires code generation |
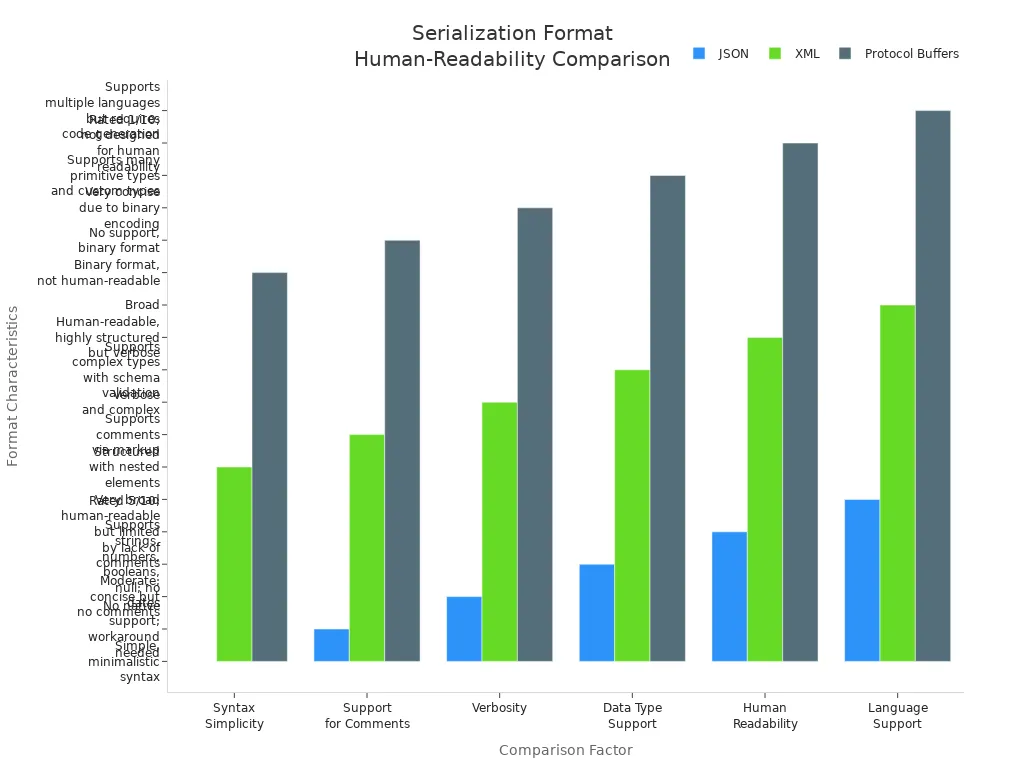
JSON and XML remain the preferred choices when human-readability is a priority. JSON’s concise structure makes it ideal for configuration files, logs, and API responses that require frequent inspection. XML’s schema validation and comment support benefit complex document workflows, despite its verbosity. Protocol Buffers, while efficient, should be reserved for cases where performance outweighs the need for human-readable data.
Legacy Systems
Legacy systems continue to play a significant role in many organizations. These systems often rely on established serialization formats such as XML and JSON. XML remains a preferred choice for legacy integration due to its mature tooling, strong schema validation, and widespread industry adoption. Many enterprise applications, especially those in finance, healthcare, and government, still depend on XML for data interchange and document-centric workflows.
JSON also finds use in legacy environments, particularly where web-based interfaces or lightweight data exchange are required. Its simplicity and broad language support make it a practical option for bridging older systems with modern applications.
Key considerations for legacy system integration include:
Compatibility: XML and JSON offer broad compatibility with existing software and hardware.
Schema Validation: XML provides robust schema enforcement through XSD, ensuring data integrity.
Tooling: Mature tools and libraries exist for both XML and JSON, reducing development overhead.
Documentation: Both formats support clear documentation, which aids in maintenance and onboarding.
| Format | Strengths in Legacy Systems | Typical Use Cases |
| XML | Strong validation, mature tooling | Enterprise, finance, healthcare |
| JSON | Simplicity, web compatibility | Web interfaces, lightweight integration |
Organizations should assess the technical debt and long-term maintenance needs when choosing a serialization format for legacy integration. XML and JSON remain reliable options for extending the life of existing systems.
Future-Proofing
Selecting a serialization format with future-proof qualities ensures long-term relevance and adaptability. Modern organizations seek formats that can evolve with changing technology landscapes and regulatory requirements. Several features define a future-proof serialization solution:
Flexibility to adapt to new data structures and business needs.
Interoperability with diverse platforms and systems.
Cloud-based integration for scalable and secure data storage.
Support for communication between different systems, including cloud-based tracking.
Secure handling of large volumes of granular data.
Offline data capture with self-healing capabilities to prevent data loss during downtime.
Aggregation and rework process support for line-level serialization.
Use of two-dimensional barcodes, such as data matrix codes, which remain mandated and relevant.
Optional integration with RFID technology for enhanced tracking and automation.
Adherence to global standards like GS1 for compliance and interoperability.
Minimal equipment footprint and seamless integration with existing production lines.
Formats such as Protocol Buffers, Avro, and CBOR align well with these requirements. They offer strong support for schema evolution, efficient cloud integration, and robust cross-platform compatibility. JSON continues to serve as a bridge for web and mobile applications, while XML maintains its place in regulated industries.
A future-proof serialization strategy should prioritize adaptability, compliance, and seamless integration with both current and emerging technologies. Organizations that invest in flexible, interoperable formats position themselves for sustained success beyond 2025.
Protocol Buffers lead in 2025 for performance and efficiency, especially in high-throughput and bandwidth-constrained systems. JSON remains the top choice for browser-based and public APIs due to its readability and integration ease. XML continues to serve scenarios requiring robust schema validation and complex document structures. The table below summarizes expert recommendations:
| Format | Best Use Case | Key Advantage |
| Protocol Buffers | Internal APIs, high-performance systems | Compact, fast, strong schema support |
| JSON | Web APIs, browser consumers | Human-readable, easy integration |
| XML | Complex validation, document-centric systems | Strong schema, narrative structure |
- Organizations should match format to use case, consider offering both JSON and Protobuf for APIs, and monitor emerging formats like Avro and MessagePack for evolving needs.
FAQ
What makes Protocol Buffers faster than JSON and XML?
Protocol Buffers use a compact binary format. This reduces parsing time and memory usage. Developers benefit from smaller payloads and faster serialization, which improves performance in high-throughput systems.
Can JSON replace Protocol Buffers in microservices?
JSON offers human-readability and broad compatibility. However, it cannot match Protocol Buffers in speed or efficiency. Microservices that require low latency and small payloads perform better with Protocol Buffers.
Is XML still relevant for new projects in 2025?
XML remains important for industries needing strict schema validation and legacy integration. Most new projects prefer JSON or Protocol Buffers for efficiency. XML best serves document-centric or regulated environments.
How do Protocol Buffers handle schema evolution?
Protocol Buffers support backward and forward compatibility. Developers can add or remove fields in .proto files without breaking existing systems. This flexibility helps maintain long-term stability in evolving applications.
Which format is best for debugging and manual inspection?
JSON stands out for debugging and manual inspection. Its text-based structure allows easy reading and editing. XML also offers human-readability but can become verbose. Protocol Buffers, being binary, require specialized tools.
Are there security concerns with any serialization format?
All formats require secure handling. Protocol Buffers, JSON, and XML can expose vulnerabilities if not validated or sanitized. Developers should implement input validation and use encryption to protect sensitive data.
Can a system use multiple serialization formats together?
Many systems combine formats. For example, APIs may use JSON for external communication and Protocol Buffers for internal messaging. This approach balances human-readability with performance.
What are the main drawbacks of Protocol Buffers?
Protocol Buffers lack human-readability and require code generation. Debugging binary data can be challenging. Teams must manage schema files and ensure all services use compatible versions.
Subscribe to my newsletter
Read articles from Community Contribution directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by