⭐ Reducing LLM Costs & Latency with Semantic Cache
 Kavya
KavyaImplementing semantic cache from scratch for production use cases.
Vrushank Vyas
Jul 11, 20235 min

Image credits: Our future AI overlords. (No, seriously, Stability AI)
Latency and Cost are significant hurdles for developers building on top of Large Language Models like GPT-4. High latency can degrade the user experience, and increased costs can impact scalability.
We've released a new feature - Semantic Cache, which efficiently addresses these challenges. Early tests reveal a promising ~20% cache hit rate at 99% accuracy for Q&A (or RAG) use cases.
Picture this: You've built a popular AI application, and you're processing a lot of LLM API calls daily. You notice that users often ask similar questions - questions you've already answered before. However, with each call to the LLM, you incur costs for all those redundant tokens, and your users have a sub-par experience.
This is where Semantic Cache comes into play. It allows you to serve a cached response for semantically repeated queries instead of resorting to your AI provider, saving you costs and reducing latency.

Examples of search & support queries served through Portkey
To illustrate the extent of semantic similarity covered and the time saved, we ran a simple query through GPT3.5, changing it a little each time and noting down the time.

Despite variations in the question, Portkey's semantic cache identified the core query each time and provided the answer in a fraction of the initial time.
We also ran the same test on a set of queries that may look similar but require different responses.

While this is a promising start, we are committed to enhancing cache performance further and expanding the breadth of semantic similarity we can cover.
In Q&A scenarios like enterprise search & customer support, we discovered that over 20% of the queries were semantically similar. With Semantic Cache, these requests can be served without the typical inference latency & token cost, offering a potential speed boost of at least 20x at zero cost to you.
📈 Impact of Caching
Let's look at the numbers. Despite recent improvements in GPT 3.5's response times through Portkey, it's evident that cached responses via our edge infrastructure are considerably quicker.
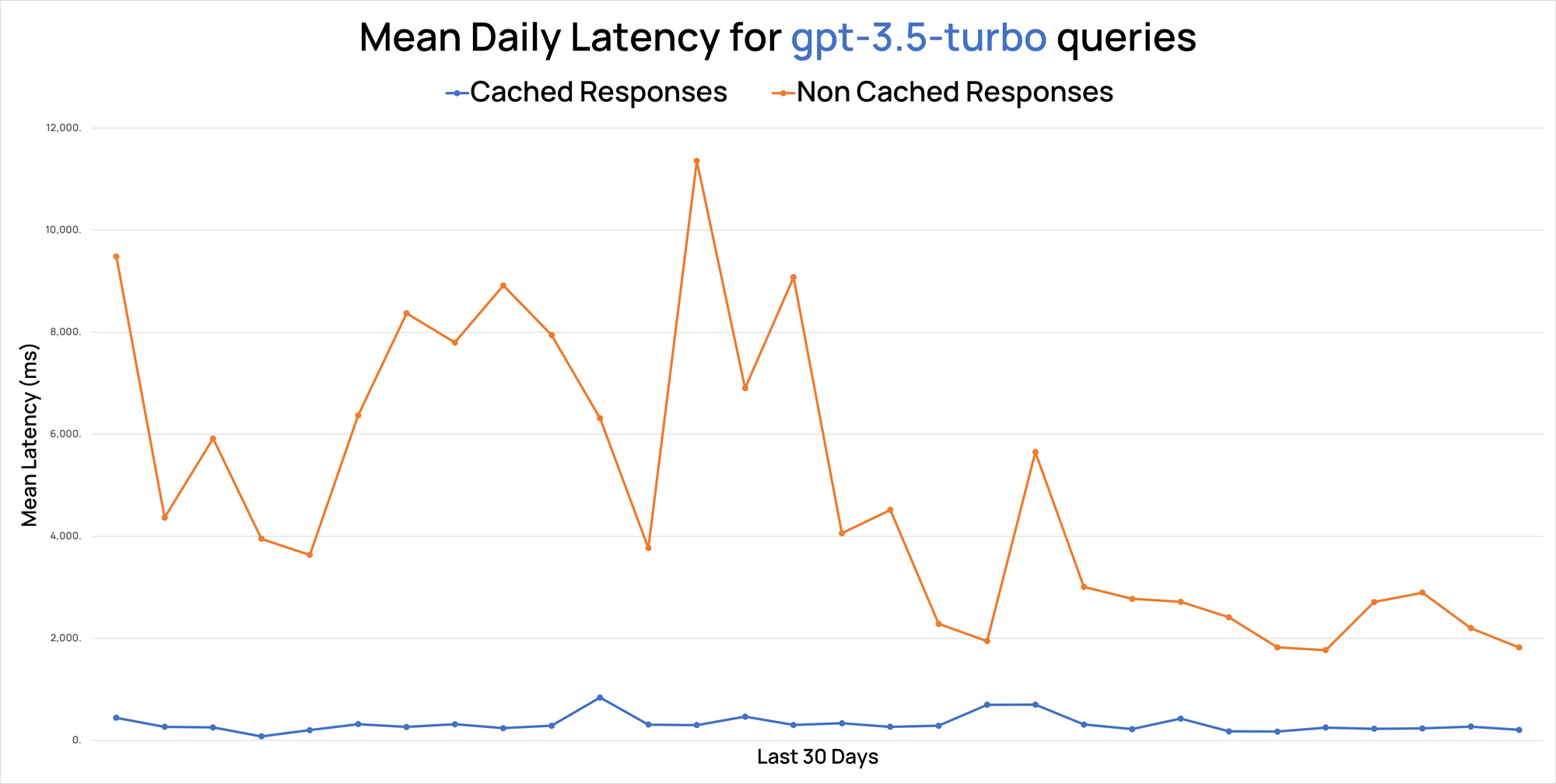
Chart on mean daily latency for request served through Portkey & Portkey cache
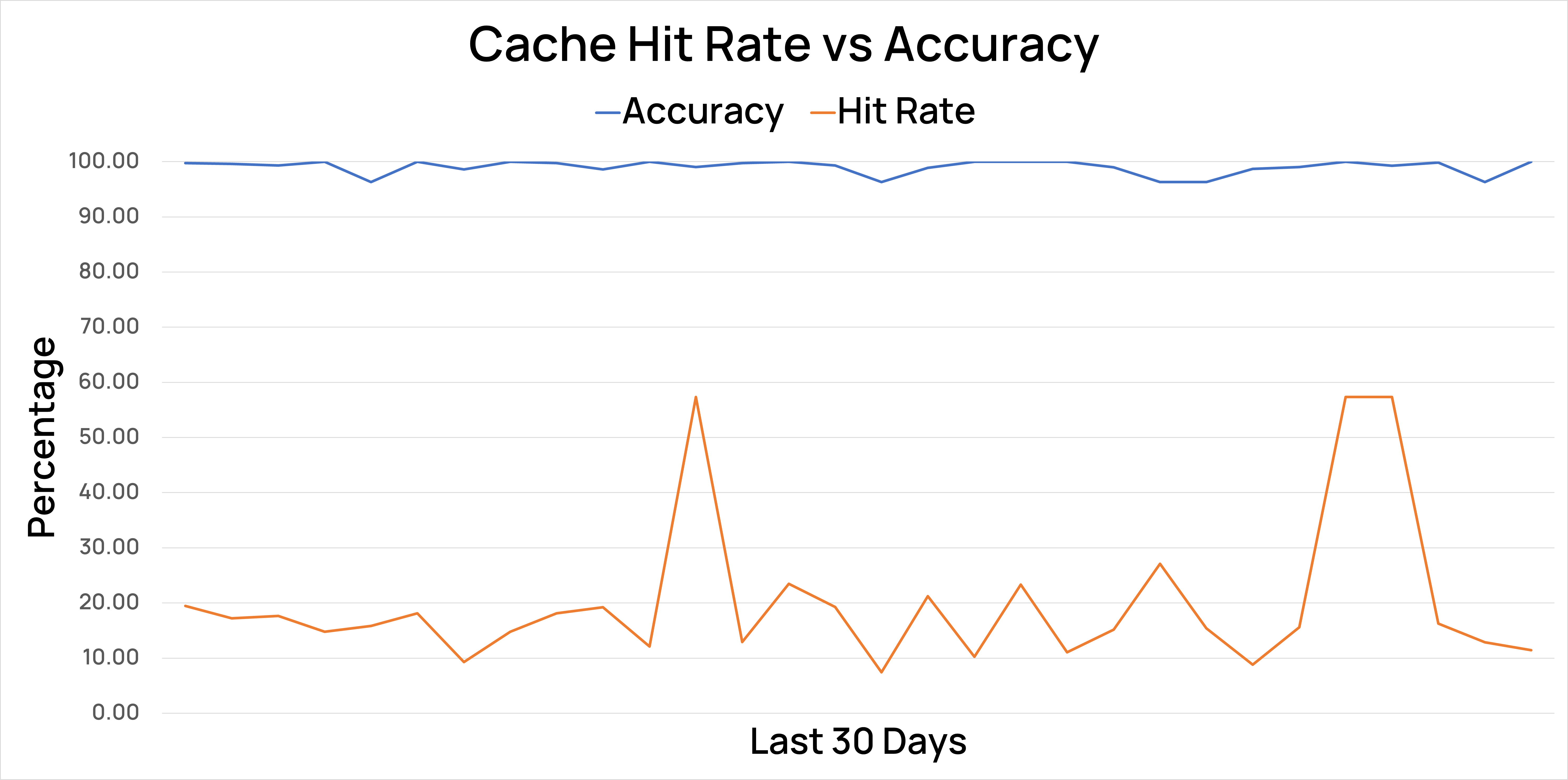
In RAG use cases, we observed a cache hit rate ranging between 18% to as high as 60%, delivering accurate results 99% of the time.
If you believe your use case can benefit from the semantic cache, consider joining the Portkey Beta.
🧮 Evaluating Cache Effectiveness
Semantic Cache's effectiveness can be evaluated by checking how many similar queries you get over a specified period - that's your expected cache hit rate.
You can use a model-graded eval to test the semantic match's accuracy at various similarity thresholds. We’d recommend starting with a 95% confidence and then tweaking it to ensure your accuracy is high enough to perform a cache call.
Here's a simple tool that calculates the money saved on GPT4 calls based on the expected cache hit rate.
Visit Portkey blogs to try it out.
🎯 Our Approach To Semantic Cache
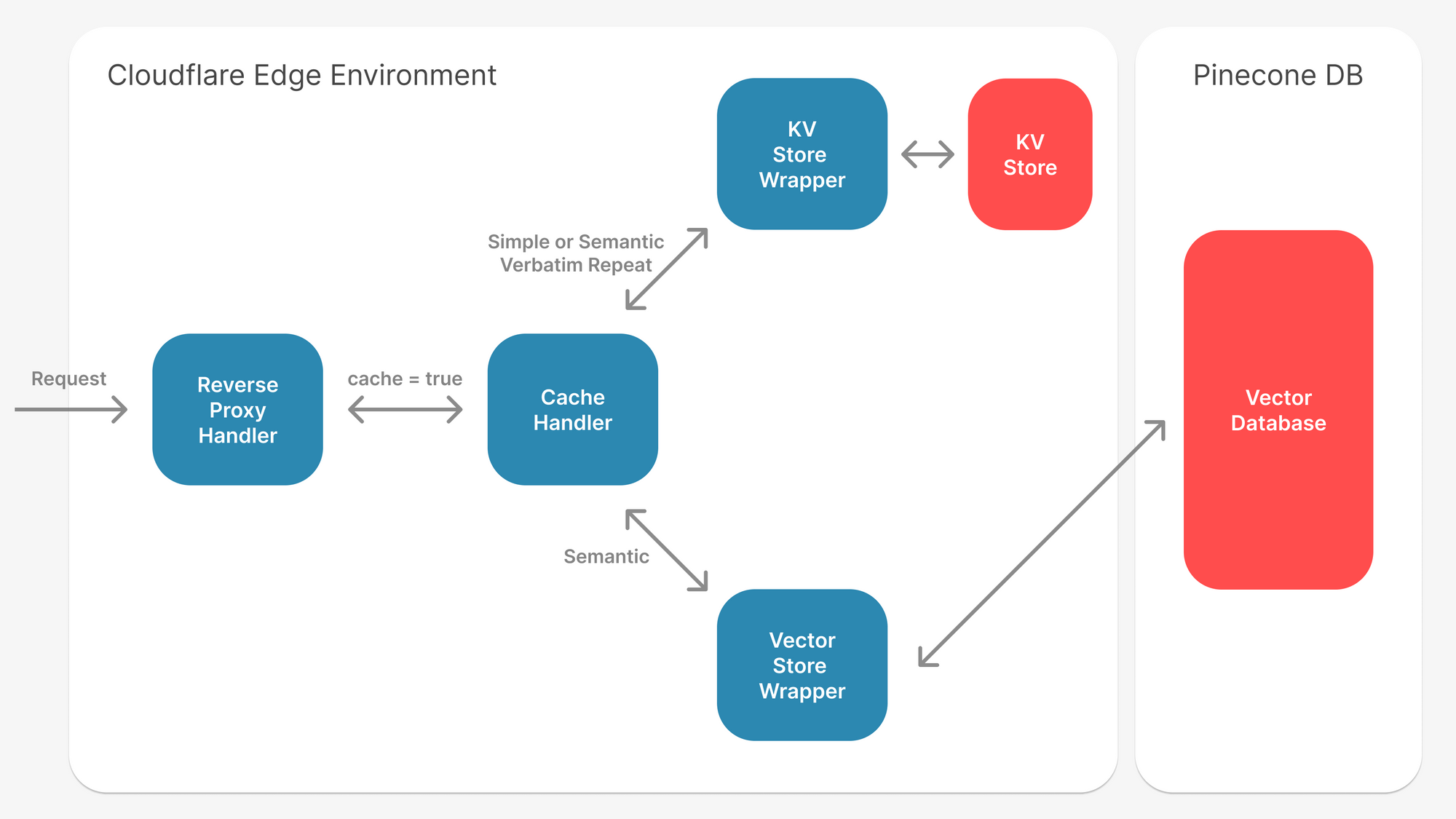
First, we check for exact repeat queries, leveraging Cloudflare’s key-value store for quick and efficient responses.
For unique queries, we apply a vector search on Pinecone, enhanced with a hybrid search that utilizes meta properties inferred from inputs. We also preprocess inputs to remove redundant content, which improves the accuracy of the vector search.
To ensure top-notch results, we run backtests to adjust the vector confidence individually for each customer.
🧩 Challenges of using Semantic Cache
Semantic Cache, while efficient, does have some challenges.
For instance, while a regular cache operates at 100% accuracy, a semantic cache can sometimes be incorrect. Embedding the entire prompt for the cache can also sometimes result in lower accuracy.
We built our cache solution on top of OpenAI embeddings & Pinecone's vector search. We combine it with advanced text manipulation & hybrid search inferred from metadata to remove irrelevant parts of the prompt.
We only return a cache hit if there is >95% confidence in similarity.
In our tests, users rated the semantic cache accuracy at 99%.
Additionally, improper management could potentially lead to data and prompt leakage.
We encrypt the whole request with
SHA256and run our cache system on top of it to prevent containment.Each organization's data, prompts, and responses are encrypted and secured under different namespaces to ensure security.
Additional metadata stored as part of the vector also mitigates leakage risks.
How to Use Semantic Cache on Portkey
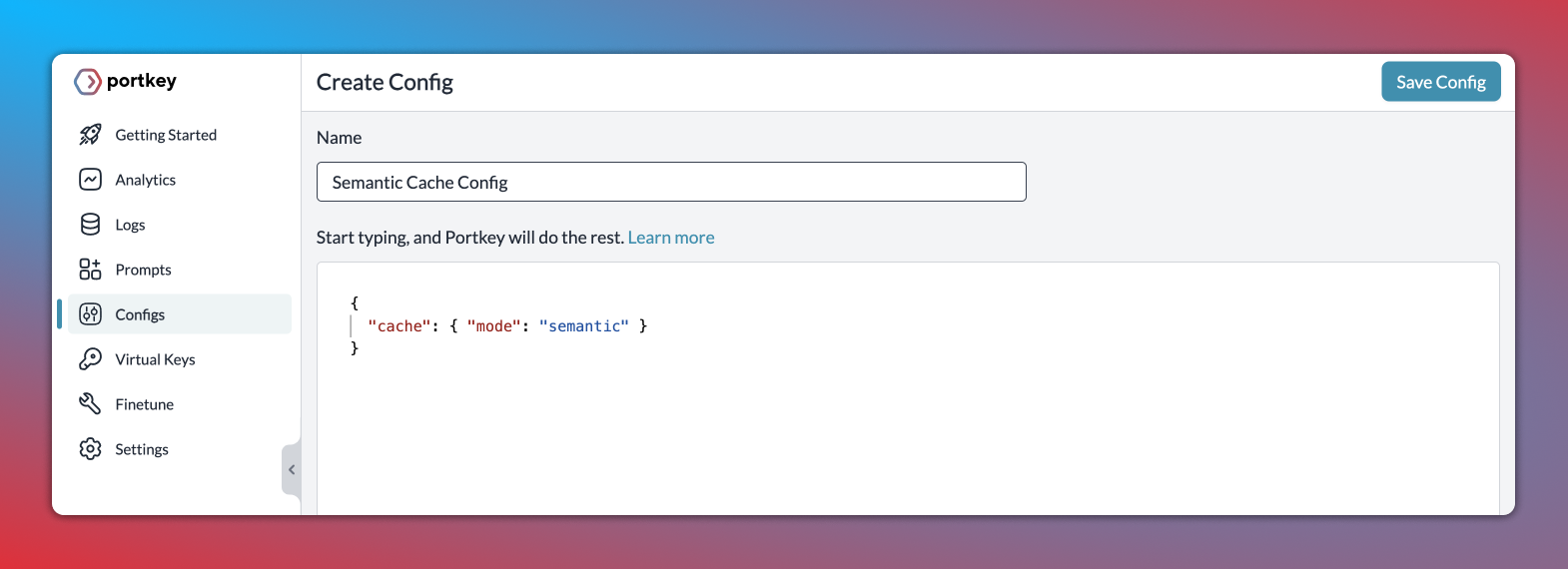
Step 1: Enable semantic cache in Portkey's Config object
Just set the cache mode as semantic and save the Config↓
{
"cache": { "mode": "semantic" }
}
Step 2: Pass the Config ID while making your request
In the Portkey SDK, you can pass the config ID while instantiating the client and then make your request just as you would usually:
from portkey_ai import Portkey
portkey = Portkey(
api_key="PORTKEY_API_KEY",
virtual_key="openai-xxx",
config="pp-semantic-cache"
)
response = portkey.chat.completions.create(
messages = [{ "role": 'user', "content": 'Portkey's semantic cache saves time and money' }],
model = 'gpt-4'
)
Refresh your cache
You can clear any previously stored cache value and fetch a new value using this feature. In the SDK, just set the cache_force_refresh flag at True ↓
response = portkey.with_options(
cache_force_refresh = True
).chat.completions.create(
messages = [{ "role": 'user', "content": 'Hello!' }],
model = 'gpt-4'
)
Check out Portkey docs for detailed instructions on how to use semantic cache.
In conclusion, the introduction of Semantic Cache not only cuts down costs and latency but also elevates the overall user experience.
PS: Portkey hosted the Chief Architect of Walmart to discuss how Walmart is doing semantic caching at scale and the conversation was enlightening! You can watch it here.
READ NEXT
Open Sourcing Guardrails on the Gateway Framework
Instruction Tuning with GPT-4 - Summary
Are We Really Making Much Progress in Text Classification? A Comparative Review - Summary
Subscribe to Portkey Blog
Subscribe now
Portkey Blog © 2024. Powered by Ghost
Subscribe to my newsletter
Read articles from Kavya directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by