Jak skutecznie wyszukiwać wiele elementów w kolekcjach .NET
 Beniamin Lenarcik
Beniamin Lenarcik
W dzisiejszym świecie rozproszonych systemów, mikro serwisów i różnych sposobów przechowywania danych coraz częściej musimy łączyć dane w warstwie obliczeniowej aplikacji. Do poszukiwania relacji między nimi często korzystamy z właściwości takich jak globalnie unikalne identyfikatory (GUID), wartości liczbowe czy inne specyficzne pola, np. nazwy produktów.
Jako praktyczny przykład prezentuję schemat architektoniczny mojej aplikacji mobilnej JokesPortal, w której często spotykam się z koniecznością łączenia danych z różnych źródeł - systemów przechowywania i produktów 3rd party:
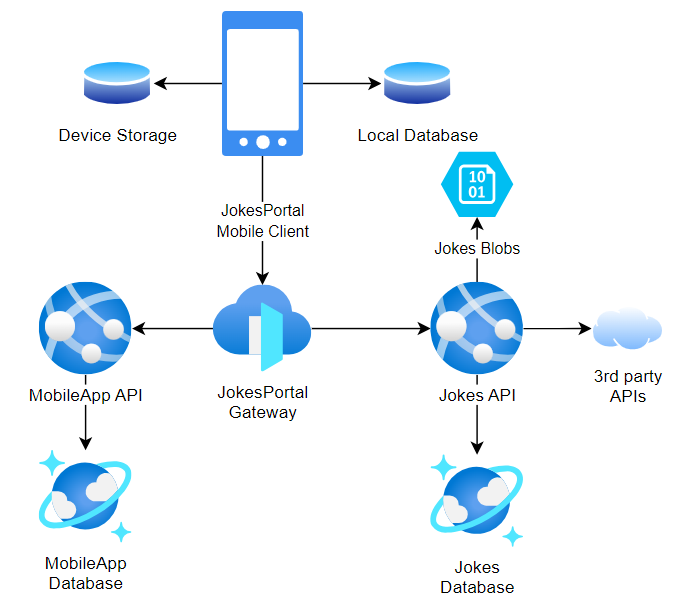
Podczas łączenia dużych zbiorów danych łatwo przeoczyć jedno z najczęstszych źródeł utraty wydajności – wielokrotne wyszukiwanie elementów jednej kolekcji w drugiej.
W artykule pokażę jak skutecznie wykonywać agregację elementów między kolekcjami w warstwie obliczeniowej. Podzielę się z Tobą obrazową analogią oraz praktycznym, krótkim benchmarkiem.
Analogia dostawcy jedzenia
Wyobraź sobie, że pracujesz jako dostawca jedzenia w znanej firmie, w której najczęściej Twoim pojazdem służbowym jest rower elektryczny lub skuter. Masz do dostarczenia pełną torbę zamówień do największego bloku w mieście - 10 000 mieszkań.

W swojej aplikacji mobilnej widzisz wszystkie potrzebne informacje, w tym numery lokali pod którymi głodni klienci czekają na dostawę. Gdy wchodzisz do budynku, czeka na Ciebie przykra niespodzianka. Blok jest na tyle nowy, że zarządca nie umieścił jeszcze numerów mieszkań na drzwiach i korytarzach.

Aby dostarczyć zamówienie, musisz pukać do każdych drzwi pytając o numer lokalu i porównując go z odpowiednikami na opakowaniach, które masz w torbie. Jesteś zbyt zabiegany, by choćby posortować paczki z jedzeniem.
Ta niewesoła sytuacja jest dokładnym odpowiednikiem wywoływania metody .Contains() na liście w każdej iteracji pętli. Każdorazowo przeszukujesz torbę z jedzeniem w poszukiwaniu konkretnego numeru zamówienia. Czynność powtarzasz dla każdych drzwi w bloku.
Optymalne rozwiązanie: użycie HashSet lub Dictionary.
Z reguły mieszkania w budynku są oznaczone numerami. Dodatkowo, na każdym piętrze, a może przy wejściu do budynku może znajdować się lista z rozpiską: piętro - numery mieszkań. Dzięki temu możesz skierować się od razu do właściwego mieszkania.
Jeśli kilka zamówień trafia pod jeden adres lub na to samo piętro, warto na chwilę zatrzymać się przy tablicy z numerami mieszkań i uporządkować torbę. Może to zaoszczędzić sporo czasu.
W .Net analogiczną, właściwą optymalizację dla takiego przypadku użycia oferują struktury danych takie jak HashSet lub Dictionary. Korzystają one z indeksu na podstawie hashów. Umożliwiają błyskawiczny dostęp i eliminują konieczność niepotrzebnego przeszukiwania całych kolekcji. Dodatkowo, algorytmy oparte na indeksach gwarantują stały czas wyszukiwania, w przeciwieństwie do wyszukiwania liniowego, które może się znacznie różnić w zależności od rozkładu danych.

Benchmark metod .Contains() i .Select()
Aby pokazać różnice wydajności pomiędzy różnymi podejściami do wyszukiwania wielu elementów w kolekcjach, przygotowałem praktyczny benchmark. Porównałem kilka metod, które często stosujemy w aplikacjach .NET. Poniżej przedstawiam wyniki tych pomiarów. Eksperyment przeprowadziłem w środowisku .Net9.
Kod źródłowy dostępny na moim GitHub.
Konfiguracja
Porównałem kilka typowych scenariuszy wyszukiwania w celu zmierzenia wydajności wyszukiwania wielu elementów w kolekcji:
| Testowany przypadek | Struktura danych i metoda | Opis działania | Złożoność |
| Contains_Multiple_Dictionary | Dictionary.ContainsKey | Tworzenie słownika przy każdym wyszukiwaniu. | O(n + m) |
| Contains_Multiple_Dictionary_Precomputed | Dictionary.ContainsKey (precomputed) | Słownik utworzony raz, używany wielokrotnie. | O(m) |
| Contains_Multiple_HashSet | HashSet.Contains | Tworzenie HashSetu przy każdym wyszukiwaniu. | O(n + m) |
| Contains_Multiple_HashSet_Precomputed | HashSet.Contains (precomputed) | HashSet utworzony raz, używany wielokrotnie. | O(m) |
| Contains_Multiple_List_Any | List.Any | Przeszukiwanie liniowe dla każdego wyszukiwania. | O(n × m) |
| Select_Multiple_Dictionary | Dictionary.TryGetValue (tworzony za każdym razem) | Tworzenie słownika przy każdym wyszukiwaniu, TryGetValue zamiast ContainsKey. | O(n + m) |
| Select_Multiple_List_FirstOrDefault | List.FirstOrDefault | Przeszukiwanie liniowe, zwracanie pierwszego pasującego elementu | O(n × m) |
Wyniki
Poniżej przedstawiam wyniki benchmarku wyszukiwania 1000 elementów w kolekcji liczącej 10 000 elementów (środowisko .NET 9):
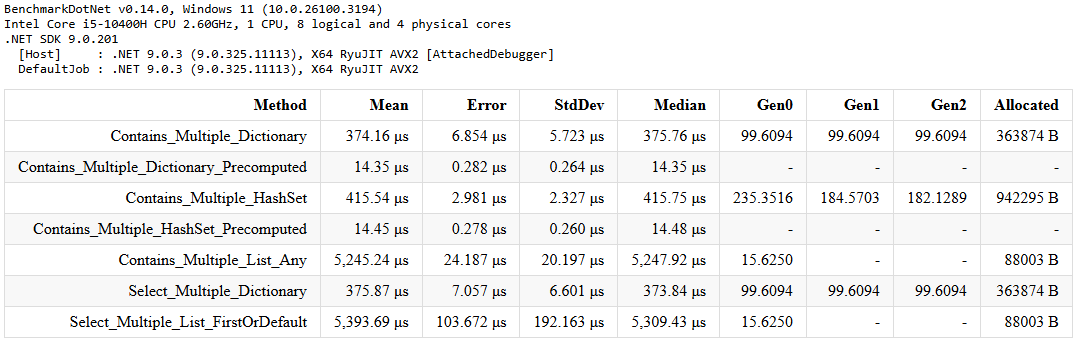
Przedstawione wyniki dotyczą konkretnego przypadku testowego – w praktyce warto powtórzyć benchmarki, dostosowując rozmiary kolekcji do własnych potrzeb.
Wnioski
Benchmark wyraźnie pokazuje, że przy wielokrotnych wyszukiwaniach warto przekształcić kolekcję do Dictionary lub HashSet. Należy unikać .Contains() i innych operacji liniowych na listach w pętlach.
Na liczbach
Przy potrzebie pojedynczej iteracji przez kolekcję, zamiana na słownik (Contains_Multiple_Dictionary) daje wzrost wydajności o ~14x w stosunku do korzystania z listy (Contains_Multiple_List_Any).
374.165 / 245.24 = 14.02 ~ 1 400%
Gdy wymagane jest kilka przejść przez pętlę, wydajność Precomputed Dictionary sprawia, że kolejne przejścia nie mają istotnego wpływu na redukcję wydajności, każde kolejne wyszukiwanie jest ~365x szybsze w porównaniu do użycia listy Contains_Multiple_List_Any
5245.24 / 14.35 = 365.52 ~ 36 500%
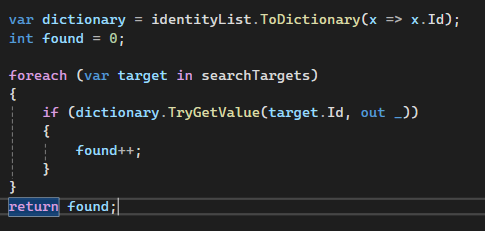
Przykład, jak skutecznie wyszukać wiele elementów w liście.
To przykład zamiany listy w słownik przy wyszukiwaniu elementów o takim samym ID(Guid) ze stworzonych benchmarków:
Uwaga
Metoda .ToDictionary() wymaga unikalnych kluczy – w przypadku duplikatów rzucony zostanie wyjątek ArgumentException. Jeśli dane pochodzą z wielu źródeł, a duplikaty są możliwe, warto najpierw je obsłużyć (np. używając .GroupBy().ToDictionary()).
Dodatkowe informacje
Warto również pamiętać także o metodach LINQ, takich jak .Intersect() czy .Except(), które także wykorzystują haszowanie.
Subscribe to my newsletter
Read articles from Beniamin Lenarcik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Beniamin Lenarcik
Beniamin Lenarcik
.NET Developer | I build applications from concept to production. On my blog, I share practical examples (.NET “by example”) and thoughts on software architecture and bridging technology with business.