How Change Data Capture (CDC) Works with Streaming Database
 Bobur Umurzokov
Bobur Umurzokov
Efficiently capture databases changes with a streaming database
Streaming Change Data Capture (CDC) is a data integration approach that has become increasingly popular in recent years. Streaming CDC is a technique that enables organizations to capture and transmit real-time data changes in data sources like SQL/NoSQL databases and sent them to a target system, such as a data warehouse or analytics platform, where they can be used to generate insights and drive business decisions. Streaming CDC can be particularly useful for organizations that need to react quickly to changing market conditions or customer needs.
In this post, we will explore how CDC works with streaming databases and the benefits this integration provides. You will also learn how to analyze data captured from MySQL with RisingWave.
RisingWave is an open-source streaming database that has built-in fully-managed CDC source connectors for MySQL and PostgreSQL and it allows you to query real-time streams using SQL. You can get a materialized view that is always up-to-date.
Learning objectives
By the end of this article, you will learn:
- What is Change Data Capture (CDC)?
- CDC use cases.
- Why use CDC with Streaming Database?
- How to Ingest CDC data from MySQL using RisingWave connector.
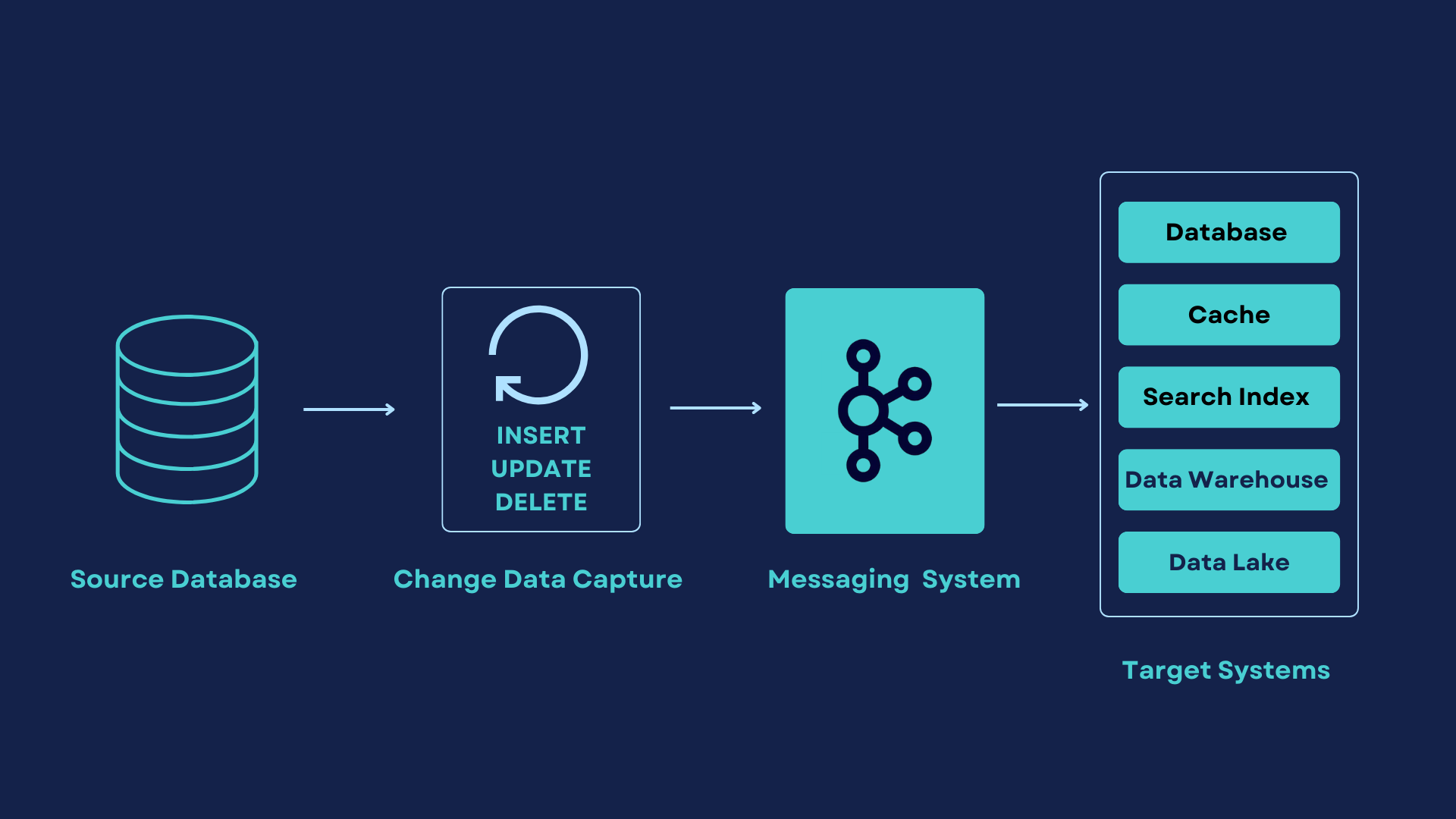
What is Change Data Capture?
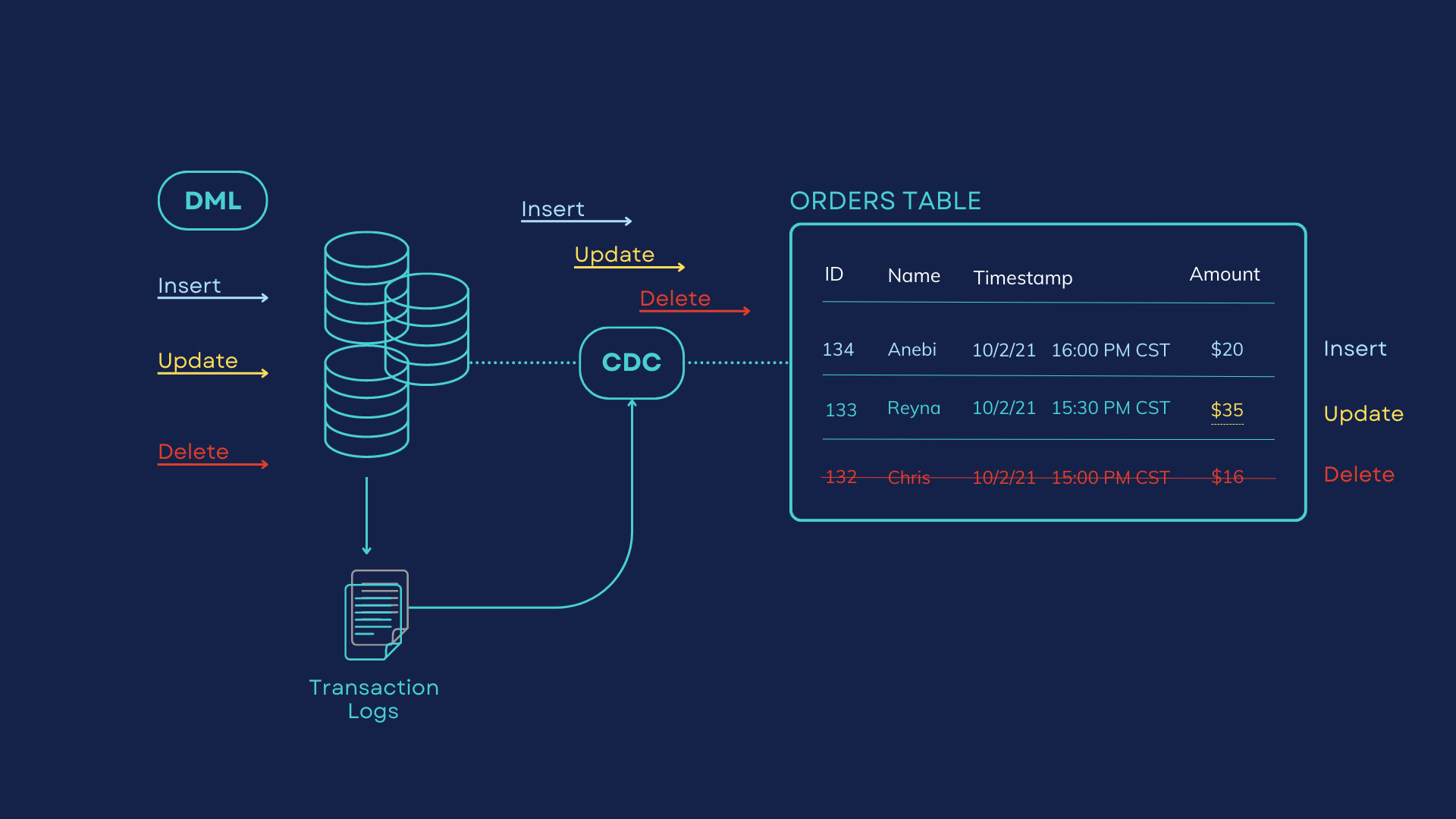
Change Data Capture is a technique used to capture and propagate changes made to a database such as MySQL, Microsoft SQL, Oracle, PostgreSQL, MongoDB, or Cassandra. CDC works by continuously monitoring the database for any changes made to the data. Multiple types of change data capture patterns can be used for data processing from a database. These include log-based CDC, trigger-based CDC, CDC based on timestamps, and difference-based CDC.
When you make operations like INSERT, UPDATE, or DELETE, against a database, a change is detected, and CDC captures the change and records it in a transaction log. The captured changes are then transformed into a format that can be consumed in real time by downstream systems. The downstream systems can be a search index, cache, stream analytics applications, messaging queues, or data warehouse.
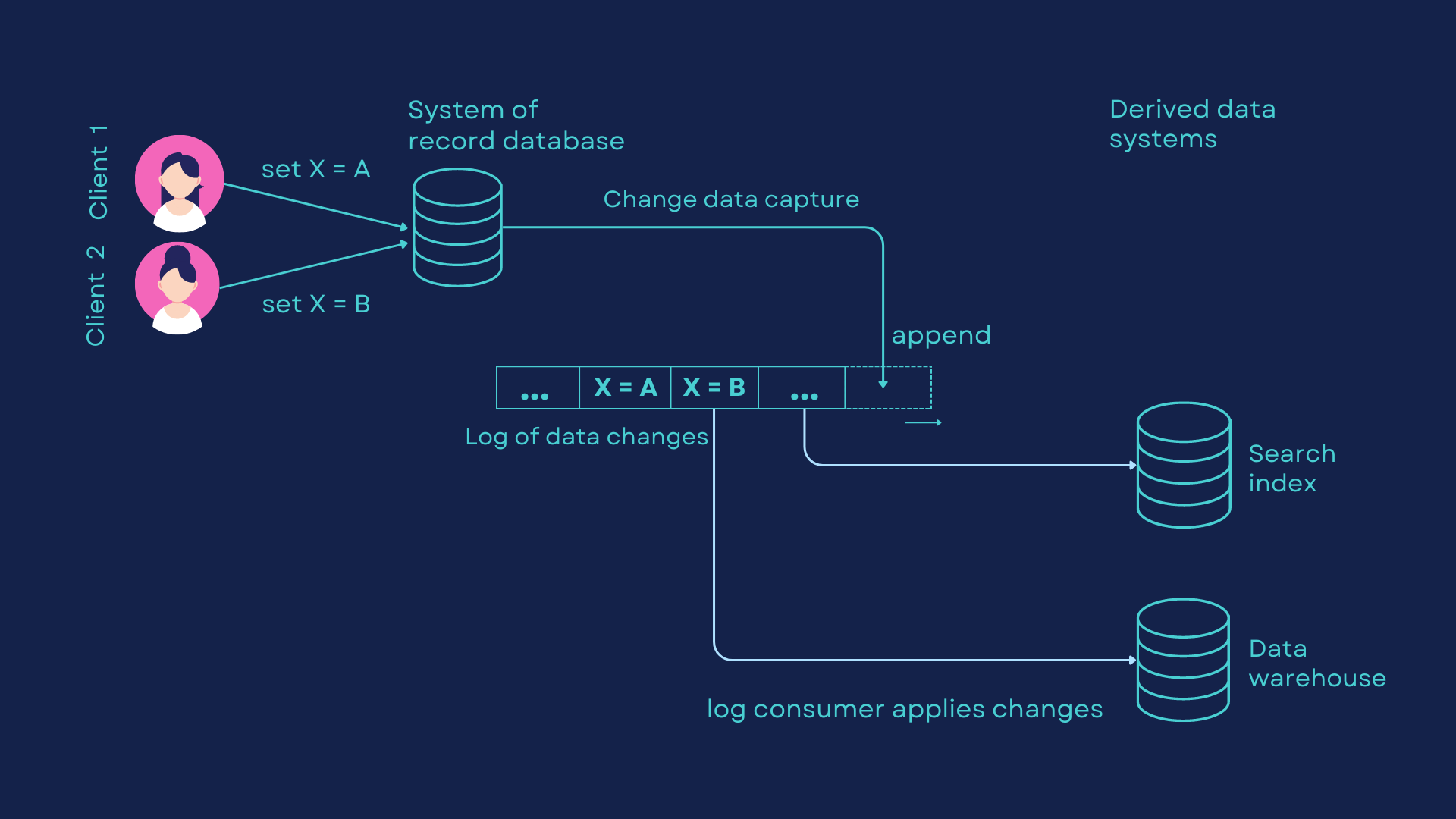
For example, you can capture the changes in a database and continually apply the same changes to a search index. If the log of changes is applied in the same order, you can expect the data in the search index to match the data in the database. The search index and any other derived data systems are just consumers of the change stream, as its shown in the diagram below:
Change Data Capture use cases
There are several use cases for streaming CDC where it shines. As we understood, CDC can detect changes to the database table as soon as any of the following operations INSERT, UPDATE, or DELETE is made. It opens doors for us to process real-time analytics on data.
CDC is commonly used for data synchronization between different data sources. For example, it can be used to synchronize on-premises data to the cloud or if an organization has multiple databases that need to be kept in sync, CDC can continuously capture and propagate changes between them. It can be used for database replication across different environments, such as from production to a staging environment. This ensures that the data in the staging environment is always up-to-date and consistent with the production environment.
Nowadays, many organizations are adopting event-driven architectures by implementing small microservices or a Function as Service (FaaS) that responds to specific changes in the system. In such cases, streaming CDC can help microservices communicate with each other by enabling real-time data sharing.
Change Data Capture with Streaming Database
A streaming database is a type of database that is designed to handle continuous data streams in real-time and makes it possible to query this data. You can read more about how a Streaming database differs from a Traditional database and how to choose the right streaming database in my other blog posts. CDC is particularly useful when working with streaming databases, you can ingest CDC data from directly databases (See an example in the next section) without setting up additional services like Kafka.
If you’re already using Debezium to extract CDC logs into Kafka, you can just set up RisingWave to consume changes from that Kafka topic. In this case, Kafka acts like a hub of CDC data, and beside RisingWave, other downstream systems like search index or data warehouses can consume changes as well.
Also, the streaming database enables downstream systems to stay in sync with the source database and have access to the latest changes made to the data using simple SQL queries. With the help of a streaming database, you can denormalize CDC data via a materialized view where the results of a query (lookup data) are stored in the streaming database's local cache to improve performance. Also, you can query that data from BI and data analytic platforms.
Streaming databases can extract data in real-time from different sources at the same time, and merge and sink data to MySQL using a JDBC connector.
Ingest CDC data from MySQL using the RisingWave connector
Suppose you are working for an e-commerce company that receives a large volume of orders every day. To ensure the timely fulfillment of these orders, you need to process them in real time as they come in.
To do this, you decide to use a streaming database such as RisingWave that can capture changes to the order data stored in MySQL DB using its native MySQL CDC connector. This way, you can read the order data from the database as soon as it's available, and process it in real-time to ensure fast and efficient order fulfillment.
With RisingWave’s MySQL CDC connector, RisingWave can connect to MySQL directly to obtain data from its binary log (binlog) without other stream processing services and manage real-time a materialized view on top of CDC data.
This demo leverages the following GitHub repository where we assume that all necessary things are set up using Docker compose. It will start multiple containers including MySQL with pre-populated inputs. You can see here what are the additional components in this Docker configuration.
Before You Begin
- Ensure you have Docker and Docker Compose installed in your environment.
- Clone the GitHub repository, and run containers with
docker compose up. - Before using the native MySQL CDC connector in RisingWave, you need to complete several configurations on MySQL. See the Set up MySQL section for more details.
- We are going to use the PostgreSQL interactive terminal
psqlfor running queries and retrieving results from RisingWave. Open your CLI, and run the following command to use the PostgreSQL developer tool:psql -h localhost -p 4566 -d dev -U root
Create a Source/Table in RisingWave
For RisingWave to ingest CDC data from MySQL, you must create a table (CREATE TABLE) with primary keys and connector settings.
create table orders (
order_id int,
order_date bigint,
customer_name varchar,
price decimal,
product_id int,
order_status smallint,
PRIMARY KEY (order_id)
) with (
connector = 'mysql-cdc',
hostname = 'mysql',
port = '3306',
username = 'root',
password = '123456',
database.name = 'mydb',
table.name = 'orders',
server.id = '1'
);
Create a materialized view
Let’s assume that we want to calculate the total number of products ordered up to now. Now you can think “We can achieve the same even without using a CDC and streaming database”. Well, you can do so if the Order dataset is static, it doesn’t change frequently and it is in small size. But in reality, there will be many orders, the data changes so frequently, and real-time access to this data is required.
CDC detects newly entered orders quickly and will update target systems with the latest data in near real-time. Then the streaming database takes these changes made to the source table and stores them in a locally cached table called orders respectively. This way CDC data will be persisted in RisingWave for further analysis in real-time with the materialized views. Any materialized view defined on top of this source will be incrementally updated and product count will be calculated behind the scene as new change arrives from CDC.
Now you have the idea of using the CDC, streaming database, and materialized view to deal with fast-changing and rapidly growing orders data.
We can use the following SQL query to create a new materialized view for the product count:
CREATE MATERIALIZED VIEW product_count AS
SELECT
product_id,
COUNT(*) as product_count
FROM
orders
GROUP BY
product_id;
Run a query on the CDC materialized view
Now we can run a simple query on the materialized view we created in the previous step to see actual the number of products ordered by limiting the result to 10 rows:
SELECT
*
FROM
product_count;
Then you can see the output retrieved from Risingwave materialized view in its database:
product_id | product_count
------------+---------------
1 | 1
2 | 2
It does not end, now if you try to insert any new row to MySQL mydb.orders table, it is immediately reflected on the product_count materialized view in RisingWave.
insert into
orders
values
(4, 1558430840000, 'John', 10.50, 1, 1);
New output on product_count materialized view in real-time:
product_id | product_count
------------+---------------
1 | 2
2 | 2
Takeaways
- CDC is capable of detecting changes to the database table, creating change events and later these events will be consumed in real-time by downstream systems.
- The streaming database acts as a stateful stream processor that can materialize the CDC events stream into a table that represents the current state.
- Compared to other relational databases, the streaming database uses a special streaming framework, instead of using a query engine to compute point-in-time results.
- A materialized view in a streaming database can be used to easily obtain, large amounts and rapidly changing data that are difficult to query directly.
Related resources
- how to choose the right streaming database
- How Streaming database differs from a Traditional database?
- Query Real-Time Data in Kafka Using SQL
Recommended content
Community
🙋 Join the Risingwave Community
About the author
Visit my personal blog: www.iambobur.com
Subscribe to my newsletter
Read articles from Bobur Umurzokov directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Bobur Umurzokov
Bobur Umurzokov
𝐖𝐡𝐨 𝐈 𝐚𝐦 Bobur is a developer advocate and speaker specializing in software and data engineering. With over 10- years of experience in IT, he blogs about open-source technologies and the community around them. 𝐖𝐡𝐚𝐭 𝐈 𝐝𝐨 I work with companies at different scales to build awareness, drive adoption, and engage with the community for your developer-targeted products. I also create inspiring content, design, and code use cases, projects, and demo apps to boost learning your product.