Demystifying Convolutional Neural Networks: The Brains Behind Computer Vision
 Unaiza Nouman
Unaiza NoumanIntroduction
As we delve deeper into machine learning, we encounter tasks that require machines not just to make decisions, but to “see.” This is where Convolutional Neural Networks (CNNs) come into play, a specialized subset of deep learning models that revolutionized image classification, object detection, facial recognition, and more.
Unlike traditional neural networks that struggle with high-dimensional data like images, CNNs exploit the spatial hierarchies in images to learn effectively with minimal preprocessing. This article unpacks the structure, function, and research-backed performance of CNNs in visual data analysis.
What Are Convolutional Neural Networks?
Convolutional Neural Networks are a class of deep neural networks designed primarily for processing data with a grid-like topology, such as images (2D grids of pixels).
Instead of learning features manually (as was common in traditional computer vision), CNNs learn features automatically using layers of convolution, pooling, and fully connected operations. This makes them especially suited for tasks like image classification, segmentation, and visual recognition.
According to Phung & Rhee (2019), CNNs achieve high accuracy by leveraging multiple convolutional layers that identify increasingly abstract features of images, enabling impressive performance even on small datasets.

Why CNNs for Image Processing?
Images are not just a set of pixels; they contain spatial hierarchies. For example, edges form shapes, shapes form objects, and objects create a scene. CNNs mimic this compositional structure by learning filters that detect local patterns and hierarchies from raw image data.
Instead of flattening the image like a traditional feedforward neural network would, CNNs preserve spatial relationships, making them more efficient and accurate for vision tasks.
Core Components of CNNs
Let’s walk through the major building blocks of a CNN.
1. Input Layer: Representing Images as Numbers
Every image is transformed into a matrix of numbers representing pixel intensities. For grayscale images, each pixel has a single intensity value. For colored images, each pixel contains RGB values, three numbers per pixel.
For example, a 28x28 grayscale image becomes a 784-length vector, while a 64x64 RGB image becomes a 64x64x3 tensor.

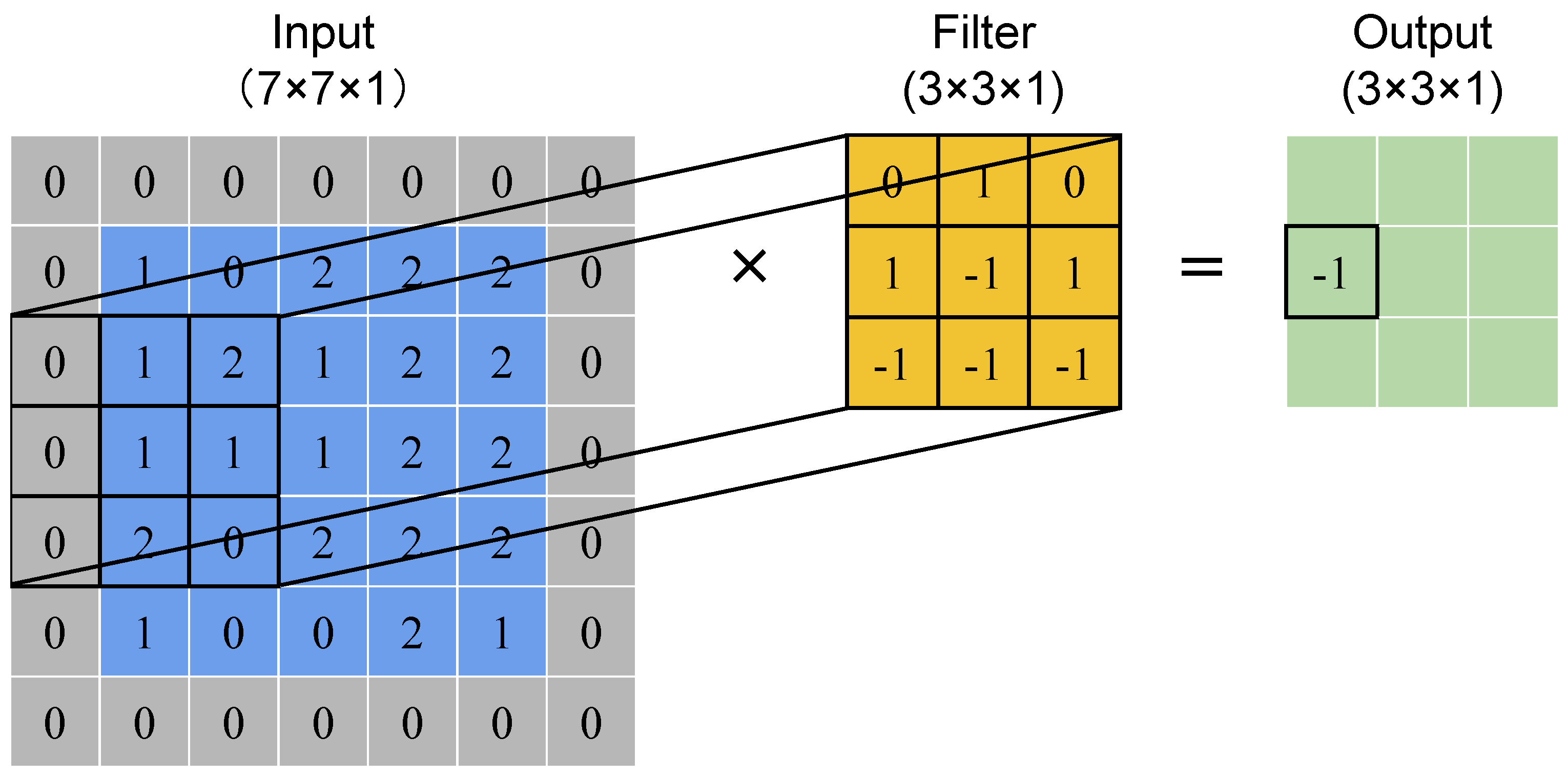
2. Convolutional Layer: Learning Patterns Locally
Convolution: A convolution is a “mathematical operation on two functions that produces a third function.”
At the heart of CNNs is the convolutional operation, a mathematical process that slides filters (also known as kernels) over the input image and computes dot products.

Each filter is designed to learn specific features like edges, textures, or corners.
As per Yakura et al. (2018)*, applying convolution with attention mechanisms can significantly improve pattern recognition even in complex domains like malware detection.*
Key concepts:
Stride: Number of pixels the filter moves.
Padding: Adds borders to maintain image size after convolution.
Activation function (ReLU): Introduces non-linearity.

3. Activation Function: Adding Non-Linearity
Without activation functions, CNNs would only be able to learn linear functions. The most commonly used activation function in CNNs is ReLU (Rectified Linear Unit), defined as:
f(x)=max(0,x)
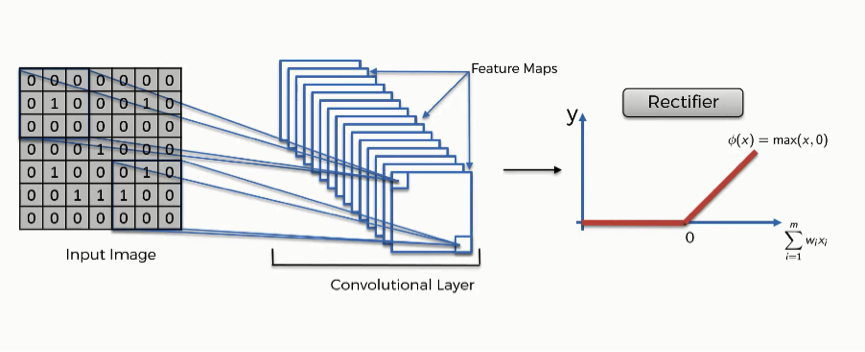
ReLU introduces non-linearity while being computationally efficient and reducing the vanishing gradient problem.
4. Pooling Layer: Downsampling for Robustness
Pooling layers are used to reduce spatial dimensions and retain the most significant information.
There are two main types:
Max Pooling: Takes the maximum value from the region.
Average Pooling: Takes the average.

This layer helps reduce computation and prevents overfitting.
According to Yani et al. (2019)*, pooling also enhances generalization in medical imaging applications,*
such as early detection of nail diseases.
5. Flattening Layer
Once the spatial features are extracted, they need to be converted into a 1D vector for the next layer. This is called flattening; the output of the last pooling layer is transformed into a vector for the dense (fully connected) layers.
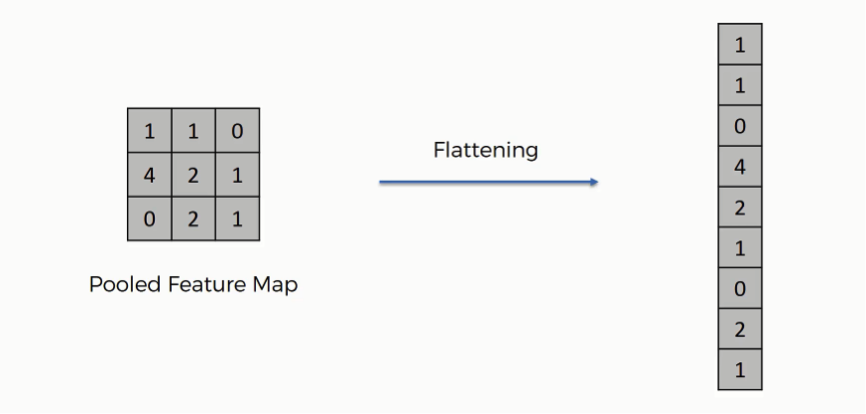
6. Fully Connected (Dense) Layer: Making Final Predictions
The fully connected layers function like those in standard neural networks. They take the high-level features and map them to the final output, whether it's binary classification (e.g., cat vs. dog) or multiclass classification (e.g., digits 0–9).

7. Output Layer & Softmax Activation
For multiclass problems, the output layer typically uses softmax activation, which converts raw scores into probabilities summing to 1.
.png?width=1024&disable=upscale&auto=webp)
This allows the model to assign probabilities to each class.
8. Loss Function: Measuring Model Errors
To evaluate how well the model is performing, a loss function is used. For classification problems, the most common is categorical cross-entropy:
L=−∑yi*log(y^i)
Lower loss indicates better predictions.
9. Backpropagation & Gradient Descent: Learning from Mistakes
After calculating the loss, the CNN updates its weights using backpropagation and gradient descent.

Backpropagation computes gradients of the loss with respect to weights.
Gradient Descent updates weights in the opposite direction of the gradient to minimize loss.
.jpg)
Where alphaα is the learning rate.
Visualization & Interpretability
CNNs are often seen as black boxes, but tools like CNN visualizers (e.g., Adam Harley’s interactive CNN tool) allow us to see how filters activate in response to different inputs. This enhances trust and explainability in AI systems.

Real-World Applications of CNNs
CNNs power a wide array of technologies:
Facial Emotion Recognition
Autonomous Vehicles
Medical Imaging
Satellite Image Analysis
Hotdog/Not Hotdog apps (Yes, really!)
Research-Backed Performance
Multiple studies highlight CNNs’ effectiveness:
Phung & Rhee (2019) demonstrated CNN ensembles achieving high accuracy on limited datasets.
Yani et al. (2019) validated CNNs in biomedical applications.
Yakura et al. (2018) integrated CNNs with attention for cybersecurity analysis.
These findings reinforce CNNs' dominance in computer vision domains.
Conclusion
Convolutional Neural Networks mark a significant leap in our journey toward intelligent machines. With the power to extract features, recognize patterns, and generalize across unseen data, CNNs represent the gold standard in visual learning tasks.
As we close this final chapter in the “ML for Humans” series, we hope this deep dive has illuminated the intricate yet fascinating architecture of CNNs. Whether you're a beginner, a student, or a practitioner, the path to mastering deep learning is now clearer.
Let’s Connect
Have feedback, suggestions, or corrections?
Did something spark your curiosity or challenge your understanding?
Let’s keep the conversation going!
Feel free to connect or drop a message. I’d love to hear from you.
Citations
Phung, S. L., & Rhee, F. C. H. (2019). A High-Accuracy Model Average Ensemble of Convolutional Neural Networks for Classification of Cloud Image Patches on Small Datasets. Applied Sciences, 9(21), 4500. https://doi.org/10.3390/app9214500
Yakura, H., Shinozaki, S., Nishimura, R., Oyama, Y., & Sakuma, J. (2018). Malware Analysis of Imaged Binary Samples by CNN with Attention Mechanism. In ACM SAC.
Yani, M., Irawan, S., & Setianingsih, C. (2019). Application of Transfer Learning Using CNN for Early Detection of Terry’s Nail. Journal of Physics: Conference Series, 1201, 012052. https://doi.org/10.1088/1742-6596/1201/1/012052
Subscribe to my newsletter
Read articles from Unaiza Nouman directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Unaiza Nouman
Unaiza Nouman
👩💻 Unaiza Nouman 🎓 CS Student @ COMSATS | 💡 Data Science Enthusiast | 🛠️ Software Developer Curious mind with a passion for building smart, scalable solutions. Exploring the world of: 🐍 Python (Pandas, NumPy) | 📊 Power BI | 🧠 Machine Learning 🧮 SQL Server | ☕ Java | 💻 C++ | 📞 VoIP (Asterisk) 🧵 DSA | 🐧 Linux | 💭 Problem Solving I write to learn, build to grow, and share to inspire. Let’s turn lines of code into something meaningful 🚀