ClickHouse Decoded: High Cardinality Use case
 Vignesh Shetty
Vignesh Shetty
Introducing the "ClickHouse Decoded" Blog Series
Welcome to the inaugural blog of the "ClickHouse Decoded" series! Over the past six months, I have been immersed in the world of ClickHouse, gaining hands-on experience with this powerful analytical database. Through this blog series, I am thrilled to share my learnings, insights, and best practices, aiming to provide a comprehensive exploration of ClickHouse's capabilities and nuances.
Whether you're a seasoned data professional or just embarking on your journey with ClickHouse, this series promises to be an invaluable resource. Join me as we unravel the intricacies of this cutting-edge technology, unlocking its potential to revolutionize data analytics and decision-making processes.
In this blog, we will dissect the performance of the count(distinct <exp>) function in ClickHouse, examining how it handles large-scale data and identifying best practices to optimize its execution. Whether you're dealing with user analytics, inventory management, or any other data-intensive task, understanding how to efficiently count distinct values is crucial for accurate and timely insights. Join me as we navigate through the complexities of high cardinality counting in ClickHouse.
In ClickHouse, there are several methods to obtain the exact or approximate count of distinct values. Here's a summary of the different approaches:
Exact Count Methods
Using
COUNT(DISTINCT <exp>): This syntax is used to count the exact number of distinct non-NULL values for an expression. It's a standard SQL aggregate function supported by ClickHouse.Using
uniqExact(<exp>): This function calculates the exact number of different argument values. It is more memory-intensive than some other methods because it does not limit the growth of the state as the number of different values increases.
Approximate Count Methods
Using
uniq(<exp>): This function calculates an approximate number of different values of the argument. It uses an adaptive sampling algorithm and is efficient on the CPU. It is recommended for use in almost all scenarios where an exact count is not necessary. Docs : https://clickhouse.com/docs/en/sql-reference/aggregate-functions/reference/uniq#agg_function-uniqUsing
uniqHLL12(<exp>): This function is an implementation of the HyperLogLog algorithm to count distinct values approximately. It is useful for large datasets where exact counts are not required, and performance is a concern. Docs : https://clickhouse.com/docs/en/sql-reference/aggregate-functions/reference/uniqhll12#agg_function-uniqhll12Using
uniqCombined(<exp>): This function provides an approximation of the number of distinct values. It is a combination of several algorithms and provides a balance between accuracy and memory usage. Docs : https://clickhouse.com/docs/en/sql-reference/aggregate-functions/reference/uniqcombined#agg_function-uniqcombinedUsing
uniqTheta(<exp>): This function is based on the Theta Sketch framework and provides an approximation of the number of distinct values. It is useful for large-scale set approximation. Docs : https://clickhouse.com/docs/en/sql-reference/aggregate-functions/reference/uniqthetasketch#agg_function-uniqthetasketch
Other Methods
Using
array aggregation length(groupUniqArray(<exp>)): This approach involves creating an array of unique values usinggroupUniqArrayand then calculating the length of this array to determine the number of distinct values. Docs : https://clickhouse.com/docs/en/sql-reference/aggregate-functions/reference/groupuniqarrayUsing
groupBitmap(<exp>): This function uses a bitmap data structure to count distinct values. It is particularly useful for counting unique identifiers and can be combined with other bitmap functions for set operations. Docs : https://clickhouse.com/docs/en/sql-reference/aggregate-functions/reference/groupbitmap
Each of these methods has its own use cases and trade-offs in terms of memory usage, performance, and accuracy. When choosing a method, it is important to consider the size of the dataset, the need for exact versus approximate results, and the available system resources. For exact counts, COUNT(DISTINCT <exp>) and uniqExact(<exp>) are the go-to functions, while uniq(<exp>), uniqHLL12(<exp>), uniqCombined(<exp>), uniqTheta(<exp>), and groupBitmap(<exp>) offer various levels of approximation that can be more efficient for large datasets. The groupUniqArray function provides a different approach by leveraging array aggregation.
About dataset - Amazon Customer Review
We will be using Amazon Customer Review dataset provided by Clickhouse, to dig deep into performance metrics comparisons. Docs : https://clickhouse.com/docs/en/getting-started/example-datasets/amazon-reviews
Infra Setup
I will be using ARM based 6 vCPU/24GiB VM for this experiment. Below are the ClickHouse installation steps using Binary.
# Step 1 - Download the ClickHouse Binary
curl https://clickhouse.com/ | sh
# Step 2 - Install ClickHouse Server
clickhouse install
# Step 3 - Start the ClickHouse Service
clickhouse start
# Step 4 - Access the ClicHouse Client
clickhouse client
Table definition
Let's create the table now, we will be using MergeTree Engine ( More about MergeTree Engine Docs : https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree)
-- DDL
CREATE TABLE default.amazon_reviews
(
`review_date` Date,
`marketplace` LowCardinality(String),
`customer_id` UInt64,
`review_id` String,
`product_id` String,
`product_parent` UInt64,
`product_title` String,
`product_category` LowCardinality(String),
`star_rating` UInt8,
`helpful_votes` UInt32,
`total_votes` UInt32,
`vine` Bool,
`verified_purchase` Bool,
`review_headline` String,
`review_body` String
)
ENGINE = MergeTree
ORDER BY (product_category, marketplace)
SETTINGS index_granularity = 8192
-- Ingest data from S3
INSERT INTO default.amazon_reviews SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_2015.snappy.parquet')
LIMIT 25000000
The dataset we're working with comprises approximately 150 million records. However, for the purposes of this experiment, we'll narrow our focus to 25 million records. It's worth noting that ingestion of this dataset typically takes around 400 seconds (ARM based 6 vCPU/24GiB VM).
Among the dataset's columns, customer_id, review_id, and product_id exhibit high cardinality. To streamline our analysis, we'll define filters based on product_category and marketplace, and then order the data accordingly. This step will help organize our exploration and provide clearer insights into the performance metrics of various methods.
Performance Review
-- Rank 1
SELECT
uniqHLL12(customer_id),
uniqHLL12(review_id)
FROM amazon_reviews
GROUP BY product_category
ORDER BY 1 DESC
LIMIT 10
Query id: b2b66920-4c34-45d4-8c57-a67ce840fa28
┌─uniqHLL12(customer_id)─┬─uniqHLL12(review_id)─┐
│ 1671807 │ 3807069 │
│ 1280094 │ 2321535 │
│ 1194487 │ 2026811 │
│ 1129973 │ 1878962 │
│ 1109405 │ 1693040 │
│ 941642 │ 1544744 │
│ 859377 │ 1288617 │
│ 859015 │ 1420599 │
│ 686697 │ 1113271 │
│ 664772 │ 1089432 │
└────────────────────────┴──────────────────────┘
10 rows in set. Elapsed: 0.456 sec. Processed 25.00 million rows, 793.40 MB (54.80 million rows/s., 1.74 GB/s.)
Peak memory usage: 1.28 MiB.
-- Rank 2
SELECT
uniqTheta(customer_id),
uniqTheta(review_id)
FROM amazon_reviews
GROUP BY product_category
ORDER BY 1 DESC
LIMIT 10
Query id: b71819cc-ff45-4cea-91a7-1cfa77c18eae
┌─uniqTheta(customer_id)─┬─uniqTheta(review_id)─┐
│ 1611615 │ 3937768 │
│ 1273902 │ 2294509 │
│ 1207273 │ 1978054 │
│ 1149449 │ 1745828 │
│ 1101125 │ 1637485 │
│ 943519 │ 1546341 │
│ 854932 │ 1252924 │
│ 853327 │ 1383581 │
│ 689702 │ 1109767 │
│ 660556 │ 1073951 │
└────────────────────────┴──────────────────────┘
10 rows in set. Elapsed: 0.583 sec. Processed 25.00 million rows, 793.40 MB (42.89 million rows/s., 1.36 GB/s.)
Peak memory usage: 16.54 MiB.
While hashing customer_id and review_id columns into integers using a suitable algorithm like sipHash64 would indeed facilitate the application of groupBitmap, it's important to note that using groupBitmap on columns with high cardinality might not yield optimal performance. The high cardinality of these columns implies a large number of distinct values, which could lead to significant memory consumption and potentially inefficient processing when employing groupBitmap.
-- Hash 1
ALTER TABLE amazon_reviews
ADD COLUMN `customer_hash` UInt64 DEFAULT sipHash64(customer_id)
-- Hash 2
ALTER TABLE amazon_reviews
ADD COLUMN `review_hash` UInt64 DEFAULT sipHash64(review_id)
-- Query
SELECT
groupBitmap(customer_hash),
groupBitmap(review_hash)
FROM amazon_reviews
GROUP BY product_category
ORDER BY 1 DESC
LIMIT 10
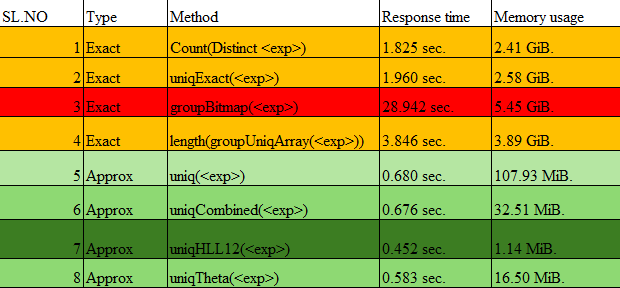
Based on the analysis presented above, it's evident that when directly obtaining an approximate count distinct on raw data, methods such as HLL (HyperLogLog), Theta Sketch, and UniqCombined demonstrate superior performance. These techniques offer efficient solutions for estimating the number of distinct values within the dataset. Specifically, HLL, Theta Sketch, and UniqCombined achieve faster response times and consume significantly less memory compared to exact counting methods like Count(Distinct <exp>) and uniqExact(<exp>).
This efficiency makes them particularly suitable for scenarios where approximate results are acceptable, especially when dealing with large datasets with high cardinality columns like customer_id and review_id.
To be continued, the next blog article will delve into further optimization strategies by leveraging aggregation techniques.
Subscribe to my newsletter
Read articles from Vignesh Shetty directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Vignesh Shetty
Vignesh Shetty
Unlock unprecedented speed and reliability with a backend wizard renowned for transforming sluggish query response times into lightning-fast results. Let's team up and revolutionize your backend operations with unparalleled efficiency and performance optimization.