Key Technical Challenges while Transitioning GenAI Applications to Production
 Pablo Salvador Lopez
Pablo Salvador Lopez
Whether you're leading the development of Generative AI apps in a startup or working in a Fortune 500 company, you'll encounter these questions at certain points in your production journey...
"Can my application scale to accommodate a 1000-fold increase in user sessions?" "How can I accelerate response times to enhance user experience?" "How do I measure the quality of my chatbot responses over time?"...and more
In this article, we are diving into these questions, and offering the technical solutions I helped build in one of the largest enterprises in the world.
Demystifying the Shift – From ML to LLM Application Development
Enterprises transitioning from prototype development to production face a new landscape in the GenAI application lifecycle. Most large enterprises don't train their own LLMs; instead, they adapt pre-built models (like Phi-3 🤖) to fit their specific needs—this is known as domain-specific adaptation. This is no longer new; it follows well-defined patterns. Most companies use either the RAG or fine-tuning pattern. Fine-tuning customizes a broad language model to meet specific needs, making it more effective for particular tasks. RAG combines the generative power of language models with the accuracy of a search engine, ensuring responses are relevant and well-informed.
However, the common factor in both approaches is the pre-trained model, a new software artifact where the "learning" is already built in. This shift towards adopting "knowledge as a service" encourages a microservices architecture, moving away from traditional, resource-intensive training and retraining (MLOps cycles) typically managed by data science and ML engineering teams.
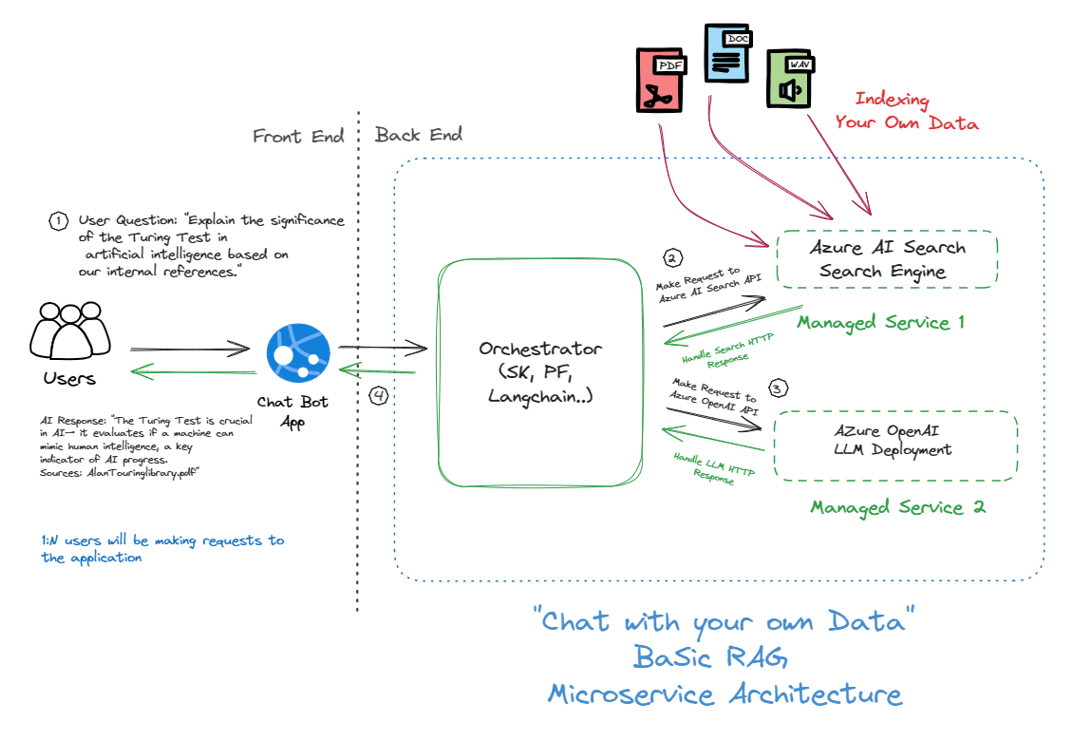
These foundational models are not light (we're talking billions of parameters), and the best way to access them is through an API from your cloud provider, like Azure OpenAI. There are basically two consumption patterns: Model-as-a-Service (MaaS) or Platform-as-a-Service (PaaS). MaaS gives you a super easy, plug-and-play API experience, perfect for quick and hassle-free deployment (Serverless Nature). On the other hand, PaaS offers more control and customization over the models and infrastructure, which is great if you need something more tailored.
So, adopting pre-trained models (MaaS or PaaS) as foundational pieces that act as intelligent layers in our architectures shifts the heavy optimization task from tweaking hyperparameters to orchestrating microservices. For example, "Bring your own data" might seem simple, but the complexity lies in retrieving data and orchestrating multiple services to bring the right data at the right time. The optimization loops occur not at the API level (LLM/SLM) but mostly in making these services harmonious and orchestrating them correctly. This is not as simple as it seems, especially when dealing with enterprise-class security and multiple data sources and formats.
The exponential improvements in AI (as a service) drive the push for this shift...
You will agree with me that this year has been both fun and hectic, especially for AI practitioners. Consider the recent launch of models like GPT-4 Turbo and GPT-4 Omni on Azure OpenAI. They were released just two weeks apart, with the latest one showing a 50% improvement in latency. I spent months working with enterprises to fine-tune system design and reduce latency. Believe it or not, a simple API change achieved what we couldn't manage before due to factors outside our control. This made it possible for many near-real-time apps to go live.
AI as Service era.Focusing the Challenges.
Now that we've discussed adopting the intelligence layer as APIs, let's explore how it all fits together and what we can do to address "system design" issues when working with MaaS and PaaS.
On my journey to production, I always get these four questions from Product and Tech Leads, asked in many different ways but essentially the same...
Throughput: "Can my application scale to support a 1000-fold increase in user sessions? 📈" – A key question that tests the limits of your application’s ability to handle growth.
Latency: "How can I improve my GenAI application's latency? ⏱️" – Essential for ensuring that your application not only functions efficiently but also delivers a seamless user experience.
Evaluation: "Are the outcomes of my GenAI application meeting the expected standards? 🔍" – This is about ensuring that the application performs up to par across various metrics.
Monitoring: "How can I keep a close eye on performance dips and spikes in real-time ? 📊" – Vital for maintaining control over your application’s continuous operational health.
Can my application scale to support a 1000-fold increase in user sessions?
One of the most pressing concerns is whether an application can scale to meet increasing demand, which involves handling increased throughput effectively.
For instance, consider Contoso enterprise deploying a customer service chatbot called WallEGPT 🤖. Initially designed to handle a few hundred human-chatbot interactions daily, the enterprise now needs the chatbot to support a 1000-fold increase in user sessions. At the POC level, this volume of traffic (calls to the APIs) was never brought up, but this is real data from the website. Panic spreads among the developers and reaches the product managers and then leadership...
👨🏾💼 VP of Product to 👩🏻💼 Product Manager:
"Good morning! I was thinking, let’s get WallEGPT integrated on our site. We’re pulling in about a thousand visitors daily now. When do you think we can make that happen?"
👩🏻💼 Product Manager to 👨🏽🔧 Engineering Manager:
"Morning! Quick question for you—do we have the capacity to scale WallEGPT to handle 1000 times the current volume of calls per minute?"
👨🏽🔧 Engineering Manager to 👩🏻💼 Product Manager:
"Hey there! Yes, technically, it’s possible. But we’d need to seriously rethink our system design to smartly handle those pesky 429 API errors we've been seeing at our current traffic. It’s doable, just needs some work and time."
👩🏻💼 Product Manager to 👨🏾💼 VP of Product:
"Sorry for the delay, but before we commit to any dates, engineering needs to redesign some aspects of the backend to handle the demand efficiently. I'll put together some timelines and get back to you soon."
👨🏾💼 VP of Product:
"Oh, that's frustrating. We need this up and running as soon as possible to stay competitive. The CEO is pushing for it. Let's make it happen quickly."
Well, Identified Challenge #1: How do we smartly manage our MaaS or PaaS to avoid hitting those limits? If we do hit those limits, we need clever strategies to redirect traffic and handle unpredictable scalability. And hey, we have a solution, and it's here.
How can I accelerate response times to enhance user experience?
Latency is crucial, especially in applications that need real-time interactions. In my opinion, latency is important in any application, as it quickly distinguishes good engineering from average. I've never liked waiting. While waiting 12 hours for a batch result might meet business needs, if you could get the same results in just 2 minutes, why wouldn't you? Only cost could convince me here. I've always been obsessed with reducing milliseconds wherever possible in every piece of software I've created. This focus has spread to almost every team I work with in today's GenAI industry, where every millisecond matters—not only to engineers but now also to businesses leaders.
Now, let's shift our focus back to Contoso Enterprise. The company has made a breakthrough by adopting WallEGPT 🤖 on their e-commerce platform, which uses a recommendation engine powered by Azure OpenAI. Previously, they were using a fine-tuned ANN algorithm for making suggestions. WallEGPT suggests products based on user behavior and preferences, aiming to deliver these suggestions instantly as users browse the site. However, high latency in generating these recommendations causes delays, leading users to lose interest and potentially abandon their shopping carts. The launch is in danger.
👨🏾💼 VP of Product to 👨🏽🔧 Engineering Manager:
"Good afternoon! Our beta testers report that WallEGPT is frustratingly slow. This could seriously impact our launch. What immediate steps can we take to reduce latency?"
👨🏽🔧 Engineering Manager to 👩🏻🔬 Data Scientist:
"Hello, we're experiencing significant latency issues that are affecting user experience. Could you investigate what might be causing these delays? We suspect it might be related to the AOAI (GPT-4) processing times."
👩🏻🔬 Data Scientist to 👨🏽🔧 Engineering Manager:
"Indeed! We are generating excessively long responses. The transformer architecture impacts token generation time, where more tokens mean more latency. We need to optimize our prompt engineering to streamline responses and reduce the number of tokens. This will require time to evaluate and re-engineer prompts to balance response quality with speed. Additionally, our use of Retrieval-Augmented Generation (RAG) and multiple microservices likely increases latency due to network congestion and deployment across different regions. We should also review the client-side orchestrator, as we have added too many sequential steps and could parallelize tasks more effectively to identify potential bottlenecks."
👨🏽🔧 Engineering Manager to 👩🏼💻 Systems Engineer:
"While the Data Science team is focused on optimizing latency at the application level, we need to thoroughly assess the communication between our managed services. Let’s ensure that our network setup and gateways are not adding to the latency, with a special focus on inter-region latency. We need to identify which services are causing delays..."
👨🏽🔧 Engineering Manager to 👨🏾💼 VP of Product:
"We’re thoroughly investigating the sources of latency. The Data Science and Systems Engineering teams are working on identifying the root causes of end-to-end latency. This might be due to our architectural design, network latency across cloud providers in different regions, and our choice of MaaS. We need more time..."
👨🏾💼 VP of Product closing:
"Oh, I thought it would be a quick fix. We must reduce this latency before we go live. Please keep me updated daily. "
Identified Challenge #2: Dual challenge - identify the sources of latency and speed up requests to enable near real-time scenarios
Click here to dive into how we optimized end-to-end latency in applications leveraging Azure OpenAI (Available Soon)
Are the results of my GenAI application meeting the expected standards?
When you’re rolling out a GenAI solution, proving its worth isn't just important—it's essential. Unlike average software, GenAI needs a thorough evaluation framework to back up its claims of capability and reliability. This isn’t just for the techies; it's for the whole team, from developers to the C-suite, to get on the same page about the application's performance and how it meets expectations.
Clear Metrics Matter: Everyone—from the most seasoned data scientist to the business leader—needs to understand what’s driving quality. Transparent metrics make it easy to see how the model is performing.
Business Alignment is Key: It’s not just about technical mumbo jumbo. You need to connect the dots between tech performance and real business impact. Show how the numbers translate into value.
Trust Doesn’t Come Easy: A solid, transparent framework builds trust by showing that your solution has been put through its paces and meets high standards.
Now, think of Contoso Enterprise and their WallEGPT. It seems the two major blockers have been resolved: latency and throughput, but again release is in danger...
👨🏾💼 VP of Product: "We need WallEGPT to deliver top-notch responses consistently, but how can we measure its reasoning and performance? Is it following responsible AI principles? Is it safe for us to release?"
👨🏽🔧 Engineering Manager: "Good point. Right now, we're somewhat in the dark. Our Data Science team uses public datasets like MMLU to gauge how WallEGPT handles different topics, MedPub for its medical knowledge, and TruthfulQA to ensure it is compliant and meets our thresholds before releasing. However, it's not easy to understand reasoning in practice and the allocation of it comes from the reliable system working in context to the LLM itself."
👨🏾💼 VP of Product: "Well...what is NMLU ? We need hard numbers to prove WallEGPT’s quality and it follows RAI to our stakeholders. How do we get there?"
👨🏽🔧 Engineering Manager: "Yes, this is our main hurdle. We need to nail down some benchmarks and metrics to define what 'quality' actually means for us. But it doesn’t stop there—we also need to automate these evaluations and present the data in a way that everyone can easily understand."
👨🏾💼 VP of Product: "Correct. Please prioritize because until we can clearly quantify and present this data, it’s going to be tough to confidently take WallEGPT to market. Let’s fast-track getting these evaluation systems in place."
Identified Challenge #3: Create an evaluation system for enterprise GENAI that builds trust and aligns development teams, product managers, and business leaders before launch. Use clear, measurable metrics. Here is the solution you are looking for Enterprise LLM/SLM Evaluation: Tools & Strategies (hashnode.dev)
Keeping Your GenAI Application in Check
Alright, you’ve scaled WallEGPT, reduced latency, and ensured it meets the quality bar. But a new challenge starts now—keeping it running smoothly in the wild. Monitoring isn’t just an afterthought; it’s your frontline defense against unexpected issues.
Why It Matters: WallEGPT might be performing well today, but that doesn’t guarantee smooth sailing tomorrow. Real-time monitoring is crucial to detect any performance dips or anomalies before they affect your users. Think of it as having a constant pulse on your app’s operational health.
What to Watch:
Performance Metrics: Keep a close eye on WallEGPT's response times, throughput, and error rates. Are users experiencing delays? Are they abandoning their carts at specific points? User behavior can provide early warnings about performance issues.
System Health: Ensure your backend infrastructure is up to the task, especially as traffic scales. Keep an eye on API limits to avoid hitting those frustrating 429 errors, which can disrupt user experience and damage trust in your platform.
Quality and Responsible AI (RAI): Monitoring doesn’t stop at technical performance. It’s crucial to continuously track the quality of WallEGPT’s responses to ensure they meet the expected standards. This includes verifying that the application adheres to responsible AI principles—ensuring fairness, transparency, and safety in its outputs. Use metrics like coherence and similarity to measure the consistency and appropriateness of the content in WallEGPT's responses, ensuring they align with our standards for accuracy, relevance, and ethical considerations.
Want to see how we set up an efficient monitoring system for GenAI applications? Click here to explore our approach (Available Soon).
Did you find it interesting? Subscribe to receive automatic alerts when I publish new articles and explore different series.
More quick how-to's in this series here: 📚🔧 Azure AI Practitioner: Tips and Hacks 💡
Explore my insights and key learnings on implementing Generative AI software systems in the world's largest enterprises. GenAI in Production 🧠
Join me to explore and analyze advancements in our industry shaping the future, from my personal corner and expertise in enterprise AI engineering. AI That Matters: My Take on New Developments 🌟
And... let's connect! We are one message away from learning from each other!
🔗 LinkedIn: Let’s get linked!
🧑🏻💻GitHub: See what I am building.
Subscribe to my newsletter
Read articles from Pablo Salvador Lopez directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pablo Salvador Lopez
Pablo Salvador Lopez
As a seasoned engineer with extensive experience in AI and machine learning, I possess a blend of skills in full-stack data science, machine learning, and software engineering, complemented by a solid foundation in mathematics. My expertise lies in designing, deploying, and monitoring GenAI & ML enterprise applications at scale, adhering to MLOps/LLMOps and best practices in software engineering. At Microsoft, as part of the AI Global Black Belt team, I empower the world's largest enterprises with cutting-edge AI and machine learning solutions. I love to write and share with the AI community in an open-source setting, believing that the best part of our work is accelerating the AI revolution and contributing to the democratization of knowledge. I'm here to contribute my two cents and share my insights on my AI journey in production environments at large scale. Thank you for reading!