VibeVoice 1.5B: Four Distinct Voices, 90 Minutes and a Leap Forward for Text‑to‑Speech
 Fotie M. Constant
Fotie M. Constant
Last week, while waiting for a tram in Lisbon, I pulled up an audio article on my phone. It was one of those long‑form pieces converted to speech by a synthetic voice. The words were accurate, but the delivery felt robotic-monotone, with awkward pauses that never let me forget I was listening to a machine. It made me wonder why, despite all our progress in AI, most text‑to‑speech (TTS) systems still sound like they’re reading from a teleprompter.
Quick note before we dive in:
If you’re experimenting with text-to-speech models like VibeVoice or even Kokoro-82M and need a hand setting things up, from running checkpoints locally to optimizing GPU usage or even integrating TTS into a bigger project, I’d be happy to help.
Working with these models can feel tricky at first, but with the right setup you can get smooth results without wasting hours on trial and error. If you’d like some guidance or just want to make sure you’re on the right track, reach out at hello@fotiecodes.com and let’s talk about how to get your project running the way you want it to.
Okay, now back to the model itself. Microsoft just dropped VibeVoice 1.5B, their latest open‑source TTS model. This isn’t just another model posting marginal gains in quality. According to the team behind it, VibeVoice can generate up to 90 minutes of natural‑sounding dialogue with as many as four distinct speakers in one go. It’s MIT‑licensed, expressive and designed to be practical for researchers and hobbyists alike. That’s a big deal: most TTS models top out at a few sentences, and they struggle if multiple voices need to interleave naturally. With VibeVoice, Microsoft is aiming squarely at long‑form podcasts, audio books and conversational agents.
To try it out for free, you can access the gradio here.
For generated audio samples, visit their repository at microsoft/VibeVoice
Why this matters
So what’s different this time? The short answer is scale and flexibility:
Long context and multi‑speaker support: VibeVoice can synthesize up to 90 minutes of continuous speech while juggling up to four voices. That’s a massive leap over the one or two‑speaker limit typical of previous models.
Parallel generation: Rather than stitching together separate clips, the model produces parallel audio streams for each speaker. The result is smoother turn‑taking and more natural back‑and‑forth dialogue.
Cross‑lingual and singing synthesis: While the training data focuses on English and Chinese, VibeVoice can handle cross‑lingual narration (an English prompt producing Chinese speech) and even generate singing. That’s rare in an open‑source model.
Open and commercially friendly: It’s released under the MIT license, so researchers and developers can build on top of it without worrying about restrictive terms.
Designed for streaming: VibeVoice’s architecture allows for long‑form synthesis and anticipates a forthcoming 7 billion‑parameter streaming‑capable version.
Emotion and expressiveness: The model incorporates emotion control to make voices sound less robotic and more human.
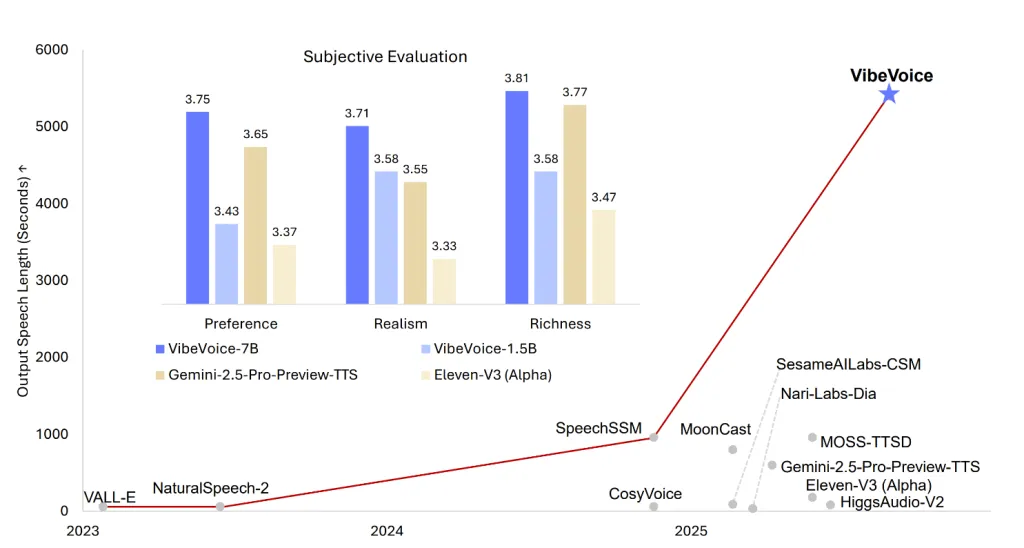
Image source: https://huggingface.co/microsoft/VibeVoice-1.5B
Put simply, this model isn’t just trying to pronounce words correctly, it’s actually trying to tell a story. If you’ve ever listened to an AI‑read audio book and felt something was off, the difference with VibeVoice can be striking.
A peek under the hood
At the heart of VibeVoice is a 1.5‑billion‑parameter language model based on Qwen2.5‑1.5B. As we already know, on its own, a language model can’t produce speech, it deals in text tokens. VibeVoice bridges that gap with a clever trio of components:
Acoustic tokenizer: Think of this as a scribe that compresses raw audio into a sequence of tokens. It’s built using a σ‑Variational Autoencoder with a mirrored encoder‑decoder and downsamples 24 kHz audio by a factor of 3200×. This huge compression makes it feasible to process long audio sequences efficiently.
Semantic tokenizer: Trained via an automatic speech recognition (ASR) proxy task, this encoder‑only model mirrors the acoustic tokenizer but without the VAE bells and whistles. It captures the “what is being said” rather than the waveform details.
Diffusion decoder head: Once the language model has planned the dialogue and the tokenizers have set the stage, a lightweight ~123 million‑parameter diffusion module predicts the final acoustic features. This module uses techniques like Classifier‑Free Guidance and DPM‑Solver to sharpen audio quality.
These pieces are then stitched together through a context length curriculum. Training begins with sequences of 4k tokens and progressively ramps up to 65k tokens, teaching the model to stay coherent over very long stretches. Meanwhile, the base language model handles dialogue flow, deciding when each speaker should talk, and the diffusion head fills in the acoustic details. It’s like writing a script (the LLM), assigning lines to actors (the tokenizers) and then directing them on stage (the diffusion head).
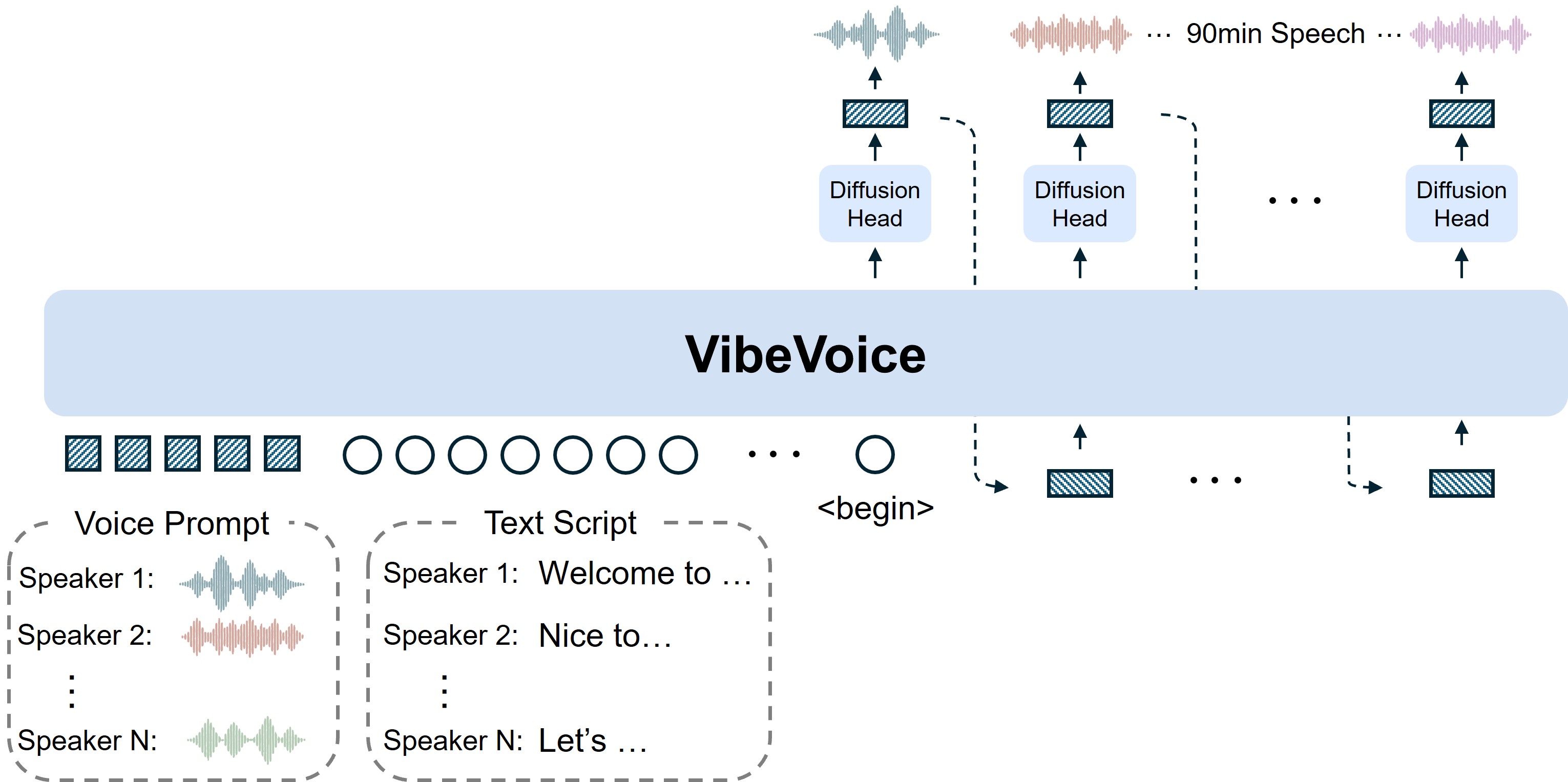
Image source: https://microsoft.github.io/VibeVoice/
If you look at the diagram above, the idea is pretty straightforward. You start by giving VibeVoice a few voice prompts, short samples of each speaker’s voice, along with a script of what they’re supposed to say. The model then takes that input, processes it, and uses its diffusion heads to generate speech that can keep going for a long stretch, up to 90 minutes. What makes this powerful is that it doesn’t just stitch audio clips together; it keeps the flow natural, switching between speakers smoothly like in a real conversation or audiobook.
Responsible use and current limits
As always, no AI model is perfect, and Microsoft is clear about where VibeVoice falls short. For now, it:
Speaks only English and Chinese. Other languages might produce gibberish or offensive content.
Avoids overlapping speech. The model handles turn‑taking but can’t simulate people talking over one another, this perhaps will be fixed in future iterations.
Generates speech only. There are no background sounds, music or ambient noise.
Warns against misuse. Microsoft explicitly bans voice impersonation, disinformation and any authentication bypass. Users must follow laws and clearly disclose AI‑generated content.
Isn’t real‑time ready. The current release isn’t optimized for low‑latency streaming; that’s reserved for the upcoming 7B variant.
These limitations don’t detract from the model’s achievements, but they do set expectations. If you’re hoping for multi‑lingual, fully overlapped conversations with music in the background, you’ll have to wait.
The bigger picture
Why should anyone outside the AI research community care about a new TTS model? Because long‑form synthetic speech is quietly reshaping how we consume information. Podcasts, documentaries and audio books require hours of narration and I personally do love listening to audio books and podcasts on the go. Until now, creating convincing multi‑speaker audio from text involved expensive human voice actors or complex post‑production. VibeVoice points to a future where a single script can become a dynamic conversation at the click of a button.
Moreover, the open‑source nature of this release invites experimentation. Hobbyists can fine‑tune voices for indie games and personal projects. Educators can create interactive lessons. Researchers can explore cross‑lingual capabilities without worrying about proprietary licenses. And because the team plans an even larger 7B streaming model, the gap between research prototypes and production‑ready tools is narrowing.
Okay, let’s talk about specs
So what do you actually need to run VibeVoice-1.5B on your own machine? Community benchmarks suggest that generating a multi-speaker dialogue with the 1.5B checkpoint eats up around 7 GB of GPU VRAM. That means a mid-range card like an RTX 3060 (8 GB) is enough to get you through inference comfortably. Of course, if you’re planning longer sessions, stacking multiple speakers, or just want smoother throughput, having more VRAM never hurts, but you don’t need a data-center GPU to play around with this model locally.
Final thoughts
VibeVoice 1.5B isn’t the end of the road for synthetic voices, but it marks a significant milestone. Its ability to generate lengthy, expressive, multi‑speaker audio under an open license sets a new bar for what community‑driven TTS can achieve. There are still hurdles to clear, things like more languages, overlapping speech and real‑time streaming, but the foundation is honestly solid.
I’m excited to see how creatives and developers will use it. Will we get entire radio dramas voiced by AI? Could language learners practice conversation with a responsive, multi‑speaker tutor? The tools are there; it’s up to us to apply them responsibly.
Have you experimented with VibeVoice or other TTS systems? I’d love to hear your experiences and whether you think AI voices can ever truly replace the human ones we’re used to. As always, feel free to drop your thoughts in the comments or reach out directly.
Subscribe to my newsletter
Read articles from Fotie M. Constant directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Fotie M. Constant
Fotie M. Constant
Widely known as fotiecodes, an open source enthusiast, software developer, mentor and SaaS founder. I'm passionate about creating software solutions that are scalable and accessible to all, and i am dedicated to building innovative SaaS products that empower businesses to work smarter, not harder.