ClickHouse Aggregations and Django
 Wolfram Kriesing
Wolfram Kriesing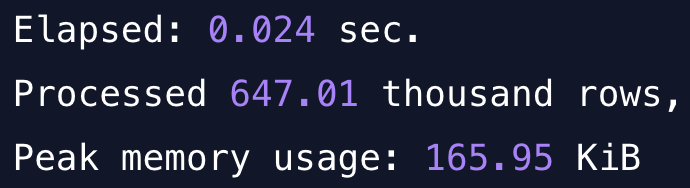
In the first clickhouse article I said my use case is web performance data, huge data set, which brought me to the column-oriented database ClickHouse. When analyzing large datasets, metrics like median, average and quantiles are essential. In web performance data we mostly look at p75 (the 75th percentile), removing the slowest 25%. This gives a better picture of the audience visiting a website in the web performance case.
SELECT quantile(0.75)(ttfb)
This is how you can select a p75 value in a ClickHouse query. Using the same data as in the first blog post, the tutorial’s NY taxi data, reading the p75 of the trip distances would look like this:
SELECT quantile(0.75)(trip_distance) FROM trips;
Quite a simple query, compared to how it would need to be done in mariadb, which is a row-oriented database, so the comparison might not be fair, each has their strengths (and I use them both).
ClickHouse reports back in 33 milliseconds, using 90 kB of memory (peak). Cool.
┌─quantile(0.75)(trip_distance)─┐
1. │ 3.3 │
└───────────────────────────────┘
1 row in set. Elapsed: 0.033 sec.
Processed 2.00 million rows, 16.00 MB (60.47 million rows/s., 483.74 MB/s.)
Peak memory usage: 90.00 KiB.
Reading the ClickHouse docs about the quantile function I learned why this can be so amazingly fast and that it is not accurate. Surprise.
SELECT quantileExact()()
The precise version of this is quantileExact, let’s try it out.
SELECT quantileExact(0.75)(trip_distance) FROM trips;
┌─quantileExact(0.75)(trip_distance)─┐
1. │ 3.3 │
└────────────────────────────────────┘
1 row in set. Elapsed: 0.059 sec.
Processed 2.00 million rows, 16.00 MB (33.99 million rows/s., 271.94 MB/s.)
Peak memory usage: 26.53 MiB.
I still love the query stats right below. Here it took 59 milliseconds, almost double the time and 26 MB peak memory. Compared to the 90 kB above this is quite a difference. Now the value is not different, so we might have optimal data and less variance in the values. Running other queries like for the tip_amount or the total_amount shows that the values are not always the same.
p75 for ClickHouse in Django
I tried a lot of ways, and with todays tooling and many wrong corners of “knowledge” on the web finding the right path ends often up in reading source code. Thanks django-clickhouse-backend for being open source.
In Django one can implement a class, which must inherit from the clickhouse package’s Aggregate class, not the django one (I made that mistake before).
from clickhouse_backend.models.aggregates import Aggregate
class Percentile75(Aggregate):
function = 'quantile(0.75)'
Use it in a django query like this:
Entry.objects
.values('site_id')
.annotate(p75=Percentile75('ttfb'))
# results in something like this
<QuerySet [
{'site_id': 42, 'p75': 121.0},
{'site_id': 23, 'p75': 118.0},
{'site_id': 21, 'p75': 512.0}
]>
The above groups all the rows by site_id and returns the p75 values for each. The query that results out of this looks just like what we expect.
>>> Entry.objects.values('site_id')
.annotate(p75=Percentile75('ttfb')).query.__str__()
'SELECT site_id, quantile(0.75)(ttfb) AS p75
FROM entry
GROUP BY site_id'
# formatted for readability
The query was very quick, as expected, 24 milliseconds and just 165 kB of memory usage.
Elapsed: 0.024 sec.
Processed 647.01 thousand rows, 10.35 MB (27.52 million rows/s., 440.32 MB/s.)
Peak memory usage: 165.95 KiB
I would be very curious about comparable data timings in MariaDB but I believe if we do not get to table sizes of tens or hundreds of millions of rows we will not see a huge difference in speed, maybe in memory sooner.
Many Aggregates in one Query
Extending the above query can be as simple as adding a couple more of these quantile classes and using them in the query.
from clickhouse_backend.models.aggregates import Aggregate
class Percentile75(Aggregate):
function = 'quantile(0.75)'
class Percentile90(Aggregate):
function = 'quantile(0.9)'
class Percentile95(Aggregate):
function = 'quantile(0.95)'
class Percentile99(Aggregate):
function = 'quantile(0.99)'
# in the python shell
# read all the percentiles and the max value in one query
>>> ClickhousePerformanceEntry.objects.values('site_id')
.annotate(p75=Percentile75('ttfb'),
p90=Percentile90('ttfb'),
p95=Percentile95('ttfb'),
p99=Percentile99('ttfb'),
max=Max('ttfb')
)
<QuerySet [
{'site_id': 42, 'p75': 111.0, 'p90': 140.0, 'p95': 164.0, 'p99': 377.0, 'max': 377},
{'site_id': 23, 'p75': 204.0, 'p90': 560.9000000000005, 'p95': 951.4499999999998, 'p99': 2877.890000000003, 'max': 65705},
{'site_id': 21, 'p75': 49.0, 'p90': 292.0, 'p95': 546.0, 'p99': 2563.2700000000004, 'max': 30316}
]>
For the query above the time the query takes stays more or less the same just the memory climbs, but the resources need to be used somehow. Right?
Finally
Aggregating even huge amount of data and calculating quantiles and alikes ClickHouse is made for this. I just scratched the surface with this, if you need more dedicated aggregate functions ClickHouse even comes with quantileTiming, quantileExactWeighted, quantileInterpolatedWeighted and so many more. I assume if you know what statistical method you need you have already guess this.
Remember: good aggregation also needs proper (data) preparation!
Subscribe to my newsletter
Read articles from Wolfram Kriesing directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Wolfram Kriesing
Wolfram Kriesing
I am currently building a startup for monitoring website speed, but not the Core Web Vitals, but the numbers behind the curtain that you can monitor and really get a grip on. Wanna know more? Ping me!