How Companies Check Millions of Usernames in Milliseconds
 Rushikesh Borkar
Rushikesh BorkarEver wondered how apps instantly tell you if a username is taken?
It looks like a simple check — but under the hood, it’s powered by a multi-layered system design that balances speed, correctness, and scale.
Let’s find out.

Why Not Just Query the Database?
A naïve approach is to query the database for every keystroke or submit. That works for small traffic but becomes slow and expensive at scale because every check competes with other read and write workloads.
Instead, use a cascade that rejects as early as possible and confirms only when necessary.
The layered architecture
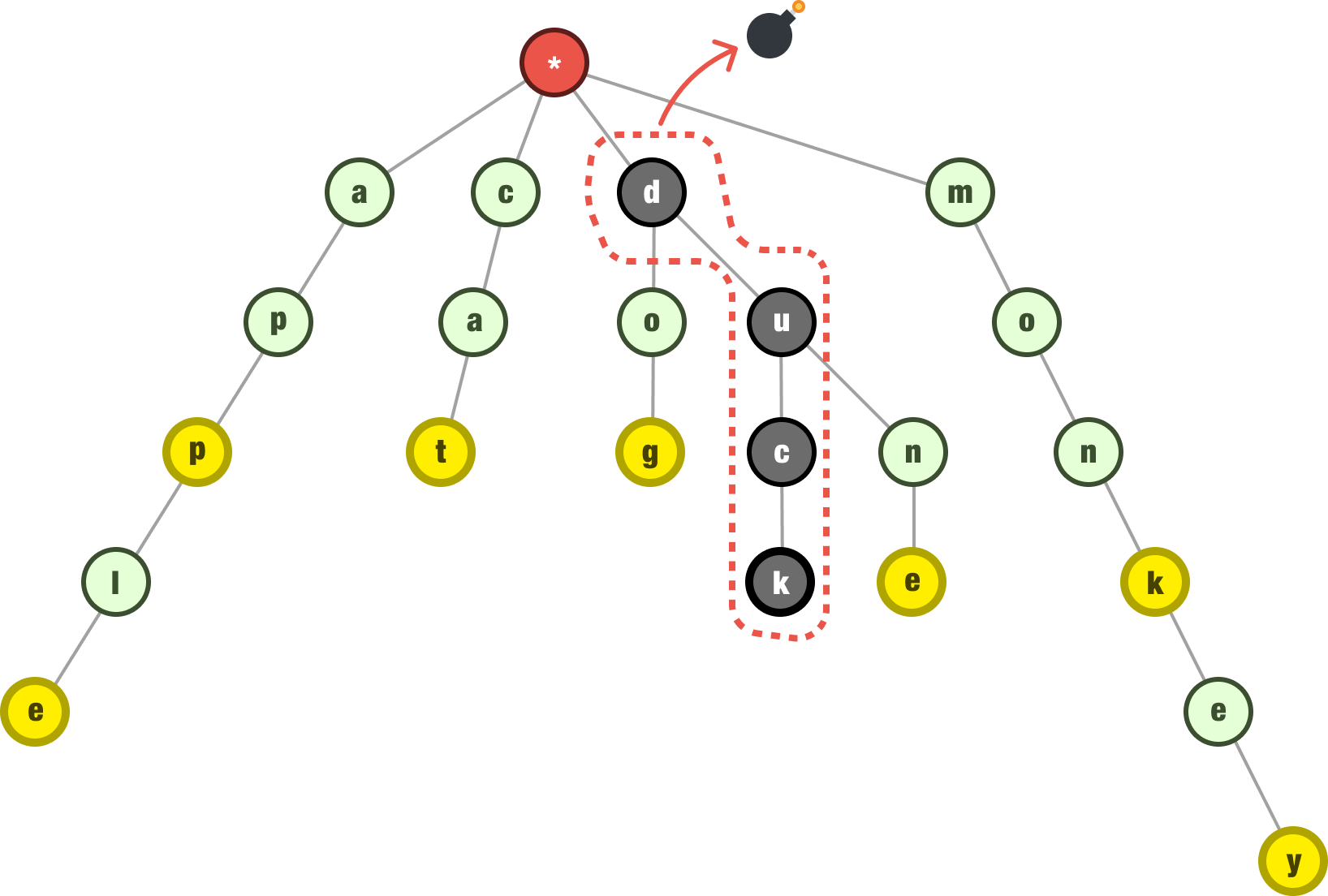
1) Bloom Filter — Fast Pre-Check
A Bloom filter answers two things quickly:
Definitely not present
Maybe present
Why it helps:
O(1) checks, very small memory footprint
Eliminates the majority of impossible usernames without touching Redis or DB
Note: false positives are possible, false negatives are not. So a “maybe” must be confirmed downstream.


2) Redis Cache — The Speed Booster
After Bloom says “maybe”, requests go to Redis.
Keep recent and frequently checked usernames in Redis with short TTLs.
Cache hit: instant yes/no
Cache miss: go to the database and backfill Redis on the way out

3) Database — the source of truth
Ultimately, correctness depends on the database.
Under the hood:
Unique index on
username(usually backed by a B+ Tree)Guarantees no duplicates — even if two users see “available” at the same time
Schema tips:
usernames table with columns: id, username (UNIQUE), created_at
Normalize or store a canonical form to enforce case and Unicode rules consistently
4) Trie — Autocomplete for UX
This part is about experience, not correctness.
A Trie (prefix tree) makes typing feel magical:
Input:
teSuggestions:
tea,team,teacup
Optimized for prefix searches, it’s why autocomplete feels instant.
This is separate from availability but improves perceived performance and usability.
End‑to‑end flow
Here’s how the full pipeline works:

Client → API (debounced input or on submit)
Bloom filter
Not present → return Available
Maybe present → step 3
- Redis
Hit → return cached result
Miss → step 4
- Database
Query by canonical username
Update Redis with the result (short TTL for "available", slightly longer for "taken")
Correctness & Race Conditions
It always relies on the database’s unique index at write time. Even if two clients see “available,” only one insert will succeed.
Treats the availability API as advisory — the signup API is authoritative via the DB constraint.
In distributed systems, this tune Bloom/caches with careful TTLs.
Conclusion
The Bloom Filter is a perfect example of how sometimes being “probably” right is better than being definitely right. It’s helping tech giants save billions while providing lightning-fast services to users worldwide.

Remember:
Perfect accuracy isn’t always necessary
Speed and efficiency often trump precision
Simple solutions can solve billion-dollar problems
The next time you browse Chrome or Netflix, remember: there’s a tiny but mighty Bloom Filter working behind the scenes, saving companies billions while making your experience seamless.
Subscribe to my newsletter
Read articles from Rushikesh Borkar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rushikesh Borkar
Rushikesh Borkar
CS undergrad (Graduating 2027) | Passionate about systems, programming, and exploring how technology works | Writing deep technical blogs to learn, share, and simplify complex concepts.