System Design 101 : Scale from Zero to Millions of Users
 Raghav Shukla
Raghav Shukla
In the past three years, I’ve mostly worked with startups, and the common approach was always “build fast, optimize later.” It definitely helped us move quickly, but when the user base started growing, we ran into scaling issues that were tough to handle in production.
That’s when I realized—it’s not about choosing between speed and scale. The real trick is finding a balance: shipping fast while also putting just enough foundation in place so the system can handle growth. After all, every startup dreams of reaching a million users, and being a little prepared early makes the ride much smoother.
Recently, while learning more about system design and reading the ByteByteGo book, I picked up a few lessons that I think are worth sharing.
Single Server Setup
To keep things simple, we’ll start by running everything on a single server. When a user accesses the website by entering a domain name like raghavdev.in, the DNS server returns the corresponding IP address. Once the IP is received, the browser sends an HTTP request to our server, which then responds with either HTML or JSON for rendering. This forms the initial setup of our system.
This is how the initial setup will look like.
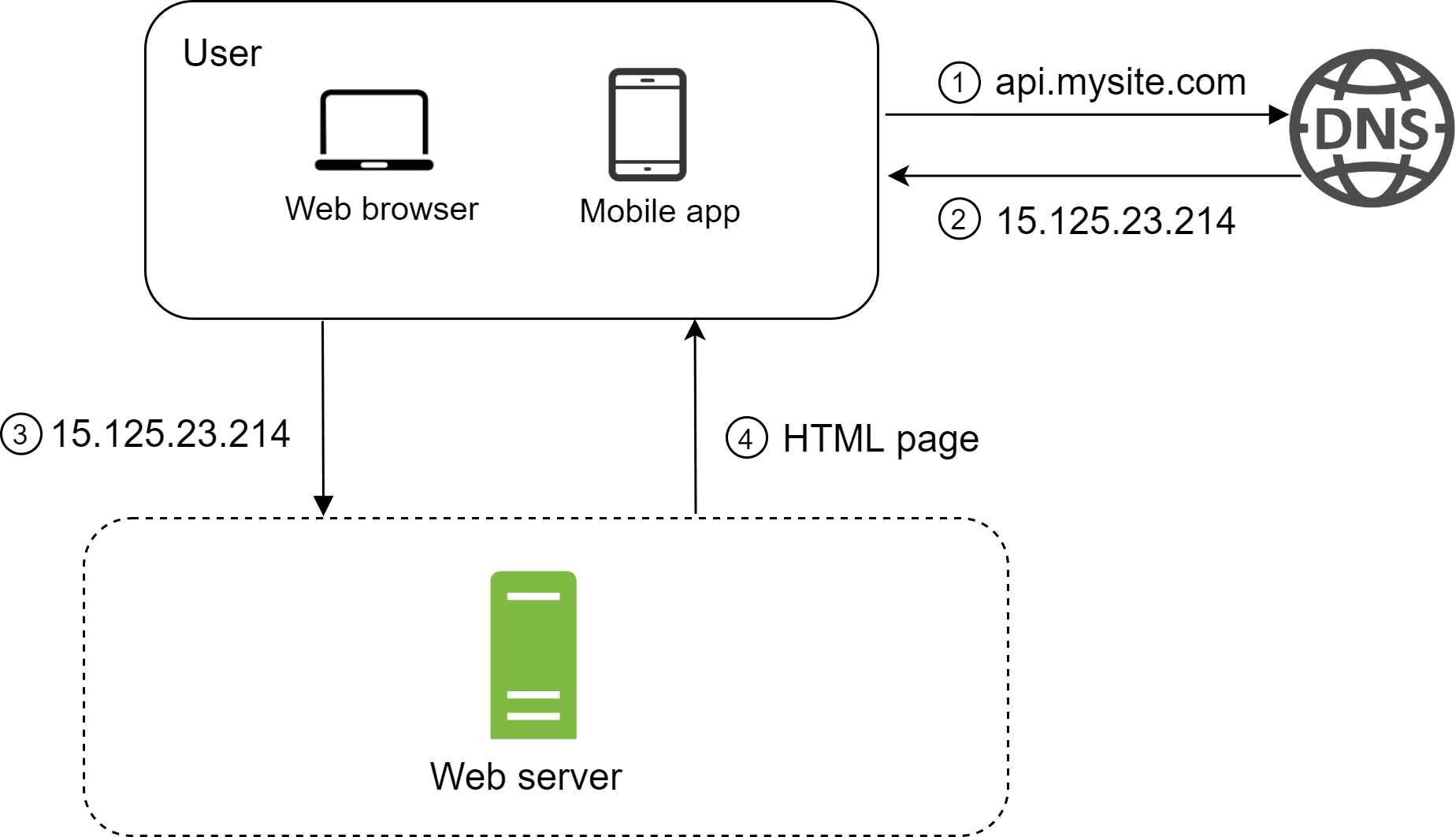
Database
As we discussed earlier, the single server setup works well in the beginning, but it quickly becomes a limitation once the user base starts growing. To scale more effectively, we need to separate the web server and the database so that each can grow independently.
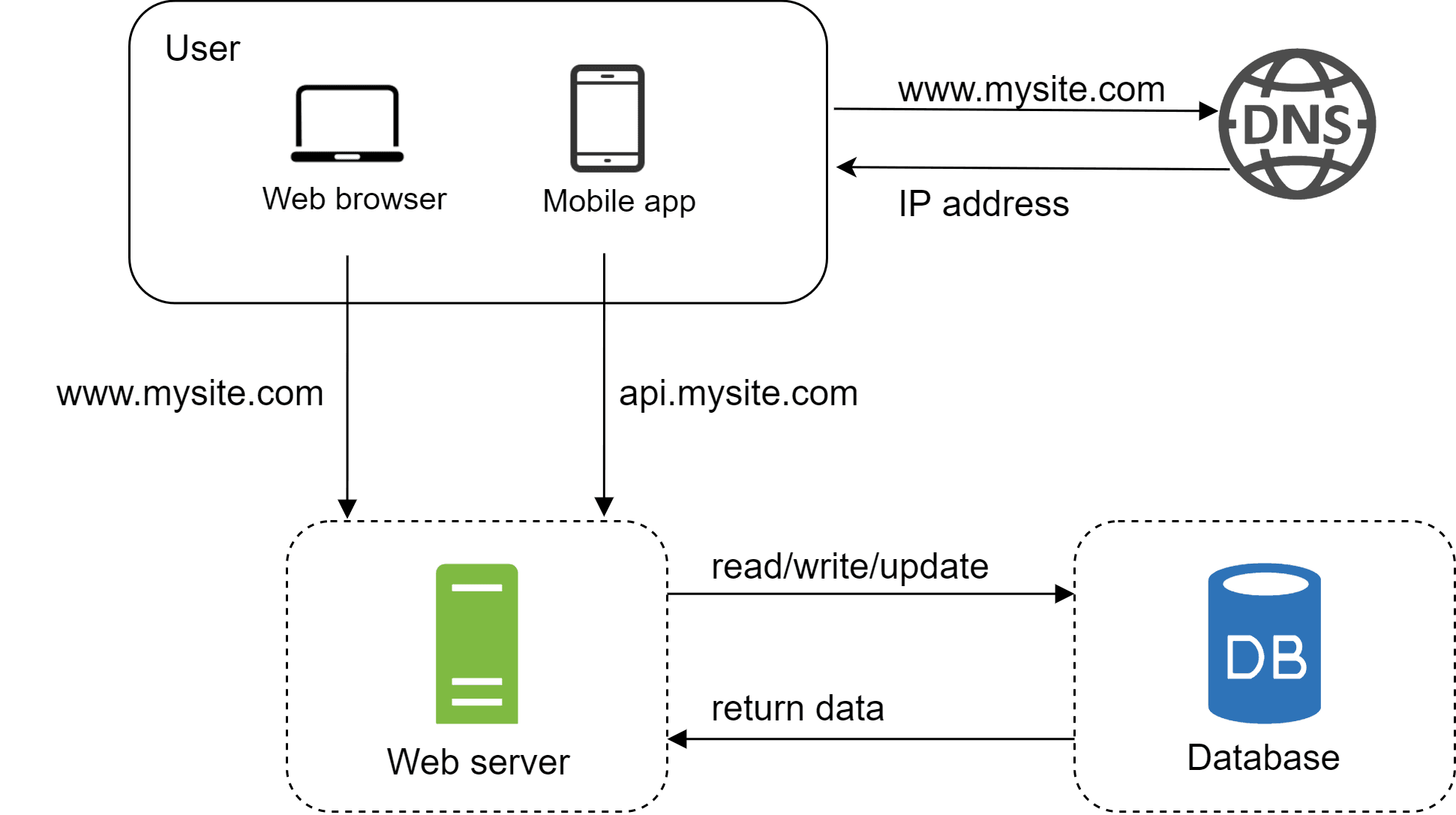
Now big question arises
Which Database to choose?
Basically there are 2 types of database :
SQL (Relational Databases) → Store data in tables with rows and columns. Popular examples are MySQL and PostgreSQL.
NoSQL (Non-Relational Databases) → Store data in more flexible formats like key-value pairs, documents, graphs, or columns. Examples include MongoDB, Cassandra, Neo4j, CouchDB, and Amazon DynamoDB.
The right choice depends on the project’s requirements, and in many cases, teams even combine multiple databases to meet different use cases.
Load Balancer
Now that the web server and database are separated, a new problem arises when many users access the website at the same time. Once the server limit is reached, responses slow down, which is something we don’t want. To handle this, we add a Load Balancer that evenly distributes incoming traffic across multiple servers.
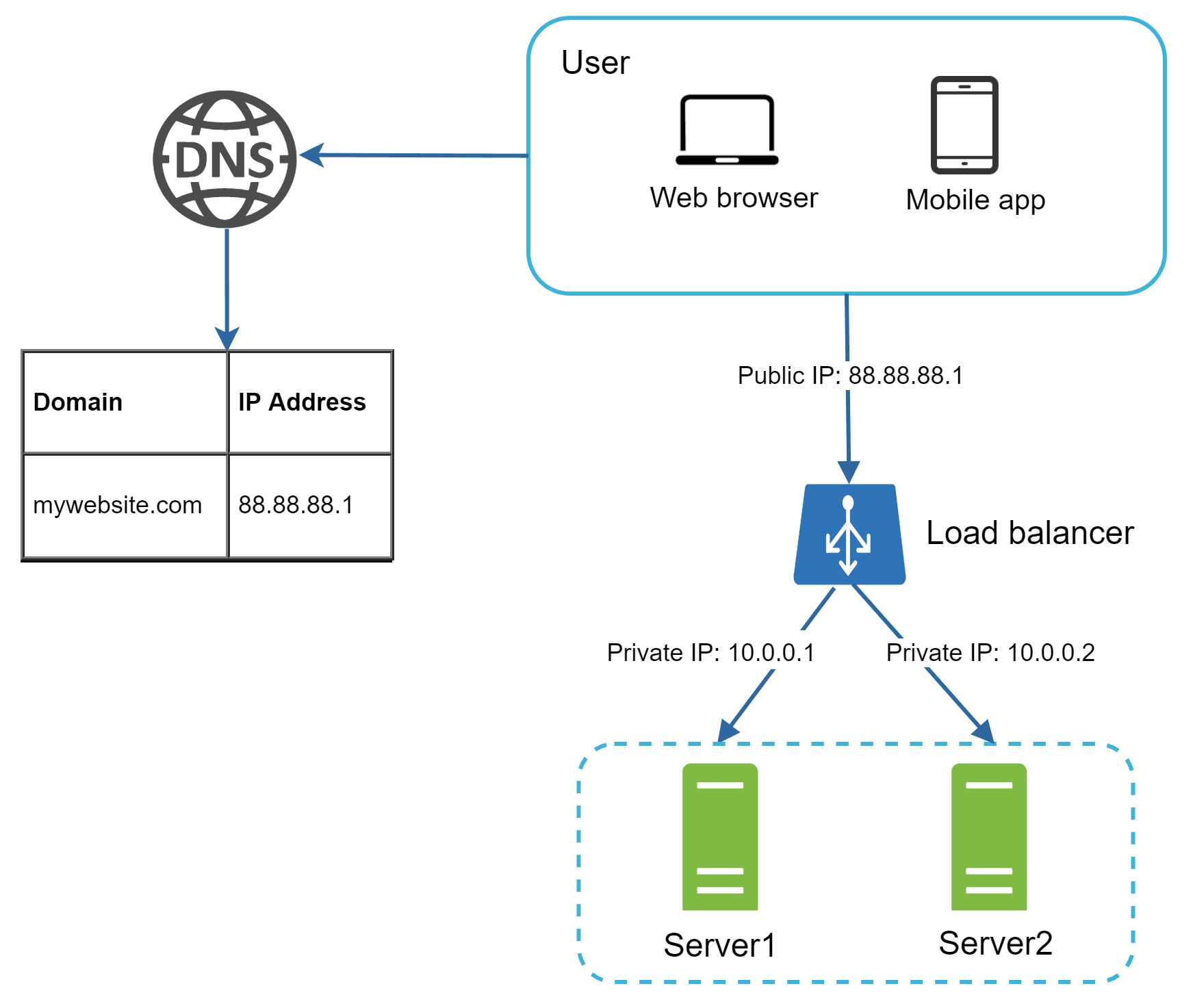
Now the users connect only to the Load Balancer (public IP) and not directly to the servers. It communicates with the web servers through private IPs within the same network, making the servers unreachable from outside.
A Load Balancer also prevents downtime if one server goes offline. If Server 1 fails, all requests are automatically redirected to Server 2, ensuring users don’t face interruptions.As traffic grows, we can keep adding more servers, and the load balancer will use its algorithm to distribute requests evenly among them. This makes the system both scalable and highly available.
Database Replication
With the Load Balancer in place, we solved the issue of servers going offline. But what if the same thing happens to our database? A single database failure would still bring the whole system down, which we need to avoid.
To keep the database safe, we can use Database Replication, where databases follow a master–slave relationship. The Master DB holds the original data and handles all write operations (insert, update, delete), while the Slave DBs maintain copies of that data and serve read operations. Since most systems perform more reads than writes, the number of slave databases is usually greater than the number of masters.
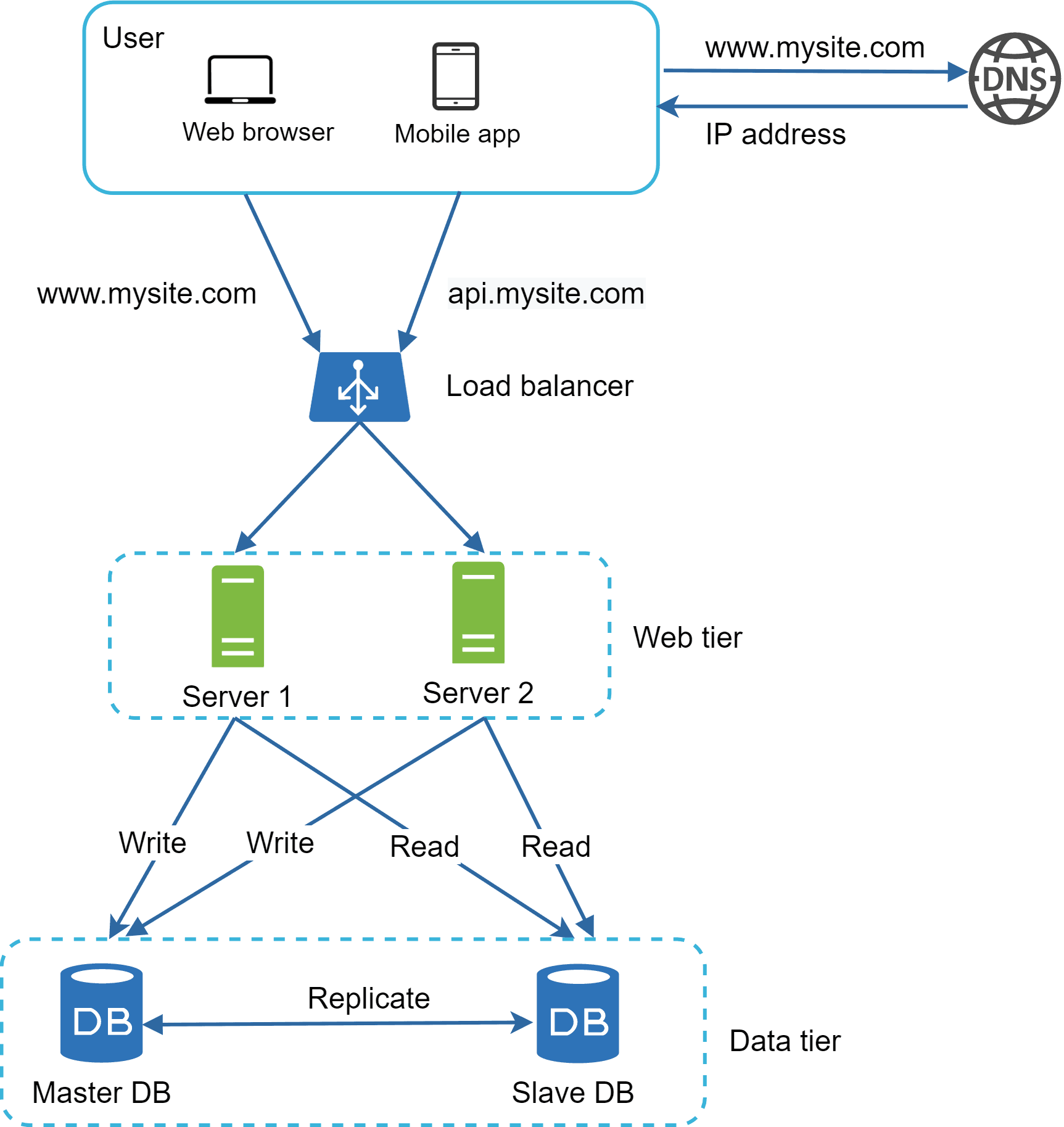
As we discussed earlier, the Load Balancer improves system availability for servers, and replication does the same for databases. If a Slave DB goes offline, the reads can temporarily go to the master, and if the Master DB fails, one of the slaves can be promoted to master so the system continues to run without downtime.
Cache
By now we’ve achieved good availability, but the next challenge is improving response time. To do this, we add a caching layer on top of the database. A cache is a high-speed storage layer that keeps frequently accessed or recently used data so it can be served much faster than fetching it directly from the database, disk, or an external API.

When a request comes in, the web server first checks the cache. If the data is found, it’s returned immediately; if not, the server fetches it from the database, stores it in the cache, and then sends it to the client. This is called a read-through cache. Depending on the use case, different caching strategies can be applied, and we can store things like JSON responses, JS files, or other static content to speed up performance.
When to use caching ?
Frequent Reads – The same data is requested repeatedly, so caching avoids recomputing or re-fetching it.
Slow Data Source – The original source (like a database, disk, or external API) is slower than memory, so caching speeds things up.
High Latency – If accessing the main source takes noticeable time, caching reduces response times.
Performance Improvement – By serving data from cache, you reduce load on the server or database.
Cost Efficiency – If data queries or API calls are expensive, caching lowers usage and costs.
Content delivery network (CDN)
A CDN is a global network of servers that cache and deliver static content like images, CSS, JS, or videos. Instead of always fetching files from the origin server, users get them from the nearest CDN server, which makes websites load much faster. For example, a user in Delhi will get content quicker from a Mumbai CDN server than from one in the US.
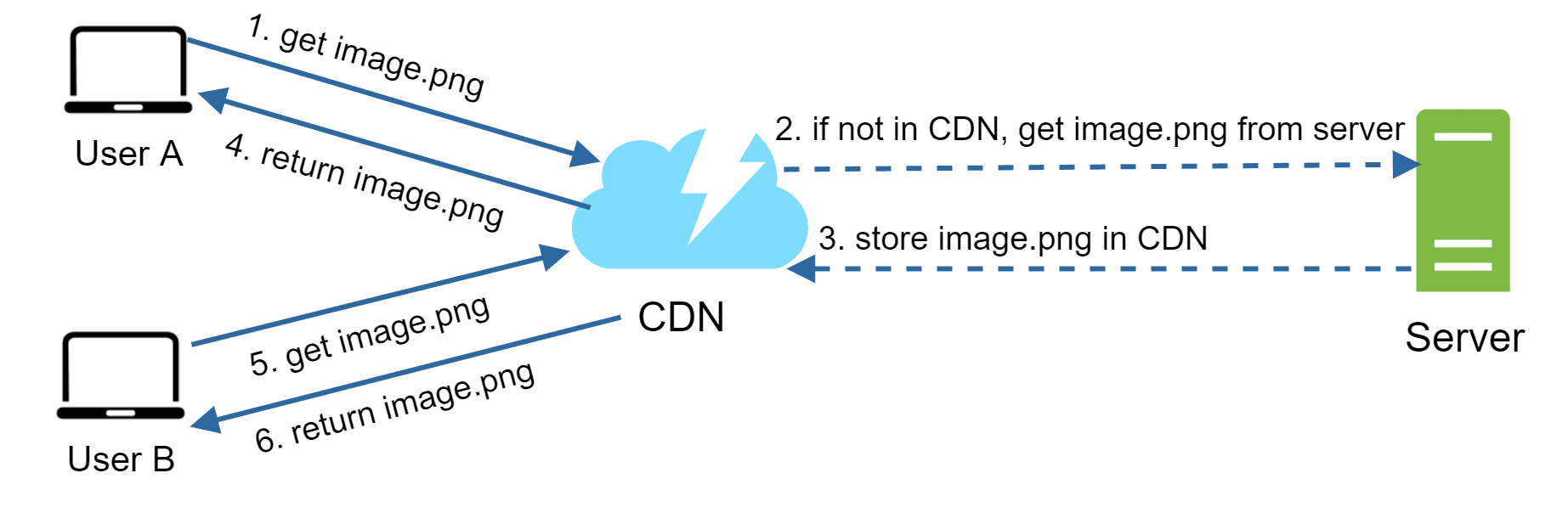
User Request – User A requests an image via a CDN URL (e.g., CloudFront or Akamai).
Cache Miss – If the CDN doesn’t have it, it fetches the file from the origin server/storage (e.g., Amazon S3).
Origin Response – The origin sends the file with a TTL (how long it should stay cached).
CDN Cache – The CDN stores the file and delivers it to User A.
Another Request – User B requests the same image.
Cache Hit – The CDN serves the image directly from its cache (until TTL expires).
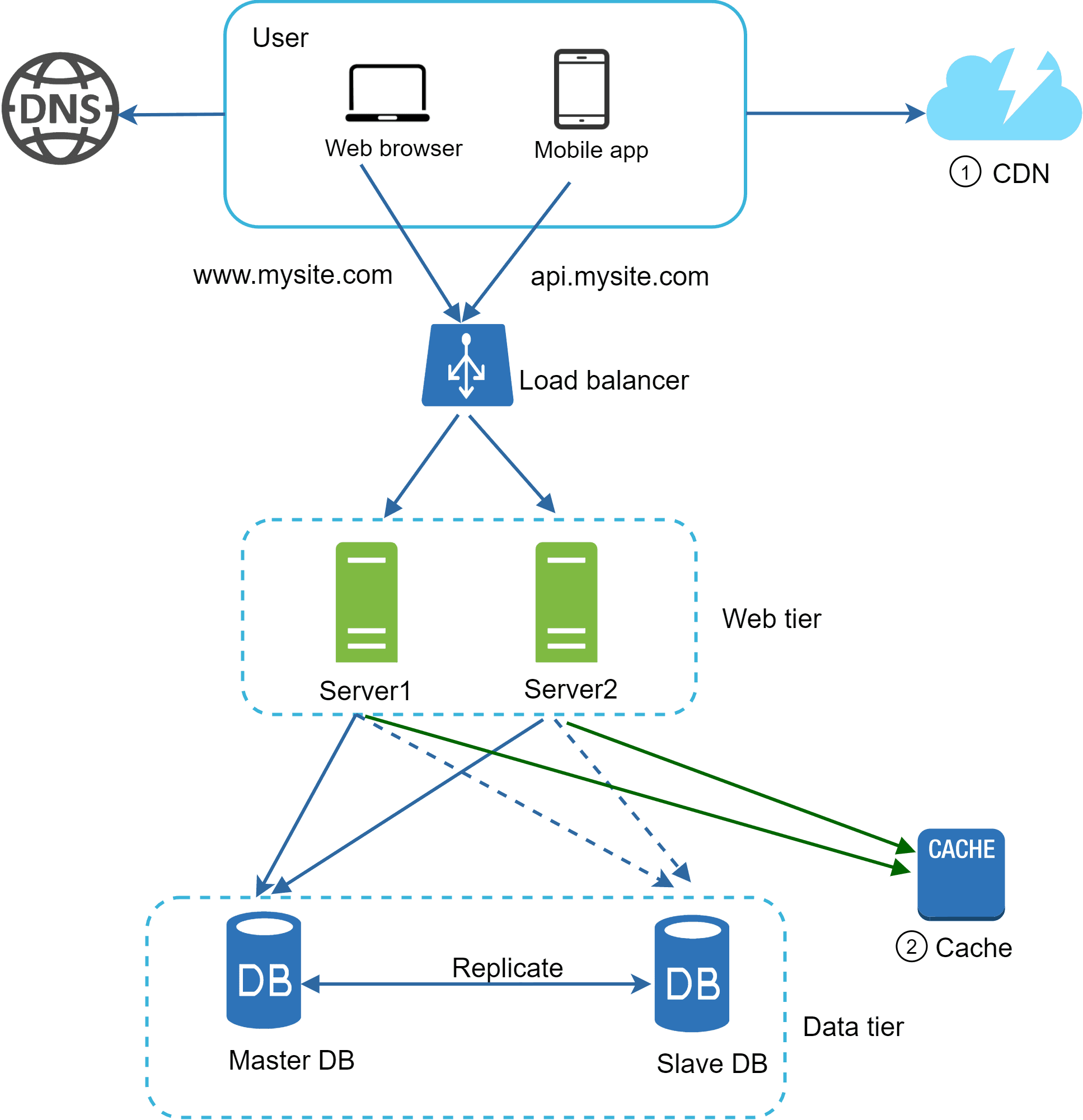
Stateless Architecture
In a stateful architecture, the server remembers client data from one request to the next. For example, in an online banking system, the server keeps track of your session—like login details, account info, and transactions—across multiple steps. While in stateless architecture the HTTP request can be shared to any of the server and it will not maintain the cleint data.
By moving state data out of the web servers, we make auto-scaling much easier. Now, servers can be added or removed based on traffic load without worrying about losing session data, making the system more flexible and scalable.
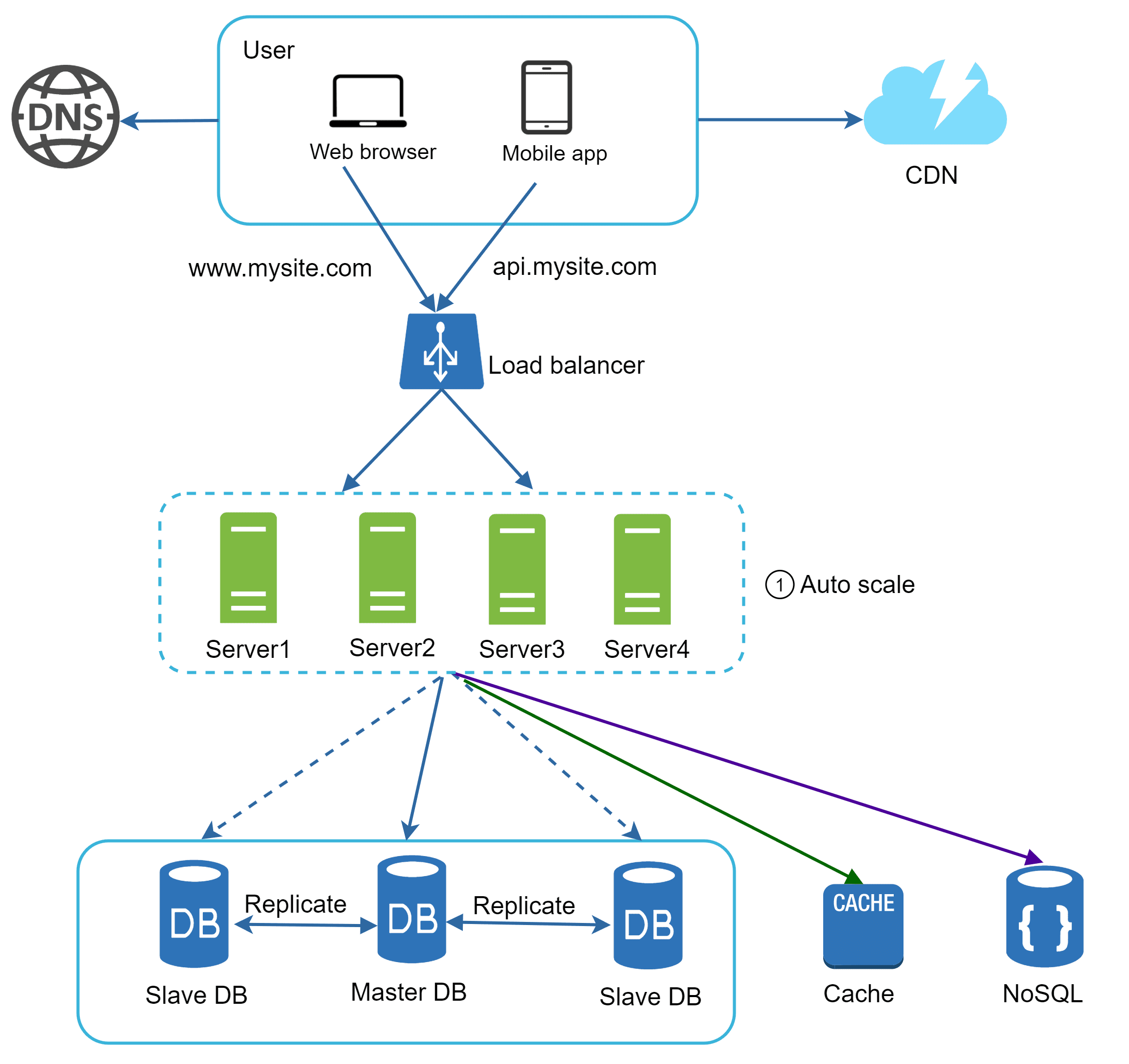
Data Centers
As the user base grows globally, a single server location is no longer enough. To reduce latency, we add multiple data centers around the world. Suppose a website has Data Center 1 in Mumbai and Data Center 2 in New York.
A user in Delhi is routed to the Mumbai data center → faster response.
A user in San Francisco is routed to the New York data center.
When a user request comes in, it flows through DNS, then to the nearest CDN, and finally reaches the Load Balancer, which uses geo-routing to direct it to the closest data center. Inside, the web servers work with caches and databases to serve the response. If one data center fails, traffic is automatically rerouted to a healthy one, while data synchronization ensures consistency across all centers.

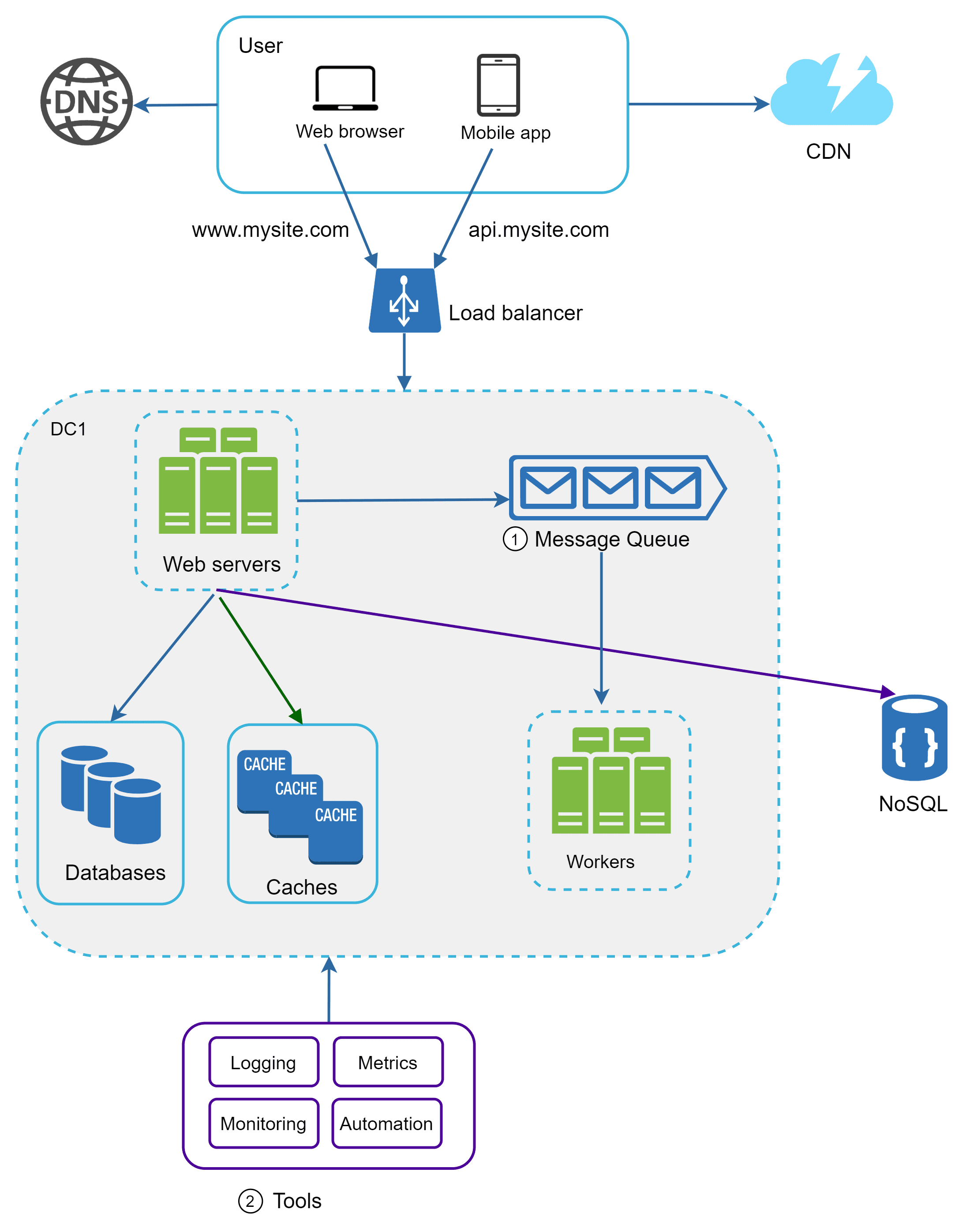
Message Queues
A Message Queue is a system that stores messages and lets services communicate asynchronously. It helps decouple producers and consumers, making applications more scalable and reliable, since messages can still be processed even if one side is temporarily unavailable. Producers publish messages to the queue, and consumers pick them up whenever they’re ready to process them.

A message queue is like a waiting line where tasks (messages) are stored until someone picks them up.Ex: When we place an order on an e-commerce platform, the inventory update and report generation don’t happen instantly but are handled in background queues.
Logs , Metrics , Automation
As our website is grown now and we need to invest in logging and metrics
Logging → Keeps a record of what’s happening in the system (errors, requests, events). Needed for debugging, audits, and finding issues fast.
Metrics → Numbers that show system health (CPU, memory, response time, traffic). Needed to measure performance and know when to scale or fix something.
Automation → Automatically handles deployments, scaling, monitoring, and recovery. Needed to reduce human error, speed up processes, and keep systems reliable.
Database scaling
As the data grows bigger now , it’ll get overloaded and we need some ways to fix this issue. We can implement following approaches.
Vertical scaling
It means improving a single server’s capacity by adding more resources like CPU, RAM, or storage Example: Upgrading memory from 8 GB to 32 GB allows the server to handle more traffic.
Horizontal scaling
It means adding more servers instead of making one server stronger. For instance, you can deploy 5 servers and use a Load Balancer to spread the traffic among them.
Sharding
It is a way of splitting a large database into smaller pieces (called shards), where each shard holds a portion of the data.Example: Instead of one database storing data for all users, you split it so users A–M are stored in Shard 1, and users N–Z are stored in Shard 2.
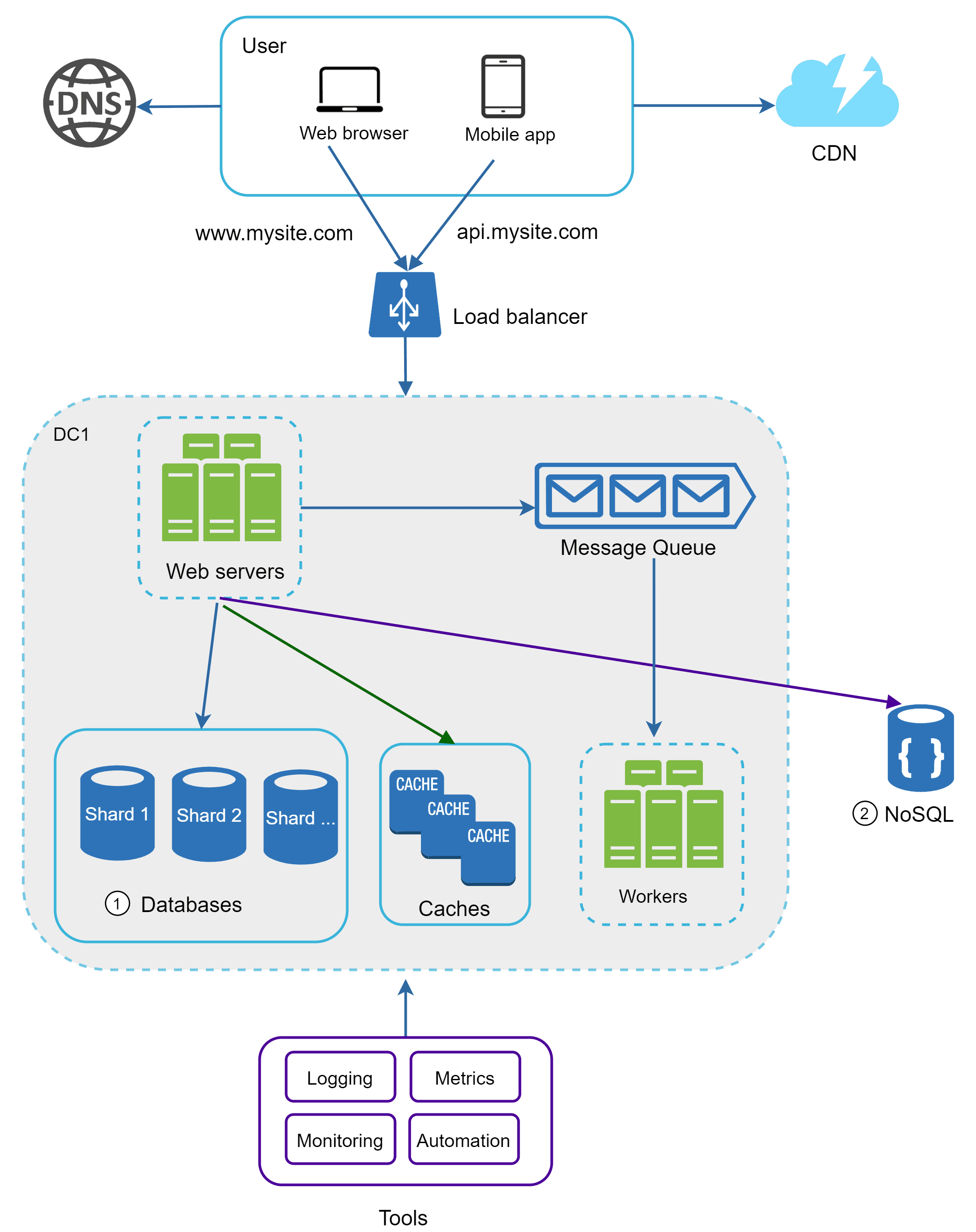
After implementing these steps, our architecture can gracefully handle millions of users and beyond. But system design is never truly “finished” , it’s an iterative process where we continuously refine, decouple layers, add more caching strategies, and adjust components as the system grows.
Thanks for reading! 🎉 A lot of these learnings are inspired by the amazing content from ByteByteGo.If you’re serious about system design, I highly recommend checking out their course.
Subscribe to my newsletter
Read articles from Raghav Shukla directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Raghav Shukla
Raghav Shukla
Passionate software developer crafting elegant solutions through code and innovation.