Federated Learning for Distributed MLOps Security
 Subhanshu Mohan Gupta
Subhanshu Mohan GuptaTable of contents
- Introduction
- The Challenge: Balancing Data Privacy with Model Performance
- Real-World Example: FL for Financial Fraud Detection
- Federated Learning in Action
- Implementation Guide: FL for MLOps Security
- 1. High-Level Architecture
- 2. Data Partitioning
- 3. Model Design and Training at Local Nodes
- 4. Secure Update Transfer
- 5. Global Aggregation
- 6. Deployment & Iterative Improvement
- 7. Security Enhancements
- 8. Configuring AlertManager and Exporting Metrics to DataDog/ELK for Federated Learning Monitoring
- 9. Testing and Validation
- Next Steps: Deployment Script
- FL with Flower and TensorFlow
- Conclusion

Introduction
As Machine Learning Operations (MLOps) scale across industries, safeguarding sensitive data while enabling distributed training becomes a significant challenge. Enter Federated Learning (FL) — a decentralized approach that trains models across multiple devices or servers without transferring raw data. This article explores how FL enhances security in distributed MLOps, with a focus on real-world use cases in healthcare and finance. We'll also walk through an end-to-end implementation, complete with an architecture diagram and testing strategy.
The Challenge: Balancing Data Privacy with Model Performance
Traditional centralized ML pipelines collect data in one location for training, exposing sensitive information to breaches and non-compliance risks (e.g., GDPR, HIPAA). Federated Learning addresses this by keeping data localized, allowing the model to learn without compromising data privacy.
Real-World Example: FL for Financial Fraud Detection
Problem: A consortium of banks aims to detect fraudulent transactions. Sharing raw data isn’t feasible due to competitive concerns and privacy regulations.
Solution: Federated Learning. Each bank trains a local fraud detection model. Only encrypted gradients are shared with a global server that refines the fraud detection algorithm. Results:
Improved detection rates by 25%.
No raw data exchange, ensuring compliance with privacy laws.
Federated Learning in Action
Federated Learning enables secure model training by sending model updates (not raw data) from each participant node to a central server, where the updates are aggregated to refine the global model.
Key Benefits
Data Privacy: No raw data leaves its source.
Regulatory Compliance: Meets strict data protection laws like GDPR and HIPAA.
Reduced Latency: Training happens locally, minimizing the need for massive data transfers.
Use Cases
Healthcare - Federated Learning can be used for diagnostic models where patient data remains within hospital premises but contributes to a global ML model.
Finance - Banks can collaboratively train fraud detection models without exposing transactional data.
Implementation Guide: FL for MLOps Security
1. High-Level Architecture
To implement Federated Learning in a real-world scenario, we need to consider several aspects: data partitioning, secure communication protocols, model aggregation techniques, and end-to-end orchestration.
Below, we dive deeper into each step with enhanced details and include an updated architecture diagram.
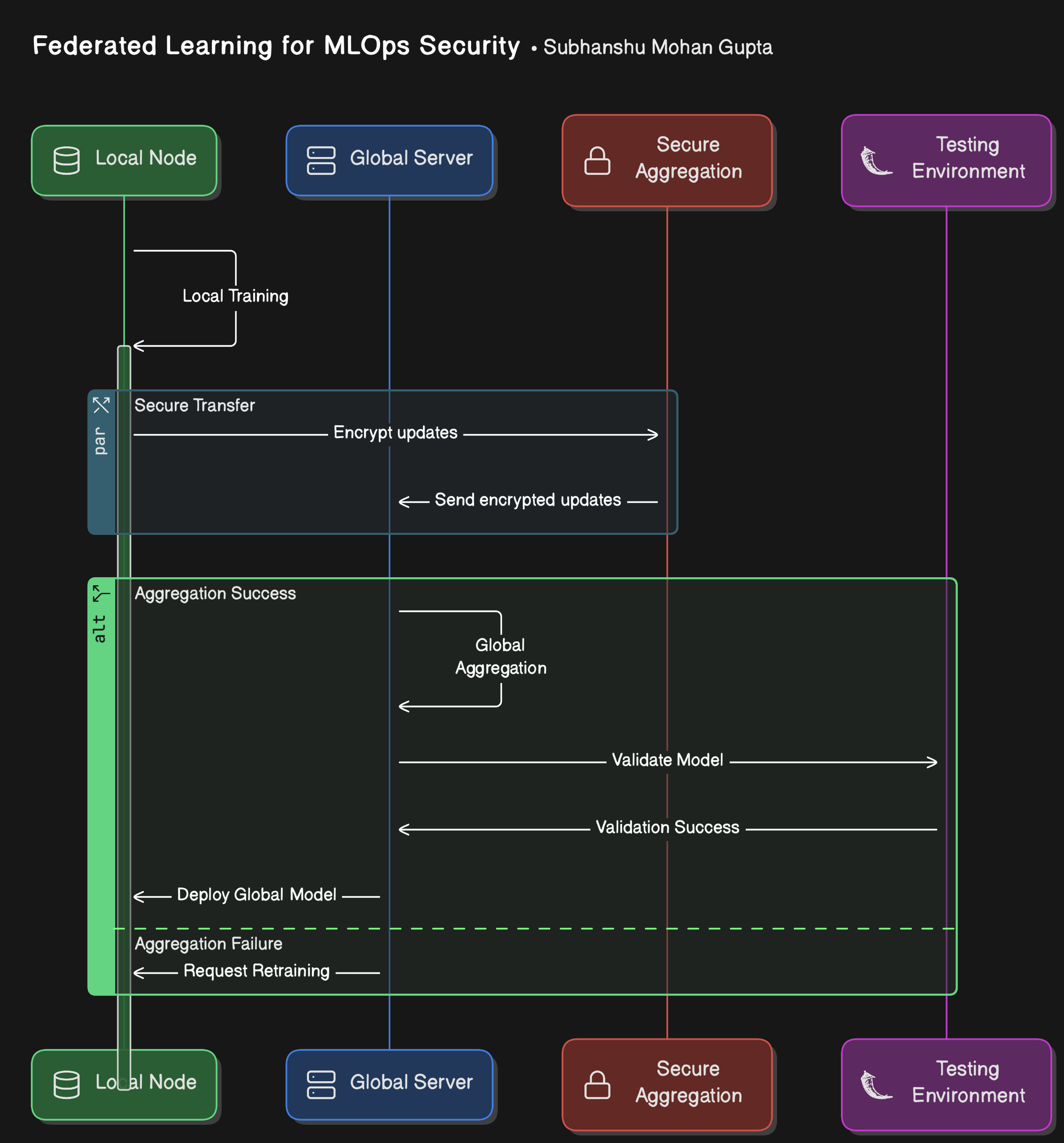
The architecture includes the following components:
Local Nodes (Hospitals, Banks, etc.) - Each node represents a data custodian (e.g., a hospital or a bank branch) that performs local model training.
Global Server - A central orchestrator aggregates encrypted model updates received from nodes.
Secure Aggregation - Uses homomorphic encryption or secure multiparty computation (SMPC) to protect updates during transit.
Testing Environment - Ensures that the aggregated model meets performance and privacy benchmarks.
2. Data Partitioning
Split the data into non-overlapping subsets corresponding to the nodes. Each subset resides exclusively at its local node.
# Example: Splitting Data for Two Nodes
data_node_1 = data[:split_point]
data_node_2 = data[split_point:]
3. Model Design and Training at Local Nodes
Design a model architecture compatible across all nodes. For example, using TensorFlow or PyTorch ensures consistency.
import tensorflow as tf
# Define Model
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
# Local Training
model = create_model()
model.fit(local_data, local_labels, epochs=5)
4. Secure Update Transfer
Leverage homomorphic encryption or PySyft for secure updates.
from syft.frameworks.torch.federated import utils
# Encrypt Model Parameters
encrypted_weights = utils.encrypt_model_params(model.get_weights())
5. Global Aggregation
Use Federated Averaging to combine model weights.
import numpy as np
def federated_averaging(models):
global_weights = np.mean([model.get_weights() for model in models], axis=0)
return global_weights
# Example: Aggregating Two Models
global_model.set_weights(federated_averaging([model_1, model_2]))
6. Deployment & Iterative Improvement
Deploy the global model back to local nodes for further refinement. This iterative loop continues until the model achieves the desired performance.
# Deploy Updated Model
local_node.load_model(global_model)
local_node.fine_tune(data, labels)
7. Security Enhancements
Differential Privacy: Introduce noise to updates for added security.
Homomorphic Encryption: Encrypt data to ensure only aggregated insights are shared.
8. Configuring AlertManager and Exporting Metrics to DataDog/ELK for Federated Learning Monitoring
This point covers configuring AlertManager for Slack notifications, and exporting metrics to DataDog and ELK for enhanced monitoring.
1. Setting Up AlertManager for Federated Learning Alerts
AlertManager is a component of Prometheus that handles alerts and sends notifications to external channels like Slack, email, or webhooks. Let's configure it to send alerts related to federated learning node health and model training progress.
Step 1: Install AlertManager
If you haven’t installed AlertManager, you can do so using Helm:
helm install alertmanager prometheus-community/alertmanager \
--namespace monitoring --create-namespace
Step 2: Configure AlertManager for Slack Notifications
To set up Slack notifications for alerts:
Create a Slack Webhook:
Go to your Slack workspace → Apps → Incoming Webhooks.
Create a new webhook and copy the generated URL.
Update Prometheus Alerting Rules: Create or edit an alerting rule for your federated learning metrics in Prometheus. Below is an example rule that triggers when the training accuracy falls below 85%.
groups:
- name: federated-learning-alerts
rules:
- alert: LowTrainingAccuracy
expr: fl_training_accuracy < 85
for: 5m
labels:
severity: critical
annotations:
summary: "Federated Learning Training Accuracy is below 85%"
description: "The training accuracy for federated learning models is below 85%. Immediate attention required."
Save this file and reload Prometheus:
kubectl exec -it <prometheus-pod> -n monitoring -- kill -HUP 1
- Configure AlertManager to Send Alerts to Slack: Edit the AlertManager configuration to use the Slack webhook.
Here’s an example configuration for AlertManager (alertmanager.yml):
global:
resolve_timeout: 5m
route:
receiver: 'slack-notifications'
receivers:
- name: 'slack-notifications'
slack_configs:
- api_url: 'https://hooks.slack.com/services/YOUR_SLACK_WEBHOOK_URL'
channel: '#federated-learning-alerts'
Apply the configuration by updating the AlertManager deployment:
kubectl apply -f alertmanager.yml
Now, whenever the training accuracy falls below 85%, an alert will be sent to Slack.
2. Exporting Prometheus Metrics to DataDog
Exporting Prometheus metrics to DataDog is useful for centralized monitoring across multiple services and infrastructure layers. To do this, we can use the Prometheus integration for DataDog.
Step 1: Install DataDog Agent
To send Prometheus metrics to DataDog, install the DataDog Agent on your Kubernetes cluster.
Create a DataDog API Key from the DataDog dashboard.
Add the DataDog Helm repository:
helm repo add datadog https://helm.datadoghq.com
helm repo update
- Install the DataDog Agent with the following command, replacing
<YOUR_API_KEY>with your actual DataDog API key:
helm install datadog datadog/datadog \
--set apiKey=<YOUR_API_KEY> \
--set prometheus.enabled=true \
--namespace monitoring --create-namespace
- Verify the DataDog agent is running:
kubectl get pods -n monitoring
Step 2: Enable Prometheus Scraping in DataDog
The DataDog Agent automatically scrapes Prometheus metrics if configured properly.
- Enable the Prometheus integration by configuring the Prometheus scraping in the DataDog Agent configuration file:
prometheusScraping:
enabled: true
scrapeInterval: 15s
scrapeTimeout: 10s
- Restart the DataDog agent for the changes to take effect:
kubectl rollout restart deployment datadog-agent -n monitoring
Now, you can view Prometheus metrics like training accuracy and node utilization directly in DataDog's UI.
3. Exporting Prometheus Metrics to ELK (Elasticsearch, Logstash, and Kibana)
Integrating Prometheus with ELK enables advanced logging and visual analysis for federated learning workflows. We will use Prometheus Exporter for Elasticsearch to push Prometheus data to ELK.
Step 1: Install Filebeat and Elasticsearch
- Install Filebeat on your Kubernetes cluster to forward logs from Prometheus to Elasticsearch:
kubectl apply -f https://raw.githubusercontent.com/elastic/helm-charts/main/elasticsearch/values.yaml
helm repo add elastic https://helm.elastic.co
helm install elasticsearch elastic/elasticsearch --namespace logging --create-namespace
- Install Logstash to handle data transformation and ingestion into Elasticsearch:
helm install logstash elastic/logstash --namespace logging
Step 2: Configure Prometheus Exporter for Elasticsearch
Install the Prometheus exporter for Elasticsearch to forward metrics from Prometheus to Elasticsearch.
helm install prometheus-elasticsearch-exporter prometheus-community/prometheus-elasticsearch-exporter \
--namespace logging --create-namespace
Step 3: Configure Filebeat to Forward Prometheus Metrics
- Configure Filebeat to capture Prometheus logs and forward them to Elasticsearch.
Add the following Filebeat input configuration to forward logs from Prometheus and Federated Learning:
filebeat.inputs:
- type: log
paths:
- /var/log/prometheus/*.log
- Apply the Filebeat configuration and restart the service:
kubectl apply -f filebeat-config.yaml
kubectl rollout restart daemonset filebeat -n logging
- Verify Metrics in Kibana: After configuring, open Kibana (accessed via the
http://<kibana-ip>:5601URL) and query the Prometheus metrics.
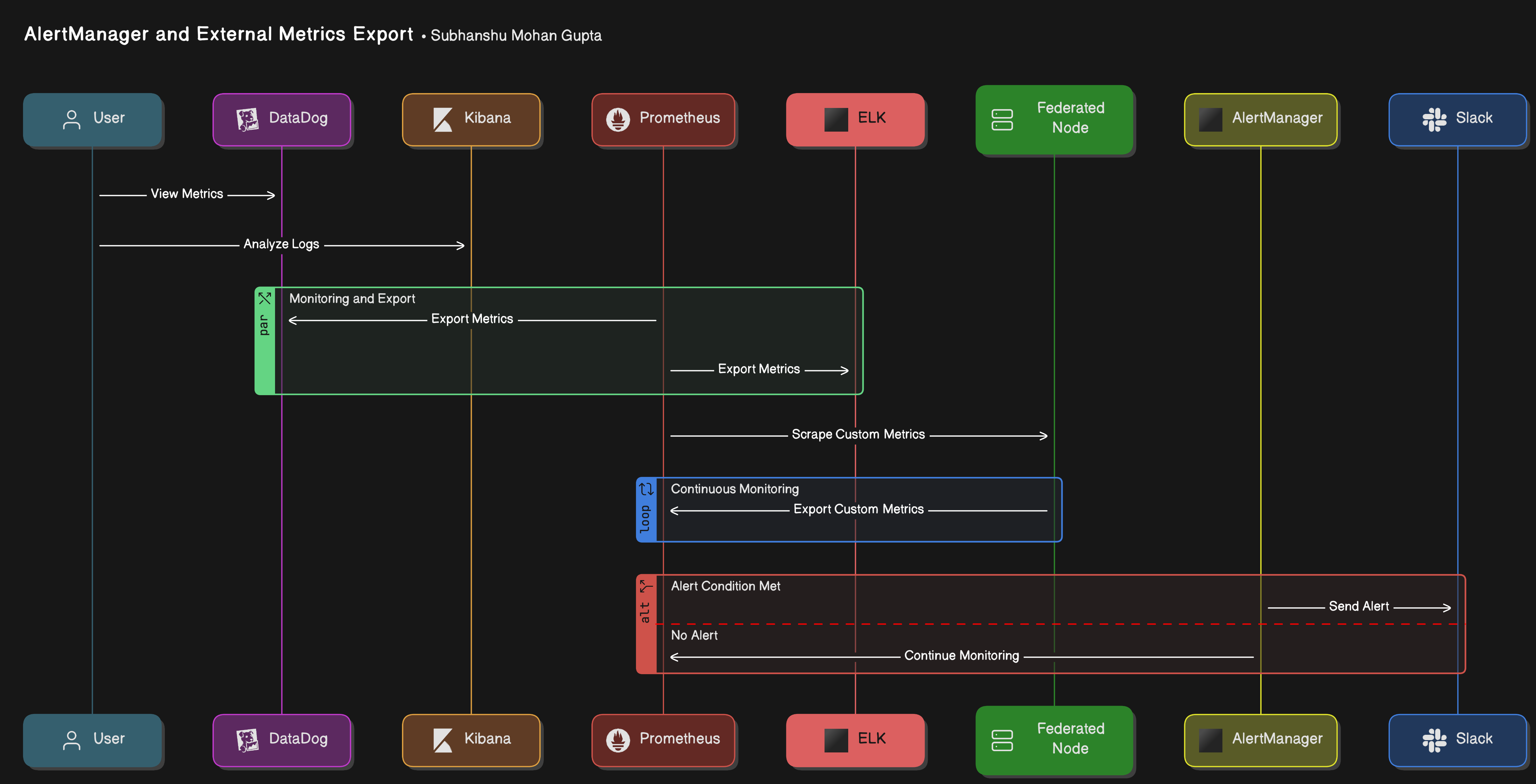
4. Architecture with AlertManager and External Metrics Export
Here’s a sequence diagram showcasing AlertManager with Slack notifications, and metrics exporting to DataDog and ELK
9. Testing and Validation
Testing Metrics
Model Accuracy: Compare global model performance against centralized baselines.
Privacy Testing: Use adversarial simulations to test if raw data can be inferred from updates.
Let’s dive deeper into the implementation and testing phase to ensure that the federated learning monitoring setup is both robust and scalable. This point will cover how to validate the deployed setup, simulate real-world scenarios, and ensure everything is functioning as expected.
1. Simulating Load and Traffic for Testing
Create Realistic Load Scenarios
In a federated learning environment, multiple nodes will be training local models and sharing updates. You want to simulate real-world traffic to test how well your monitoring and scaling architecture handles these operations.
Use Locust for Load Testing
- Install Locust (if you haven’t already):
pip install locust
- Create a Locust Test Script:
Here’s a sample script that simulates federated learning clients sending metrics and model updates:
from locust import HttpUser, task, between
class FederatedLearningUser(HttpUser):
wait_time = between(1, 5) # Simulate wait time between requests
@task
def send_model_update(self):
# Simulate sending model update data to the federated learning server
model_update_data = {
"model_id": "federated_model_1",
"update": {"weights": [0.1, 0.5, 0.8], "biases": [0.3, 0.7]},
"metrics": {"accuracy": 0.95, "loss": 0.05}
}
self.client.post("/model-update", json=model_update_data)
@task
def fetch_metrics(self):
# Simulate fetching training metrics from the federated nodes
self.client.get("/metrics")
This script simulates model updates and metrics fetches, representing what your federated learning clients would send and receive. You can then scale the load by adjusting the number of users (simulated federated nodes) and tasks.
- Run the Load Test:
Execute Locust with the following command:
locust -f locustfile.py --host=http://<federated-learning-server-ip>
Open the Locust web interface (default on port 8089) and start the test. You can simulate large numbers of requests to test how the system behaves under high load.
2. Validating Prometheus Metrics Collection
Step 1: Ensure Metrics Are Being Collected
Use Prometheus’ web interface to query metrics for correctness. Open the Prometheus dashboard and use queries like:
fl_model_updates_total
fl_training_loss
fl_training_accuracy
This will help you verify that model updates and training metrics are being captured correctly.
Key Metrics to Check
fl_model_updates_total: Total number of model updates received.fl_training_accuracy: Accuracy metric from the federated nodes.fl_training_loss: Loss metric from the federated training process.
Step 2: Monitor with Grafana Dashboards
If you have Grafana set up, you should create custom dashboards to visualize your federated learning metrics.
Create a New Dashboard in Grafana:
Use Prometheus as a data source.
Add panels for the metrics like
fl_model_updates_total,fl_training_loss, andfl_training_accuracy.
Add Alerts to Grafana: You can set up alerts in Grafana to notify you of any abnormal behavior, such as:
Training accuracy dropping below a certain threshold.
Model updates not being received within a defined time.
3. Testing AlertManager Setup
You can manually trigger alerts to ensure that AlertManager is working correctly.
- Create a Test Alert in Prometheus:
In the prometheus.yml file, add a simple alert rule like:
groups:
- name: federated-learning-alerts
rules:
- alert: ModelAccuracyDropped
expr: fl_training_accuracy < 0.80
for: 5m
labels:
severity: critical
annotations:
summary: "Federated model accuracy dropped below threshold"
This alert triggers when the accuracy drops below 80% for 5 minutes.
- Test Alert Firing:
If the accuracy drops below the threshold (e.g., due to a poor model update), Prometheus will fire the alert, and AlertManager will handle the notification (email, Slack, etc.).
- Verify Alerts in AlertManager:
You can check the AlertManager UI (typically on port 9093) to see if the alert was triggered and routed correctly.
4. Validating ELK Stack for Logging
Step 1: Verify Log Collection
Once logs are sent from Logstash to Elasticsearch, ensure they are being indexed correctly:
- Query Elasticsearch for logs:
curl -X GET "localhost:9200/federated-logs-*/_search?q=update"
This will help you verify that logs related to model updates and other interactions are being stored correctly.
Step 2: Check for Log Anomalies
Use Kibana to analyze logs. Set up Kibana dashboards to monitor key logs, such as:
Model update logs: Ensure that federated nodes are sending updates.
Training status logs: Track whether the training process is progressing without errors.
You can also set up alerts within Kibana for certain log patterns (e.g., error logs).
5. Ensuring DataDog Integration Works
Step 1: Monitor Prometheus Metrics in DataDog
If you’ve integrated Prometheus with DataDog, you can use Datadog’s dashboards to visualize your federated learning metrics.
- Configure DataDog Dashboards:
Set up custom dashboards in DataDog to monitor:
The number of model updates.
Training metrics such as accuracy and loss.
Infrastructure health, including CPU, memory, and disk usage on the federated nodes.
- Check for Alerts in DataDog:
Ensure that alerts are firing when unusual activity occurs (e.g., model accuracy degradation, failed model updates, etc.).
Step 2: Scale the System with DataDog
Simulate the scaling up of federated learning nodes and check the performance in DataDog. It will help you ensure that DataDog can handle monitoring as the federated system scales.
6. Stress Testing the Whole Setup
After setting up the scalable monitoring architecture, perform stress testing to simulate real-world failure conditions, such as:
Node failures: Simulate failures of federated learning nodes and ensure that your monitoring system alerts appropriately.
Heavy load: Increase the number of federated learning nodes to test system performance under stress.
Data sync issues: Simulate delayed or failed model updates to check how the system handles such cases.
You can also perform chaos engineering (e.g., Gremlin or Chaos Monkey) to disrupt different parts of the infrastructure and check how well the monitoring, alerting, and scaling mechanisms react.
Next Steps: Deployment Script
Experiment with TensorFlow and Flower.
Simulate real-world FL scenarios in your MLOps pipeline.
Implement advanced security protocols like homomorphic encryption.
Let’s go ahead and implement the custom deployment script for the above steps.
FL with Flower and TensorFlow
This custom script simulates a federated learning setup with two local nodes, a global server, and secure updates.
1. Setup Flower and TensorFlow
Install the required libraries:
pip install flwr tensorflow
2. Node Implementation
Each node (e.g., hospital or bank) trains its local model and communicates with the global server.
Node Script: node.py
import flwr as fl
import tensorflow as tf
import numpy as np
# Create a simple dataset
def load_data():
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
return (x_train[:10000], y_train[:10000]), (x_test[:2000], y_test[:2000])
# Define a simple model
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
# Federated Learning client
class FLClient(fl.client.NumPyClient):
def __init__(self, model, train_data, test_data):
self.model = model
self.train_data = train_data
self.test_data = test_data
def get_parameters(self):
return self.model.get_weights()
def set_parameters(self, parameters):
self.model.set_weights(parameters)
def fit(self, parameters, config):
self.set_parameters(parameters)
self.model.fit(self.train_data[0], self.train_data[1], epochs=1, batch_size=32)
return self.get_parameters(), len(self.train_data[0]), {}
def evaluate(self, parameters, config):
self.set_parameters(parameters)
loss, accuracy = self.model.evaluate(self.test_data[0], self.test_data[1])
return loss, len(self.test_data[0]), {"accuracy": accuracy}
if __name__ == "__main__":
# Load data and model
train_data, test_data = load_data()
model = create_model()
# Start Flower client
fl.client.start_numpy_client(server_address="localhost:8080", client=FLClient(model, train_data, test_data))
3. Global Server Implementation
The server orchestrates the federated learning process by aggregating updates from nodes.
Server Script: server.py
import flwr as fl
# Define strategy for aggregation
strategy = fl.server.strategy.FedAvg()
# Start Flower server
if __name__ == "__main__":
fl.server.start_server(server_address="localhost:8080", config={"num_rounds": 3}, strategy=strategy)
4. Running the System
Start the server:
python server.pyStart the nodes (run in separate terminals):
python node.py
5. Securing Updates with Differential Privacy
Flower allows customization to secure updates. Add differential privacy noise before sending updates. Modify the fit method in node.py:
import numpy as np
def add_dp_noise(parameters, epsilon=1.0):
noise = [np.random.laplace(0, 1/epsilon, p.shape) for p in parameters]
return [p + n for p, n in zip(parameters, noise)]
def fit(self, parameters, config):
self.set_parameters(parameters)
self.model.fit(self.train_data[0], self.train_data[1], epochs=1, batch_size=32)
parameters = self.get_parameters()
parameters = add_dp_noise(parameters, epsilon=0.5) # Add noise for DP
return parameters, len(self.train_data[0]), {}
6. Testing and Validation
After training, test the global model’s performance:
Global Testing Script
import tensorflow as tf
# Define global model
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
# Load test data
(_, _), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_test = x_test / 255.0
# Evaluate the model
global_model = create_model()
global_model.set_weights(<aggregated_weights>) # Add aggregated weights
loss, accuracy = global_model.evaluate(x_test, y_test)
print(f"Test Accuracy: {accuracy}")
7. End-to-End Workflow
Server Aggregates Updates: Collects encrypted weights from nodes and computes a global model.
Nodes Train Locally: Iteratively improve the global model using their private datasets.
Validation: Evaluate global model performance while ensuring privacy.
8. Next Steps: Kubernetes deployment
Add Homomorphic Encryption:
Secure updates further with encryption libraries like PySyft.
Real Data Simulation:
Use healthcare or financial datasets for realistic testing.
Deployment in Kubernetes:
For scalability, deploy the nodes and server as Kubernetes pods.
Below’s an extended deployment guide to implement Federated Learning in Kubernetes, including steps for containerization, orchestration, and security using encryption.
Prerequisites
Install Docker: Required for containerizing the server and nodes.
sudo apt update sudo apt install docker.ioInstall Minikube or Kubernetes: To simulate the Kubernetes cluster.
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 sudo install minikube-linux-amd64 /usr/local/bin/minikube minikube startInstall kubectl: Kubernetes command-line tool.
sudo apt install -y kubectl
Containerization with Docker
Dockerfile for Server (
server.Dockerfile)FROM python:3.9-slim # Install dependencies RUN pip install flwr tensorflow # Copy server script COPY server.py /app/server.py # Set working directory WORKDIR /app # Expose port EXPOSE 8080 # Run server CMD ["python", "server.py"]Dockerfile for Node (
node.Dockerfile)FROM python:3.9-slim # Install dependencies RUN pip install flwr tensorflow # Copy node script COPY node.py /app/node.py # Set working directory WORKDIR /app # Run node CMD ["python", "node.py"]Build and Push Docker Images
- Build the images:
docker build -t federated-server -f server.Dockerfile . docker build -t federated-node -f node.Dockerfile .- Push to a container registry (e.g., Docker Hub):
docker tag federated-server <your_dockerhub_username>/federated-server docker tag federated-node <your_dockerhub_username>/federated-node docker push <your_dockerhub_username>/federated-server docker push <your_dockerhub_username>/federated-node
Deploying in Kubernetes
Kubernetes Deployment YAML for Server (
server-deployment.yaml)apiVersion: apps/v1 kind: Deployment metadata: name: federated-server spec: replicas: 1 selector: matchLabels: app: federated-server template: metadata: labels: app: federated-server spec: containers: - name: federated-server image: <your_dockerhub_username>/federated-server ports: - containerPort: 8080 --- apiVersion: v1 kind: Service metadata: name: federated-server-service spec: type: NodePort ports: - port: 8080 targetPort: 8080 nodePort: 30001 selector: app: federated-serverKubernetes Deployment YAML for Nodes (
node-deployment.yaml)apiVersion: apps/v1 kind: Deployment metadata: name: federated-node spec: replicas: 2 selector: matchLabels: app: federated-node template: metadata: labels: app: federated-node spec: containers: - name: federated-node image: <your_dockerhub_username>/federated-node env: - name: SERVER_ADDRESS value: "federated-server-service:8080"Apply Kubernetes Configurations
kubectl apply -f server-deployment.yaml kubectl apply -f node-deployment.yaml
Secure Communication with Encryption
Homomorphic Encryption for Secure UpdatesIntegrate PySyft for encryption:
Install PySyft:
pip install syftModify the
fitmethod in thenode.pyto encrypt updates:from syft.frameworks.torch.federated import utils def fit(self, parameters, config): self.set_parameters(parameters) self.model.fit(self.train_data[0], self.train_data[1], epochs=1, batch_size=32) encrypted_weights = utils.encrypt_model_params(self.model.get_weights()) return encrypted_weights, len(self.train_data[0]), {}
Testing in Kubernetes
Check Pods Status:
kubectl get podsAccess Server Logs:
kubectl logs -f <federated-server-pod-name>Validate Node Training:
kubectl logs -f <federated-node-pod-name>
Monitoring and Scaling
Scaling the Nodes
Increase the number of nodes dynamically:
kubectl scale deployment federated-node --replicas=5Monitoring with Prometheus and Grafana
Deploy Prometheus and Grafana in your cluster.
Expose metrics from
server.pyandnode.pyfor monitoring:from prometheus_client import start_http_server, Summary REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing requests') start_http_server(8000)
Conclusion
Federated Learning bridges the gap between data privacy and collaborative intelligence. Industries like healthcare and finance can securely scale their ML pipelines using this approach. Building and deploying a scalable and secure FL system requires integrating various technologies.
From Flower to Kubernetes for container orchestration, Prometheus for monitoring, and by integrating tools like PySyft and privacy-preserving techniques, organizations can achieve robust, secure, and compliant distributed ML systems.
Subscribe to my newsletter
Read articles from Subhanshu Mohan Gupta directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Subhanshu Mohan Gupta
Subhanshu Mohan Gupta
A passionate AI DevOps Engineer specialized in creating secure, scalable, and efficient systems that bridge development and operations. My expertise lies in automating complex processes, integrating AI-driven solutions, and ensuring seamless, secure delivery pipelines. With a deep understanding of cloud infrastructure, CI/CD, and cybersecurity, I thrive on solving challenges at the intersection of innovation and security, driving continuous improvement in both technology and team dynamics.