How AI Finds Its Way: The Logic of Search
 Sakib Miyahn
Sakib Miyahn
When we discuss intelligence, we often think about making informed decisions. But decisions don’t always happen in a single step. Whether it’s navigating a maze, planning a delivery route, or solving a puzzle, many problems require an agent to figure out a sequence of actions, not just what to do, but in what order.
This process of finding a path through a space of possibilities is what we refer to as search in artificial intelligence. It’s one of the most fundamental problem-solving tools in the field. And while it may sound simple, there’s a surprising amount of depth and elegance in how it works.
“In which we see how an agent can find a sequence of actions that achieves its goals when no single action will do.” - Peter Norvig and Stuart J. Russel
From Real-World Goals to Search Problems
Before an AI system can search, it needs to understand what it’s searching for. This means turning a real-world problem into a well-defined structure that the machine can reason about. We start by defining the initial state, where the agent begins. We also define the goal, what the agent is trying to reach. Then we list all the actions available at each point, and describe how those actions move the agent from one state to another. This forms a search space, a kind of mental map the agent can explore.
Imagine a robot in a house. Its initial state might be in the kitchen and the goal is in the living room. The actions are things like move forward, turn left or open door. Once this is modeled, the AI can start figuring out how to get from point A to point B.
How Machines Search
To find a path to the goal, the AI explores different possible sequences of actions, essentially walking a decision tree. Each branch represents a new state that results from taking an action. Some paths lead to dead ends. Others eventually reach the goal.
Unlike humans, machines don’t have intuition or shortcuts built in. So we need to give them algorithms, precise strategies for exploring the search space.
Some of these strategies are quite basic, treating all options equally. Others use clever tricks to prioritise certain paths over others. Broadly, we divide them into two categories: uninformed and informed search.
Blind Strategies: Uninformed Search
Uninformed search algorithms don’t use any knowledge about the goal’s location. They treat all states equally and rely solely on the problem definition. These methods are useful when no heuristic guidance is available.
Breadth-First Search (BFS)
It explores all paths that take one step, then all paths that take two steps, and so on. It guarantees the shortest solution (in terms of number of steps), but can be slow and memory-intensive.
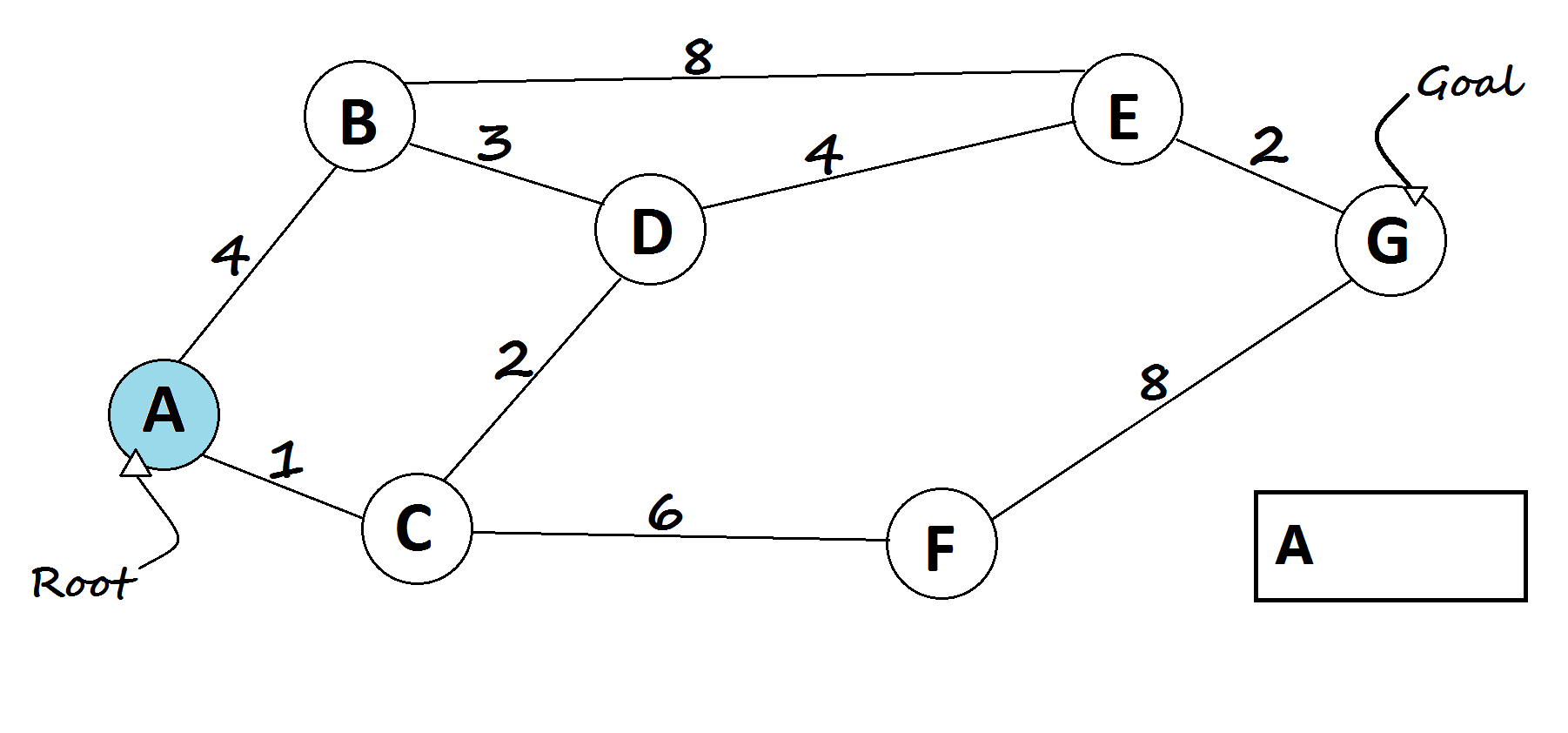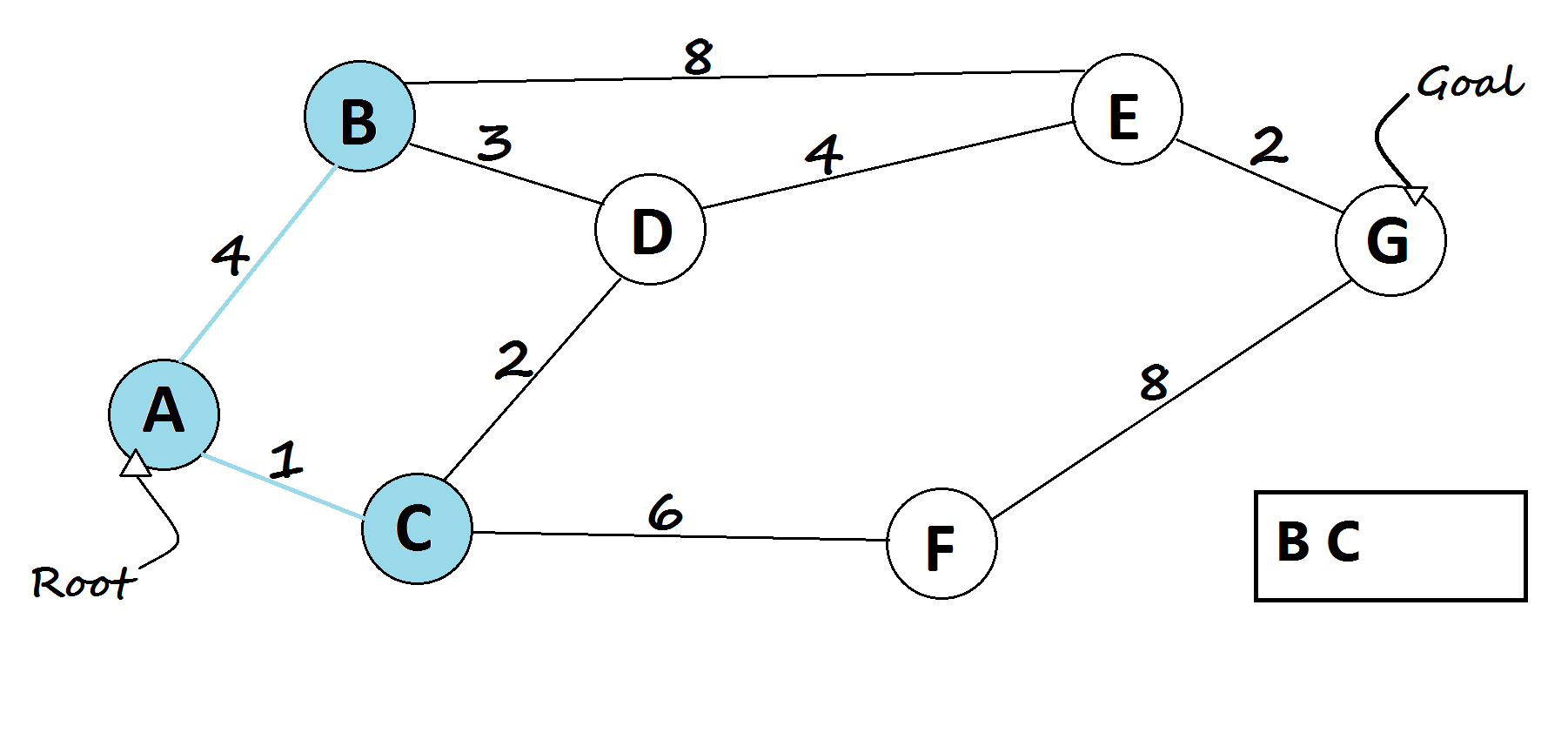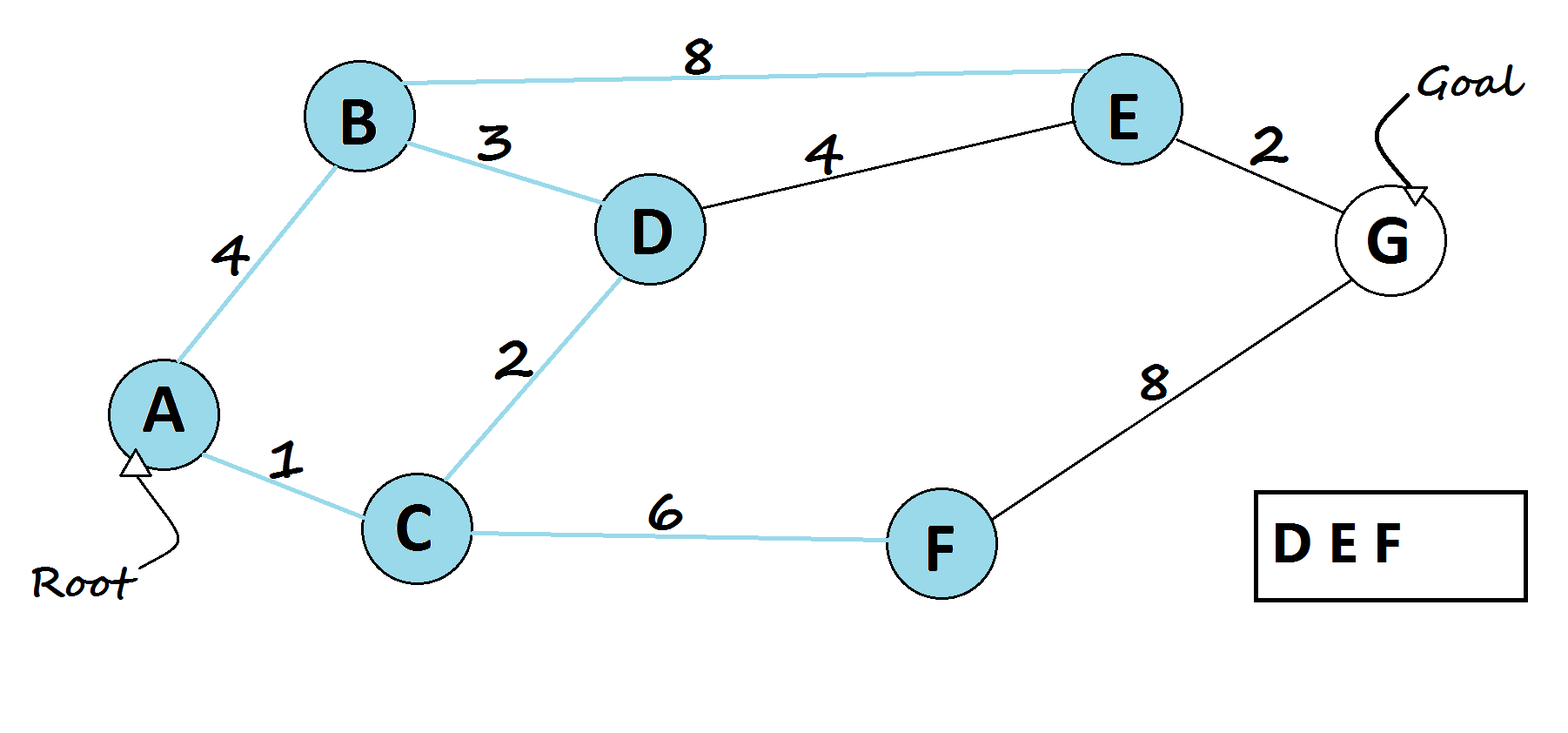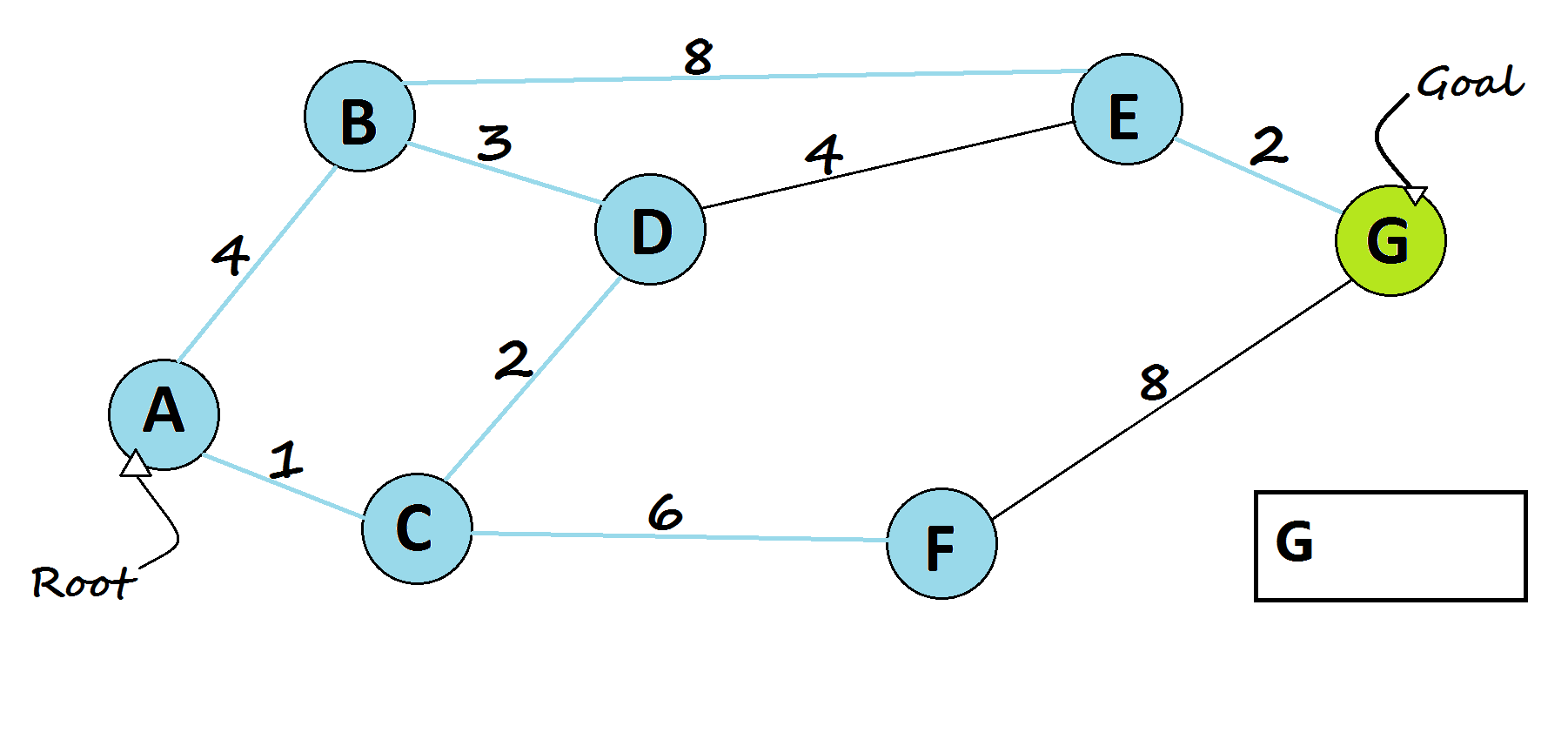
def BFS(graph, start, goal):
# Initialize the queue with the starting node and an empty path
queue = [(start, [])]
# Set to keep track of visited nodes
visited = set()
# Counter to keep track of node expansions
node_expansions = 0
while queue:
# Dequeue a node and its path
node, path = queue.pop(0)
# If the node has been visited, skip it
if node in visited:
continue
# Mark the node as visited
visited.add(node)
# Append the current node to the path
path = path + [node]
# If the goal is reached, return the path, its length, and the number of node expansions
if node == goal:
return path, len(path), node_expansions
# Increment the node expansions counter
node_expansions += 1
# Add all unvisited neighbors to the queue
for neighbor in graph.neighbors(node):
if neighbor not in visited:
queue.append((neighbor, path))
# If no path is found, return an empty list, infinity for path length, and the number of node expansions
return [], float("inf"), node_expansions
Depth-First Search (DFS)
It goes as far down a single path as it can before backtracking. It’s more memory-efficient but can get lost if the search space is deep or looping.
def DFS(graph, start, goal):
# Initialize the stack with the starting node and an empty path
stack = [(start, [])]
# Set to keep track of visited nodes
visited = set()
# Counter to keep track of node expansions
node_expansions = 0
while stack:
# Pop a node and its path from the stack
node, path = stack.pop()
# If the node has been visited, skip it
if node in visited:
continue
# Mark the node as visited
visited.add(node)
# Append the current node to the path
path = path + [node]
# If the goal is reached, return the path, its length, and the number of node expansions
if node == goal:
return path, len(path), node_expansions
# Increment the node expansions counter
node_expansions += 1
# Add all unvisited neighbors to the stack
for neighbor in reversed(list(graph.neighbors(node))):
if neighbor not in visited:
stack.append((neighbor, path))
# If no path is found, return an empty list, infinity for path length, and the number of node expansions
return [], float("inf"), node_expansions
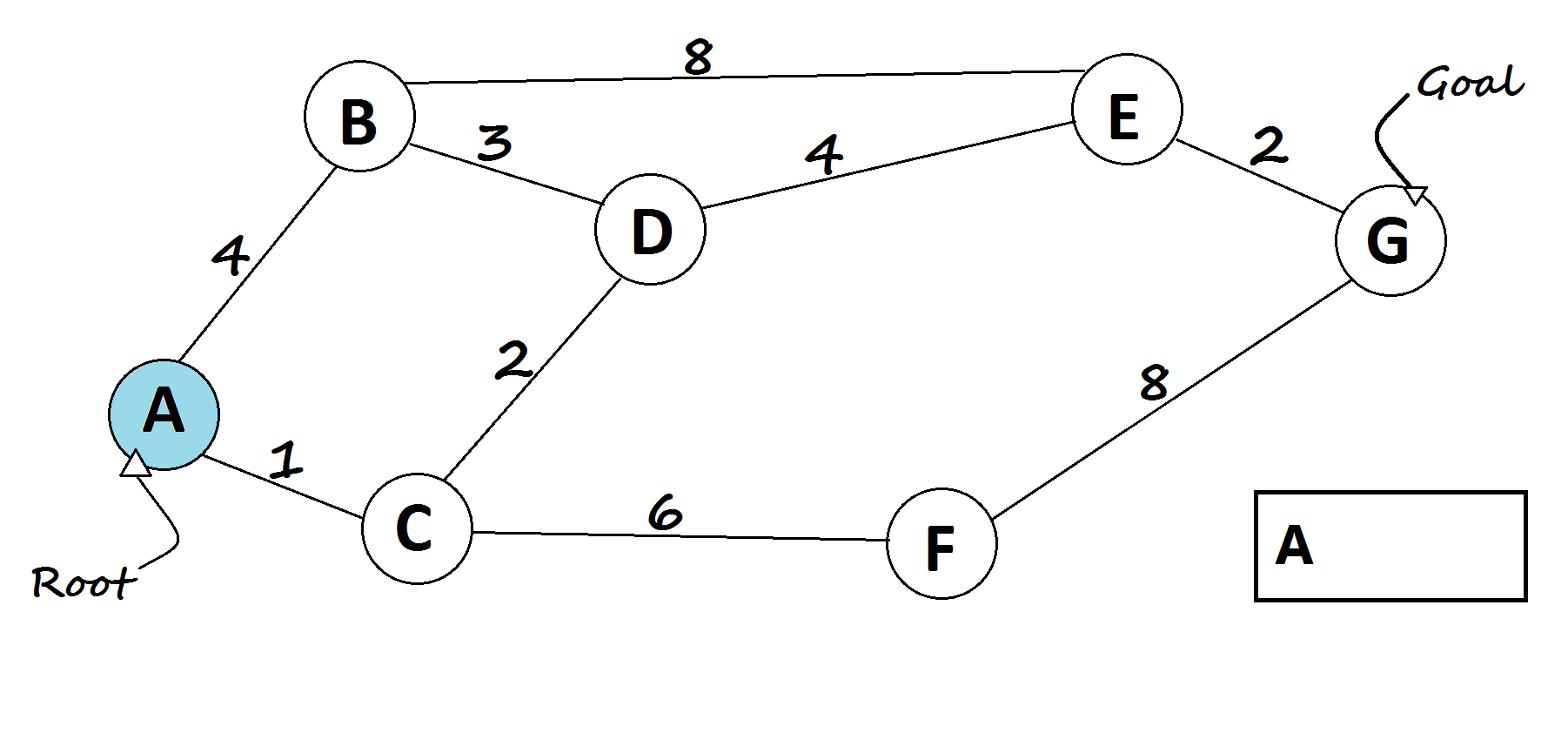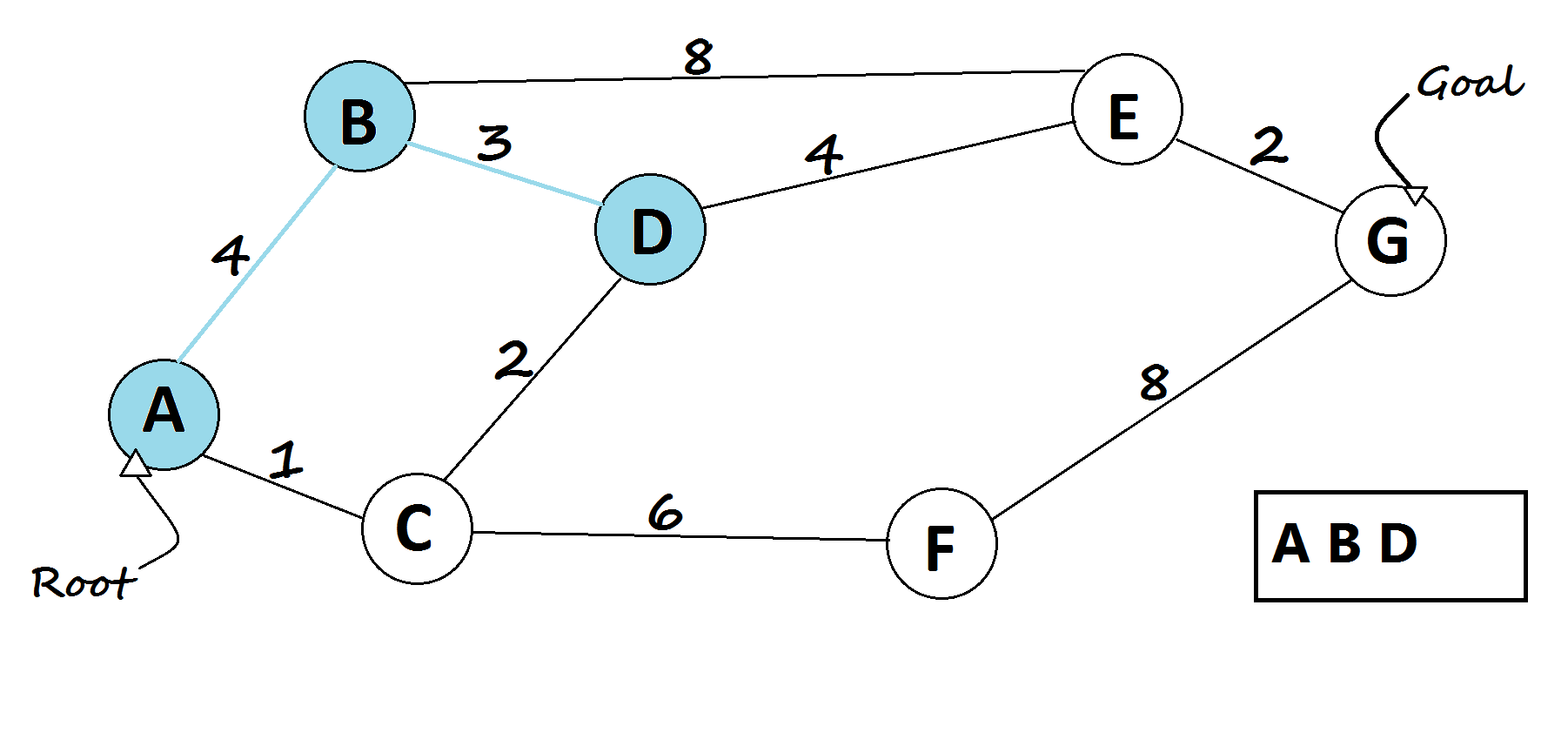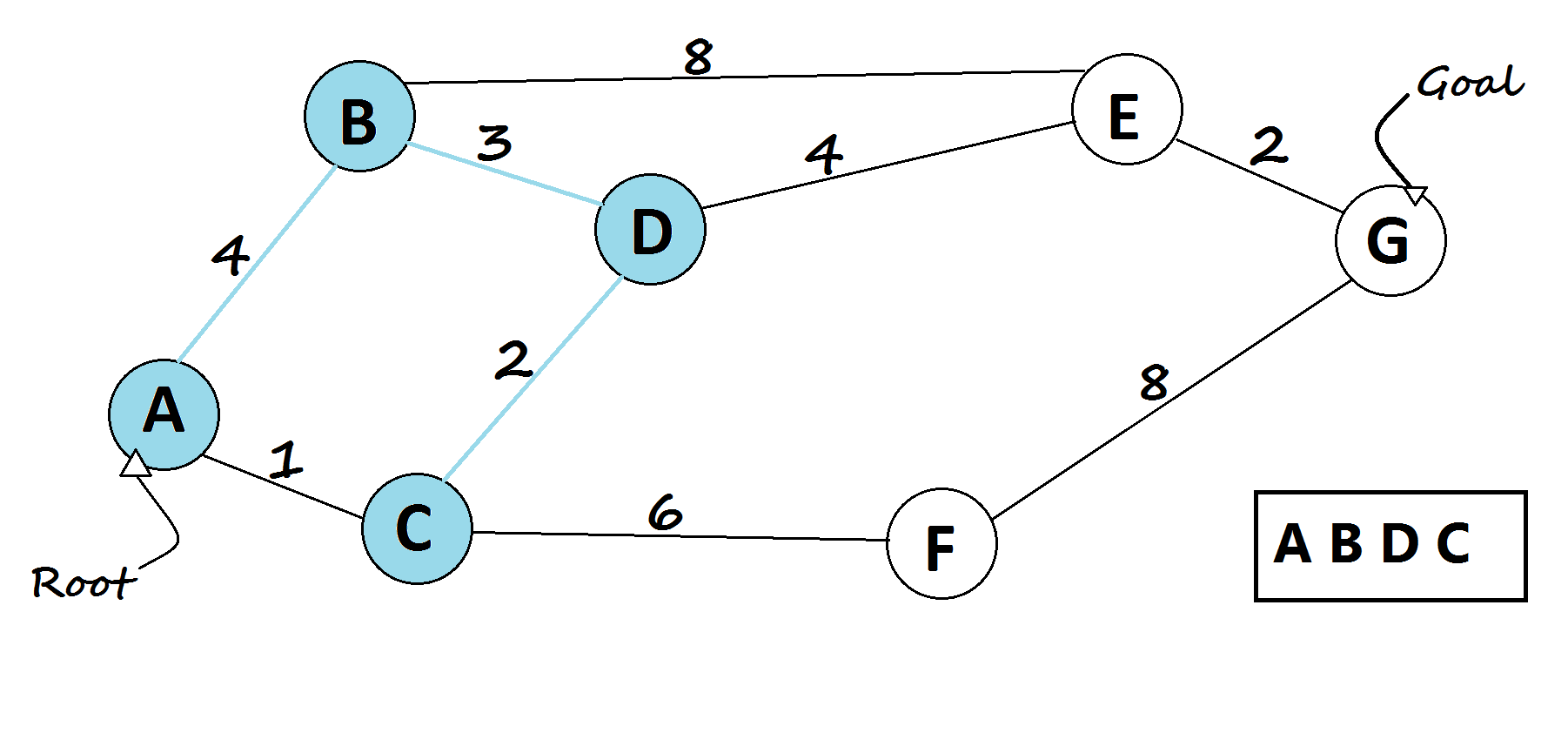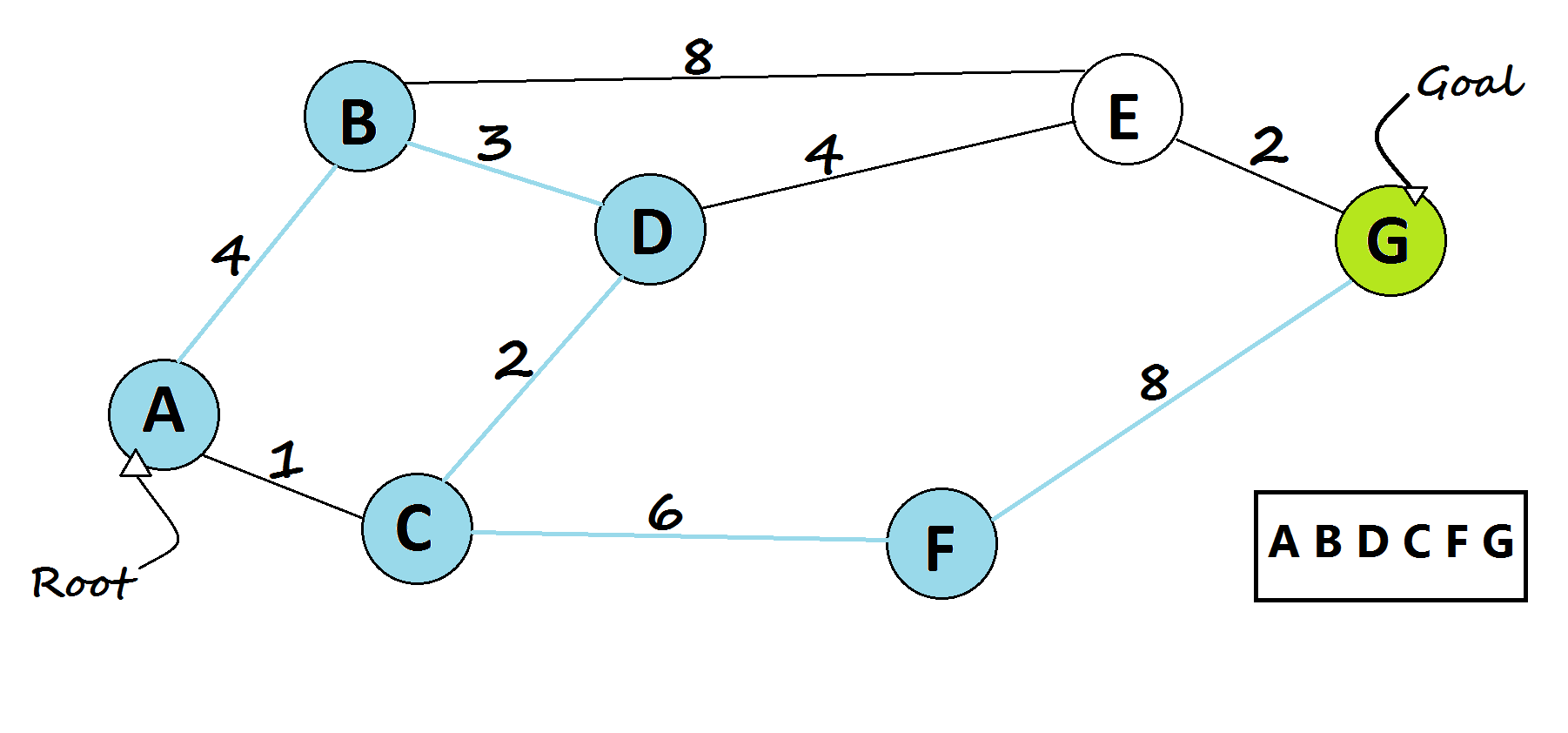
Uniform Cost Search (UCS)
Adds a layer of realism by considering the cost of each action. Instead of counting steps, it looks for the path with the lowest total cost, useful when some actions are harder, slower, or more expensive than others.

def UCS(graph, start, goal):
# Initialize the priority queue with the starting node, cost 0, and an empty path
queue = [(0, start, [])]
# Set to keep track of visited nodes
visited = set()
# Counter to keep track of node expansions
node_expansions = 0
while queue:
# Dequeue the node with the lowest cost
cost, node, path = heapq.heappop(queue)
# If the node has been visited, skip it
if node in visited:
continue
# Mark the node as visited
visited.add(node)
# Append the current node to the path
path = path + [node]
# If the goal is reached, return the path, its length, and the number of node expansions
if node == goal:
return path, cost, node_expansions
# Increment the node expansions counter
node_expansions += 1
# Add all unvisited neighbors to the priority queue with their cumulative cost
for neighbor in graph.neighbors(node):
if neighbor not in visited:
edge_weight = graph.edges[node, neighbor].get("weight", 1)
heapq.heappush(queue, (cost + edge_weight, neighbor, path))
# If no path is found, return an empty list, infinity for path length, and the number of node expansions
return [], float("inf"), node_expansions
All of these algorithms are systematic, but none of them are particularly smart. They don’t know which direction is better; they just explore everything. A few other uninformed search algorithms include:
Depth-Limited Search - DFS with a fixed depth limit. Prevents infinite loops, but might miss deeper solutions.
Iterative Deepening Search (IDDFS) - Combines the space efficiency of DFS with the completeness of BFS. Performs DFS to increasing depths.
Bidirectional Search - Searches forward from the start and backward from the goal simultaneously. Efficient if the goal is known.
Smarter Strategies: Informed (Heuristic) Search
Informed search, sometimes called heuristic search, brings some knowledge into the process. These algorithms use heuristics (estimates of how far a given state is from the goal) to make better choices about what to explore next.
Greedy Best-First Search
Always picks the path that looks closest to the goal. It’s fast but not always accurate; sometimes it’s lured into traps because it doesn’t consider the cost of the path so far.
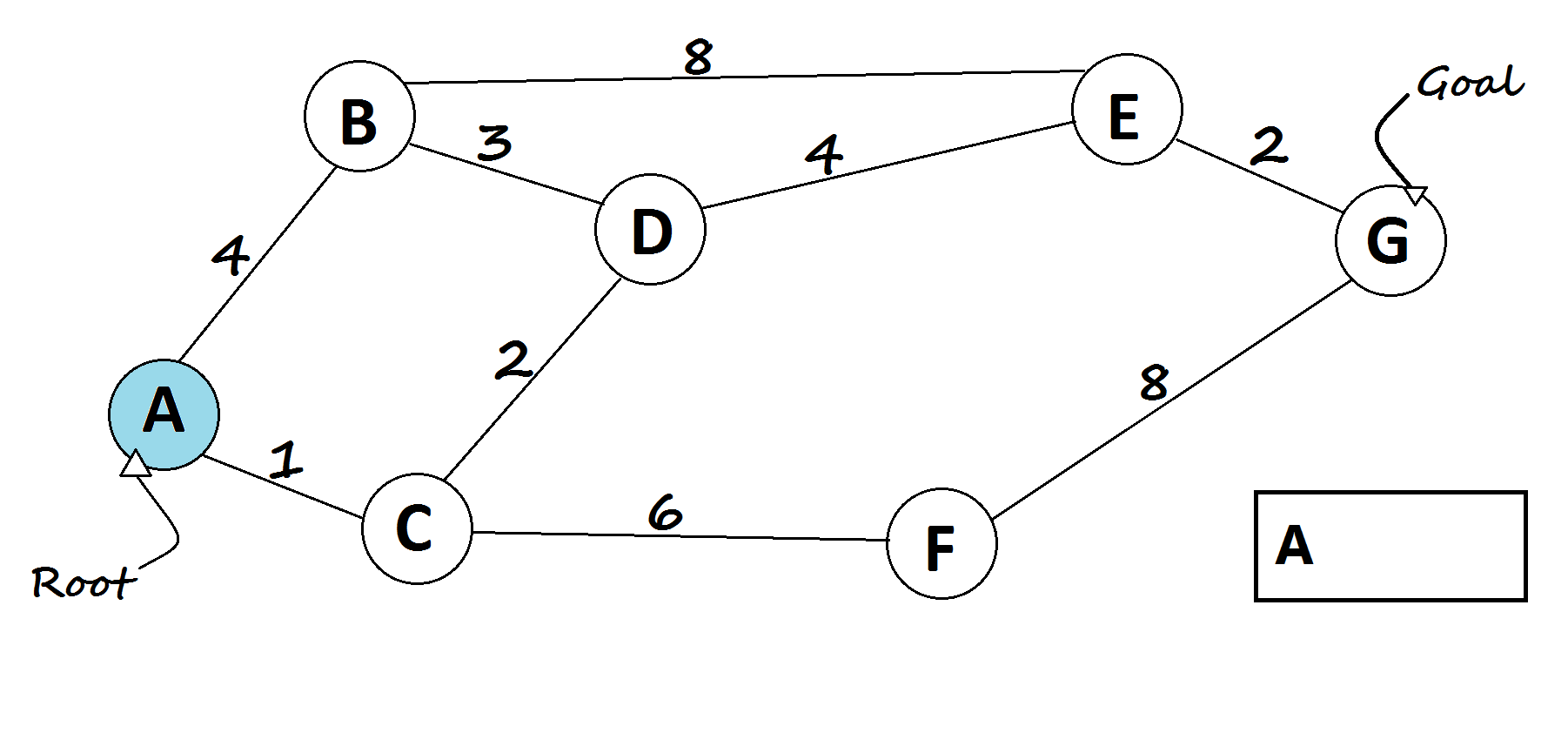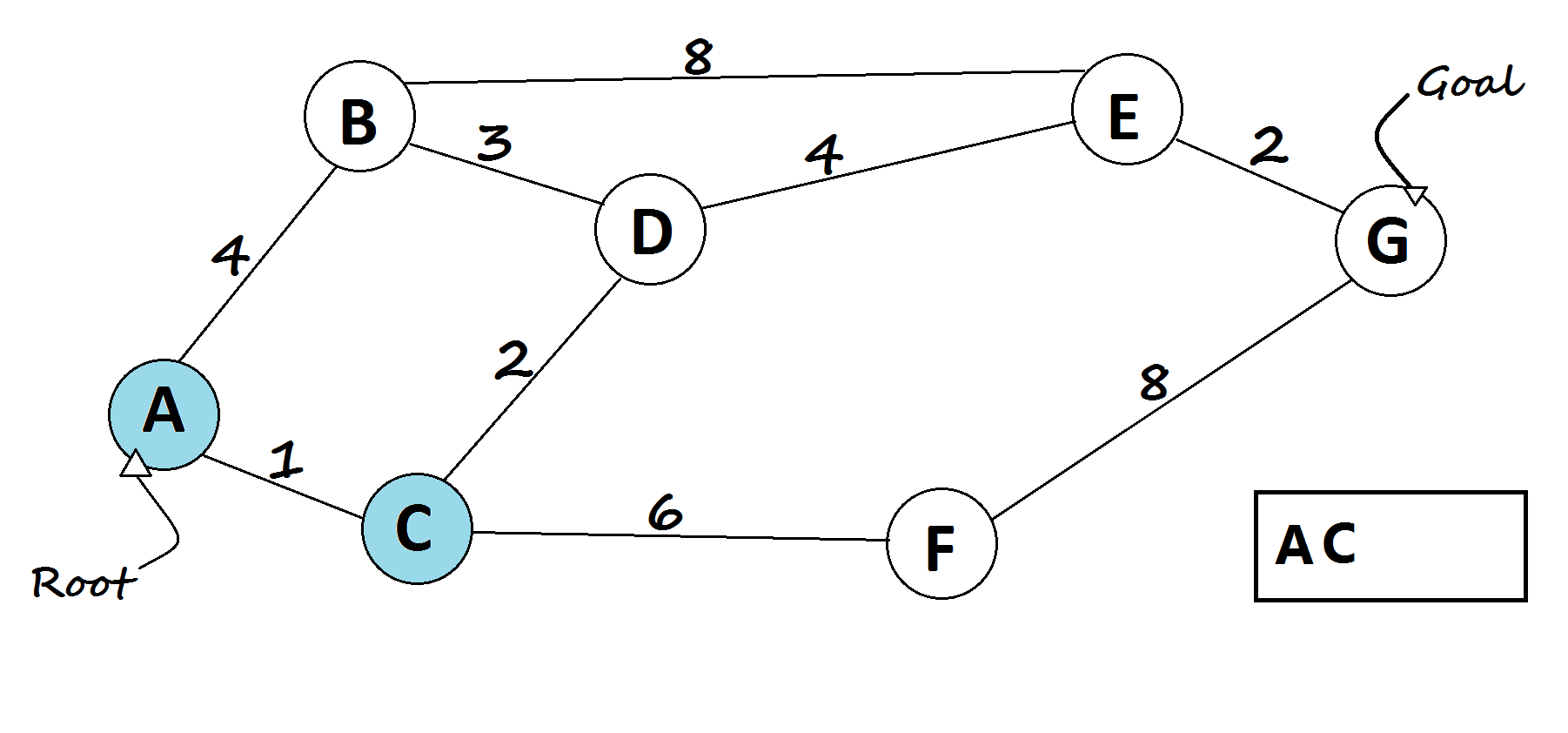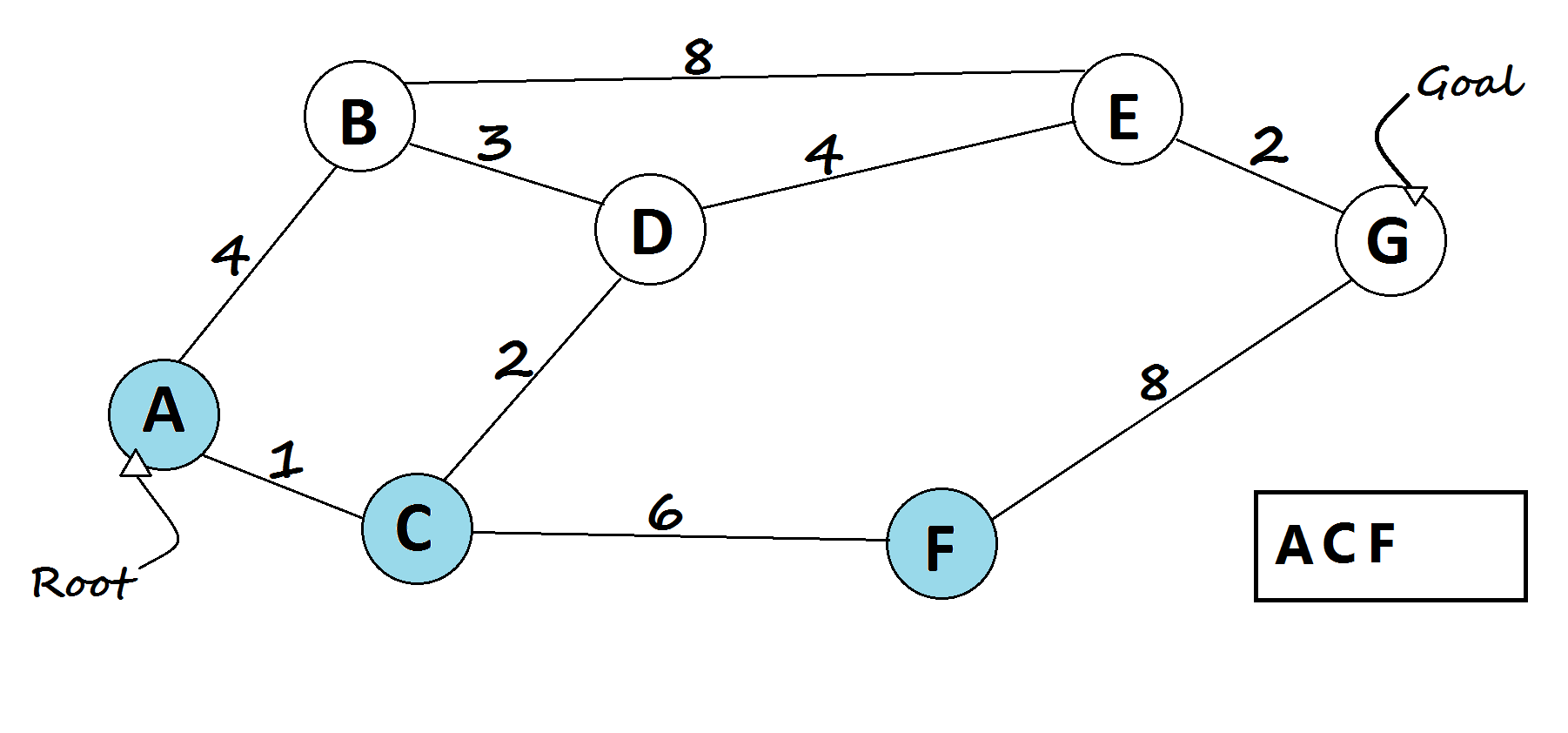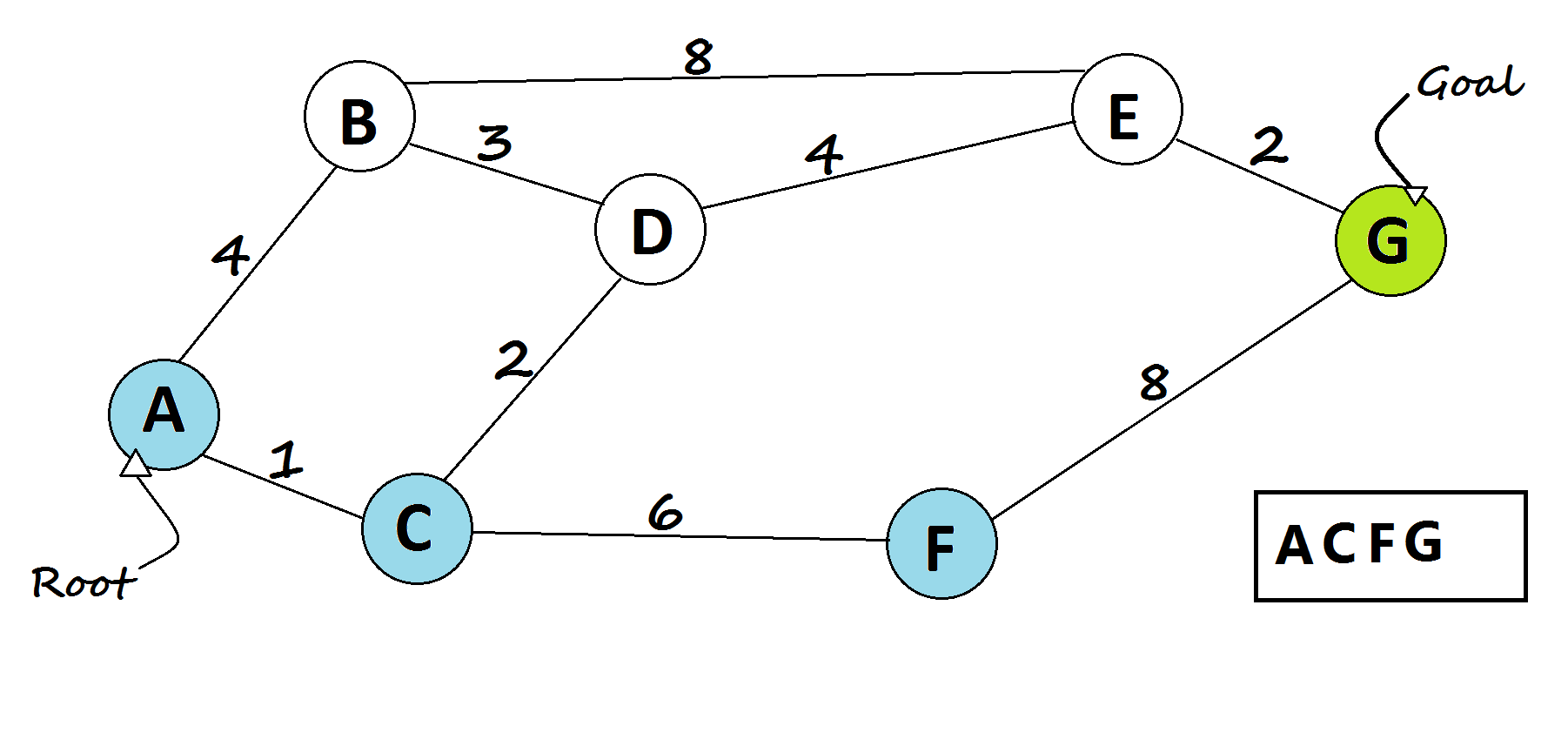
def best_first_search(graph, start, goal, heuristic):
# Initialize the priority queue with the starting node, its heuristic value, and an empty path
queue = [(heuristic[start], start, [])]
# Set to keep track of visited nodes
visited = set()
# Counter to keep track of node expansions
node_expansions = 0
while queue:
# Dequeue the node with the lowest heuristic value
_, node, path = heapq.heappop(queue)
# If the node has been visited, skip it
if node in visited:
continue
# Mark the node as visited
visited.add(node)
# Append the current node to the path
path = path + [node]
# If the goal is reached, return the path, its length, and the number of node expansions
if node == goal:
return path, len(path), node_expansions
# Increment the node expansions counter
node_expansions += 1
# Add all unvisited neighbors to the priority queue with their heuristic value
for neighbor in graph.neighbors(node):
if neighbor not in visited:
heapq.heappush(queue, (heuristic[neighbor], neighbor, path))
# If no path is found, return an empty list, infinity for path length, and the number of node expansions
return [], float("inf"), node_expansions
A* Search
It tries to balance two things: how much progress has already been made, and how much further there is to go (based on the heuristic). If the heuristic is well-designed, A* can find the best path quickly and reliably.
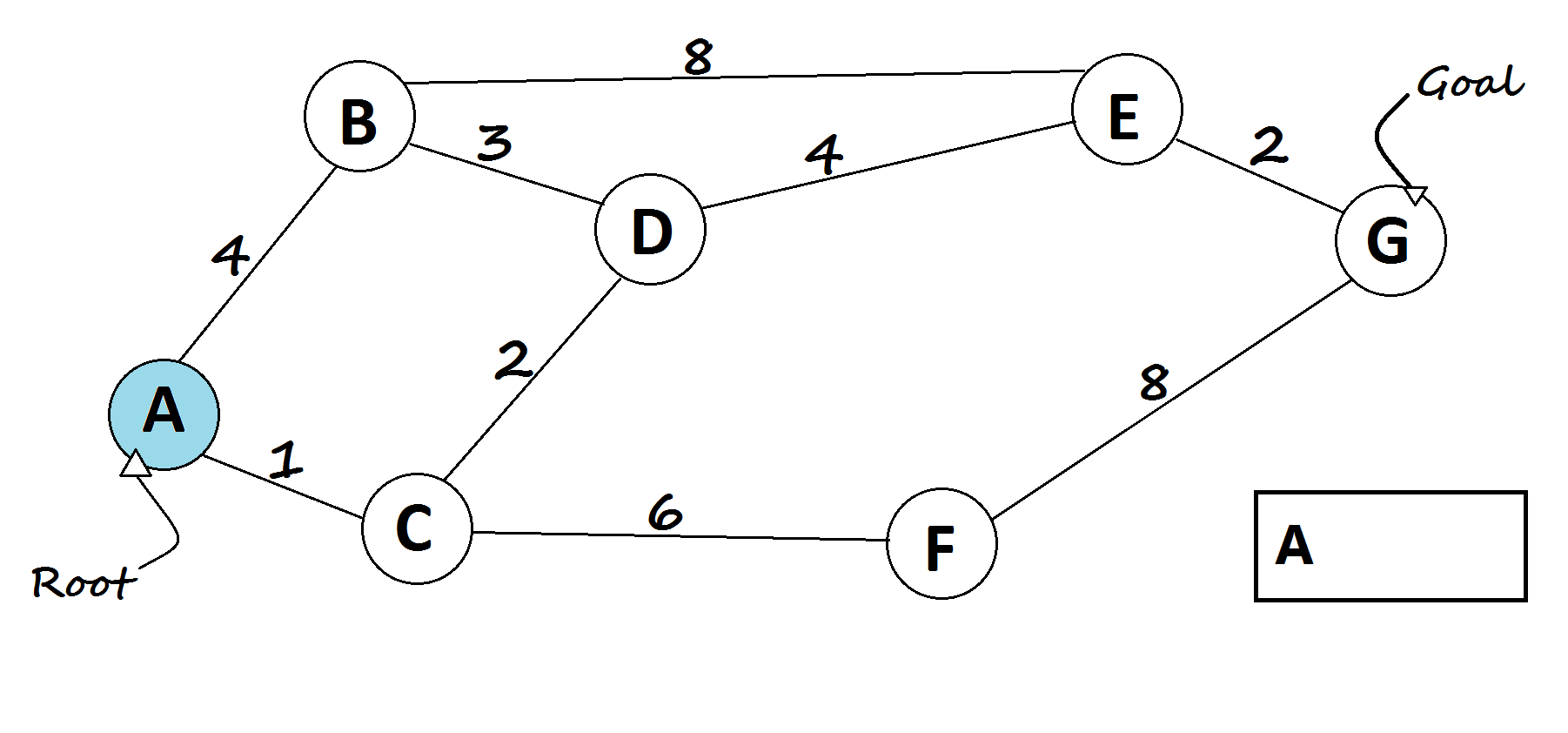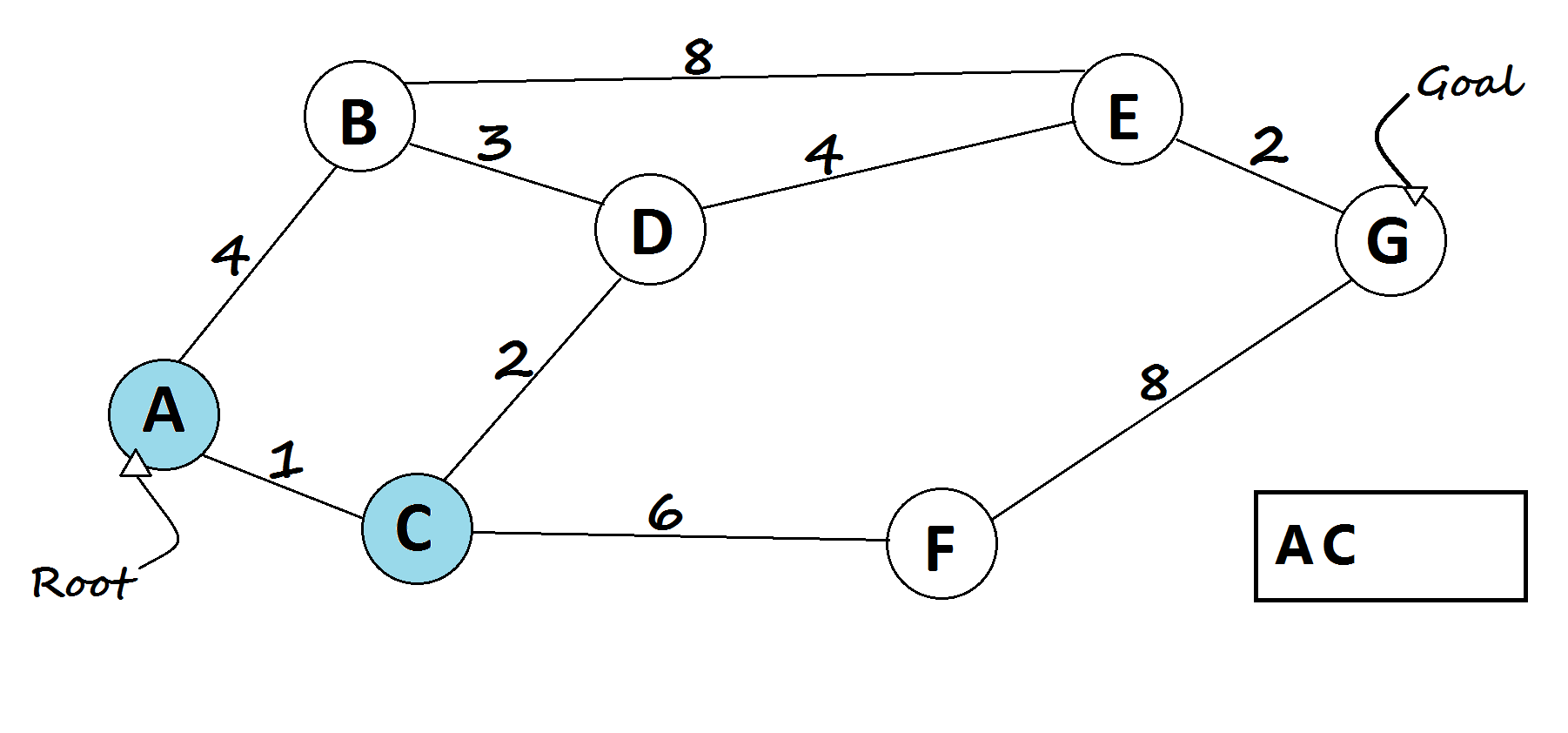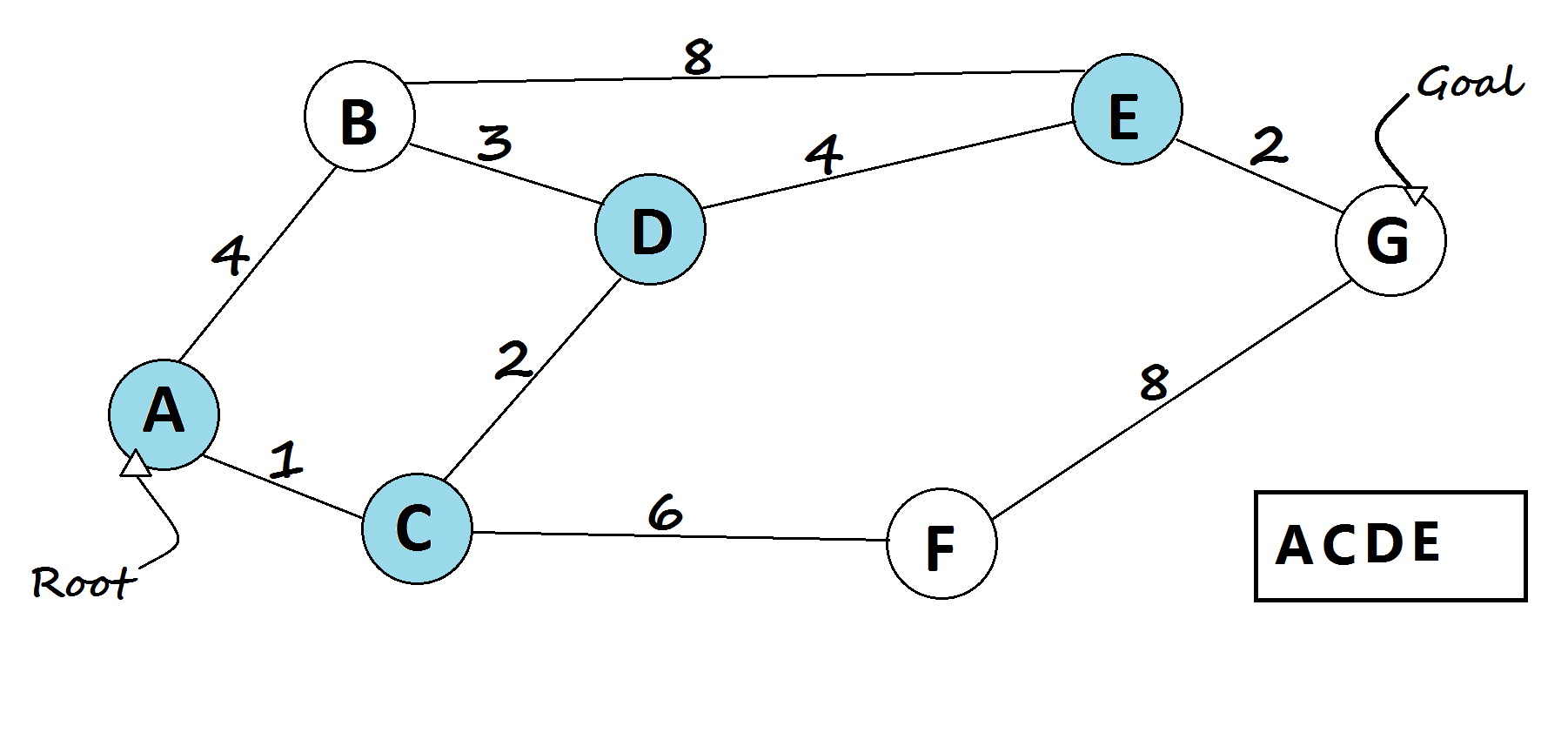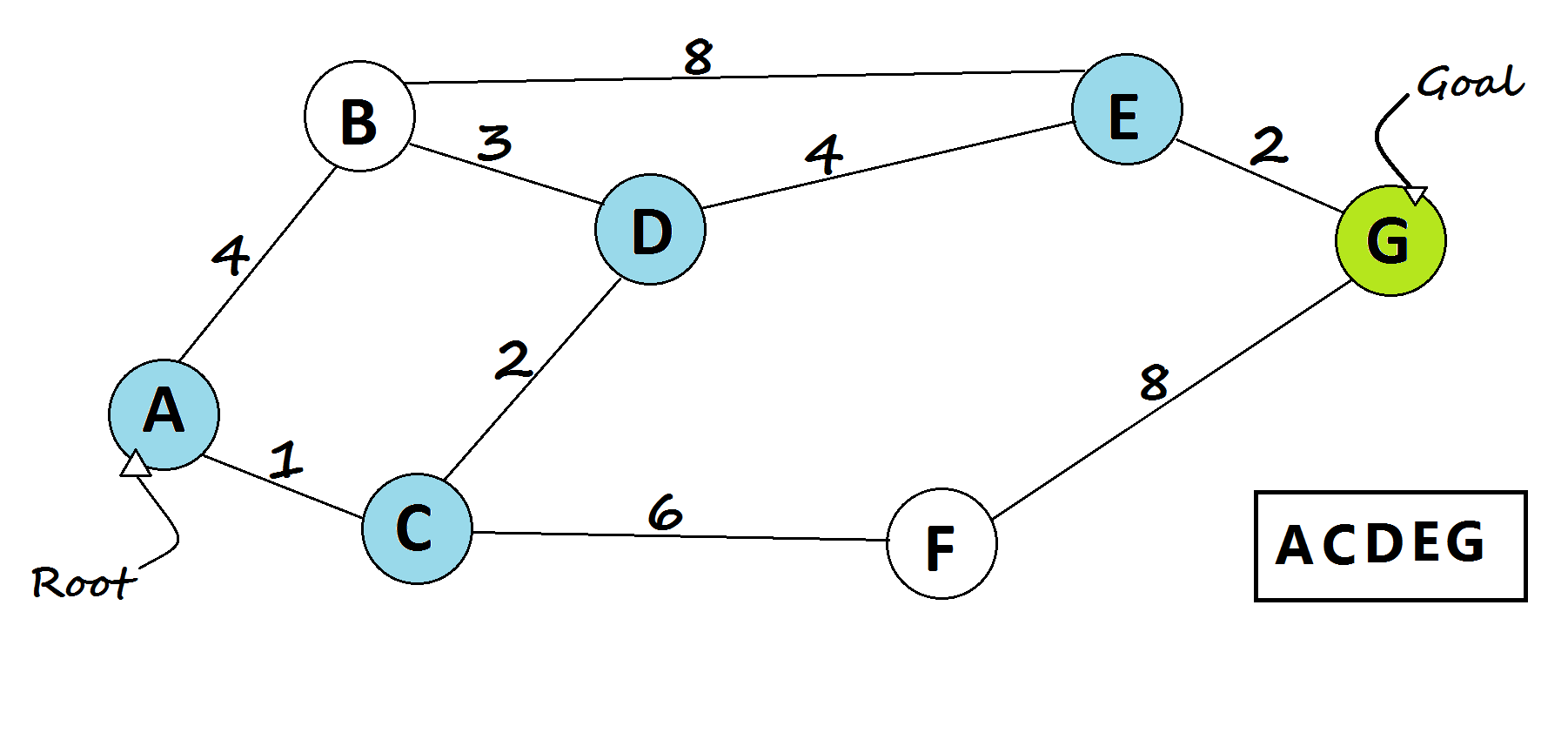
def a_star(graph, start, goal, heuristic):
# Initialize the priority queue with the starting node, cost 0, its heuristic value, and an empty path
queue = [(heuristic[start], 0, start, [])]
# Set to keep track of visited nodes
visited = set()
# Counter to keep track of node expansions
node_expansions = 0
while queue:
# Dequeue the node with the lowest cost + heuristic value
_, cost, node, path = heapq.heappop(queue)
# If the node has been visited, skip it
if node in visited:
continue
# Mark the node as visited
visited.add(node)
# Append the current node to the path
path = path + [node]
# If the goal is reached, return the path, its length, and the number of node expansions
if node == goal:
return path, cost, node_expansions
# Increment the node expansions counter
node_expansions += 1
# Add all unvisited neighbors to the priority queue with their cumulative cost + heuristic value
for neighbor in graph.neighbors(node):
if neighbor not in visited:
# This line retrieves the weight (or cost) of the edge between the current node and the neighbor.
# The code uses .get("weight", 1) to get the weight of the edge, with a default value of 1 if the weight is not specified.
edge_weight = graph.edges[node, neighbor].get("weight", 1)
total_cost = cost + edge_weight
heapq.heappush(
queue,
(total_cost + heuristic[neighbor], total_cost, neighbor, path),
)
# If no path is found, return an empty list, infinity for path length, and the number of node expansions
return [], float("inf"), node_expansions
Designing good heuristics is an art of its own. A heuristic must be efficient to compute and ideally never overestimate the true cost. When done right, it can drastically improve performance, especially in large or complex search spaces.
Why Search Matters
Search algorithms are the decision-making backbone of many AI systems: robot navigation, game playing, logistics, and even basic planning in smart assistants.
Each algorithm offers trade-offs in speed, memory, and optimality. Some are fast but risky, others are thorough but slow. Choosing the right one depends on what your agent is trying to do, and how much it knows about the world.
Understanding search is the first step in designing agents that can act intelligently, not just react, but think ahead, reason with uncertainty, and solve problems.
Looking Ahead
So far, we’ve focused on planning, choosing actions in a known world. But what if the world is unknown, complex, or constantly changing?
That’s where learning comes in. In our next article, we’ll explore neural networks, how they learn patterns from data, recognise images, understand speech, and drive modern AI systems.
Subscribe to my newsletter
Read articles from Sakib Miyahn directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sakib Miyahn
Sakib Miyahn
👋 Hi, I’m Sakib — a Sydney-based Full-Stack Software Engineer with a passion for building scalable systems, clean code and elegant developer experiences. With over 8 years of experience, I specialise in modern web technologies, including Next.js, NestJS, and TypeScript, and have a strong background in FinTech, payment gateway integration, and embedded systems. I enjoy architecting solutions that are robust, secure and user-centric. Outside of coding, I’m an avid learner who enjoys astrophysics, chess (1900+ blitz rating on Chess.com ♟️), hiking, good food and wine. 🌐 Learn more at https://sakibmiyahn.com