Same Region Replication(SRR) Amazon S3-Replication.
 RAKESH DUTTA
RAKESH DUTTA
Replication helps us store our data with rules and regulations and where or how it will be managed by region replication. Replication helps us keep a copy of our data across different AWS accounts but in the same region. Replication helps us choose or switch ownership of data through backups and protect against accidental deletion.
Data complience and supremacy of Replication : Replication helps us with data compilance and data supremacy through keeping a replica of our data in a different AWS account in the same region like the original.
Aggregated logs of Replication : Replication helps us with merging logs from another s3 bucket into one bucket for processing the same region.
Replication in different accounts : Replication helps us to replicate object and metadata between different accounts, like testers and developers accounts.
Variable account ownership : Replication helps us to change ownership for the replicated object or metadata to protect it from accidental deletation.
Critical data recovery : Replication helps us with backing-up of critical data when compilance does’nt allow to move tha data within region.
In a nutshell Replication is responsible for keeping our data safe within a same region and also in different accounts.
Step 1 : On the AWS console we heading towards S3 bucket and hit create bucket with the name along ‘buck-origin’ and another one is ‘buck-demo’ with enabling bucket versioning.
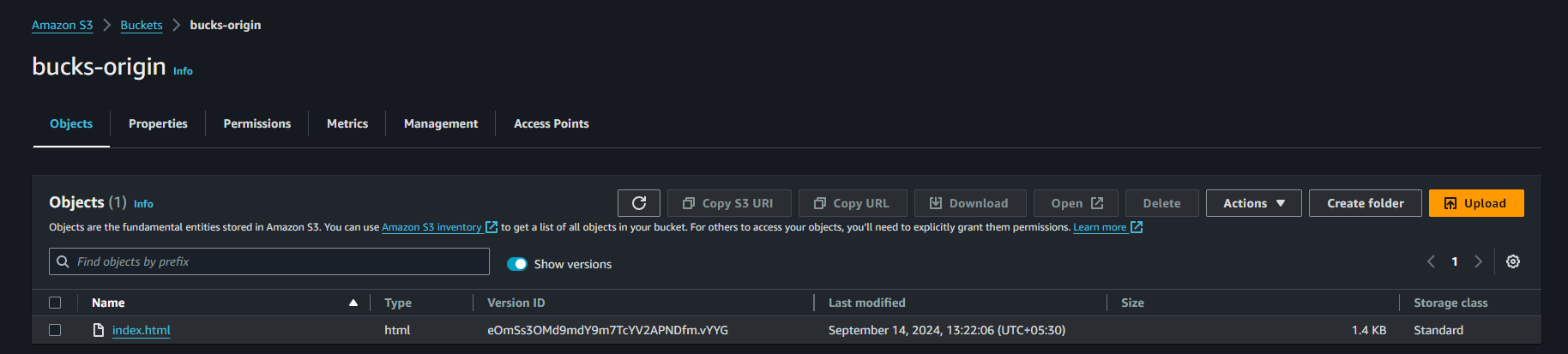
Step 2 : Put some object or data on bucks-origin with enabling versioning.
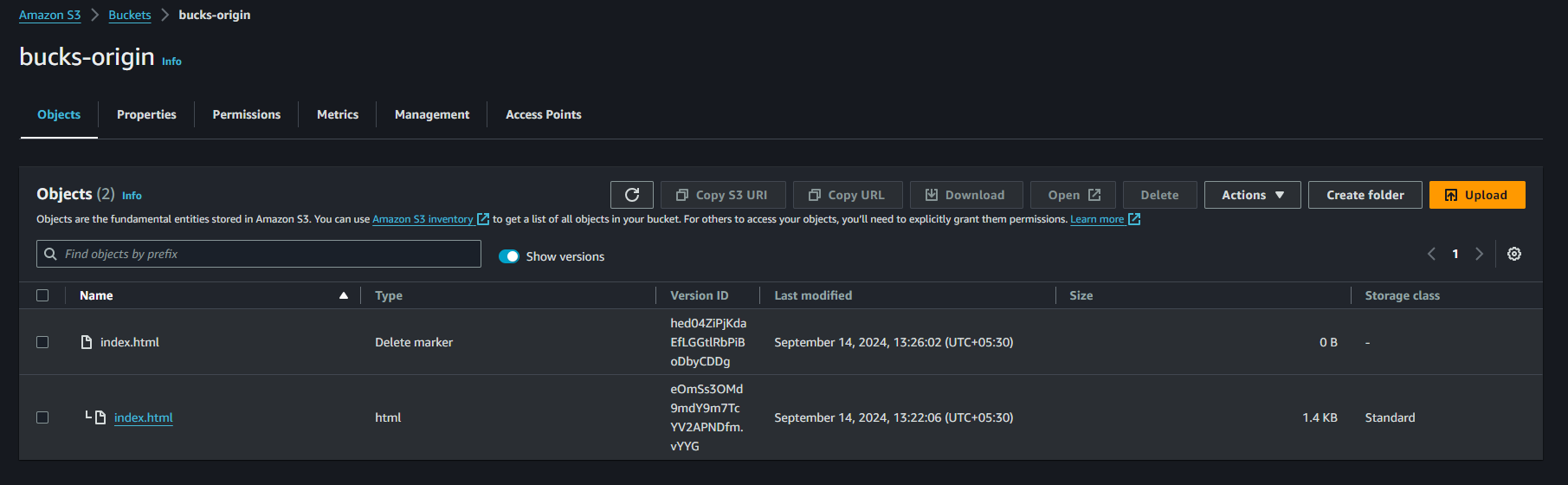
Step 3 : Here we can see the our origin bucket have the both original data and version data also.
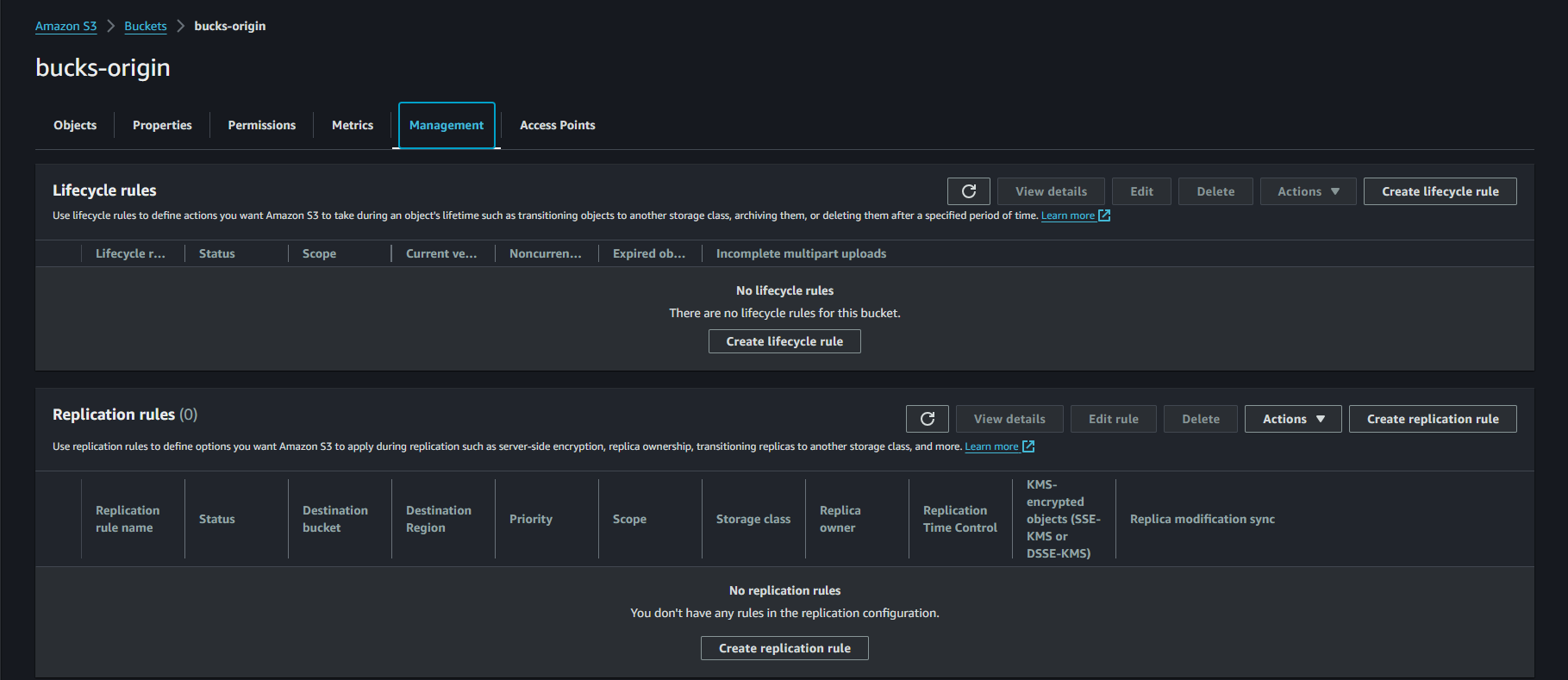
Step 4 : Here we are going to allow replication on bucks-demo which is our replication bucket of buks-origin. So on the management after the scroll we can see replication rule, we’ll set it up for our replication. Here we’ll also add the the delete marker replication also. Here is those steps to create replication rule for replication bucket.
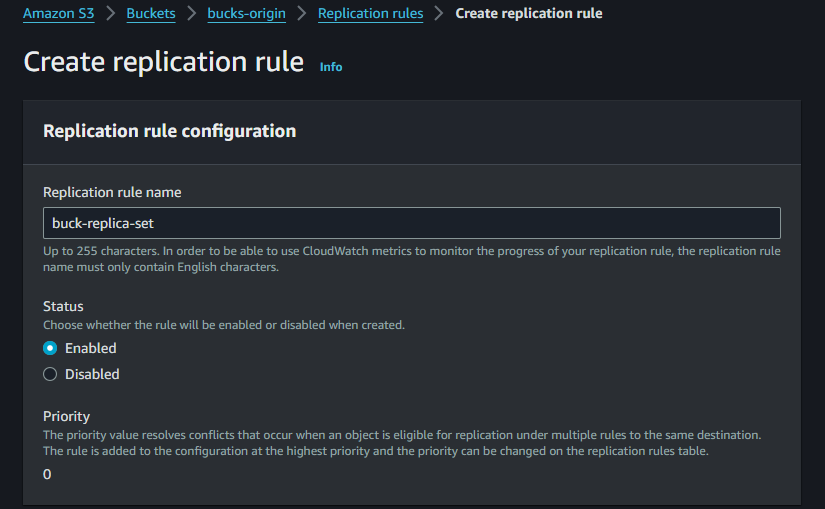
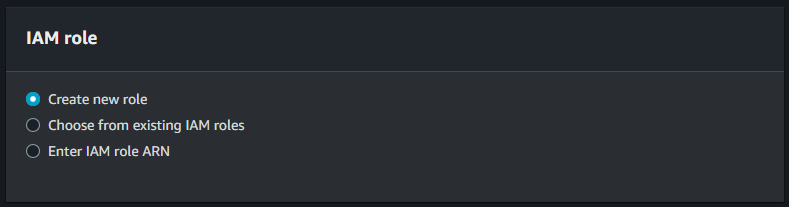
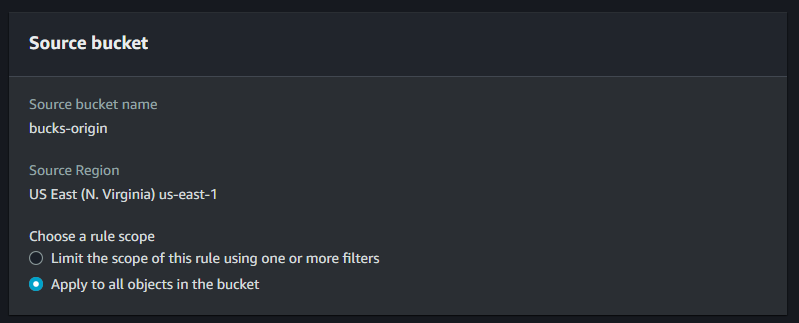
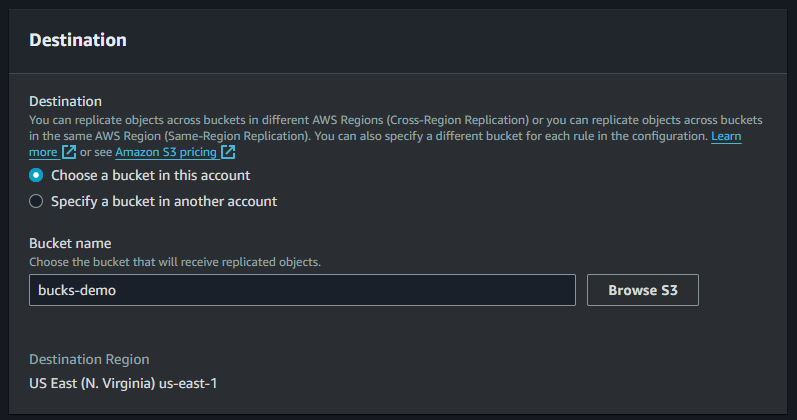
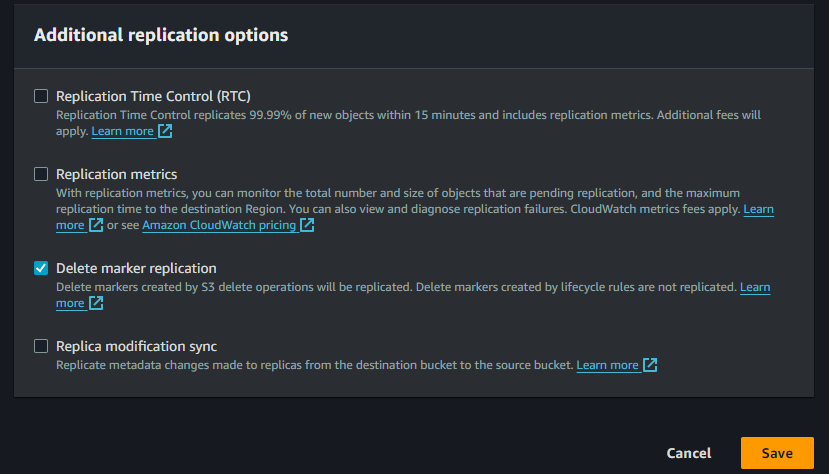
Here is our replication rule for bucket which define the source of the bucket.

Step 5 : Here on the bucks-origin we wll erase the data which we uploaded from local to bucket earliar. Here we can see we delete the data.
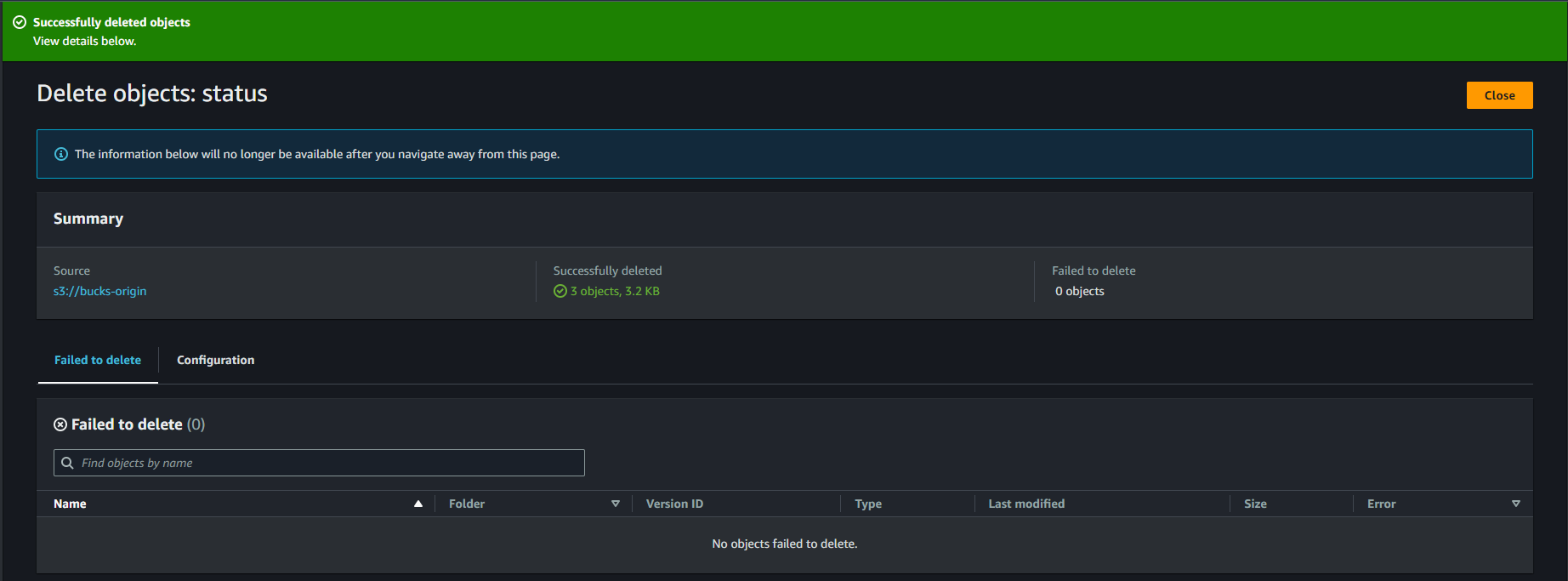
Step 6 : After enebling the replication for buck-demo which is our replication bucket there our uploaded object will be present and if we delete this data or object with agreee or by accidentally.
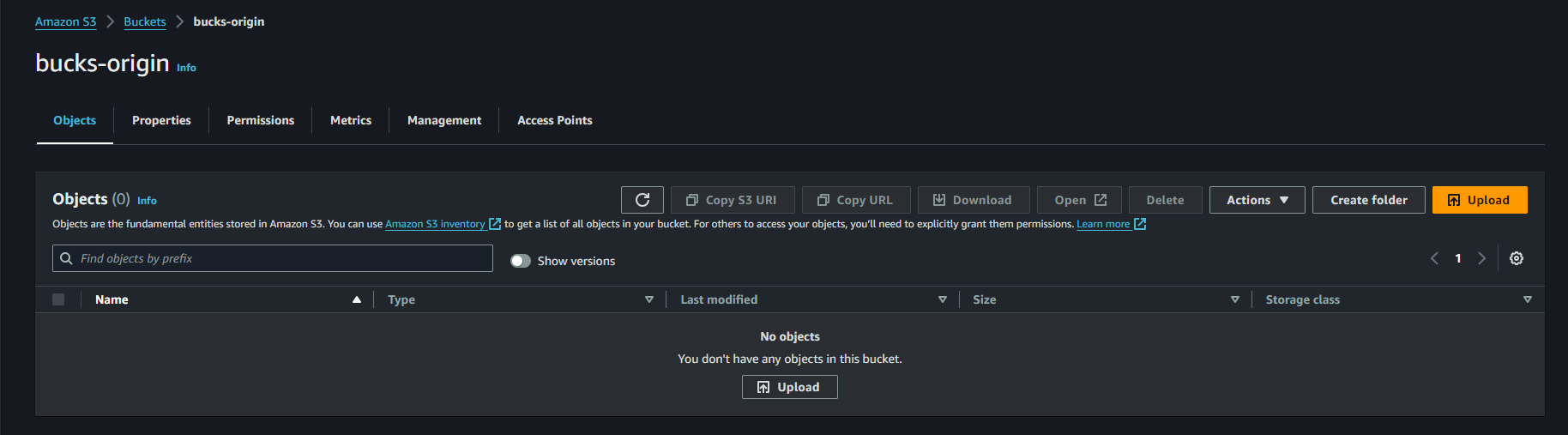
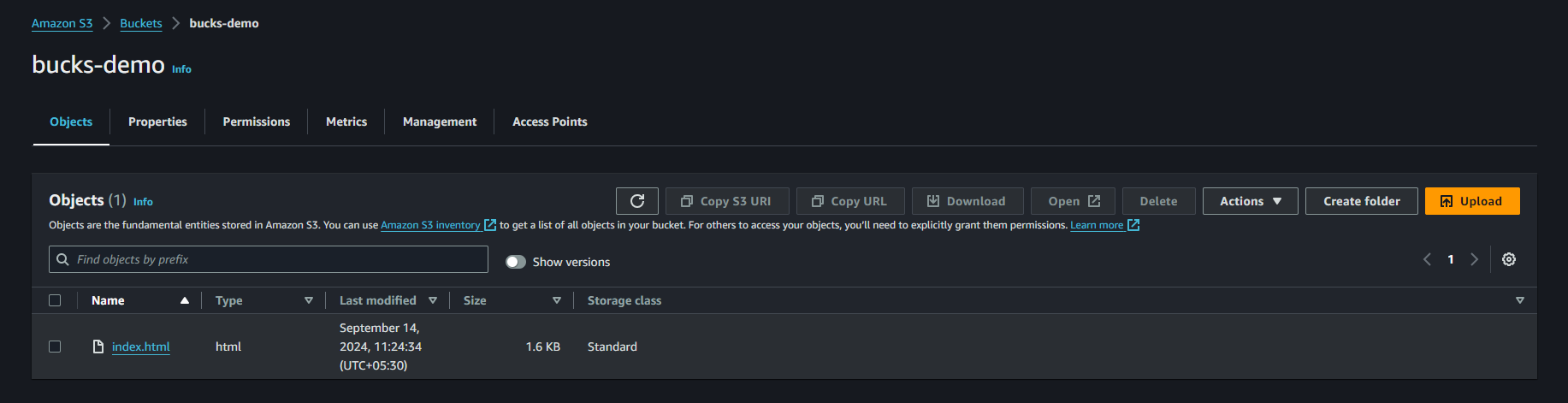
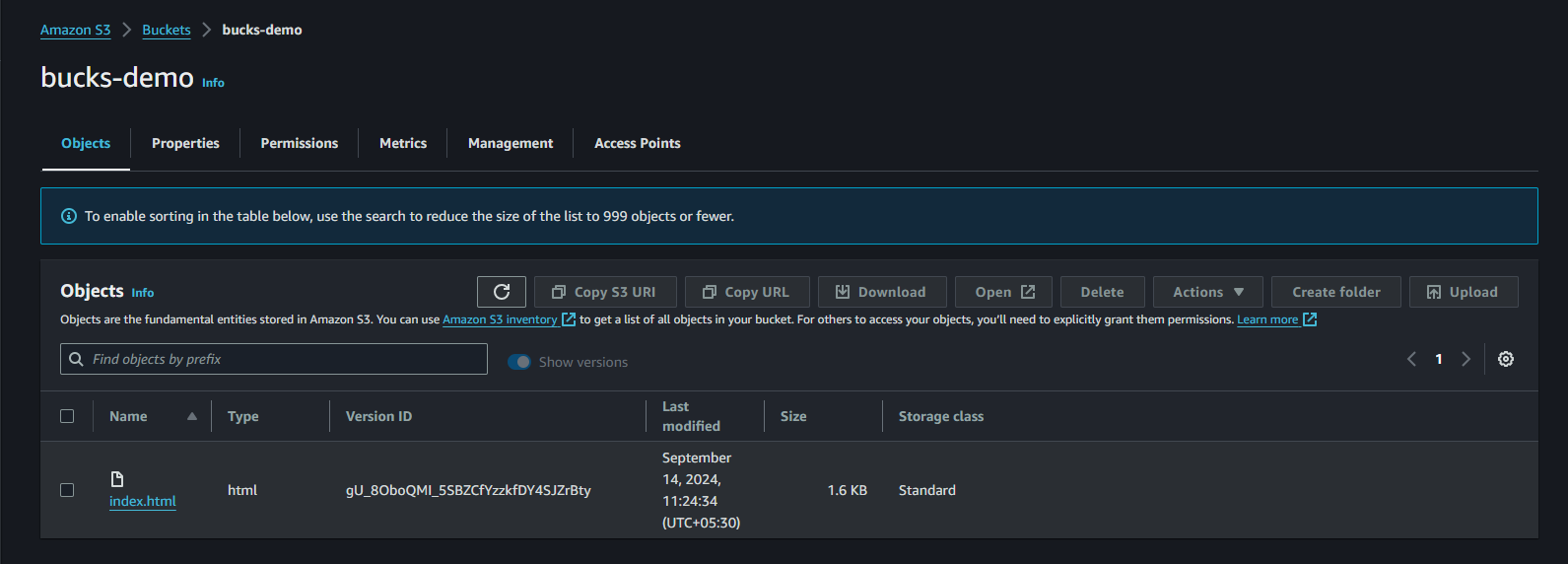
Step 7 : If we waive off the data which is stored on our bucks-origin S3 bucket and replicated on bucks-demo bucket we can we there data will be still present cause we tick delete marker replication when we creating replica set for bucks-demo.
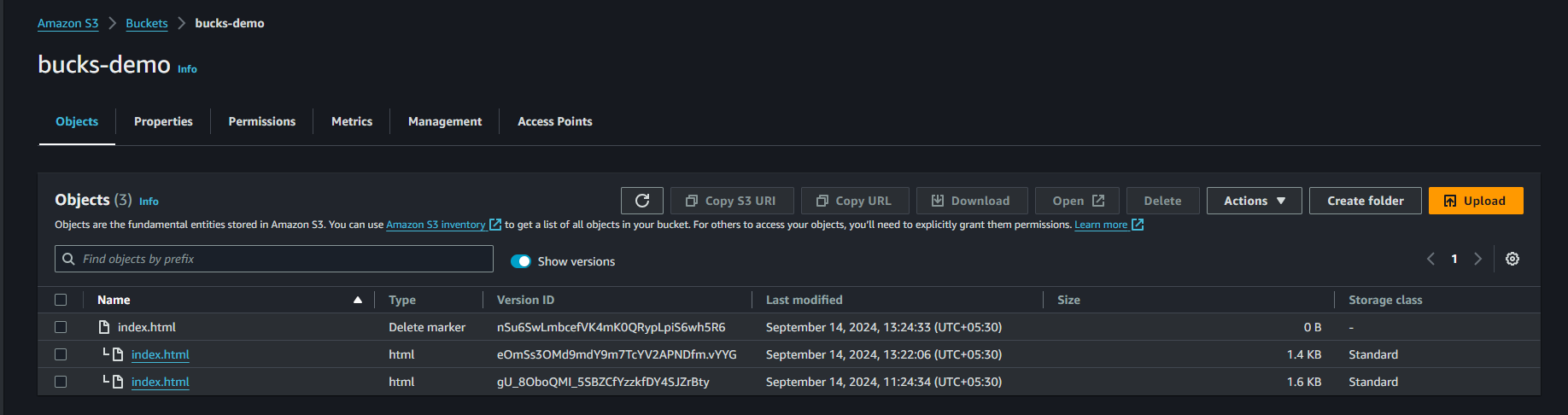
Here we can see how to can retrive our data or object which kept on our s3 bucket here we can easily save our data or retrive our data by doing s3 SRR same region replicaton.
thank Yu !!
Subscribe to my newsletter
Read articles from RAKESH DUTTA directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by