A Developer’s Guide to Comparing Popular Serialization Formats
 Community Contribution
Community ContributionTable of contents
- Key Takeaways
- Serialization Format Basics
- Serialization Format Overview
- Schema Management
- Serialization Format Comparison
- Choosing a Serialization Format
- FAQ
- What is the main difference between JSON, Protobuf, and Avro?
- When should a developer choose Protobuf over Avro?
- Does Avro support schema evolution better than Protobuf?
- Is JSON still relevant for modern APIs?
- How do serialization formats impact debugging?
- Can developers mix serialization formats in one system?

Choosing the right serialization format shapes application performance and integration success. JSON, Protobuf, and Avro each serve different needs. JSON offers human-readable data and broad ecosystem support. Protobuf and Avro provide compact, fast binary serialization, with Avro excelling in schema evolution. The table below compares common formats, showing that CSV and JSON favor speed and readability, while more complex formats like XML increase data size and processing time.
| Serialization Format | Speed | Data Size | Human Readability | Complexity Support | Tooling |
| JSON | Fast | Moderate | Good | Hierarchical | Extensive |
| Protobuf | Very Fast | Small | Low | Complex | Mature |
| Avro | Very Fast | Small | Low | Complex | Strong |
Key Takeaways
Serialization converts data into formats for storage, transfer, and reconstruction, enabling smooth communication between systems.
JSON is human-readable and easy to use, ideal for web APIs and rapid development, but it produces larger data and slower performance.
Protobuf offers fast, compact binary serialization with strict schemas, making it great for microservices and resource-limited devices.
Avro excels in schema evolution and compact data size, fitting big data, streaming, and systems with frequent schema changes.
Choosing the right format depends on needs like readability, performance, schema support, and ecosystem compatibility.
Schema management is key: Avro embeds schemas for flexibility, Protobuf uses external schemas for strict control, and JSON relies on optional validation.
Binary formats like Protobuf and Avro improve speed and reduce data size but require more tooling and complex debugging.
Many teams combine formats, using JSON for external APIs and Protobuf or Avro internally, to balance readability and efficiency.
Serialization Format Basics
What Is Serialization?
Serialization refers to the process of converting complex data structures or object states into a format suitable for storage, transmission, or later reconstruction. Developers use serialization and deserialization to enable applications to save object states, transfer data across networks, and reconstruct original data from serialized formats. The fundamental principles of data serialization involve encoding an object's state into a byte stream or text-based format, which can be stored or transmitted. Deserialization reverses this process, restoring the original object. In programming environments such as .NET and C#, formatters define how objects are encoded and decoded, while data contracts specify the structure to ensure compatibility and versioning. These concepts support network programming and interoperability in distributed systems.
Tip: Always validate input data during deserialization to prevent security vulnerabilities and ensure data integrity.
The most common data serialization formats include JSON, XML, Protocol Buffers, YAML, and binary formats. Each serialization format offers specific trade-offs in readability, compactness, and schema support.
Key steps in data serialization:
Convert in-memory objects into a format for storage or transmission.
Use deserialization to reconstruct objects from the serialized format.
Why Serialization Formats Matter
Serialization formats play a critical role in distributed systems and data exchange. They convert data into structured forms suitable for storage and transmission, ensuring data integrity and coherence across different systems. Efficient serialization formats package data compactly, reducing latency and improving performance. In distributed architectures, serialization standardizes encoding and decoding, facilitating smooth communication between diverse components. This standardization is essential for interoperability and platform independence in heterogeneous environments.
Serialization formats enable efficient data transmission and reduce network overhead.
Schema-based serialization formats, such as Avro and Protobuf, ensure consistency in data representation and support evolving software systems.
Different serialization formats offer trade-offs in readability, efficiency, schema flexibility, and performance, catering to various application needs.
Selecting the right data serialization format impacts application performance, scalability, and integration capabilities. Developers must consider factors such as human readability, schema validation, and throughput when choosing a serialization format.
Common Use Cases
Serialization formats support a wide range of use cases in modern software architectures. The table below highlights typical scenarios where data serialization and exchange are essential:
| Use Case Category | Description and Examples |
| Data Storage and Transfer | Serialization converts objects into byte streams for saving to files, databases, or sending over networks, preserving structure and meaning across different architectures. |
| Interoperability | Enables data exchange between different programming languages and platforms, e.g., JSON, Protocol Buffers, XML create a common data format for cross-language communication. |
| Web APIs and Configuration | JSON is widely used for human-readable data exchange in web APIs and configuration files due to its simplicity and language independence. |
| Microservices Communication | Protocol Buffers and gRPC are popular for efficient, schema-based communication in microservices and IoT applications, supporting high performance and compact data. |
| Big Data and Streaming | Formats like Avro and Parquet support schema evolution and are used in big data platforms (Hadoop) and streaming systems (Kafka). |
| Enterprise and Industry | XML is common in enterprise environments for configuration, document markup, and data interchange; industries like aerospace, pharmaceuticals, and supply chain use serialization for traceability, compliance, and logistics. |
| Real-time and AI Systems | Optimized serialization protocols speed up real-time processing in web applications, AI model serving, and genomic data processing (e.g., Apache Arrow, NVIDIA's use cases). |
| Machine Learning Pipelines | Serialization is used to store models and serialize metrics for dashboards, enabling efficient data handling in ML workflows. |
Developers rely on data serialization formats to support data persistence, network communication, inter-process communication, and machine learning workflows. Choosing the appropriate serialization format ensures reliable, efficient, and consistent data serialization and exchange across diverse systems.
Serialization Format Overview
JSON
JSON, short for JavaScript Object Notation, stands as a widely adopted serialization format. Developers favor JSON for its human-readable text format, which uses curly braces for objects and square brackets for arrays. This format supports basic data types such as strings, numbers, booleans, arrays, objects, and null. JSON serialization and deserialization occur easily with native or library support in most programming languages.
Strengths of JSON:
Simplicity and fast parsing.
Human-readable structure, making debugging and manual editing straightforward.
Extensive adoption in web APIs, configuration files, and data storage.
Language and platform independence, which facilitates interoperability.
Weaknesses of JSON:
Verbosity increases data size compared to binary formats.
Strict syntax can cause errors, such as missing braces or quotes.
Limited support for complex data types; lacks native date or binary types.
No built-in schema enforcement or versioning, which can lead to compatibility issues.
Relaxed typing may result in errors if data formats are not strictly followed.
Security risks, such as JSON injection, require careful input validation.
JSON’s textual nature makes it suitable for scenarios where readability and ease of integration matter more than performance. Many web applications and APIs rely on JSON for exchanging data, despite its slower speed and larger payloads compared to binary formats.
Protobuf
Protobuf, or Protocol Buffers, is a binary serialization format developed by Google. It provides efficient data encoding, resulting in smaller payloads and faster transmission than JSON. Protobuf enforces strict typing through schema definitions, which helps catch errors early and maintain data consistency.
Advantages of Protobuf:
Compact binary representation reduces network bandwidth usage.
High performance with faster encoding and decoding.
Strict schema enforcement prevents data inconsistencies.
Supports backward and forward compatibility, allowing schema evolution.
Cross-language and cross-platform support.
Disadvantages of Protobuf:
Not human-readable, which complicates debugging and manual inspection.
Requires a compilation step to generate data access classes, adding complexity to the build process.
Limited native support in some languages, such as JavaScript, often requiring third-party libraries.
Lacks metadata support, so contextual information cannot be embedded within the data.
Protobuf excels in environments where performance and data size matter, such as microservices, mobile applications, and IoT systems. Its schema-based approach ensures reliable data exchange and compatibility across different versions of applications.
Avro
Avro is a binary serialization format designed for efficient data storage and transmission, especially in big data and streaming applications. Avro manages schema evolution by using both writer’s and reader’s schemas. When reading data, Avro compares these schemas and translates fields accordingly. Fields present in the writer’s schema but missing in the reader’s schema are ignored, while missing fields in the writer’s schema are filled with default values from the reader’s schema. This approach ensures forward and backward compatibility.
Avro schemas use JSON format, embedding documentation and default values. This design reduces misunderstandings and supports multi-language use. Avro provides compact binary serialization with logical types, making data efficient in space. Schema registries, such as Confluent Schema Registry, offer centralized schema storage and enforce compatibility rules and versioning. In Java, Avro supports POJO class generation from schemas, simplifying development.
Avro’s primary use cases include streaming platforms like Kafka, where it provides schema embedding, efficient schema evolution, and operational simplicity. Developers rely on Avro for real-time data streaming and processing systems, where data quality and reliability are critical.
| Format | Encoding Type | Schema Handling | Typical Use Cases |
| JSON | Text | Optional, external | Web APIs, config files |
| Protobuf | Binary | Required, external | Microservices, IoT, mobile |
| Avro | Binary | Required, embedded | Big data, streaming, Kafka |
Note: Choosing between JSON, Protobuf, and Avro depends on the specific requirements for data readability, schema management, and performance in your application.
Other Formats
Developers often encounter serialization needs that extend beyond JSON, Protobuf, and avro. Several alternative formats address specific requirements in modern software systems. Each format brings unique strengths, making them suitable for particular scenarios.
MessagePack delivers a compact binary format. It encodes data quickly and efficiently, making it ideal for real-time applications. Developers choose MessagePack when they need cross-language compatibility and already share a schema between systems. The format does not include a schema, so both sender and receiver must agree on data structure in advance.
BSON stands for Binary JSON. It encodes JSON-like documents in a binary form, adding type information. BSON is the backbone of MongoDB, supporting efficient storage and retrieval. Developers use BSON when they need to bridge the gap between human-readable JSON and the performance of binary formats. BSON does not enforce a schema, which allows flexibility but can introduce inconsistencies.
Apache Thrift supports a wide range of programming languages. It offers a full client/server stack for remote procedure calls (RPC), unlike Protobuf. Thrift includes advanced data structures such as Map and Set. Teams prefer Thrift for multi-language RPC services that require richer data structures and seamless integration. Thrift’s schema-driven approach ensures data consistency across diverse environments.
ujson has gained popularity for its ultra-fast JSON parsing and serialization. It provides a drop-in replacement for standard JSON libraries in Python. Developers select ujson when they need to process large volumes of JSON data with minimal latency. ujson does not support schema validation or evolution, so it fits best in scenarios where speed outweighs strict data contracts. Many data pipelines and web services use ujson to accelerate data exchange, especially when working with avro or other binary formats is unnecessary.
YAML offers a human-friendly format for configuration files. It supports complex data structures and comments, making it popular in DevOps and infrastructure-as-code tools. YAML’s readability comes at the cost of slower parsing and higher risk of syntax errors. Developers avoid YAML for high-performance or large-scale data exchange.
The following table summarizes these alternatives, highlighting their key characteristics and preferred scenarios:
| Serialization Format | Key Characteristics | Preferred Scenarios |
| MessagePack | Binary format, compact, fast, no schema included | Real-time applications, cross-language compatibility |
| BSON | Binary JSON encoding, includes type information, no schema | MongoDB use cases, bridging JSON and binary efficiency |
| Apache Thrift | Multi-language support, richer data structures, RPC stack | Multi-language RPC services, complex data structures |
| ujson | Ultra-fast JSON parsing/serialization, no schema | High-speed JSON processing in Python, data pipelines, web APIs |
| YAML | Human-readable, supports comments, complex structures | Configuration files, DevOps, infrastructure-as-code |
Note: Developers should evaluate the trade-offs between speed, schema support, and ecosystem compatibility when selecting a serialization format. For example, ujson excels in Python environments where performance is critical, while avro remains the top choice for schema evolution and large-scale data storage.
Many teams combine formats to optimize for different parts of their stack. They might use avro for persistent storage and ujson for rapid API responses. This hybrid approach leverages the strengths of each format, ensuring both performance and maintainability.
Schema Management
JSON Schema
JSON Schema provides a structured way to define and validate the shape of json data. Developers use it to specify required fields, data types, and value constraints. This approach ensures that json data remains consistent and predictable across systems. JSON Schema acts as a validation tool, not a serialization format. Tools like Ajv help enforce schema rules and return clear errors when json data does not match expectations. MongoDB, Postman, and Microsoft products rely on JSON Schema to maintain data integrity and compatibility. The Linux kernel uses JSON Schema to standardize hardware descriptions, while Open Policy Agent integrates it for static type checking.
JSON Schema supports compatibility in serialization workflows by enabling schema versioning and compatibility modes. Developers often use schema registries and CI/CD integrations to automate validation and enforce compatibility during deployments. By defining structured rules, JSON Schema prevents missing or malformed data, reducing parsing errors and improving data quality. In machine learning pipelines, JSON Schema ensures that data such as bounding boxes or confidence scores meet strict requirements. This standardization enables consistent data exchange across frameworks like PyTorch and TensorFlow.
MongoDB uses JSON Schema for collection constraints.
Postman validates API requests and responses with JSON Schema.
Open Policy Agent integrates JSON Schema for policy code checks.
Microsoft products maintain consistent data structures using JSON Schema.
The Linux kernel defines device tree bindings with JSON Schema.
Schema registries and CI/CD pipelines automate validation and compatibility.
Protobuf Schema
Protobuf schema management centers on defining message structures with unique field numbers. Each field receives a fixed tag, which cannot change or be reused. This design ensures that protobuf serialization and deserialization remain consistent over time. Developers use the reserved keyword to prevent conflicts when removing or deprecating fields. The removal of required fields in proto3 avoids compatibility issues, as missing required fields can cause errors. Instead, optional fields with default values are recommended.
Protobuf supports backward compatibility, allowing new consumers to read data from previous schema versions. Forward compatibility enables old consumers to ignore unknown fields added in newer schemas. Full compatibility combines both, ensuring smooth data exchange between different versions. Compatibility modes, such as BACKWARD_TRANSITIVE, extend these guarantees across multiple schema versions. Developers must avoid changing field types and instead deprecate old fields, adding new ones as needed. Field names and order can change, but field numbers must remain constant. When using json serialization with protobuf, field names become significant and should be reserved if deprecated.
Forward compatibility: Old consumers ignore new fields.
Full compatibility: Both directions within version ranges.
Optional fields with defaults maintain compatibility.
Changing field types is discouraged; deprecate instead.
Avro Schema
Avro schema management stands out for its flexibility and adaptability. Avro schemas use json format, making them intuitive for developers. Each avro data file includes its schema, allowing readers to interpret data without external definitions. Avro supports backward, forward, and full compatibility through clear rules. Developers can add new fields with default values, remove fields, or rename them using aliases. This approach allows avro to handle schema changes without breaking existing data.
Avro requires a schema to read data, enabling compact binary serialization without field names in the payload. This design reduces data size and improves performance. Avro handles schema evolution gracefully, making it ideal for projects with frequent changes. In contrast, protobuf relies on immutable field numbers, and json schema evolution can become complex due to json's flexible nature. Avro's compatibility rules ensure that new fields do not disrupt older consumers, and aliases help with renaming fields. This adaptability makes avro a popular choice for big data and streaming platforms, where data structures evolve rapidly.
Avro uses json-defined schemas embedded with data.
Backward, forward, and full compatibility supported.
Adding fields with defaults and using aliases for renaming.
Schema required for reading, enabling compact serialization.
Handles frequent schema changes without breaking data.
Preferred for big data and streaming systems.
Tip: Avro's schema evolution features make it highly suitable for environments where data structures change often, while protobuf excels in stable, performance-critical systems.
Schema Evolution
Schema evolution refers to the process of adapting data structures over time without disrupting existing systems. Developers often face challenges when updating schemas in distributed environments, especially when multiple services or applications consume the same data. Each serialization format—json, avro, and protobuf—offers distinct approaches to managing schema evolution, compatibility, and governance.
Avro stands out for its robust schema evolution capabilities. Avro embeds the schema directly with the data, allowing readers to interpret records even when the schema changes. This design supports backward, forward, and full compatibility. Developers can add new fields with default values, remove obsolete fields, or rename fields using aliases. Avro’s schema registry solutions, such as Confluent Schema Registry, provide centralized governance and version control. Teams often automate schema validation and integrate schema versioning with CI/CD pipelines to ensure consistency and enable rollback. Avro’s compatibility rules help prevent pipeline failures and maintain data integrity during migrations.
Protobuf manages schema evolution through external schema definitions. Each field in a protobuf message receives a unique tag number, which must remain unchanged. Developers avoid breaking changes by never renaming fields or altering data types. Instead, they deprecate old fields and introduce new ones. Protobuf supports backward and forward compatibility by allowing unknown fields to be ignored and default values to fill missing fields. Automated validation tools and reserved keywords help maintain schema integrity. Protobuf’s approach requires careful coordination during application deployment to avoid integration issues.
Json offers flexibility but lacks native schema enforcement. Developers use json schema as an optional layer to validate data structure and types. Schema evolution in json relies on external validation tools, such as Ajv, and manual governance. Teams often automate validation processes and employ declarative schema management to detect issues early. Json’s relaxed typing can introduce compatibility risks if changes are not carefully managed. Best practices include versioning schemas, maintaining documentation, and using schema registries for governance.
Tip: Centralized schema registries and automated validation processes help teams detect schema issues early and maintain compatibility across distributed systems.
Best practices for managing schema evolution in large-scale environments include:
Using schema-aware formats like avro and protobuf to support evolution natively.
Automating validation with tools to detect schema issues before deployment.
Employing declarative schema management and integrating version control with CI/CD pipelines.
Implementing zero-downtime migrations using expand-and-contract patterns and dual writes.
Maintaining backward and forward compatibility with default values and nullable fields.
Separating development and production environments for exhaustive testing.
Monitoring schema changes in real-time with alerting systems.
Coordinating schema evolution with application deployment to reduce integration risks.
Addressing security and governance by automating compliance checks and maintaining audit trails.
A typical workflow for schema evolution involves initial schema registration, validation for compatibility, writing new files, and optionally rewriting older files. Developers avoid breaking changes, enforce validation at write time, and communicate schema updates proactively across teams.
| Format | Schema Location | Evolution Support | Compatibility Strategies |
| json | Optional, external | Limited | Manual validation, versioning |
| avro | Embedded | Strong | Default values, aliases, registry |
| protobuf | External | Moderate | Reserved tags, deprecation, validation |
Avro provides the most comprehensive schema evolution support, making it ideal for big data and streaming platforms. Protobuf offers reliable compatibility for stable systems with strict schema governance. Json remains suitable for flexible environments where human readability and rapid iteration matter more than strict compatibility.
Serialization Format Comparison
Performance Comparison
Speed
Speed remains a critical metric for evaluating data serialization tools. Developers often prioritize high-speed performance when building distributed systems or real-time applications. Recent benchmarks highlight clear differences in speed among json, protobuf, and avro.
| Format | Serialized Size | Serialization Speed | Deserialization Speed | Memory Usage | Notes |
| JSON | Largest among tested | Slowest serialization | Slower deserialization | Moderate | Easy to use, human-readable |
| Protobuf | Slightly larger than Avro | Fast serialization (close to fastest) | Fast deserialization (close to fastest) | Low | Mature .NET library, predictable performance |
| Avro (Apache) | Most compact size | Inefficient serialization | Very slow deserialization (~10x slower than optimized) | High | Poor performance in Apache.Avro .NET, lacks logical type support |
| Avro (Chr) | Most compact size | Fastest serialization for entire collection | Fastest deserialization | Moderate | Optimized library, better performance than Apache.Avro |
| BSON | Similar to JSON | No significant gain over JSON | Similar to JSON | Moderate | No major performance advantage |
Benchmarks on modern CPUs, such as the Ryzen 3900x, show that optimized avro libraries can double throughput compared to default clients. Protobuf consistently delivers fast serialization and deserialization, especially in environments with precompiled schemas. Json, while easy to use, lags behind in speed due to its text-based nature.
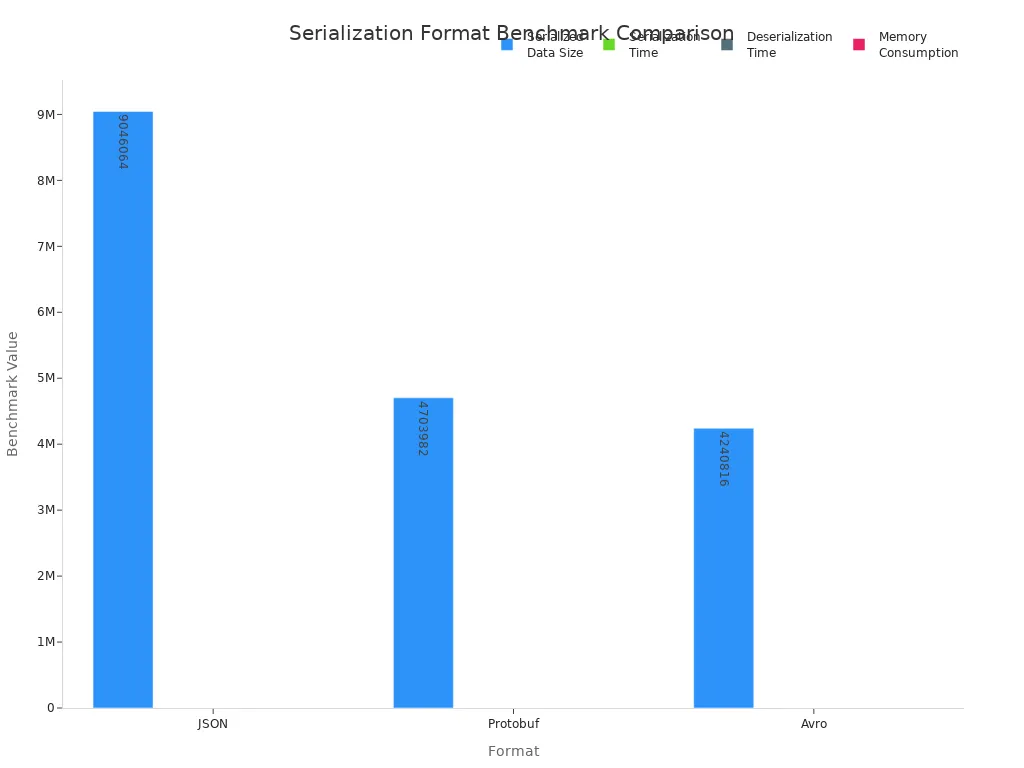
Data Size
The size of serialized data directly impacts network bandwidth and storage costs. Compact serialization formats reduce latency and improve efficiency in data pipelines.
| Format | Serialized Data Size (bytes) | Serialization Time (seconds) | Deserialization Time (seconds) | Memory Consumption (MB) | Advantages | Disadvantages |
| JSON | 9,046,064 | 0.92 | 0.34 | 40.05 | Easy to use, human-readable | Largest data size, slowest performance |
| Protobuf | 4,703,982 | 0.50 | 0.01 | 4.49 | Compact, fastest serialization and deserialization | Requires schema compilation, less readable |
| Avro | 4,240,816 | 3.40 | 47.32 | 116.79 | Most compact serialized data | Very high deserialization time, high memory use |
Avro produces the smallest size of serialized data, making it ideal for big data and streaming platforms. Protobuf also achieves a small size of serialized data, balancing speed and efficiency. Json generates the largest size of serialized data, which can slow down transmission and increase storage requirements. Developers working with ujson may see some improvements in speed, but the size of serialized data remains similar to standard json.
Memory Usage
Memory usage patterns differ significantly across formats during serialization and deserialization. Json, as a text-based format, consumes more memory due to its verbosity. Protobuf, with static typing and precompiled schemas, uses less memory and processes data faster. Avro, embedding schema information and using dynamic typing, introduces overhead and higher memory consumption, especially during deserialization.
Json is easy to read and write but less efficient in memory usage.
Protobuf uses static typing and code generation, resulting in efficient memory usage.
Avro includes embedded schema information, leading to higher memory usage and slower processing.
Developers should consider memory metrics when selecting a format for high-throughput or resource-constrained environments.
Integration and Tooling
Language Support
Language support plays a vital role in cross-platform development. Json stands out as the most widely supported serialization format, with libraries available in nearly every programming language. Its simplicity and human-readable syntax make it the default choice for many web APIs and applications.
Json offers broad compatibility and ease of use, especially in JavaScript environments.
Protobuf and Apache Thrift provide structured, compact binary formats with multi-language support. Protobuf, designed for cross-language structured data, supports C++, Java, Python, Go, and more.
Avro supports multiple languages but often requires additional tooling for schema management and code generation.
MessagePack and BSON offer alternatives with multi-language support and better performance than json.
For cross-platform projects, json ensures simplicity, while protobuf and avro deliver better performance characteristics at the cost of more complex tooling.
Ecosystem
The ecosystem and tooling around each format influence developer productivity and integration with existing systems.
Json enjoys extensive ecosystem support, with lightweight syntax and easy integration in diverse environments. However, it lacks advanced features like comments and namespaces.
Protobuf, developed by Google, provides efficient binary serialization, extensibility, and language-neutral schema definitions. Developers generate code in multiple languages, making it suitable for performance-critical applications.
Avro requires tools such as
avrogenfor class generation and integrates with schema registries for validation and compatibility. Producers and consumers use specialized serializers and deserializers, often managed through platforms like Kafka.All three formats integrate with Kafka Schema Registry, supporting schema management and data validation.
In .NET/C# environments, developers install specific NuGet packages and configure schema registries for each format, streamlining the serialization and deserialization process.
Note: The choice of data serialization tools depends on project requirements, language preferences, and the need for schema governance.
Ease of Use
Human-Readability
Human-readability remains a key factor for debugging and maintenance. Json, as a text-based format, is easy to parse and inspect manually. This makes it ideal for quick debugging, simple integrations, and external-facing APIs.
| Format | Human-Readability | Debugging & Maintenance Trade-offs | Typical Use Cases |
| JSON | Text-based, human-readable | Easy to debug and maintain due to readable format; no schema needed | APIs, front-end apps prioritizing readability |
| Protobuf | Binary, not human-readable | Harder to debug; requires schema management and compilation | Performance-critical systems, microservices |
| Avro | Binary, not human-readable | Requires schema management; schema embedded with data aids evolution | Big data pipelines, distributed data systems |
Json's human-readable nature simplifies troubleshooting and supports rapid development cycles. Protobuf and avro, as binary formats, require specialized tools for inspection and debugging.
Debugging
Debugging challenges increase with binary formats. Json allows developers to inspect data directly, reducing the need for extra tools. Protobuf and avro, however, require upfront schema definitions and compilation. Their binary nature complicates manual inspection, making debugging more difficult.
Protobuf and avro need schema management and code generation, adding setup complexity.
Json enables quick inspection and debugging without additional tooling.
The binary structure and schema dependencies of protobuf and avro introduce extra steps for troubleshooting.
Developers working with ujson benefit from faster parsing but still enjoy the same human-readable format as standard json.
Tip: For projects where debugging and maintenance speed matter, json or ujson provide clear advantages. For internal systems prioritizing compact serialization and high-speed performance, protobuf and avro offer better performance characteristics, though at the cost of more complex debugging.
Choosing a Serialization Format
Web APIs and Microservices
Developers often face critical decisions when selecting a serialization format for web APIs and microservices. The choice directly affects performance, maintainability, and interoperability. JSON remains the most popular format due to its human-readable structure and extensive ecosystem. Many APIs use JSON for client-server communication, making debugging and documentation straightforward. However, JSON can increase data size and slow down data serialization and exchange in high-throughput environments.
Protobuf and Avro offer compact binary serialization, reducing message size and improving performance. These formats support schema evolution, which is essential for APIs that change over time. Protobuf provides multi-language code generation, enabling seamless integration across diverse platforms. Avro embeds schema information with data, simplifying compatibility and versioning. Thrift also delivers efficient binary serialization but introduces a steeper learning curve and less community support.
Key criteria for choosing a format include:
Performance and efficiency: Binary formats like Protobuf and Avro excel in microservices requiring fast data processing.
Schema evolution: Protobuf and Avro support backward and forward compatibility, reducing integration risks.
Interoperability: JSON offers broad language support, while Protobuf and Avro facilitate cross-language communication.
Human-readability: JSON simplifies debugging, but binary formats require specialized tools.
Ecosystem maturity: JSON and REST APIs provide extensive tooling; Protobuf and Avro offer robust support for evolving systems.
Tip: For public APIs and rapid development, JSON is ideal. For internal microservices demanding high performance and schema management, Protobuf or Avro deliver better results.
Data Pipelines
Data pipelines rely on efficient serialization formats to handle large volumes of streaming data and complex data processing tasks. JSON and CSV often serve as entry points for data ingestion due to their simplicity and compatibility. As data moves through the pipeline, developers transition to Avro for structured streaming and schema flexibility. Avro supports schema evolution, making it suitable for distributed systems with frequent changes.
Protobuf also provides fast serialization and compact data size, supporting scalable data pipelines. During processing and storage, formats like Parquet and ORC offer efficient compression and rapid queries. Avro remains a preferred choice for streaming data and big data platforms, balancing performance and schema management.
| Serialization Format | Serialization Time (ms) | Deserialization Time (ms) |
| JSON | 10 | 15 |
| Avro | 2 | 3 |
| Protobuf | 1 | 2 |
This table demonstrates that Avro and Protobuf outperform JSON in serialization and deserialization speed, enhancing pipeline throughput and scalability.
Note: Developers should align format selection with pipeline requirements. Avro and Protobuf optimize performance and schema evolution, while JSON offers simplicity for initial ingestion.
Mobile and IoT
Mobile and IoT applications demand serialization formats that minimize data size and communication overhead. JSON provides human-readable data and broad ecosystem support, making it suitable for public APIs and simple integrations. However, JSON's verbosity can increase bandwidth usage and energy consumption, which is critical for devices with limited resources.
Protobuf and Avro deliver compact binary serialization, reducing payload size and improving efficiency. Protobuf supports schema evolution and strong versioning, essential for devices that update frequently. Avro enables dynamic schema resolution, popular in big data and streaming data scenarios. MessagePack offers another compact binary option, though it lacks robust schema evolution.
| Serialization Format | Key Considerations | Pros | Cons |
| JSON | Readability, ecosystem | Human-readable, widely supported | Verbose, slower parsing |
| Protobuf | Efficiency, schema evolution | Compact, fast, strong versioning | Requires code generation |
| Avro | Dynamic schema, big data | Compact, schema evolution | Needs tooling, not human-readable |
| MessagePack | Compactness | Binary, closer to JSON | Limited schema support |
Developers must consider encoding, decoding, and security when handling data serialization and exchange in mobile and IoT environments. Compact formats like Protobuf and Avro help reduce operational costs and extend device battery life.
Tip: For resource-constrained devices, Protobuf and Avro provide optimal performance and scalability. JSON remains useful for readable data and broad integration, but binary formats are preferred for efficiency.
Interoperability
Interoperability stands as a critical requirement for modern distributed systems. Developers must ensure that applications exchange data seamlessly across diverse platforms and programming languages. The choice of serialization format directly impacts the ability to integrate heterogeneous systems and maintain consistent communication.
JSON provides a human-readable format, which simplifies initial integration between systems. Many web APIs and front-end applications rely on json for its simplicity and broad language support. However, json lacks schema enforcement. This limitation can lead to compatibility issues when different systems interpret data structures in varying ways. Without strict typing, json may introduce errors during data exchange, especially in environments where data contracts change frequently.
Protobuf addresses these challenges by using .proto schema files. These schemas define the structure and types of data, enabling strong cross-language compatibility. Developers benefit from schema enforcement, which ensures that all parties interpret data consistently. Protobuf’s compact binary format reduces payload size and improves performance. Service-to-service communication in microservices often uses protobuf to achieve low-latency and reliable data exchange. Strict schemas help prevent integration errors and support automated code generation for multiple languages.
Avro offers schema-based serialization with built-in schema evolution. Each avro record includes its schema, allowing systems to interpret data even as schemas change over time. Avro supports forward and backward compatibility, which is essential for event-driven architectures and big data pipelines. Streaming platforms such as Kafka and analytics tools like Snowflake favor avro for its efficient data transmission and adaptability. Avro’s binary format further reduces payload size, supporting high-throughput data streaming.
Developers often adopt a hybrid approach to maximize interoperability. They use protobuf for real-time API communication, leveraging strict schemas and efficient serialization. Avro becomes the preferred choice for large-scale data streaming, where schema evolution and compatibility matter most. This strategy enforces schemas and enables cross-language data exchange, supporting integration across heterogeneous systems.
Tip: Teams should evaluate the requirements for schema enforcement, performance, and compatibility before selecting a serialization format. Combining protobuf and avro can provide robust interoperability for both service communication and data streaming.
The following list summarizes how each format supports interoperability:
json enables quick integration but risks compatibility issues due to lack of schema enforcement.
protobuf enforces schemas and supports cross-language data exchange, ideal for distributed systems.
avro embeds schemas with data and supports schema evolution, crucial for big data and streaming platforms.
Both protobuf and avro use compact binary formats, improving performance and reducing payload size.
Hybrid strategies leverage protobuf for APIs and avro for analytics, ensuring interoperability across diverse environments.
A well-chosen serialization format ensures that systems communicate reliably, maintain data integrity, and scale as requirements evolve.
Developers face important decisions when selecting serialization formats. The following table highlights the main trade-offs:
| Feature/Aspect | JSON | protobuf | avro |
| Schema Management | Schema-less, flexible | Strict, code-generated schemas | JSON-based schemas stored with data |
| Performance | Slower, larger messages | Fast, compact binary | Efficient, compact, supports evolution |
| Readability | Human-readable | Binary, needs tools | Binary, schema embedded |
| Use Cases | Rapid prototyping, APIs | Microservices, IoT | Big data, analytics, streaming |
Developers should consider the following steps:
Analyze system requirements and environment before choosing avro or protobuf.
Set up test environments to benchmark avro, protobuf, and JSON for speed and payload size.
Experiment with avro and protobuf frameworks to understand their impact on performance and maintenance.
A case study in machine learning systems showed that serialization format choice affects compatibility and maintainability. Financial, gaming, and distributed computing domains also benefit from avro and protobuf due to their schema management and performance. Future trends indicate that avro will continue to evolve for distributed systems, while protobuf will optimize for low-latency environments.
Developers should evaluate avro and protobuf in real-world scenarios, considering schema evolution, interoperability, and performance. Hands-on experimentation with avro and protobuf will help teams select the best fit for their projects.
FAQ
What is the main difference between JSON, Protobuf, and Avro?
JSON uses a human-readable text format. Protobuf and Avro use compact binary formats. Protobuf requires external schemas, while Avro embeds schemas with data. Avro excels at schema evolution. Protobuf and Avro offer better performance and smaller data sizes than JSON.
When should a developer choose Protobuf over Avro?
A developer should select Protobuf for microservices, mobile, or IoT systems that require strict schemas, fast serialization, and cross-language support. Protobuf works best in environments where schema changes are rare and performance is critical.
Does Avro support schema evolution better than Protobuf?
Yes. Avro embeds schemas with each data file and supports backward, forward, and full compatibility. Developers can add or rename fields easily. Protobuf requires careful management of field numbers and external schema files, making evolution more complex.
Is JSON still relevant for modern APIs?
JSON remains highly relevant. Many web APIs and front-end applications use JSON for its readability and broad language support. Developers prefer JSON for rapid prototyping, debugging, and public-facing APIs, despite its larger size and slower performance.
How do serialization formats impact debugging?
JSON simplifies debugging because developers can read and edit data directly. Protobuf and Avro use binary formats, which require specialized tools for inspection. These binary formats make manual debugging more challenging but improve performance.
Can developers mix serialization formats in one system?
Yes. Many teams use JSON for external APIs and Protobuf or Avro for internal communication or data pipelines. This hybrid approach leverages the strengths of each format, balancing readability, performance, and schema management.
Subscribe to my newsletter
Read articles from Community Contribution directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by