Best Real-World Applications of Stateless Stream Processing
 Community Contribution
Community ContributionTable of contents
- Key Takeaways
- Stateless Stream Processing Use Cases
- What Is Stateless Stream Processing
- How Stateless Stream Processing Works
- Benefits
- Limitations
- FAQ
- What is the main advantage of stateless stream processing?
- Can stateless stream processing handle real-time analytics?
- When should a team choose stateful processing instead?
- Is stateless stream processing suitable for IoT applications?
- How does stateless stream processing improve scalability?
- What are common frameworks for stateless stream processing?
- Does stateless stream processing support fault tolerance?
- Can stateless stream processing integrate with REST APIs?

A delivery app sends thousands of updates every minute, tracking drivers and orders in real time. Companies such as Lyft and Pinterest use stateless stream processing to power similar applications. This approach works well for use cases like fraud detection, IoT analytics, and healthcare monitoring, where each stream event is independent. Stateless stream processing provides low latency and high scalability, making it ideal for high-volume data streams. Teams report increased efficiency and reduced costs by choosing stateless solutions over more complex alternatives.
Key Takeaways
Stateless stream processing handles each event independently, enabling fast and simple data processing without tracking past events.
This approach excels in real-time use cases like filtering, data transformation, monitoring, fraud detection, and IoT data handling.
Stateless systems offer low latency and high scalability, making them ideal for high-volume, real-time data streams.
They simplify development and maintenance by avoiding complex state management, reducing operational costs and effort.
Stateless processing supports easy horizontal scaling, allowing organizations to add or remove processing nodes quickly.
Common frameworks like Apache Flink, Kafka Streams, and Amazon Kinesis support stateless operations effectively.
Stateless stream processing fits well with REST APIs, enabling scalable, session-free, and fault-tolerant data transfer.
While powerful, stateless processing is not suitable for tasks needing event correlation, aggregation, or long-term state tracking; hybrid approaches can combine stateless and stateful methods for best results.
Stateless Stream Processing Use Cases
Stateless stream processing has become a cornerstone in modern data architectures. Organizations rely on it for a wide range of use cases that demand simplicity, scalability, and low latency. By handling each event independently, stateless systems excel in scenarios where rapid, real-time decisions are essential. The following sections explore the most impactful use cases, highlighting how stateless stream processing delivers efficiency and reliability.
Filtering
Filtering stands as one of the most common and valuable use cases for stateless stream processing. Teams use filtering to improve data quality and reduce noise in high-velocity data streams.
Unwanted Event Removal
Data filtering techniques allow systems to discard irrelevant or erroneous events as soon as they arrive. For example, a financial institution may remove invalid or incomplete transactions from a payment stream. Each event undergoes validation independently, which enables fast and scalable processing. By eliminating unwanted data early, organizations ensure that only valid events proceed downstream, improving overall data quality.
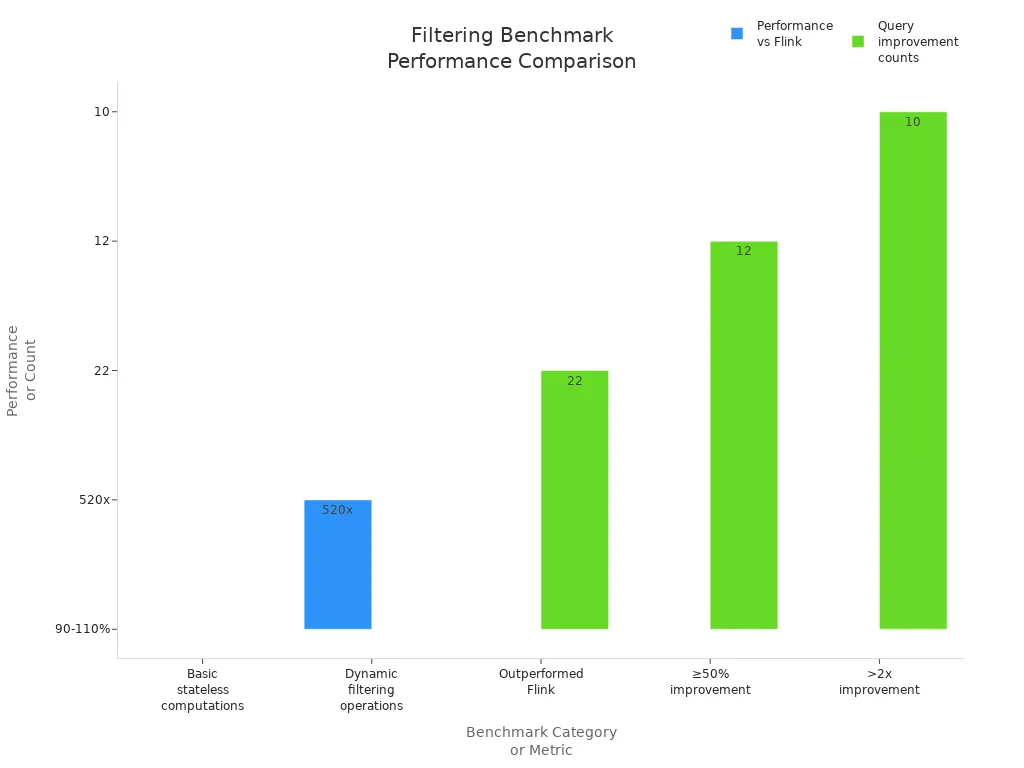
Performance benchmarks demonstrate the efficiency of stateless filtering. In a recent comparison, RisingWave matched or exceeded Apache Flink’s performance for basic stateless computations, including filtering operations. Dynamic filtering queries showed even greater speedups, with one query running 520 times faster than Flink.
Rule-Based Filtering
Rule-based filtering applies predefined criteria to incoming events. E-commerce platforms, for instance, filter purchase events from clickstreams to identify valid sales. Each event is evaluated against business rules without referencing previous events. This stateless approach supports horizontal scalability and low-latency processing, making it ideal for high-throughput environments. By leveraging stateless stream processing, organizations can efficiently handle large volumes of data while maintaining resource efficiency and fault tolerance.
Data Transformation
Data transformation is another critical use case for stateless stream processing. It enables organizations to convert, enrich, and prepare data for downstream analytics or storage.
Format Conversion
Many industries require real-time format conversion to standardize data from diverse sources. Stateless stream processing treats each event independently, allowing for straightforward and scalable transformations. For example, telecommunications companies convert raw sensor data into structured formats for monitoring and analysis. This independence accelerates processing and reduces complexity, supporting real-time analytics across sectors such as manufacturing, finance, and e-commerce.
Data Enrichment
Data enrichment adds valuable context to each event by combining it with external information. A common method involves stream-table joins, where each event is matched with records from a static table based on a key. For instance, an IoT analytics platform may enrich sensor readings with device metadata from a reference database. Stateless stream processing enables this enrichment in real time, enhancing the value of data streams without introducing complex state management. This approach supports scalability and low latency, which are essential for applications that require immediate insights.
Simple ETL
Simple ETL (Extract, Transform, Load) processes benefit greatly from stateless stream processing. These use cases focus on moving and transforming data quickly and efficiently.
Extract and Load
In stateless ETL pipelines, systems extract raw data from sources, apply transformations, and load the results into target systems such as data warehouses or lakes. Each event is processed independently, which ensures low latency and high throughput. For example, a payment monitoring system may filter transactions above a certain threshold and forward them for further inspection. Stateless stream processing makes these pipelines easy to scale and maintain.
Real-Time Transformation
Real-time transformation allows organizations to process and prepare data as it arrives. A Kafka Streams application, for example, can split incoming text lines into words, count occurrences, and output results to another topic. This stateless approach enables immediate data availability for reporting and analytics. By handling each event separately, organizations achieve simplicity and efficiency, making stateless stream processing ideal for real-time ETL tasks.
Tip: Stateless stream processing offers a lightweight solution for high-volume, real-time data pipelines. Teams can scale horizontally and reduce operational complexity by avoiding state management.
Monitoring and Alerting
Stateless stream processing plays a vital role in monitoring and alerting systems across industries. These use cases demand immediate detection and response to anomalies, system failures, or critical events. By processing each event independently, stateless solutions deliver the speed and scalability required for enterprise environments.
System Health Checks
Enterprises rely on stateless stream processing to monitor the health of their infrastructure and applications. The Keystone platform, for example, offers personalized dashboards for each streaming job. These dashboards allow both platform and application teams to diagnose issues quickly. Health monitors detect failures and trigger self-healing mechanisms, ensuring reliable operations. Stateless processing enables these checks to run efficiently, as each health event is evaluated on its own. This approach supports rapid detection of problems without the overhead of managing state.
Key benefits of stateless system health checks:
Immediate failure detection
Scalable monitoring across distributed systems
Simplified troubleshooting and maintenance
Real-Time Notifications
Organizations use stateless stream processing to generate real-time notifications for critical events. For instance, a payment monitoring system can flag high-value transactions instantly. Each event passes through the stream and, if it meets alert criteria, triggers a notification. This method ensures that alerts reach stakeholders without delay. Stateless processing supports high-throughput environments, where thousands of events may require evaluation every second.
Note: Common monitoring and alerting use cases include real-time payment monitoring, filtering events by criteria, and basic transformations. These scenarios highlight the importance of real-time detection in enterprise environments.
REST APIs
REST APIs represent a foundational use case for stateless stream processing. Their design principles align perfectly with stateless architectures, making them ideal for scalable, session-free data transfer.
Stateless Request Handling
REST APIs treat each request as an independent transaction. This stateless approach means that every request contains all necessary information for processing. Server instances do not track session data, which allows any server to handle any request. Companies like AWS and Netflix use this model to serve millions of users efficiently.
| Aspect | Explanation | Real-World Example(s) |
| Statelessness | Each request contains all necessary info; no server-side session tracking. | AWS, Netflix |
| Horizontal Scaling | Servers can be added or removed dynamically to handle load. | AWS |
| Caching | Reduces load and improves response times. | |
| API Rate Limiting | Controls request rates to maintain stable performance. | Google Maps |
| Loose Coupling | Components can be scaled or modified independently. |
This architecture enables effortless horizontal scaling and robust fault tolerance. Load balancers can distribute requests to any available server, and clients can reroute requests if a server fails. Authentication is handled through tokens or API keys included in each request, further supporting stateless operation.
Session-Free Data Transfer
Stateless stream processing ensures that REST APIs remain session-free. Each request carries all authentication and context data, eliminating the need for server-side session management. This design simplifies caching, improves platform independence, and makes testing easier. Distributed systems and cloud architectures benefit from this approach, as it reduces overhead and enhances reliability.
Advantages of session-free data transfer:
Easier horizontal scaling
Improved fault tolerance
Simplified server responsibilities
Enhanced platform independence
Payment and Fraud Detection
Stateless stream processing has become essential in payment and fraud detection use cases. Financial institutions require immediate evaluation of transactions to prevent fraud and ensure compliance.
Transaction Validation
Stateless stream processing evaluates each transaction independently. This method allows systems to check attributes such as amount, location, and frequency in real time. For example, a fraud detection system can flag transactions that exceed a certain threshold. The stream processes each payment event without referencing previous transactions, enabling low-latency and scalable validation.
The system receives a payment event.
It checks if the amount exceeds a predefined limit.
If so, it flags the transaction or routes it for further inspection.
This approach supports high-volume environments, where immediate action is critical.
Event-Based Fraud Checks
Event-based fraud checks use stateless stream processing to identify suspicious activity as it happens. Each event is analyzed for anomalies, such as unusual spending patterns or transactions from unexpected locations. The system can route flagged events to a separate topic for further review.
KStream<String, Payment> payments = builder.stream("payments");
payments.filter((key, payment) -> payment.getAmount() > 100)
.to("high-risk-payments");
This code snippet demonstrates how a stateless stream can filter high-risk payments in real time. The benefits include immediate processing, simplicity, and the ability to handle large data volumes efficiently. Financial organizations rely on these use cases to maintain security and trust in their services.
Log Analysis
Stateless stream processing has transformed log analysis by enabling organizations to detect errors and monitor performance in real time. Modern systems generate massive volumes of logs, making efficient processing essential for maintaining application reliability and user satisfaction.
Error Detection
Error detection in log analysis relies on the ability to process each log event independently. Stateless stream processing excels in this area by filtering, routing, and transforming security events as they arrive. This approach reduces noise and highlights critical issues, allowing teams to respond quickly to anomalies. In serverless computing environments, where execution is ephemeral and state is not preserved, lightweight and context-aware techniques become necessary. By combining structured telemetry with unstructured logs and leveraging AI models, organizations can identify anomalies without the overhead of maintaining state. This method supports rapid error detection and integrates seamlessly with security information and event management (SIEM) systems, ensuring timely threat response.
Tip: Stateless stream processing enables organizations to pre-process security events efficiently, reducing hardware resource usage and improving insight extraction.
Performance Monitoring
Performance monitoring benefits significantly from stateless stream processing. Frameworks such as Roots APM use lightweight, stateless benchmarking processes to collect performance data asynchronously. This design avoids delays in request processing and allows for timely anomaly detection. By buffering and batching data writes, these systems maintain high throughput and low latency. As a result, organizations can monitor application health and performance in real time, identifying bottlenecks before they impact users. The ability to process each event independently ensures that monitoring scales effortlessly with increased log volume, supporting robust real-time analytics.
IoT Data Streams
The rise of IoT devices has led to an explosion of sensor and device-generated data. Stateless stream processing provides a scalable and efficient solution for handling these high-velocity data streams, especially when immediate, per-event processing is required.
Device Monitoring
Device monitoring in IoT environments demands rapid evaluation of individual events. Stateless stream processing handles each event independently, enabling organizations to filter, transform, and enrich data without maintaining historical context. This approach supports operational efficiency by forwarding only relevant events, such as device-generated alerts or specific sensor readings, to downstream systems. The simplicity of stateless processing allows for easy horizontal scaling, ensuring that monitoring systems can keep pace with growing device fleets.
Key advantages of stateless device monitoring:
Immediate detection of device anomalies
Efficient filtering of high-volume data streams
Simplified fault tolerance and recovery
Sensor Data Processing
Sensor data processing often requires real-time analytics to extract actionable insights from continuous streams of measurements. Stateless stream processing demonstrates exceptional scalability and efficiency in this domain. Experimental evaluations on Kubernetes clusters show that increasing the number of processing instances in proportion to sensor data volume maintains stable, low-latency processing. For example, a system can scale from handling 82 to 85 sensors by simply adding more processing instances, ensuring that event-time latency remains minimal. This linear scalability allows organizations to maintain high throughput as IoT deployments expand.
By leveraging stateless stream processing, teams can efficiently filter, transform, and route sensor data for real-time analytics, supporting applications in manufacturing, smart cities, and environmental monitoring. The ability to process each event independently ensures robust performance, even as data volumes grow.
Note: Stateless stream processing aligns perfectly with the needs of IoT applications, delivering low latency, high scalability, and operational simplicity for both device monitoring and sensor data processing.
What Is Stateless Stream Processing
Definition
Stateless stream processing refers to a data processing model where each event in a stream is handled independently. The system does not retain information about previous events or interactions. This approach allows the processor to treat every incoming event as a self-contained unit. Many organizations use stateless stream processing for tasks such as filtering, mapping, and simple transformations. These operations do not require any memory of past events, which makes the system lightweight and efficient.
Stateless processing stands out in environments where high throughput and low latency are critical. For example, a payment gateway may use stateless stream processing to validate each transaction as it arrives, without referencing earlier transactions. This independence enables rapid decision-making and supports real-time analytics.
Key Features
Several features distinguish stateless stream processing from other models:
Each event is processed independently, without reliance on previous events or stored information.
Stateless operations include filtering, mapping, and grouping by key when no aggregation is needed.
The system does not require persistent storage or complex state management.
Resource usage remains low, supporting efficient scaling and fault tolerance.
Stateless stream processing enables tasks to complete without global synchronization or coordination.
Tip: Stateless processing allows organizations to add more workers and increase throughput almost linearly, since no state needs to be shared or managed.
This model simplifies fault recovery. If a task fails, the system can restart and reprocess events without restoring in-memory state. Many modern stream processing engines, such as Apache Flink and Kafka Streams, support both stateless and stateful operations, but stateless tasks remain easier to scale and maintain.
Stateless vs. Stateful
Understanding the difference between stateless and stateful processing helps teams choose the right approach for their needs. The table below summarizes the main distinctions:
| Feature | Stateless Processing | Stateful Processing |
| State Retention | Does not store information about interactions | Stores information about interactions (e.g., in DB) |
| Session Dependence | Each request is independent | Requests depend on previous interactions |
| Storage Dependence | No persistent storage needed | Requires persistent storage and synchronization |
| Resource Usage | Generally lower resource utilization | Higher resource needs due to state management |
| Scalability | Easier to scale due to independent requests | More complex scaling due to coupled state |
| Fault Tolerance | More fault-tolerant as no session data lost | Risk of data loss without replication or clustering |
| Development Complexity | Simpler to develop and maintain | Requires careful state and session management |
Stateless stream processing excels in scenarios where event independence and rapid scaling matter most. Stateless tasks avoid the overhead of global barriers and synchronization, which stateful systems require for consistency. This design leads to lower latency, easier scaling, and simpler fault recovery. In contrast, stateful processing fits use cases that need aggregation, joins, or tracking over time, but introduces complexity and higher resource demands.
How Stateless Stream Processing Works
Event Handling
Stateless stream processing systems follow a clear sequence when handling events. Each event moves through the pipeline independently, which ensures rapid and predictable processing. The main steps include:
Receiving input data streams: The system ingests continuous flows of events, such as log entries, sensor readings, or API requests.
Processing each event independently: Operations like filtering, mapping, or simple transformations occur without referencing previous events.
Producing output data streams: The system emits processed results for downstream applications, storage, or further analysis.
Stateless event handling treats every event as an isolated occurrence. For example, a stream processing pipeline might read input lines from a socket, split each line into words, convert them to integers, and sum them—each step performed independently for every event. This approach uses the producer-consumer pattern, where producers generate events and consumers process them, often through push or pull mechanisms. Routing and partitioning play a crucial role, directing each event to the appropriate processing instance based on predefined logic or keys.
Note: Stateless processing eliminates the need for context retention, which simplifies scaling and fault recovery.
Scalability
Stateless stream processing excels in scalability. Because each event is independent, the system can add or remove processing nodes without complex coordination. Routing and partitioning strategies distribute events evenly across available resources, ensuring balanced workloads. This design allows organizations to handle spikes in data volume by simply increasing the number of processing instances.
Horizontal scaling becomes straightforward. Teams can deploy additional workers to process more streams in parallel. Since no state needs to be shared, new instances can join or leave the cluster with minimal impact. Cloud-native environments benefit from this flexibility, as resources can scale up or down based on demand. Stateless architectures also support multi-tenant scenarios, where different teams or applications share the same infrastructure without interfering with each other.
Performance
Performance remains a key advantage of stateless stream processing. Systems achieve low latency because they process each event immediately, without waiting for related events or maintaining session data. Benchmarks such as ShuffleBench provide insights into real-time performance. This benchmark evaluates distributed stream processing frameworks like Flink, Hazelcast, Kafka Streams, and Spark Structured Streaming. While ShuffleBench focuses on stateful aggregation, its dataflow and load generation components reflect scenarios relevant to stateless processing.
A load generator creates synthetic data at configurable rates, simulating real-world conditions. The benchmark demonstrates that stateless operations, such as flatMap and routing, maintain high throughput and predictable latency even as data volumes increase. Organizations can rely on stateless stream processing for real-time analytics, alerting, and monitoring, knowing that performance will remain consistent as workloads grow.
Tip: Stateless stream processing supports high-throughput, low-latency applications, making it ideal for scenarios that demand immediate insights and rapid response.
Benefits
Simplicity
Stateless stream processing offers unmatched simplicity in both implementation and maintenance. By processing each event independently, developers avoid the need to manage complex state or track previous interactions. This design choice reduces the cognitive load for teams and streamlines the development process. The SPAF framework, for example, deliberately excludes stateful processing to keep its architecture straightforward. By not storing intermediate results, SPAF remains easy to implement and maintain. This approach eliminates the extra concepts and overhead that stateful computations introduce. Teams can deploy, update, and troubleshoot stateless systems with minimal effort, making them ideal for organizations seeking rapid development cycles and reduced operational complexity.
Teams often find that stateless architectures lower the barrier to entry for new developers and simplify onboarding.
Low Latency
Stateless stream processing consistently delivers low latency, making it a preferred choice for real-time analytics and mission-critical applications. Each event moves through the stream without waiting for related data, which ensures immediate processing and response. The following table highlights latency and throughput across popular data processing frameworks:
| Framework | Latency | Throughput | Scalability | Fault tolerance |
| Apache Hadoop | High | High | High | Replication in the HDFS |
| Apache Spark | Low | High | High | Resilient Distributed Dataset |
| Apache Flink | Low | High | High | Incremental checkpointing (markers) |
| Apache Storm | Low | High | High | Record-level acknowledgements |
| Apache Heron | Low | High | High | High fault tolerance |
| Apache Samza | Low | High | High | Host-affinity, incremental checkpointing |
| Amazon Kinesis | Low | High | High | High fault tolerance |
Frameworks such as Apache Flink, Storm, and Amazon Kinesis maintain low latency even under heavy loads. In smart city deployments, Flink achieves the lowest latency and highest throughput, outperforming Spark and Storm. Flink also demonstrates resilience, maintaining performance during failure recovery with only a minor decrease. These results show that stateless stream processing frameworks excel in delivering fast, reliable results for high-volume, real-time data streams.
Scalability
Scalability stands as a core advantage of stateless stream processing. Because each event is independent, organizations can add or remove processing nodes without complex coordination. This flexibility allows systems to handle sudden spikes in data volume by simply increasing the number of processing instances. Cloud-native environments benefit from this model, as resources can scale up or down based on demand. Stateless architectures also support multi-tenant scenarios, enabling different teams to share infrastructure efficiently. As a result, companies can maintain consistent performance and reliability, even as their data streams grow in size and complexity.
Scalability ensures that organizations can meet evolving business needs without overhauling their existing stream processing infrastructure.
Limitations
When Not to Use
Stateless stream processing offers speed and simplicity, but it does not fit every scenario. Teams should consider alternative approaches when applications require complex event relationships or long-term data tracking. Stateless systems process each event independently, which means they cannot aggregate data over time or maintain context between events.
Key situations where stateless stream processing may not be suitable include:
Aggregations and Windowed Operations: Applications that need to calculate running totals, averages, or other metrics over time require stateful processing. Stateless systems cannot track previous events or maintain rolling windows.
Event Correlation: Fraud detection systems often need to analyze patterns across multiple transactions. Stateless processing cannot correlate events or detect trends that span several records.
Exactly-Once Semantics: Mission-critical applications, such as financial services, demand strict consistency and fault tolerance. Stateless processing does not address the challenges of maintaining exactly-once guarantees during failure recovery.
Complex Failure Recovery: Systems with large state sizes struggle to restore data efficiently after a failure. Stateless architectures do not support checkpointing or rapid state restoration.
Teams should evaluate the complexity of their data flows before choosing a stateless approach. Stateless processing works best for simple, independent event handling.
The following table summarizes the main limitations:
| Limitation | Explanation |
| Failure to scale with complexity | Embedded frameworks like Kafka Streams require careful resource management. Simple stateless tasks scale well, but complex logic introduces bottlenecks. |
| Lack of internal consistency | Outputs may be temporarily incorrect until input streams stop. Eventual consistency does not meet strict requirements for some applications. |
| Failure recovery issues | Stateless systems lack checkpointing for state stores. Large state sizes cause long restore times and impact reliability. |
Hybrid Approaches
Many organizations combine stateless and stateful stream processing to balance simplicity and advanced functionality. Hybrid architectures allow teams to use stateless operations for tasks like filtering and transformation, while stateful components handle aggregations, joins, and pattern detection.
A typical hybrid pipeline might use stateless filters to remove unwanted events, then pass relevant data to stateful modules for deeper analysis. This approach leverages the scalability of stateless processing and the power of stateful logic. For example, an IoT monitoring system can use stateless processing to clean sensor data, then apply stateful algorithms to detect anomalies over time.
Advantages of Hybrid Approaches:
Efficient resource usage for simple tasks
Advanced analytics for complex scenarios
Improved fault tolerance and consistency
Flexible scaling based on workload
Hybrid stream processing enables organizations to optimize performance and reliability. Teams can tailor their pipelines to meet specific business needs, combining the best features of both models.
Hybrid solutions require careful design to ensure seamless integration between stateless and stateful components. Developers must manage resource allocation and monitor system health to prevent bottlenecks. By adopting hybrid architectures, organizations can address a wider range of use cases and maintain robust, scalable data processing pipelines.
Stateless stream processing delivers speed, scalability, and simplicity across many industries. Teams often choose this approach for real-time, high-volume data pipelines. It works best when each event in the stream stands alone.
Organizations should review their data needs and match them to the right processing model.
Next steps for implementation:
Identify use cases that require low latency and independent event handling.
Test stateless solutions with sample data streams.
Monitor performance and adjust resources as needed.
FAQ
What is the main advantage of stateless stream processing?
Stateless stream processing enables rapid event handling. Teams can scale systems easily. Each event is processed independently, which reduces complexity and improves fault tolerance.
Can stateless stream processing handle real-time analytics?
Stateless stream processing supports real-time analytics for independent events. It delivers low latency and high throughput. Teams use it for monitoring, alerting, and simple transformations.
When should a team choose stateful processing instead?
Teams should select stateful processing for tasks that require aggregation, event correlation, or tracking over time. Stateful systems manage context between events, which is essential for complex analytics.
Is stateless stream processing suitable for IoT applications?
Stateless stream processing fits IoT scenarios well. It processes device and sensor data efficiently. Teams can monitor devices and filter sensor streams without managing historical context.
How does stateless stream processing improve scalability?
Stateless stream processing allows horizontal scaling. Teams add or remove processing nodes as needed. No shared state means new instances join easily, which maintains consistent performance.
What are common frameworks for stateless stream processing?
Popular frameworks include Apache Flink, Kafka Streams, and Amazon Kinesis. Each framework supports stateless operations, such as filtering, mapping, and simple transformations.
Does stateless stream processing support fault tolerance?
Stateless stream processing supports fault tolerance by restarting failed tasks without restoring state. Systems recover quickly, which ensures reliable event handling.
Can stateless stream processing integrate with REST APIs?
Stateless stream processing integrates seamlessly with REST APIs. Each API request is independent. Teams use stateless architectures for scalable, session-free data transfer.
Subscribe to my newsletter
Read articles from Community Contribution directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by