Case Study: Upgrading Monitoring and Observability with Datadog for a Medium-Scale Company
 TOFADE OLAWALE
TOFADE OLAWALE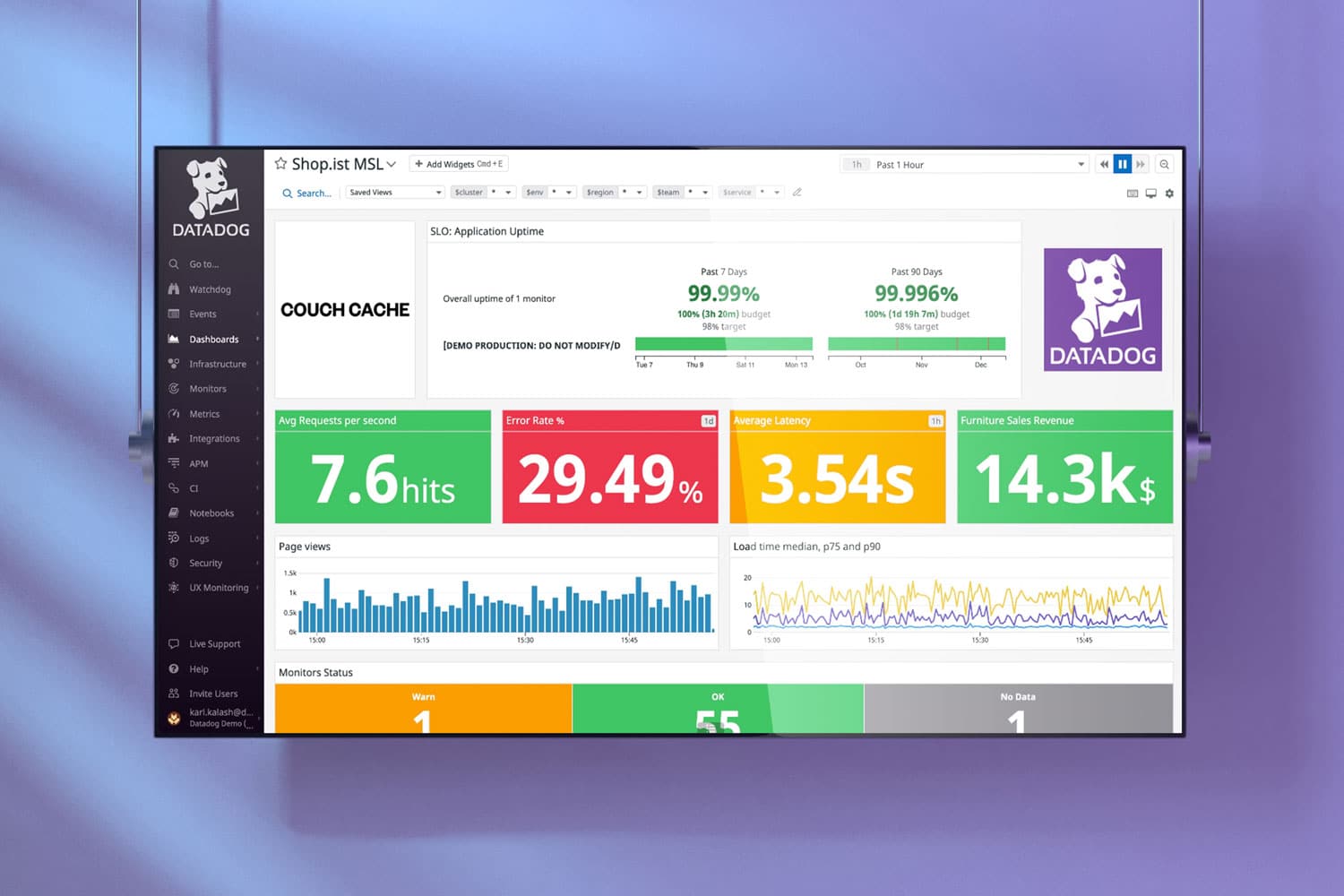
Background
A medium-scale company sought to upgrade its monitoring and observability system from AWS CloudWatch to a more advanced and feature-rich solution. While CloudWatch had been adequate, it did not fully meet their evolving needs. After detailed discussions to understand the company's requirements, we embarked on finding the best tool to address their challenges.
Solution
To address the monitoring needs, we selected Datadog for its ease of integration, active community support, comprehensive features, and cost-effectiveness for this specific use case. The company's infrastructure included an ECS cluster within a private subnet in a VPC, featuring Aurora databases, Kafka, SNS, Redash, and other components. The objective was to ensure Datadog could monitor ECS clusters, track tasks, application events, logs, query executions, and detect anomalies.
Integration and Deployment:
Datadog Integration:
Datadog was configured to query CloudWatch for metrics and tags from ECS.
Datadog Agents were deployed to the ECS clusters to collect metrics, request traces, and logs from Docker and other software running within ECS.
ECS Configuration:
Deployment of Datadog Agents involved declaring a container within the tasks in the ECS cluster.
A Datadog Agent object was added to the
containerDefinitionsarray in the task definition, particularly since the ECS was using a Fargate launch type. This allowed for the collection of system metrics from each container in the cluster.
Dashboard and Alert Creation:
Custom dashboards were built for each team within the development team, providing visibility into deployments, events within clusters, resource utilization (both at the cluster and container level), health checks, and logs.
Alerts were configured and integrated with the company’s Slack channels to ensure real-time notifications for different applications within the ECS clusters.
Application Performance Monitoring (APM):
Datadog APM was set up to trace requests across containers, hosts, and services within the ECS cluster.
This setup enabled the team to gain insights into runtime errors and other application-specific issues, enhancing troubleshooting and optimization efforts.
Benefits
Enhanced Insight: The client gained comprehensive visibility into activities within the ECS cluster.
Improved Troubleshooting: Detailed metrics and logs from Datadog made diagnosing application issues significantly easier.
Proactive Monitoring: Alerts sent to Slack channels enabled developers to react quickly to potential issues, often before they escalated.
Effective Incident Management: Datadog provided valuable information through traces, requests, and logs, facilitating more efficient incident management and resolution.
Lessons
Tool Selection: Choosing a monitoring tool that aligns well with the specific needs and existing infrastructure is crucial for maximizing benefits.
Integration Strategy: Effective integration of monitoring agents and leveraging existing data sources like CloudWatch can enhance the monitoring setup.
Proactive Alerting: Real-time alerts integrated with communication tools like Slack can significantly improve response times to potential issues.
Comprehensive Monitoring: Utilizing APM and detailed dashboards ensures that all aspects of the infrastructure and applications are monitored, aiding in quick troubleshooting and optimization.
Continuous Improvement: Regularly reviewing and updating the monitoring setup based on team feedback and changing requirements ensures the system remains effective and relevant.
Conclusion
Implementing Datadog for monitoring and observability transformed the company's ability to manage its infrastructure. The advanced features and integrations provided by Datadog significantly improved the visibility, reliability, and maintainability of their ECS clusters and associated services. The proactive alerting and detailed insights facilitated better incident management and overall system performance.
Subscribe to my newsletter
Read articles from TOFADE OLAWALE directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
TOFADE OLAWALE
TOFADE OLAWALE
I am just a guy in this corner of the world, writing bugs.