how infinite scrolling on social media actually works (and why most devs get it wrong) -2025
 Syed Muhammad Haris
Syed Muhammad Haris
I was scrolling twitter at 2am last night (as one does when you should be sleeping), and i started wondering... how the fk does this thing just keep going forever?
like seriously, i've been scrolling for what feels like hours, millions of people are posting every second, and somehow i never see the same tweet twice, never get a "loading error", never hit some weird gap where posts are missing. it just... works?
turns out there's some actually clever engineering behind this that most people (including me until recently) have no clue about, and it's one of those things that separates real production systems from the mvp prototypes most of us start with.
the obvious approach (that doesn't work)
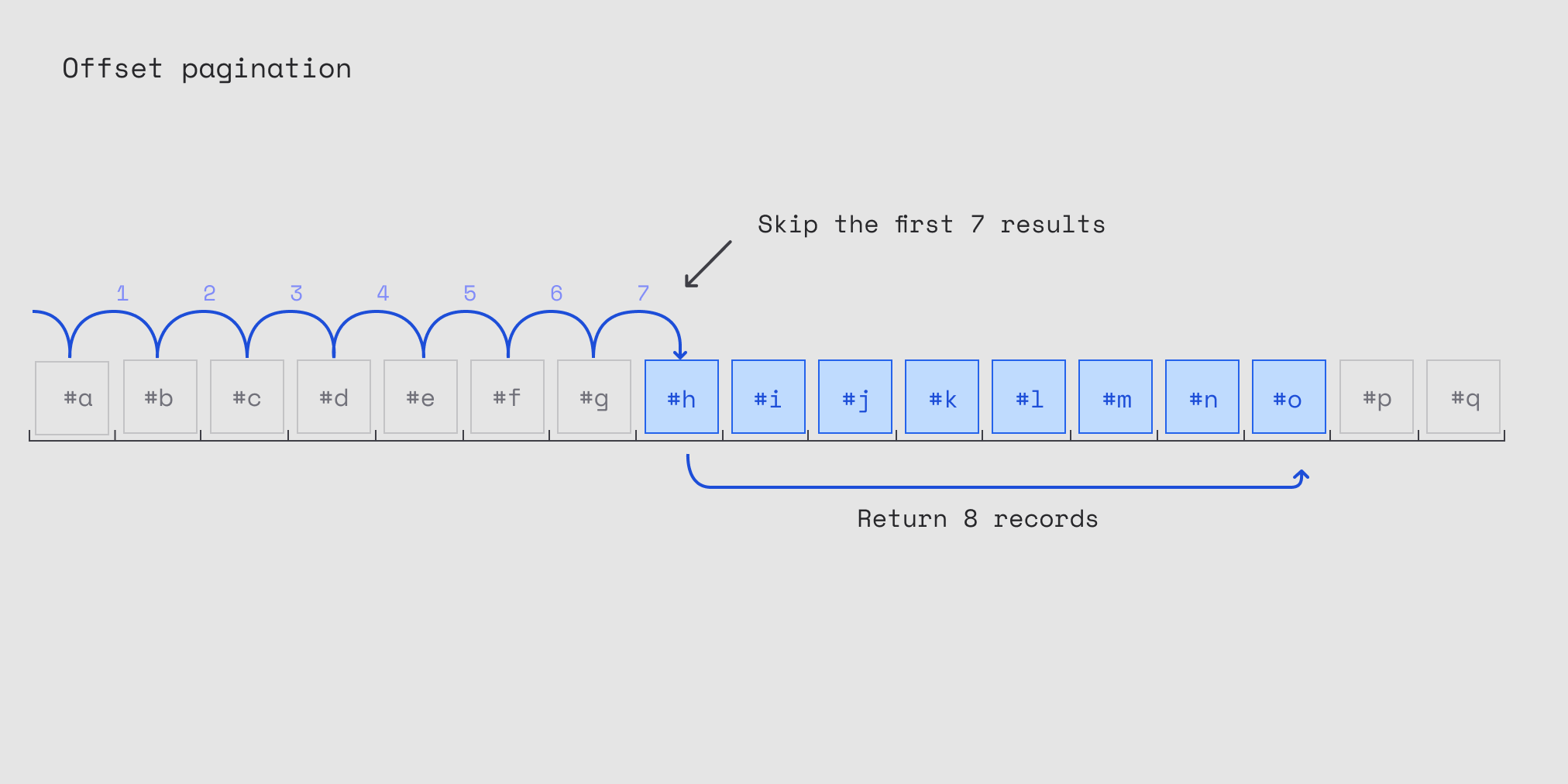
when you're building your first app with infinite scrolling, you probably do what i did - offset pagination. it's the most obvious thing in the world:
SQL
SELECT * FROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 0; -- page 1
SELECT * FROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 20; -- page 2
SELECT * FROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 40; -- page 3
works great when you have 1000 users and a few thousand posts. feels like magic when you first implement it and see that smooth scrolling action.
img by Dan Hollick
but this approach doesn't work at scale, and here's why:
performance gets worse with every page - when you're on page 1000, the database has to count through 20,000 rows just to find your starting point. it's like counting to 20,000 every time someone scrolls down.
inconsistent results - if someone posts a new tweet while you're scrolling, your offset gets messed up. you might see the same post twice or miss posts entirely. super confusing for users.
memory usage - databases hate large offsets, they literally have to load and skip all those rows in memory.
how the big players actually do it (cursor pagination)
platforms like twitter, reddit, instagram, tiktok all use something called cursor pagination instead, and it's honestly way more elegant once you understand it.
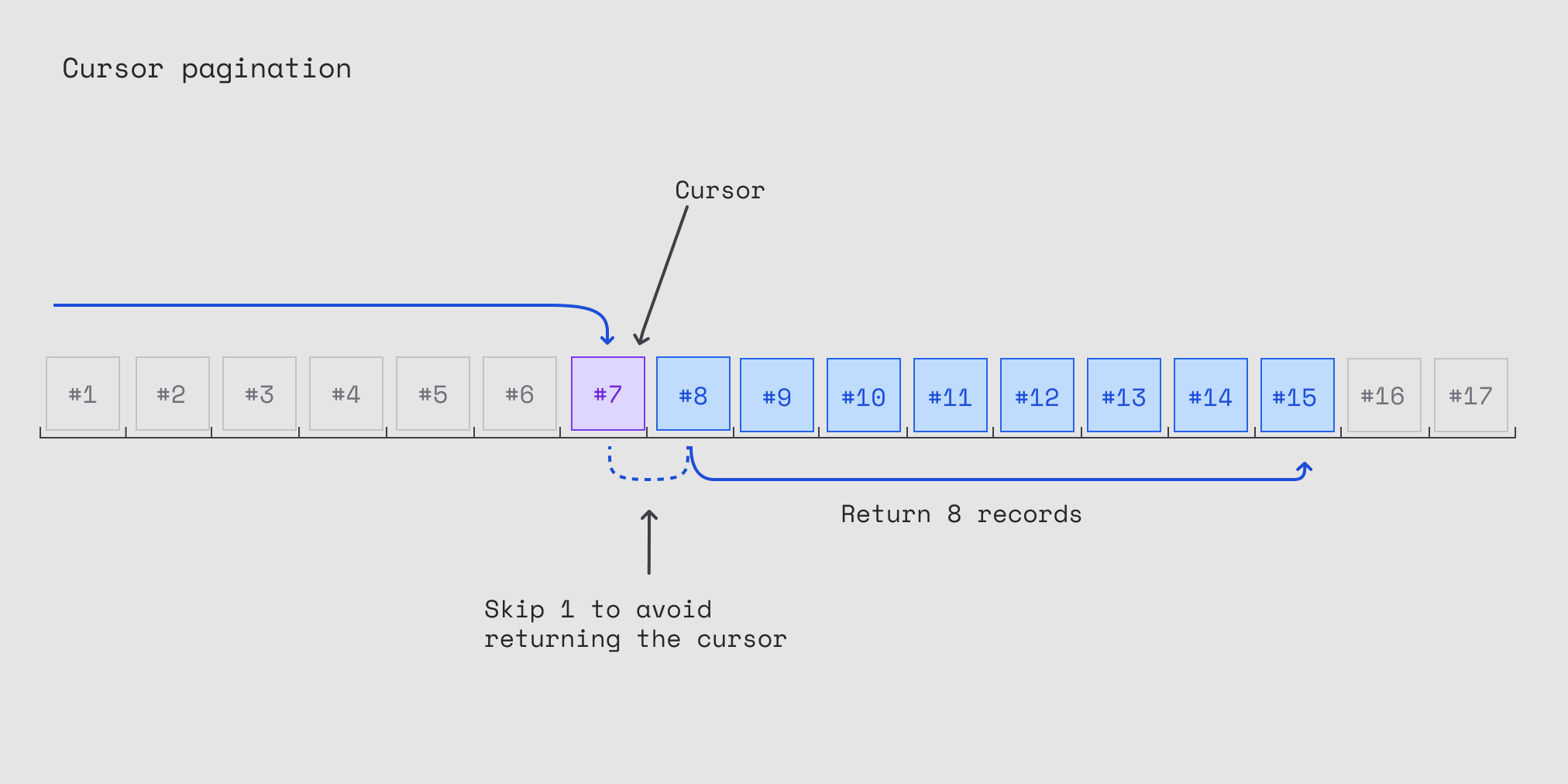
instead of saying "give me page 5", you say "give me 20 posts after this exact post id/timestamp". the api looks something like:
GET /posts?after=1692123456789&limit=20
where that after parameter is called a cursor - it's like leaving a bookmark instead of counting pages.
img by Dan Hollick
on the backend, your query becomes:
sql
SELECT * FROM posts
WHERE created_at < '2023-08-15 12:34:56'
ORDER BY created_at DESC
LIMIT 20;
this is lightning fast because:
constant time lookups - databases can jump directly to your cursor position using indexes
stable results - new posts don't affect your current scroll position
scales infinitely - doesn't matter if you have 1000 posts or 1 billion
the frontend just stores the last post's timestamp/id and uses that for the next request. boom, perfect infinite scrolling that works exactly like the big platforms.
the devil's in the implementation details but here's where it gets interesting - each platform has their own flavor of cursors depending on their needs:
twitter uses tweet ids (which are chronologically ordered snowflake ids), reddit combines score and timestamp for their ranking algorithm, instagram has to handle both chronological and algorithmic feeds.
some use opaque cursor tokens (encrypted strings that hide the implementation), others expose the actual values. some encode multiple values into a single cursor for complex sorting.
there's also edge cases like handling deleted posts, dealing with ties in timestamps, making sure cursors work across different timezones, pagination limits to prevent abuse... lot of little details that make the difference between a prototype and production-ready infinite scrolling.
what's next in this series
this is the first post in my "how shit actually works" series because i keep using these tools every day and realizing i have no idea what's happening under the hood, and apparently neither do a lot of other people.
next post i'm gonna dive deeper into cursor token implementation - how to handle complex sorting, deal with edge cases, and build cursors that actually work in production. might even show some real code examples from projects i've worked on.
building your own infinite scroll?
if you're working on something that needs this kind of functionality, honestly the jump from prototype pagination to production-ready cursor systems can be tricky. there's a lot of little details that aren't obvious until you hit scale or real user patterns.
i help founders and indie hackers turn their ideas into actual working products all the time - from mvp to scale, full-stack development, team building, all that stuff. if you're building something cool and want someone who's been through these scaling challenges before, hit me up.
anyway, that's how your favorite apps keep you scrolling forever without breaking. pretty neat engineering hidden behind something that just feels like magic.
Subscribe to my newsletter
Read articles from Syed Muhammad Haris directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Syed Muhammad Haris
Syed Muhammad Haris
As a Software Engineer extraordinaire, he's a master of creating awesome stuff for the web and mobile. But here’s the twist: Haris is not just about code; he’s about making an impact. With a knack for stats and over 3 years of experience, he’s had the honor of working with big-name clients and organizations. His toolbox? It’s packed with the latest tech goodies like MongoDB, ExpressJS, SQL Server, Node.js, React.js, Jetpack Compose, MongoDb, Firebase, AWS, Python and more