Getting Started with RAG: An Easy Guide for Beginners
 Utkarsh Kumawat
Utkarsh Kumawat
Large Language Models (LLMs) like ChatGPT and Gemini are powerful. They can generate essays, code, and even answer complex questions. But here’s the catch — they only know what they were trained on. Ask them about yesterday’s news, your company policies, or a private document, and they’ll either hallucinate an answer or say, “I don’t know.”
This is where Retrieval-Augmented Generation (RAG) comes in. RAG connects an LLM to your own data, so it can give accurate, context-aware, and up-to-date responses.
By the end, you’ll know how to build your own RAG-powered chatbot
What is RAG?
RAG is a technique where an LLM is combined with external knowledge retrieval to give more accurate and up-to-date answers.
For example, LLM is like a smart person general knowledge and RAG is like giving them access to library or google.
How RAG works
RAG system works in 3 steps:
Retrieval: Accessing and retrieving information from a knowledge source, such as a database or memory.
Augmented: Enhancing or enriching something, in this case, the text generation process, with additional information or context.
Generation: The process of creating or producing something, in this context, generating text or language.

Steps in RAG
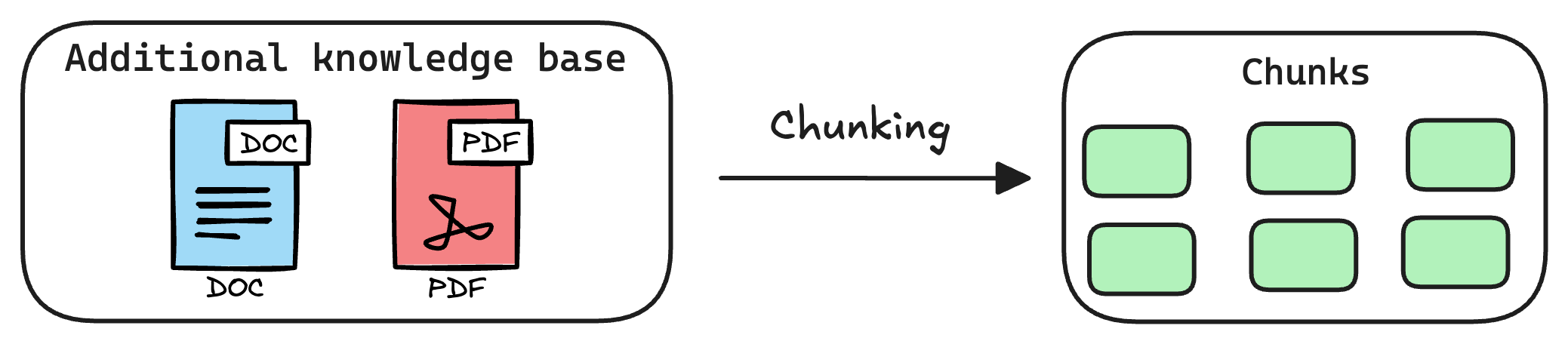
1) Create Chunks
The first step is to break down this additional knowledge into chunks before embedding and storing it in the vector database.
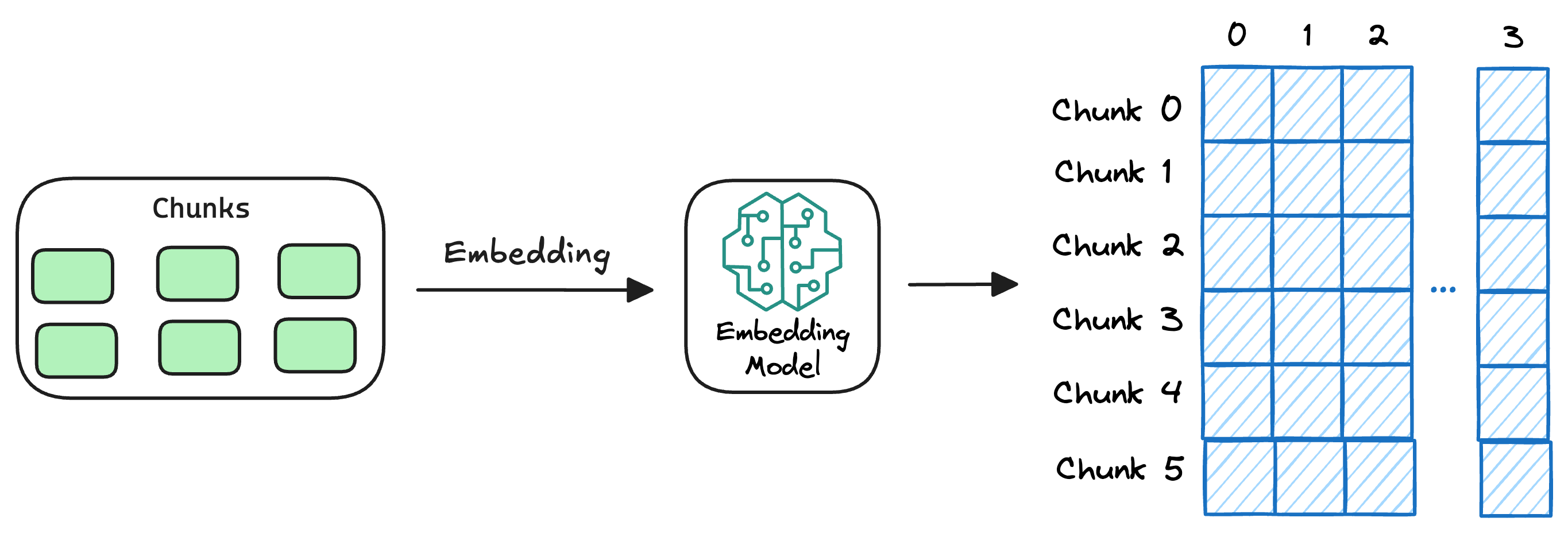
2) Generate embeddings
Moreover, if we don't chunk, the entire document will have a single embedding, which won't be of any practical use to retrieve relevant context.
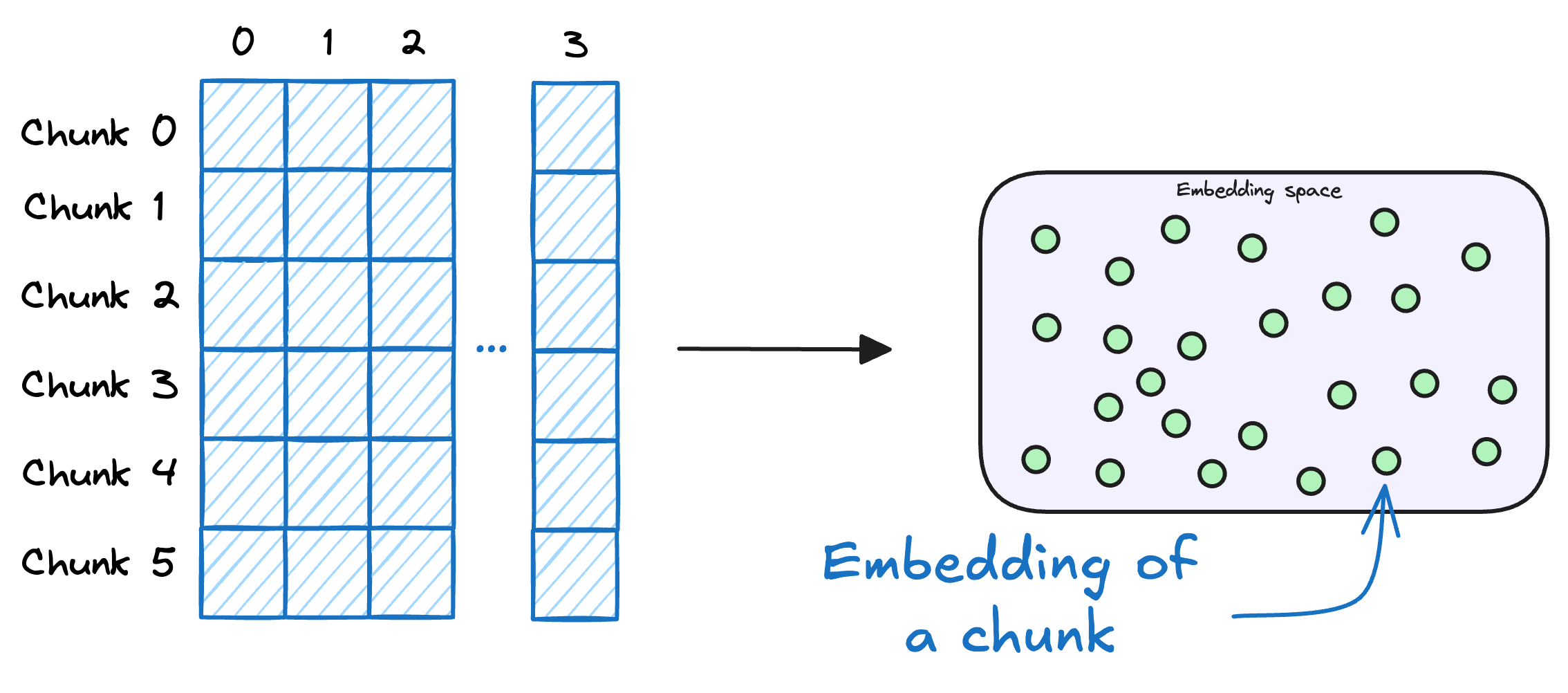
3) Store embedding in Database
These embeddings are then stored in the vector database
💡This shows that a vector database acts as a memory for your RAG application since this is precisely where we store all the additional knowledge, using which, the user's query will be answered.
A vector database also stores the metadata and original content along with the vector embeddings.
With that, our vector databases has been created and information has been added. More information can be added to this if needed.
4) User input query
Next, the user inputs a query, a string representing the information they're seeking
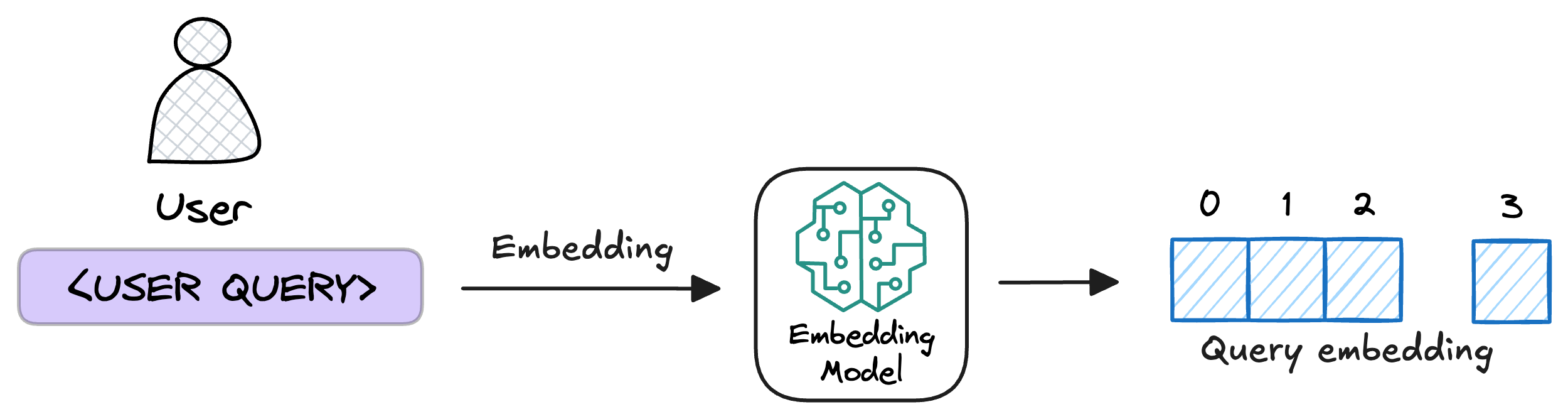
5) Embed the query
This query is transformed into a vector using the same embedding model we used to embed the chunks earlier in Step 2.
6) Retrieve similar chunks
The vectorized query is then compared against our existing vectors in the database to find the most similar information.
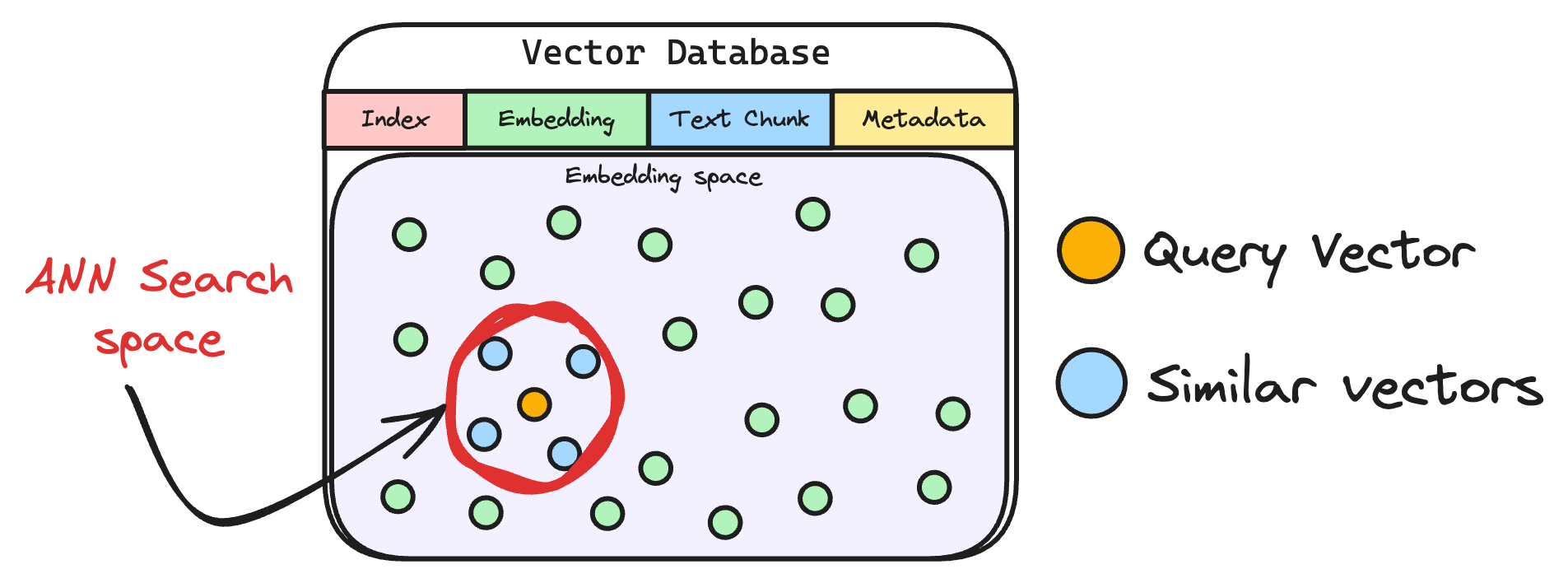
The vector database returns the k (a pre-defined parameter) most similar documents/chunks (using approximate nearest neighbor search).
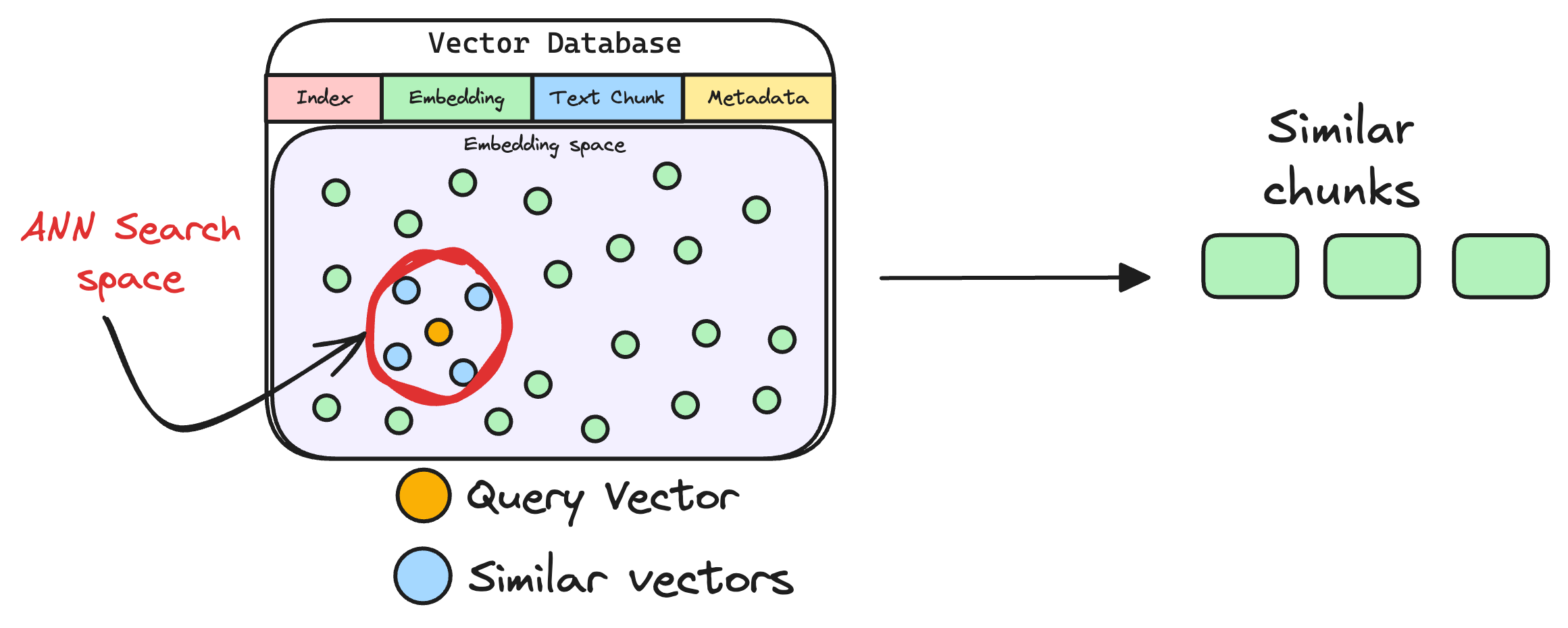
It is expected that these retrieved documents contain information related to the query, providing a basis for the final response generation.
7) Generate Final Answer
Finally, the query + retrieved chunks are passed to the LLM.
The LLM uses both the query and the additional context to generate a more accurate and grounded answer.
Full Workflow

Simple Steps to Build a RAG Chatbot (with Example Code)
1. Load Data
Read your PDF (each page becomes a document).
const loader = new PDFLoader("./my pc repair guide.pdf");
const docs = await loader.load();
2. Embed Data
Convert chunks into vector embeddings using Gemini.
const embeddings = new GoogleGenerativeAIEmbeddings({
model: "embedding-001",
apiKey: process.env.GEMINI_API_KEY,
});
3. Store in Vector DB
Save embeddings in Qdrant (can use any vector DB).
await QdrantVectorStore.fromDocuments(docs, embeddings, {
url: "http://localhost:6333",
collectionName: "RAG-testing",
});
4. User Query
Take the user’s question.
const query = "How to remove battery from my PC?";
5. Retrieve Context
Find most relevant chunks from the DB.
const retriever = vectorStore.asRetriever({ k: 3 });
const results = await retriever.invoke(query);
6. Generate Answer
Send query + retrieved context to the LLM.
const response = await openai.chat.completions.create({
model: "gemini-2.0-flash",
messages: [
{ role: "system", content: `Answer only using context: ${JSON.stringify(results)}` },
{ role: "user", content: query },
],
});
console.log(response.choices[0].message.content);
👉 That’s it! The flow is:
PDF → Embeddings → Vector DB → Query → Retrieval → LLM Answer
Conclusion

Retrieval-Augmented Generation (RAG) is a simple but powerful way to make LLMs smarter. Instead of relying only on what the model was trained on, RAG connects it to your own data — whether that’s PDFs, documents, or a company knowledge base.
Subscribe to my newsletter
Read articles from Utkarsh Kumawat directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by