A guide to reading and writing Node.js streams
 Matteo Collina
Matteo Collina
Working with large datasets in Node.js applications can be a double-edged sword. The ability to handle massive amounts of data is extremely handy, but can also lead to performance bottlenecks and memory exhaustion. Traditionally, developers tackled this challenge by reading the entire dataset into memory at once. This approach, while intuitive for smaller datasets, becomes inefficient and resource-intensive for large files.
This is where Node.js streams come in. Streams offer a fundamentally different approach, allowing you to process data incrementally and optimize memory usage. By handling data in manageable chunks, streams empower you to build scalable applications that can efficiently tackle even the most daunting datasets. As popularly quoted, “streams are arrays over time”. In this article, we explore the core concepts of Node.js streams. You'll gain a thorough understanding of how to leverage streams for real-time data processing, memory management, and building scalable applications.
By the end of this guide, you will learn how to create and manage readable and writable streams, and handle backpressure and error management.
What are Node.js Streams?
Node.js streams offer a powerful abstraction for managing data flow in your applications. They excel at processing large datasets like videos or real-time transmissions without compromising performance.
This approach differs from traditional methods where the entire dataset is loaded into memory at once. Streams process data in chunks, significantly reducing memory usage. All streams in Node.js inherit from the EventEmitter class, allowing them to emit events at various stages of data processing. These streams can be readable, writable, or both, providing flexibility for different data handling scenarios.
Event-Driven Architecture
Node.js thrives on an event-driven architecture, making it ideal for real-time I/O. This means consuming input as soon as it's available and sending output as soon as the application generates it. Streams seamlessly integrate with this approach, enabling continuous data processing.
They achieve this by emitting events at key stages. These events include signals for received data (data event) and the stream's completion (end event). Developers can listen to these events and execute custom logic accordingly. This event-driven nature makes streams highly efficient for real-time processing of data from external sources.
Why use streams?
Streams provide three key advantages over other data-handling methods:
Memory Efficiency: Streams process data incrementally, consuming and processing data in chunks rather than loading the entire dataset into memory. This is a major advantage when dealing with large datasets, as it significantly reduces memory usage and prevents memory-related performance issues.
Improved response time: Streams allow for immediate data processing. When a chunk of data arrives, it can be processed without waiting for the entire payload to be received. This reduces latency and improves your application's overall responsiveness.
Scalability for real-time processing: By handling data in chunks, Node.js with streams can efficiently handle large amounts of data with limited resources. This scalability makes streams ideal for applications that process high volumes of data in real time.
These advantages make streams a powerful tool for building high-performance, scalable Node.js applications, particularly when working with large datasets or real-time data processing.
💡***A note on when not to use streams:***If your application already has all the data readily available in memory, using streams might add unnecessary overhead and slow down your application. In such scenarios, traditional methods might be more efficient.
Taming the Flow: Backpressure in Streams
In Node.js streams, backpressure is a critical mechanism for managing data flow between the producer (source of data) and the consumer (destination for data), especially when dealing with large datasets. It ensures the producer doesn't overwhelm the consumer, which could lead to crashes, data loss or performance issues.
Imagine a fire hose - backpressure acts like a valve, regulating the water flow to prevent the consumer (in this case, the person holding the hose) from being blasted away.
Here's the key point: a computer's memory has a finite size. Without backpressure, the producer (like a fire hose) could send data much faster than the consumer (the program processing the data) can store it in memory. This can lead to two problems:
Data Loss: If the data arrives faster than the consumer can handle it, some data might be dropped or discarded entirely.
Performance Issues: The consumer might struggle to keep up with the incoming data, leading to slow processing, crashes, or high memory usage.
Backpressure prevents this by creating a controlled flow. The consumer signals the producer to slow down the data stream if it's reaching its memory capacity. This ensures the data is processed in manageable chunks, avoiding memory overload and data loss.
How Backpressure Works
The main goal of backpressure is to provide a mechanism for the consumer to throttle the producer, ensuring that the data flow does not exceed what the consumer can handle. This is achieved through a controlled buffering system where the stream temporarily holds the data until the consumer is ready to process more.
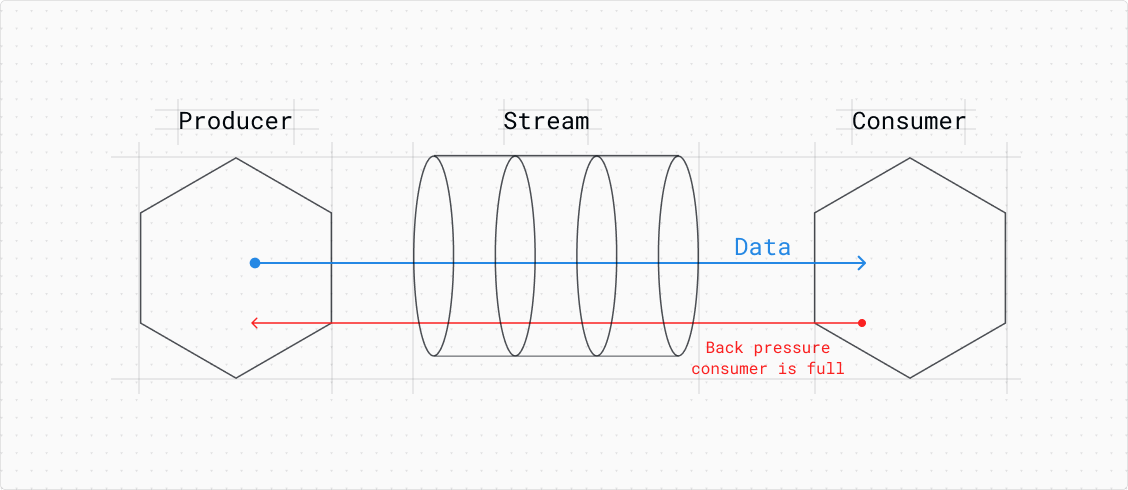
In Node.js streams, this buffering and flow control is managed through an internal property called ‘highWaterMark’. The highWaterMark specifies the maximum number of bytes (for byte streams) or objects (for object streams) that can be buffered internally before additional data reading or writing is paused.
Buffering and Flow Control
Here's a brief overview of how buffering and flow control manage backpressure:
DataProduction: When a producer (like a readable stream) generates data, it fills the internal buffer up to the limit set by
highWaterMark.Buffering: If the internal buffer reaches the
highWaterMark, the stream will temporarily stop reading from the source or accepting more data until some buffers are consumed.DataConsumption: The consumer (like a writable stream) processes data from the buffer. As the buffer level decreases and goes below the
highWaterMark, the stream resumes reading or accepting data, replenishing the buffer.
This backpressure mechanism ensures that the data flowing through the pipeline is regulated, preventing the consumer from being overwhelmed and ensuring smooth, efficient and reliable data processing.
Demo Prerequisites
Ensure you meet the following requirements to follow along with this guide:
- Install Node.js v20. If you're using Linux or macOS, we recommend using Node Version Manager (nvm) to manage your Node.js installations.
nvm install 20
nvm use 20
- Set up your workspace.
mkdir workshop
cd workshop
Install GitHub Large File Storage (LFS) for handling large files.
Clone the Training Repository to get the necessary example code and materials.
git clone https://github.com/mcollina/streams-training.git
Working with Readable Streams
Readable is the class that we use to sequentially read a source of data.
Key Methods and Events
A readable stream operates with several core methods and events that allow fine control over data handling:
on('data'): This event is triggered whenever data is available from the stream. It is very fast, as the stream pushes data as quickly as it can handle, making it suitable for high-throughput scenarios.
on('end'): Emitted when there is no more data to read from the stream. It signifies the completion of data delivery.
on('readable'): This event is triggered when there is data available to read from the stream or when the end of the stream has been reached. It allows for more controlled data reading when needed.
Basic Readable Stream
Here's an example of a simple readable stream implementation that generates data dynamically:
const { Readable } = require('stream');
class MyStream extends Readable {
#count = 0;
_read(size) {
this.push(':-)');
if (this.#count++ === 5) { this.push(null); }
}
}
const stream = new MyStream();
stream.on('data', chunk => {
console.log(chunk.toString());
});
In this code, the MyStream class extends Readable and overrides the _read method to push a string ":-)" to the internal buffer. After pushing the string five times, it signals the end of the stream by pushing null. The on('data') event handler logs each chunk to the console as it is received.
Output
:-)
:-)
:-)
:-)
:-)
:-)
Managing Backpressure with Pause and Resume
Backpressure can be handled by pausing and resuming the stream based on the application's capacity to process the data. Here's how you can implement this:
const stream = new MyStream();
stream.on('data', chunk => {
console.log(chunk.toString());
stream.pause(); // Pause receiving data to simulate processing delay
setTimeout(() => {
stream.resume(); // Resume after 1000ms
}, 1000);
});
In this setup, every time data is received, the stream is paused, and a timeout is set to resume the stream after one second. This mimics a scenario where processing each chunk takes time, thus demonstrating basic backpressure management by controlling data flow using pause() and resume().
Advanced Control with the “readable” Event
For even finer control over data flow, the readable event can be used. This event is more complex but provides better performance for certain applications by allowing explicit control over when data is read from the stream:
const stream = new MyStream({
highWaterMark: 1
});
stream.on("readable", () => {
console.count(">> readable event");
let chunk;
while ((chunk = stream.read()) !== null) {
console.log(chunk.toString()); // Process the chunk
}
});
stream.on("end", () => console.log('>> end event'));
Here, the readable event is used to pull data from the stream as needed manually. The loop inside the readable event handler continues to read data from the stream buffer until it returns “null”, indicating that the buffer is temporarily empty or the stream has ended. Setting highWaterMark to 1 keeps the buffer size small, triggering the readable event more frequently and allowing more granular control over data flow.
>> readable event: 1
:-)
>> readable event: 2
:-)
>> readable event: 3
:-)
>> readable event: 4
:-)
>> readable event: 5
:-)
>> readable event: 6
:-)
>> readable event: 7
>> end event
Async Iterators
Async Iterators are our recommendation as the standard way to model streaming data. Compared to all the streams primitives on the Web and Node.js, Async iterators are easier to understand and to use. In recent versions of Node.js, async iterators have emerged as a more elegant and readable way to interact with streams. Building upon the foundation of events, async iterators provide a higher-level abstraction that simplifies stream consumption.
In Node.js, all readable streams are asynchronous iterables. This means you can use the for await...of syntax to loop through the stream's data as it becomes available, handling each piece of data with the efficiency and simplicity of asynchronous code.
Here's an example demonstrating the use of async iterators with a readable stream:
import { setTimeout as sleep } from 'timers/promises';
async function* generate() {
yield 'hello';
await sleep(10); // Simulates a delay
yield ' ';
await sleep(10); // Simulates another delay
yield 'world';
}
Readable.from(generate()).on('data', chunk => console.log(chunk));
In this example, the generate function is an async generator that yields three pieces of data with deliberate pauses in between, using await sleep(10). This mimics the behavior of an asynchronous operation, such as API calls or database queries, where there is a noticeable delay between data availability.
The Readable.from() method is used to convert this generator into a readable stream. This stream then emits each piece of data as it becomes available, and we handle it using the on('data') event to log in to the console. The output of this code, when run, will be:
hello
world
Benefits of Using Async Iterators with Streams
Using async iterators with streams simplifies the handling of asynchronous data flows in several ways:
Enhanced Readability: The code structure is cleaner and more readable, particularly when dealing with multiple asynchronous data sources.
Error Handling: Async iterators allow straightforward error handling using try/catch blocks, akin to regular asynchronous functions.
Flow Control: They inherently manage backpressure, as the consumer controls the flow by awaiting the next piece of data, allowing for more efficient memory usage and processing.
Async iterators offer a more modern and often more readable way to work with readable streams, especially when dealing with asynchronous data sources or when you prefer a more sequential, loop-based approach to data processing.
Working with Writable Streams
Writable streams are useful for creating files, uploading data, or any task that involves sequentially outputting data. While readable streams provide the source of data, writable streams in Node.js act as the destination for your data.
Key Methods and Events in Writable Streams
.write(): This method is used to write a chunk of data to the stream. It handles the data by buffering it up to a defined limit (highWaterMark), and returns a boolean indicating whether more data can be written immediately.
.end(): This method signals the end of the data writing process. It signals the stream to complete the write operation and potentially perform any necessary cleanup.
Creating a Writable
Here's an example of creating a writable stream that converts all incoming data to uppercase before writing it to the standard output:
import { Writable } from 'stream';
import { once } from 'events';
class MyStream extends Writable {
constructor() {
super({ highWaterMark: 10 /* 10 bytes */ });
}
_write(data, encode, cb) {
process.stdout.write(data.toString().toUpperCase() + '\n', cb);
}
}
const stream = new MyStream();
for (let i = 0; i < 10; i++) {
const waitDrain = !stream.write('hello');
if (waitDrain) {
console.log('>> wait drain');
await once(stream, 'drain');
}
}
stream.end('world');
In this code, MyStream is a custom Writable stream with a buffer capacity (highWaterMark) of 10 bytes. It overrides the _write method to convert data to uppercase before writing it out.
The loop attempts to write hello ten times to the stream. If the buffer fills up (waitDrain becomes true), it waits for a drain event before continuing, ensuring we do not overwhelm the stream's buffer.
The output will be:
HELLO
>> wait drain
HELLO
HELLO
>> wait drain
HELLO
HELLO
>> wait drain
HELLO
HELLO
>> wait drain
HELLO
HELLO
>> wait drain
HELLO
WORLD
How Not to Stream a File Over HTTP
When dealing with streams, especially in the context of HTTP, it's crucial to be mindful of potential problems. Let's look at an example of how not to stream a file over HTTP:
const { createReadStream } = require('fs');
const { createServer } = require('http');
const server = createServer((req, res) => {
createReadStream(__filename).pipe(res);
});
server.listen(3000);
While seemingly straightforward, this code has a hidden danger. If an error occurs during the file reading process (e.g., the file doesn't exist), the error might not be handled properly, potentially crashing the server.
Error Handling in Piping Streams
Handling errors in streams, especially when piping, can be complex due to the possibility of errors in any part of the stream pipeline affecting the entire process. Here's an example:
const fs = require('fs');
const { Transform } = require('stream');
const upper = new Transform({
transform: function (data, enc, cb) {
this.push(data.toString().toUpperCase());
cb();
}
});
fs.createReadStream(__filename)
.pipe(upper)
.pipe(process.stdout);
In this scenario, if an error occurs at any stage (reading, transforming, or writing), it might not be caught, leading to unexpected behavior. Using techniques such as the pipeline() function from the stream/promises module can help manage these errors more effectively.
Using Async Iterators with Pipeline
Combining pipeline with async iterators provides a powerful way to handle stream transformations with minimal buffering:
import fs from 'fs';
import { pipeline } from 'stream/promises';
await pipeline(
fs.createReadStream(import.meta.filename),
async function* (source) {
for await (let chunk of source) {
yield chunk.toString().toUpperCase();
}
},
process.stdout
);
This code achieves the same outcome as the previous example but with better error handling. The pipeline function automatically manages errors within the pipeline, simplifying our code and making it safe from memory overload issues.
By combining the efficiency of streams, the control of backpressure mechanisms, and the elegance of async iterators, you can build high-performance applications capable of handling vast amounts of data with grace and efficiency.
Wrapping up
Streams offer a powerful and efficient way to manage data, particularly for large datasets, real-time scenarios, and memory optimization.
This article explored the fundamental concepts of Node.js streams, learning about readable and writable streams, backpressure, handling errors, and advanced techniques like async iterators.
To see Node.js streams in action and to challenge your newfound skills, check out the examples provided in the streams-training GitHub repository from the prerequisites. Working through these examples will give you practical experience and a stronger grasp of stream handling.
There are much more to streams than the examples in this article. We always suggest using the NodeJS Docs as your primary source when developing a solution for your use case.
Subscribe to my newsletter
Read articles from Matteo Collina directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by