El Primer Paso - Conectando a Datos en Power Query vs. Python con Pandas
 Norman Reynaldo Sabillon Castro
Norman Reynaldo Sabillon CastroTable of contents
- Nuestro Ejemplo: Un Archivo de Geografía
- Preparando Nuestro Espacio de Trabajo: Conectando con GitHub
- El Mundo que Conocemos: Obtener Datos en Power Query
- Cruzando el Puente: Leer Datos con Python y Pandas
- Extra: Validando el Proceso en Google Colab
- Comparación Rápida: ¿Clics vs. Código?
- Preparándonos para el Cuarto Blog...

¡Bienvenido al tercer capítulo de "El Puente al Machine Learning"!
En el post anterior, instalamos nuestro laboratorio de ciencia de datos. Ahora que tienes tu entorno listo, es hora de hacer lo que mejor sabemos hacer: conectarnos a un origen de datos.
Recuerdo la primera vez que tuve que importar un archivo de texto plano (.txt) con un formato algo extraño en Power BI. Tuve que pasar por varias ventanas de configuración, probando delimitadores hasta que finalmente di con el correcto. Funcionó, pero me dejó pensando: ¿habrá una forma más directa y reproducible de hacerlo?
Hoy te mostraré que la hay. Vamos a comparar, cara a cara, cómo se realiza esta tarea fundamental en nuestro mundo conocido de Power Query y en nuestro nuevo taller de Python.
Nuestro Ejemplo: Un Archivo de Geografía
Para nuestro ejercicio, vamos a usar un archivo de datos geográficos de Honduras llamado Geografia.txt, que he alojado en el repositorio de GitHub del blog. Es un ejemplo realista del tipo de datos con los que trabajamos en BI.
Preparando Nuestro Espacio de Trabajo: Conectando con GitHub
Antes de leer los datos, vamos a traerlos a nuestro entorno local. En lugar de descargar el archivo manualmente, clonaremos el repositorio completo. Esto nos asegura tener siempre la versión más actualizada de los datos y el código.
Paso 0: ¡Requisito Previo! Instalar Git
Para poder clonar el repositorio, necesitamos una herramienta fundamental llamada Git. Si al intentar el siguiente paso te aparece un error como 'git' is not recognized as an internal or external command, significa que no lo tienes.
Puedes instalarlo fácilmente desde su página oficial: git-scm.com/download/win. Simplemente descarga el instalador y haz clic en "Next" en todas las ventanas, aceptando la configuración por defecto. Una vez instalado, es muy importante que cierres y vuelvas a abrir tu Anaconda Prompt.
Paso 1: Clonar el Repositorio
Ahora sí, abre tu Anaconda Prompt (¡no uses PowerShell ni el CMD normal!), navega a la carpeta donde guardas tus proyectos (usando el comando cd), y ejecuta el siguiente comando:
git clone https://github.com/NORSAB/El-Puente-al-Machine-Learning.git
Este comando creará una nueva carpeta llamada El-Puente-al-Machine-Learning en tu computadora con todos los archivos del repositorio.
Pro Tip: Si la carpeta
El-Puente-al-Machine-Learningya existe de un intento anterior, el comandogit clonete dará un error. Simplemente borra la carpeta existente y vuelve a intentarlo.
Paso 2: Navegar al Directorio y Abrir Jupyter Lab
Una vez clonado, desde la misma Anaconda Prompt, navega dentro de la nueva carpeta. Si clonaste el repositorio directamente en tu disco C:\, el comando sería:
cd C:\El-Puente-al-Machine-Learning
Ahora, activa el entorno que creamos en el post anterior:
conda activate mi_entorno_ml
Y desde ahí, lanza Jupyter Lab:
jupyter lab
Esto abrirá Jupyter en tu navegador, con acceso directo a todas las carpetas y archivos del proyecto.
Paso 3 (Opcional): Crear un Atajo Inteligente para Automatizar Todo
Para no tener que escribir estos comandos cada vez, podemos crear un script .bat que haga todo por nosotros: verificará que todo esté correcto, actualizará el repositorio y lanzará Jupyter Lab.
- Abre el Bloc de Notas.
- Copia y pega el siguiente código:
@echo off
:: Cambiar a UTF-8 para mostrar bien acentos y caracteres del español
chcp 65001 >nul
cls
echo ===================================================
echo CHECKLIST: Requisitos para El Puente al ML
echo ===================================================
echo.
:: === 1. Verificar si git está instalado ===
echo [1/4] Verificando Git...
where git >nul 2>&1
if %errorlevel% equ 0 (
echo ✓ Git encontrado
) else (
echo ✗ ERROR: Git no está instalado o no está en el PATH.
echo Descarga Git desde: [https://git-scm.com](https://git-scm.com)
echo.
pause
exit /b 1
)
:: === 2. Detectar e inicializar conda ===
echo [2/4] Buscando instalación de Anaconda/Miniconda...
set "CONDA_PATH="
if exist "%USERPROFILE%\Anaconda3\Scripts\activate.bat" set "CONDA_PATH=%USERPROFILE%\Anaconda3"
if exist "%USERPROFILE%\Miniconda3\Scripts\activate.bat" set "CONDA_PATH=%USERPROFILE%\Miniconda3"
if exist "C:\ProgramData\Anaconda3\Scripts\activate.bat" set "CONDA_PATH=C:\ProgramData\Anaconda3"
if exist "C:\ProgramData\Miniconda3\Scripts\activate.bat" set "CONDA_PATH=C:\ProgramData\Miniconda3"
if defined CONDA_PATH (
echo ✓ Conda encontrado en: %CONDA_PATH%
call "%CONDA_PATH%\Scripts\activate.bat"
) else (
echo ✗ ERROR: No se encontró Anaconda ni Miniconda.
echo Asegúrate de tenerlo instalado en la ruta por defecto.
echo Descarga desde: [https://www.anaconda.com](https://www.anaconda.com) o [https://docs.conda.io/en/latest/miniconda.html](https://docs.conda.io/en/latest/miniconda.html)
echo.
pause
exit /b 1
)
:: === 3. Verificar entorno ===
echo [3/4] Verificando entorno 'mi_entorno_ml'...
call conda env list | findstr /C:"mi_entorno_ml" >nul 2>&1
if %errorlevel% equ 0 (
echo ✓ Entorno 'mi_entorno_ml' encontrado
) else (
echo ✗ ERROR: El entorno 'mi_entorno_ml' no existe.
echo Por favor, créalo siguiendo las instrucciones del post anterior.
echo.
pause
exit /b 1
)
:: === 4. Verificar Jupyter Lab ===
echo [4/4] Verificando Jupyter Lab en el entorno...
call conda list -n mi_entorno_ml | findstr /C:"jupyterlab" >nul 2>&1
if %errorlevel% equ 0 (
echo ✓ Jupyter Lab encontrado en el entorno.
) else (
echo ✗ ADVERTENCIA: Jupyter Lab no está instalado en 'mi_entorno_ml'.
echo Instálalo con: conda install -n mi_entorno_ml jupyterlab
echo.
pause
)
echo.
echo ===================================================
echo ✅ Todos los requisitos están listos
echo ===================================================
echo.
timeout /t 3 >nul
:: === Flujo principal ===
cd /d C:\
echo Buscando carpeta del repositorio...
IF NOT EXIST "El-Puente-al-Machine-Learning" (
echo Carpeta no encontrada. Clonando repositorio...
git clone [https://github.com/NORSAB/El-Puente-al-Machine-Learning.git](https://github.com/NORSAB/El-Puente-al-Machine-Learning.git)
if %errorlevel% neq 0 (
echo ERROR: No se pudo clonar el repositorio.
pause
exit /b %errorlevel%
)
goto :iniciar
)
cd El-Puente-al-Machine-Learning
echo Actualizando repositorio...
git pull
:iniciar
echo Activando entorno y lanzando Jupyter Lab...
call conda activate mi_entorno_ml
if %errorlevel% neq 0 (
echo ERROR: No se pudo activar el entorno 'mi_entorno_ml'.
pause
exit /b 1
)
start "" jupyter-lab
exit /b 0
- Guarda el archivo en tu Escritorio con el nombre
Abrir_Mi_Laboratorio.bat. - ¡Listo! Ahora, cada vez que hagas doble clic en este archivo, se verificará todo, se actualizará el repositorio y se abrirá Jupyter Lab automáticamente.
Nota para usuarios de macOS/Linux: Este script
.bates solo para Windows. Si usas macOS o Linux, puedes crear un script.shequivalente con comandos similares (por ejemplo,source activate mi_entorno_ml). O, para mayor simplicidad, ¡siempre puedes usar Google Colab!Nota importante: Si el script te indica que el entorno
mi_entorno_mlno existe, significa que te saltaste un paso. ¡No te preocupes! Simplemente regresa a mi publicación de la semana pasada donde te explico cómo crearlo: ¡Manos a la Obra! Instalando tu Kit de Herramientas de Machine Learning
El Mundo que Conocemos: Obtener Datos en Power Query
En Power BI, el proceso para un archivo de texto delimitado es casi idéntico al de un CSV:
- Abrir Power BI Desktop.
- Hacer clic en "Obtener datos" y seleccionar "Texto/CSV".
- Navegar hasta nuestro archivo
Geografia.txt(dentro de la carpetadatosque acabamos de clonar) y seleccionarlo.
Al hacerlo, Power BI nos presenta una ventana de previsualización muy útil.
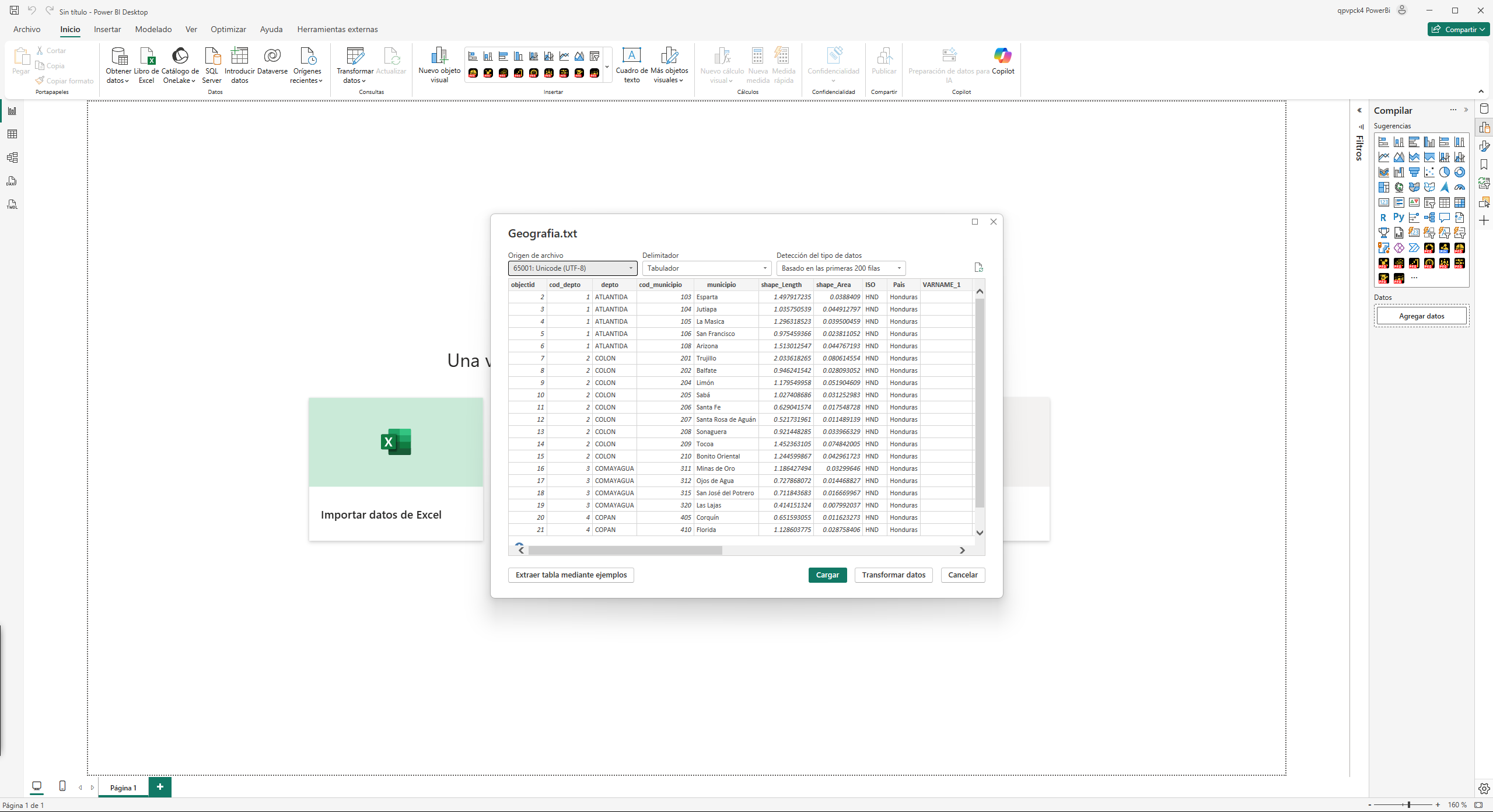
Como vemos en la imagen, aunque Power BI detecta automáticamente el formato, nos da un control total. Podemos cambiar el Origen del archivo (la codificación), el Delimitador (en este caso, detectó correctamente la tabulación) y decidir en cuántas filas se basa la detección del tipo de datos.
Una vez que estamos conformes, hacemos clic en "Transformar datos" y ya tenemos nuestra tabla en el Editor de Power Query.
Cruzando el Puente: Leer Datos con Python y Pandas
Ahora, vamos a traducir esa misma acción en nuestro Jupyter Lab. Te recomiendo que crees tu propio notebook desde cero dentro de la carpeta notebooks para que practiques, pero si prefieres ir directo al resultado, he dejado el notebook completo de este capítulo listo para que lo explores.
Paso 1: Importar la Librería Pandas
import pandas as pd
Le damos el alias pd por convención, para no tener que escribir "pandas" cada vez.
Paso 2: Leer el Archivo de Texto (Delimitado por Tabulaciones)
Como nuestro notebook está en la carpeta notebooks, necesitamos "subir un nivel" para encontrar la carpeta datos. Por eso usamos ../ en la ruta.
# Especificamos la ruta al archivo subiendo un nivel ('../')
ruta_archivo = '../datos/Geografia.txt'
# Usamos la función read_csv, especificando que el separador es una tabulación ('\t')
# Esto es clave, ya que le decimos a Pandas cómo están divididas nuestras columnas.
df = pd.read_csv(ruta_archivo, sep='\t')
Pro Tip para datos en español: Si al cargar tus datos ves caracteres extraños en lugar de acentos o la 'ñ', es un problema de codificación. Puedes solucionarlo añadiendo el parámetro
encoding, similar a la opción "Origen del archivo" en Power BI. Prueba conencoding='utf-8'oencoding='latin-1'.df = pd.read_csv(ruta_archivo, sep='\t', encoding='utf-8')
Paso 3: Visualizar los Datos
Para ver las primeras filas de nuestra tabla, similar a la vista previa de Power BI, usamos el método .head().
# Mostramos las primeras 5 filas de nuestro DataFrame
df.head()
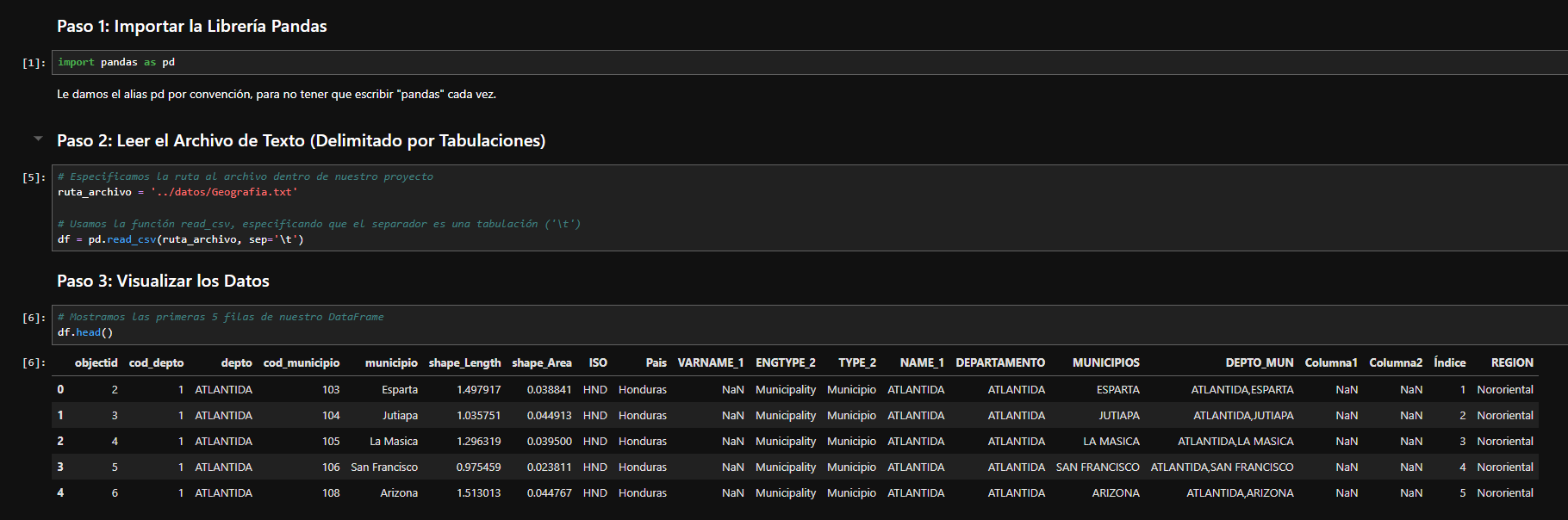
¡Y eso es todo! Hemos importado nuestros datos directamente desde la estructura de nuestro proyecto en GitHub.
Extra: Validando el Proceso en Google Colab
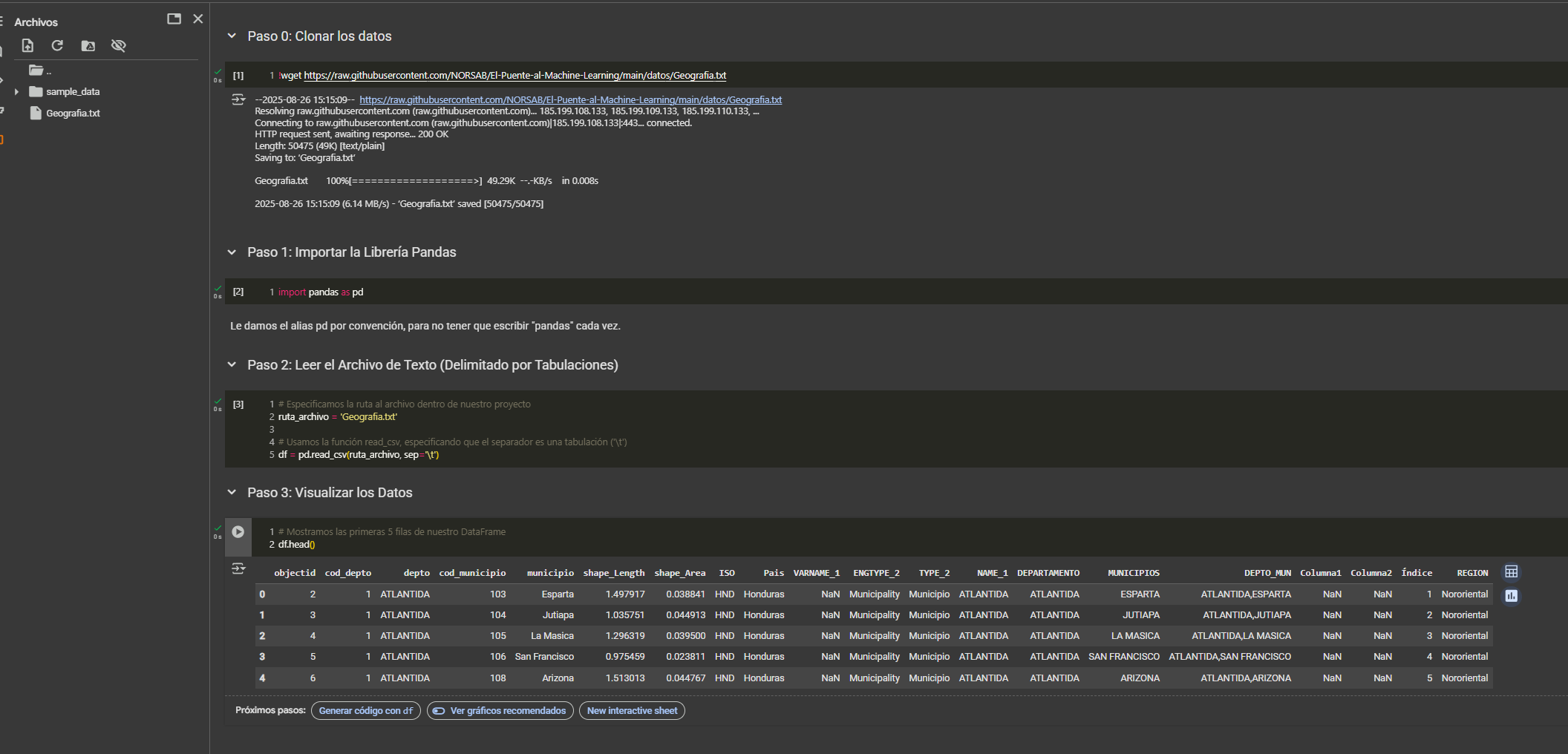
Para los usuarios de macOS, Linux, o cualquiera que prefiera un entorno en la nube, ¡este mismo proceso funciona a la perfección en Google Colab!
He preparado un notebook público que puedes ejecutar con un solo clic. Este notebook clona los datos directamente desde nuestro repositorio de GitHub y ejecuta los mismos pasos que acabamos de ver, validando que el proceso es 100% reproducible.
➡️ Haz clic aquí para ejecutar el notebook interactivamente en Google Colab
Comparación Rápida: ¿Clics vs. Código?
| Característica | Power Query (Power BI) | Pandas (Python) |
| Interfaz | Gráfica y visual (GUI) | Basada en código |
| Curva de Aprendizaje | Baja, muy intuitiva al inicio | Moderada, requiere aprender sintaxis |
| Flexibilidad | Alta, pero limitada a sus conectores | Extrema, puedes conectar a casi cualquier cosa |
| Reproducibilidad | Buena, los pasos se guardan | Perfecta, el código es la receta exacta |
Preparándonos para el Cuarto Blog...
Ahora que hemos abierto la puerta y cargado nuestros datos en un DataFrame, el siguiente paso es empezar a explorarlos y limpiarlos.
Si en Power Query tu siguiente clic sería "Quitar columnas", "Filtrar filas" o "Remover valores", en nuestro próximo capítulo te mostraré cómo hacer exactamente esas mismas transformaciones en Pandas. Tomaremos nuestro DataFrame de Geografía y aprenderemos a replicar tres de las operaciones más comunes de Power Query: Seleccionar Columnas, Filtrar por una Región y Cambiar el Nombre de una Columna.
Verás que, una vez más, es solo cuestión de traducir tus conocimientos. ¡Prepárate para la verdadera magia de la limpieza de datos con código! 🚀
¡Ahora te toca a ti! ¿Prefieres la interfaz gráfica de Power Query o la flexibilidad del código de Pandas para conectar a tus datos? ¡Cuéntame por qué en los comentarios!
#MachineLearning #BItoML #Pandas #PowerQuery #Python #DataScience #CienciaDeDatos #Español #Tutorial #GitHub #PowerBI #Tableau #DatosGeograficos #HondurasDatos #DataCleaning
Subscribe to my newsletter
Read articles from Norman Reynaldo Sabillon Castro directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Norman Reynaldo Sabillon Castro
Norman Reynaldo Sabillon Castro
Soy un consultor de Business Intelligence con más de 7 años de experiencia transformando datos en decisiones estratégicas con Power BI y Tableau. He capacitado a más de 500 profesionales, pero mi curiosidad me llevó al siguiente nivel: no solo reportar el pasado, sino predecir el futuro. Actualmente, estoy cursando una maestría en Big Data y especializándome como Ingeniero de Machine Learning. Este blog es mi bitácora y mi guía para profesionales de datos que, como yo, buscan cruzar el puente del análisis de negocios al aprendizaje automático. ¡Vamos a construir el futuro de los datos juntos!